欢迎 fastai 加入 Hugging Face Hub



让神经网络再次不酷……并分享它们
很少有像 fast.ai 生态系统这样致力于使深度学习变得易于使用的。Hugging Face 的使命是使优秀的机器学习民主化。让我们将机器学习(包括预训练模型)的独占访问变为过去,并进一步推动这个令人惊叹的领域。
fastai 是一个开源深度学习库,它利用 PyTorch 和 Python 提供高级组件,用于在文本、视觉和表格数据上训练快速、准确的神经网络,并取得最先进的成果。然而,fast.ai,这家公司,不仅仅是一个库;它已经发展成为一个由开源贡献者和学习神经网络的人组成的繁荣生态系统。例如,您可以查看他们的书籍和课程。加入 fast.ai 的 Discord 和论坛。保证您会通过参与他们的社区而学到很多!
鉴于以上种种,以及更多(本文作者的旅程就始于 fast.ai 课程),我们很荣幸地宣布,fastai 用户现在只需一行 Python 代码,即可将模型分享并上传到 Hugging Face Hub。
👉 在这篇博文中,我们将介绍 fastai 与 Hub 之间的集成。此外,您可以将此教程作为 Colab 笔记本打开。
我们感谢 fast.ai 社区,特别是 Jeremy Howard、Wayde Gilliam 和 Zach Mueller 提供的反馈 🤗。本博客深受 fastai 文档中Hugging Face Hub 部分的启发。
为什么分享到 Hub?
Hub 是一个中心平台,任何人都可以分享和探索模型、数据集和机器学习演示。它拥有最广泛的开源模型、数据集和演示集合。
在 Hub 上分享您的 fastai 模型,可以扩大其影响力,使其可供他人下载和探索。您还可以使用 fastai 模型进行迁移学习;将他人的模型作为您任务的基础。
任何人都可以通过在 hf.co/models 网页上按 fastai 库筛选来访问 Hub 中的所有 fastai 模型,如下图所示。
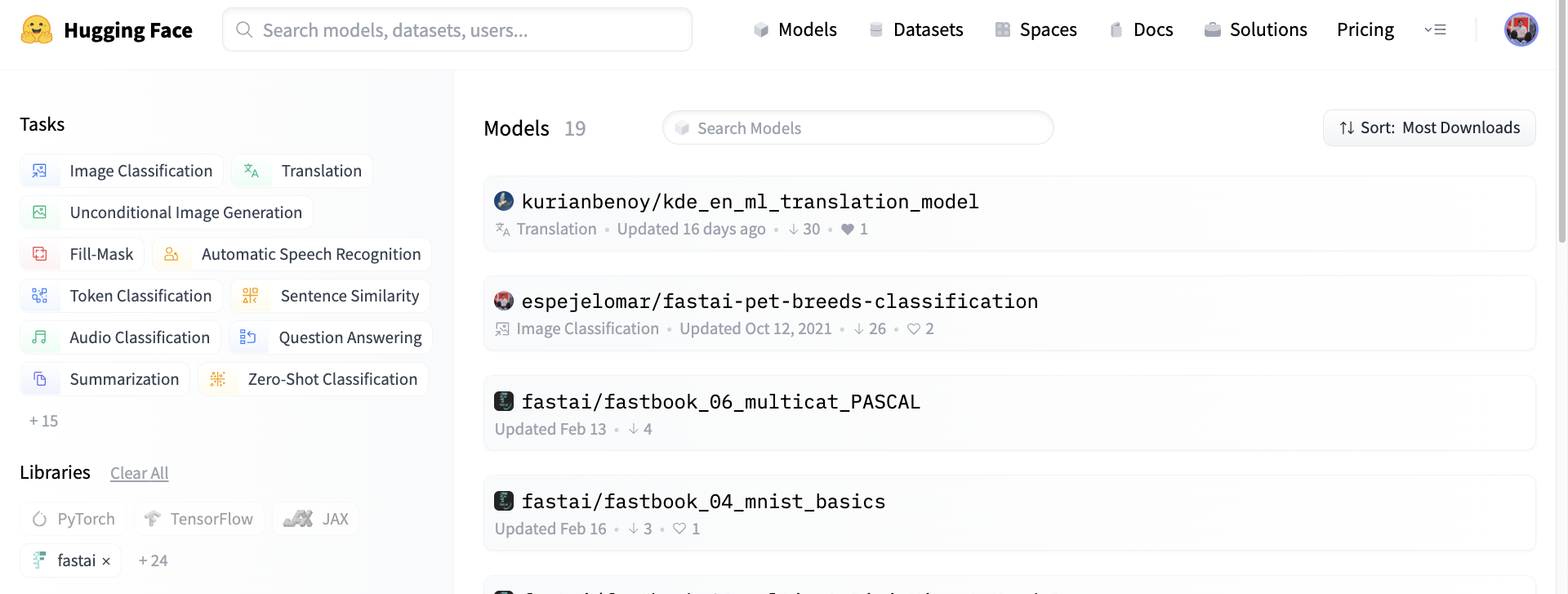
除了免费的模型托管和对更广泛社区的曝光之外,Hub 还内置了基于 git 的版本控制(用于大文件的 git-lfs)和用于可发现性和可重现性的模型卡。有关导航 Hub 的更多信息,请参阅此介绍。
加入 Hugging Face 并安装
要在 Hub 中分享模型,您需要有一个用户。在 Hugging Face 网站上创建它。
huggingface_hub 库是一个轻量级的 Python 客户端,具有与 Hugging Face Hub 交互的实用功能。要将 fastai 模型推送到 Hub,您需要预先安装一些库(fastai>=2.4、fastcore>=1.3.27 和 toml)。您可以在安装 huggingface_hub 时通过指定 ["fastai"] 自动安装它们,您的环境就可以使用了
pip install huggingface_hub["fastai"]
创建一个 fastai `Learner`
在这里,我们训练 fastbook 中的第一个模型来识别猫 🐱。我们强烈建议阅读完整的 fastbook。
# Training of 6 lines in chapter 1 of the fastbook.
from fastai.vision.all import *
path = untar_data(URLs.PETS)/'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path, get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat, item_tfms=Resize(224))
learn = vision_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)
将 `Learner` 分享到 Hub
`Learner` 是一个 fastai 对象,它捆绑了模型、数据加载器和损失函数。在本篇博文中,我们将互换使用 `Learner` 和 Model 这两个词。
首先,登录 Hugging Face Hub。您需要在您的帐户设置中创建一个`write` token。然后有三种登录方式
在您的终端中输入 `huggingface-cli login` 并输入您的 token。
如果在 Python 笔记本中,您可以使用 `notebook_login`。
from huggingface_hub import notebook_login
notebook_login()
- 使用 `push_to_hub_fastai` 函数的 `token` 参数。
您可以将要上传的 `Learner` 和 Hub 的仓库 ID(格式为“namespace/repo_name”)输入到 `push_to_hub_fastai` 中。命名空间可以是个人账户,也可以是您有写入权限的组织(例如,“fastai/stanza-de”)。有关更多详细信息,请参阅 Hub 客户端文档。
from huggingface_hub import push_to_hub_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "espejelomar/identify-my-cat"
push_to_hub_fastai(learner=learn, repo_id=repo_id)
该 `Learner` 现在位于 Hub 中,仓库名为 `espejelomar/identify-my-cat`。一个自动模型卡已创建,其中包含一些链接和后续步骤。上传 fastai `Learner`(或任何其他模型)到 Hub 时,编辑其模型卡(下图)以帮助他人更好地理解您的工作会很有帮助(请参阅Hugging Face 文档)。
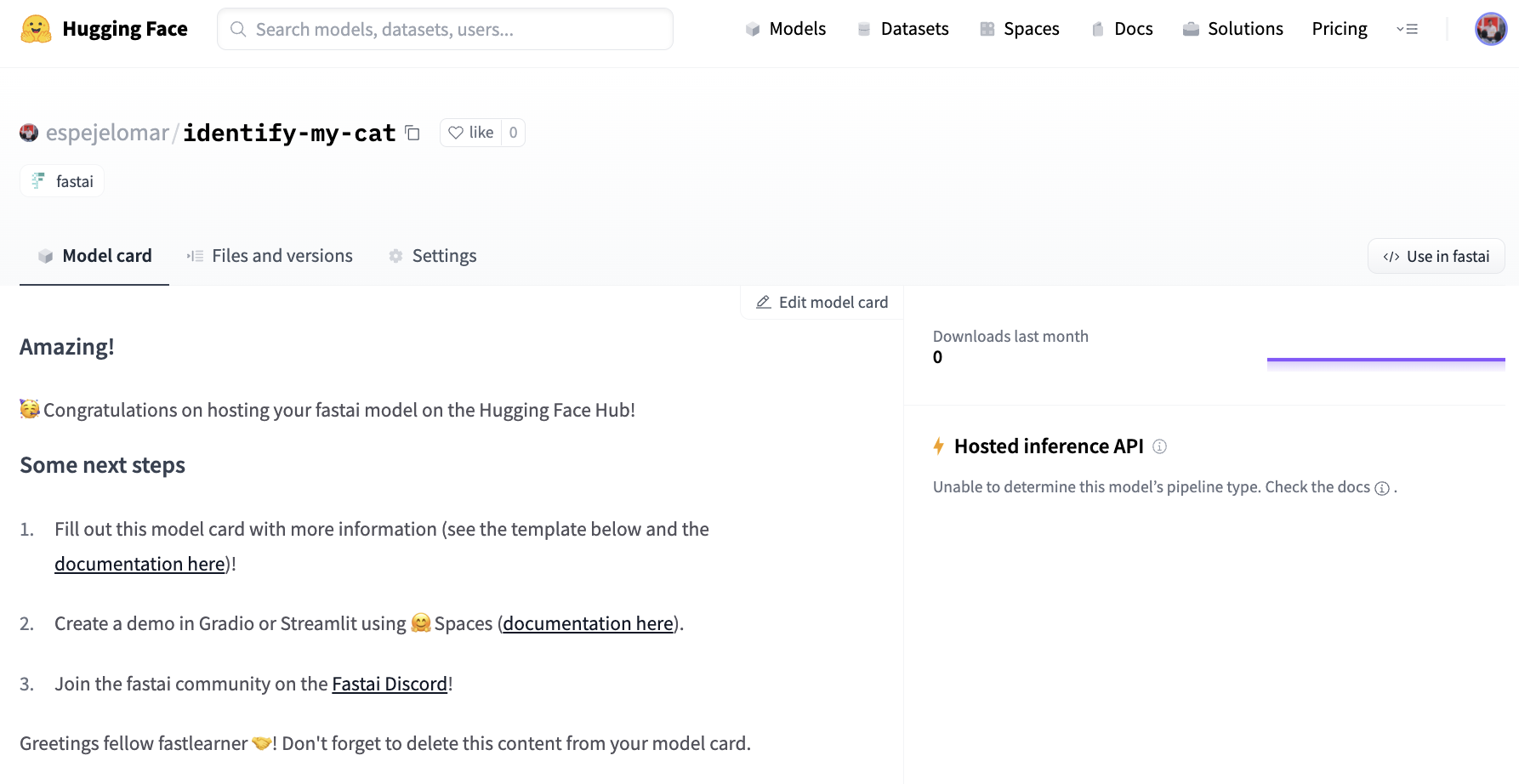
如果您想了解更多关于 `push_to_hub_fastai` 的信息,请访问 Hub 客户端文档。里面有一些您可能会感兴趣的很酷的参数 👀。请记住,您的模型是一个Git 仓库,具有 Git 带来的一切优点:版本控制、提交、分支……
从 Hugging Face Hub 加载 `Learner`
从 Hub 加载模型更简单。我们将加载我们的 `Learner`,“espejelomar/identify-my-cat”,并用一张猫的图片进行测试(🦮?)。此代码改编自 fastbook 的第一章。
首先,上传一张猫的图片(或者可能是一只狗?)。本教程的 Colab 笔记本使用 `ipywidgets` 交互式上传猫的图片(或者不上传?)。这里我们将使用这只可爱的猫 🐅

现在让我们加载我们刚刚在 Hub 中共享的 `Learner` 并进行测试。
from huggingface_hub import from_pretrained_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "espejelomar/identify-my-cat"
learner = from_pretrained_fastai(repo_id)
它奏效了 👇!
_,_,probs = learner.predict(img)
print(f"Probability it's a cat: {100*probs[1].item():.2f}%")
Probability it's a cat: 100.00%
Hub 客户端文档中包含 `from_pretrained_fastai` 的更多详细信息。
`Blurr`:结合 fastai 和 Hugging Face Transformers(并分享它们)!
[Blurr 是]一个专为 fastai 开发者设计的库,旨在训练和部署 Hugging Face Transformers - Blurr 文档。
我们将:
- 使用高级 Blurr API 训练一个 `blurr` Learner。它将从 Hugging Face Hub 加载 `distilbert-base-uncased` 模型,并准备一个序列分类模型。
- 使用 `push_to_hub_fastai` 将其分享到 Hub,命名空间为 `fastai/blurr_IMDB_distilbert_classification`。
- 使用 `from_pretrained_fastai` 加载它,并使用 `learner_blurr.predict()` 进行尝试。
协作和开源太棒了!
首先,安装 `blurr` 并训练 Learner。
git clone https://github.com/ohmeow/blurr.git
cd blurr
pip install -e ".[dev]"
import torch
import transformers
from fastai.text.all import *
from blurr.text.data.all import *
from blurr.text.modeling.all import *
path = untar_data(URLs.IMDB_SAMPLE)
model_path = Path("models")
imdb_df = pd.read_csv(path / "texts.csv")
learn_blurr = BlearnerForSequenceClassification.from_data(imdb_df, "distilbert-base-uncased", dl_kwargs={"bs": 4})
learn_blurr.fit_one_cycle(1, lr_max=1e-3)
使用 `push_to_hub_fastai` 分享到 Hub。
from huggingface_hub import push_to_hub_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "fastai/blurr_IMDB_distilbert_classification"
push_to_hub_fastai(learn_blurr, repo_id)
使用 `from_pretrained_fastai` 从 Hub 加载 `blurr` 模型。
from huggingface_hub import from_pretrained_fastai
# repo_id = "YOUR_USERNAME/YOUR_LEARNER_NAME"
repo_id = "fastai/blurr_IMDB_distilbert_classification"
learner_blurr = from_pretrained_fastai(repo_id)
用几个句子试一下,并用 `learner_blurr.predict()` 查看它们的情感(消极或积极)。
sentences = ["This integration is amazing!",
"I hate this was not available before."]
probs = learner_blurr.predict(sentences)
print(f"Probability that sentence '{sentences[0]}' is negative is: {100*probs[0]['probs'][0]:.2f}%")
print(f"Probability that sentence '{sentences[1]}' is negative is: {100*probs[1]['probs'][0]:.2f}%")
又成功了!
Probability that sentence 'This integration is amazing!' is negative is: 29.46%
Probability that sentence 'I hate this was not available before.' is negative is: 70.04%
接下来做什么?
参加 fast.ai 课程(新版本即将推出),关注 Jeremy Howard 和 fast.ai 的 Twitter 更新,并开始在 Hub 上分享您的 fastai 模型 🤗。或者加载一个Hub 中已有的模型。
📧 欢迎通过 Hugging Face Discord 联系我们,如果您有项目想法,请分享。我们很乐意听取您的反馈 💖。
您想将您的库集成到 Hub 吗?
此集成通过 `huggingface_hub` 库实现。如果您想将您的库添加到 Hub,我们为您准备了指南!或者只需标记 Hugging Face 团队的某人即可。
向 Hugging Face 团队为此集成所做的一切工作致敬,特别是 @osanseviero 🦙。
感谢 fastlearners 和 hugging learners 🤗。
