将开源模型引入电子表格 🚀







只要我们能想象如何使用人工智能,它就能帮助记者做很多伟大的事情。这就是为什么我创建了一个简单但可能非常有用的工具:Hugging Face on Sheets,将开源人工智能模型引入电子表格。这个想法是让人们在他们熟悉的环境中使用人工智能,将其作为一个功能。
在记者和媒体组织其他专业人员的工具库中,电子表格是一个必不可少的工具——不仅用于处理数字,也用于处理文本。仔细想想,这与人工智能简直是天作之合,因为它们都是设计用于处理数据的工具。
这个项目有一天在我与一位经济学家朋友在操场上分享我对人工智能的惊奇时萌生了(我承认,这不一定是集思广益的最佳地点!)。他深思熟虑的回答让我回到了现实:“是的,人工智能很有趣。但作为在最著名的统计研究所工作的一名博士,我可以告诉你,我们95%的工作仍然在电子表格中完成。”
然而,人工智能从根本上改变了一件事:我们可以用我们自己的语言与机器对话。或者,正如 Andrej Karpathy 所说:“最热门的新编程语言是英语”。与电子表格对话、掌握公式等可能具有挑战性,这是我在向记者和学生教授数据新闻学时经常观察到的。
此外,聊天机器人是消费级产品,不一定是新闻等专业领域的最佳工具。使用电子表格,您可以处理大量数据,自动化任务,大海捞针,并以高度灵活和定制的方式处理数据集。
在电子表格中使用人工智能模型有很多优点:
- 无需代码
- 它是新闻工作流程中常用的工具
- 您可以操作各种类型的数据:文本、URL、日期、数字、图像...
- 您可以链接提示以定义复杂流程
- 您可以创建可复现和自动化的工作流程
- 在API速率限制内免费使用
我可能遗漏了一些其他论点;欢迎在评论中添加您的看法;)
为了帮助释放这些好处,我创建了一个脚本,您可以将其作为附加组件在 Google 表格中运行(我不是一个优秀的编码员,所以在构建它时得到了一些人工智能的帮助)。
这个工具开启了与数据交互的许多可能性,并支持诸如分类、提取、数据清洗、摘要、命名实体识别、翻译、正则表达式公式、删除个人信息等等分析任务!您可以考虑在不同列中链接提示,或者添加少量样本提示来改进您的结果。
此脚本允许您在 Hugging Face 上免费推理API支持的模型中选择您喜欢的模型,例如 Meta Llama 3 8B 和 70B、Mixtral 8x7B 等(在此处查看完整列表)。对于更高级的用途,您还可以设置自己的推理端点并访问更广泛的模型。
接下来,让我们看看三个具体的用例,了解 Hugging Face on Sheets 的实际应用。
1. 分类

让我们寓工作于娱乐,看看《熊家餐馆》第三季是否值得观看,根据烂番茄汇总的影评人评论。
我将它们导入到一个结构良好的表格中,包含作者、出版物和评论者列(感谢本帖范围之外的 importxml 公式)。然后,我在表格中创建了一个新列,使用以下单元格公式对其进行分类:
=HF(C2, "meta-llama/Meta-Llama-3-70B-Instruct", "逐步思考。1. 仅使用以下类别对这部影评进行分类:“积极”、“中立”、“消极”。2. 在您的答案中删除特殊字符、标签和大写字母。3. 清理最终结果,只用一个词回答。")
这是公式的分解:
HF是公式的名称C2是评论文本所在的单元格- 然后,我调用模型
- 最后,是我的提示。
您可以通过以下两个示例看到结果:
- 《熊家餐馆》第三季感觉像是一场过长的实验,并没有完全奏效。也许它会从卡米本季反复强调的一个不可妥协的原则中受益:减法。→ 消极
- 《熊家餐馆》在角色追求卓越专业和个人成长的过程中仍然找到了超然的时刻,但这部剧仍然比其热烈的赞誉所暗示的更容易犯错。→ 中立
你可能会想,为什么不写一个简单的提示,比如“使用三个类别对这部影评进行分类”呢?这是一个试错的问题,但在经过三次提示迭代后,我得到了一个干净的结果。专业提示:请LLM为您生成提示。有时它会更快、结构更好,至少为您提供了进一步完善的起点。
2. 提取

为了测试该工具在提取任务中的表现,我从 CNN Dailymail 数据集中抽取了一个样本,因为它非常适合新闻任务。这个英语数据集包含略多于30万篇由 CNN 和 Daily Mail 记者撰写的独特新闻文章。
第一次尝试,我写了以下提示:
=HF(A2, "meta-llama/Meta-Llama-3-70B-Instruct", "列出文本中提到的每个人名,用逗号分隔。只回答人名列表。排除特殊字符和标签。")
效果还不错,但有几个人名缺失了。有趣的是,我通过改变措辞得到了更好的结果:
=HF(A2, "meta-llama/Meta-Llama-3-70B-Instruct", "提取文本中提到的每个人名,用逗号分隔。只回答人名列表。排除特殊字符和标签。")
我还创建了另一个“丹尼尔·雷德克利夫/非丹尼尔·雷德克利夫”的列,询问模型这个名字是否出现在之前创建的列中。提示是:
=HF(B2, "meta-llama/Meta-Llama-3-70B-Instruct", "文本中是否提到‘丹尼尔·雷德克利夫’?逐步思考。1. 只用小写字母回答‘是’或‘否’。2. 删除答案中的所有其他内容(标签、特殊字符)。文本:")
您会注意到我以“文本:”结尾,以明确告诉模型文本在此提示之后开始。如果我们深入了解代码,调用提示的代码行如下:
const formattedPrompt = `<s> [INST] ${systemPrompt} ${prompt} [/INST] </s>`;
这将转换为:
<s> [INST] 文本中是否提到‘丹尼尔·雷德克利夫’?逐步思考。1. 只用小写字母回答‘是’或‘否’。2. 删除答案中的所有其他内容(标签、特殊字符)。文本:丹尼尔·雷德克利夫, 拉迪亚德·吉卜林, 彼得·沙弗尔, 哈利·波特, 杰克·吉卜林 [/INST] </s>`
作为发送到第一个单元格模型的输入。
与任何生成式AI工具一样,您需要迭代提示才能使其恰到好处。
顺便说一句,这个工具的默认系统提示是:
“你是一个乐于助人且诚实的助手。请简洁真实地回答。”
如果您编写新提示,此系统提示将被自动覆盖。根据您的用例,您可以手动将其添加到新提示的开头。在我的实验中,它有时会改进结果,有时则不会。
3. 脏数据
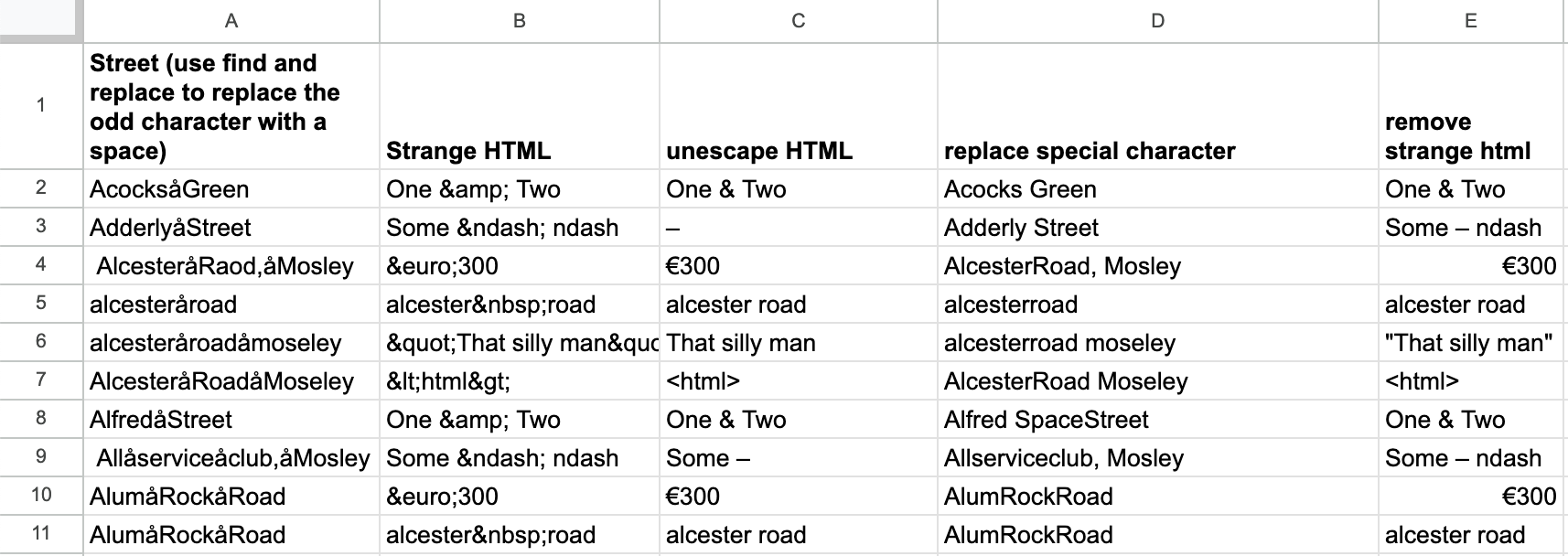
Paul Bradshaw 在他的文章《什么是脏数据以及如何清理?数据记者的大指南》中概述了新闻业中经常遇到的数据问题,包括不准确、不完整、不一致和不兼容。Hugging Face on Sheets 插件能帮助解决其中一些问题吗?
我尝试了一下,它在清理奇怪的 HTML 方面表现出色。它在从字符串中删除特殊字符方面也出奇地好,而这有时是 LLM 难以解决的问题(试试问你最喜欢的模型“strawberry”中有多少个“r”)。我还添加了一个额外步骤来规范字母的大小写。
=HF(C9, "meta-llama/Meta-Llama-3-70B-Instruct", "你是一个乐于助人的助手。我希望你删除以下文本中所有的字符“å”。请逐步思考:1. 找到字符“å”。2. 将它们替换为空格。3. 将单词首字母大写。4. 只给出最终答案。不要添加任何评论并删除特殊字符。")
显然,数据问题的范围可能千差万别,但我认为这种方法对于希望在进行更标准分析之前清理和整理数据的数据记者来说确实非常强大。
开源方法
这段代码基于开源模型,本身也是开源的,这意味着每个人都可以自由使用它,并且可以为其做出贡献!
自发布以来,我看到了社区的力量,有两个有趣的例子。Louis Brulé Naudet 改进了它,增加了直接在单元格中而不是在脚本中选择模型和提示的可能性,从而使该工具更具灵活性。本博客的编辑 Nick Diakopoulos 发现了提示链和 [/INST] 标签中的错误,显著改善了结果。
我最近看到了哥伦比亚大学新闻学教授 Jonathan Soma 开发的另一个有趣示例。他的示例将 Hugging Faces Hub 上特定任务的模型(而不是基础模型)用于零样本分类、标记分类、摘要或文本到图像等任务。
如何开始使用 Hugging Faces for Sheets
要开始使用,您需要:
- 注册或登录Hugging Face
- 在您的 Hugging Face 个人资料设置中获取您的 API 密钥(免费)
- 选择“细粒度令牌”>“生成令牌”
- 复制您的令牌
- 设置权限 > 选择“调用无服务器推理API”
- 如果您计划使用专用端点,也可以选择“调用推理端点”。
然后,在您的 Google 表格中:
- 点击“扩展程序”>“Apps 脚本”
- 用此脚本替换现有代码并保存。
- 回到表格中,您应该会看到一个名为“Hugging Sheets”的新标签页。
- 点击它并添加您的API密钥。
- 瞧!
接下来呢?
我可以想到许多可能的改进,并邀请您为这个项目做出贡献!
- 添加面向任务的模型,如摘要、图像生成、翻译等(在此处查看完整的任务列表)
- 在项目社区标签页中分享有趣的用例和高效的提示,以帮助每个人使用它。(如果您有想法,请与我分享示例!)
- 将其作为官方附加组件发布到 Google Marketplace,以便更轻松地安装。我已经研究过这个过程,不幸的是它相当繁琐!
最重要的是,让我们一起构想其他工具!我坚信新闻业需要掌握人工智能,开发量身定制的产品,并培养人工智能构建者而不是人工智能用户。
所以,请随时通过LinkedIn联系我,并加入Hugging Face 上的记者社区!
本文最初发表于新闻编辑室的生成式人工智能。感谢 Nicholas Diakopoulos 邀请我撰写本文!
Florent Daudens 是开源人工智能平台 Hugging Face 的新闻主管。他还在蒙特利尔大学教授数字新闻学,并提供新闻编辑室培训。他曾作为记者和主编在媒体工作超过15年,为加拿大新闻编辑室(如 Le Devoir 和 CBC/Radio-Canada)服务。
