使用遥感(卫星)图像和说明对CLIP进行微调










使用遥感(卫星)图像和说明对CLIP进行微调

今年七月,Hugging Face 组织了一场 Flax/JAX 社区周,并邀请社区提交项目,以训练 Hugging Face transformers 模型,领域涵盖自然语言处理 (NLP) 和计算机视觉 (CV)。
参与者使用张量处理单元 (TPU) 和 Flax 及 JAX。JAX 是一个线性代数库(类似 numpy),可以进行自动微分 (Autograd) 并编译成 XLA,而 Flax 是 JAX 的神经网络库和生态系统。TPU 计算时间由共同赞助本次活动的 Google Cloud 免费提供。
在接下来的两周里,团队参与了 Hugging Face 和 Google 的讲座,使用 JAX/Flax 训练了一个或多个模型,并与社区共享,还提供了 Hugging Face Spaces 演示,展示了其模型的功能。大约有 100 个团队参与了此次活动,共产生了 170 个模型和 36 个演示。
我们的团队,可能和许多其他团队一样,是一个分布式团队,横跨 12 个时区。我们的共同点是我们都属于 TWIML Slack 频道,我们因对人工智能 (AI) 和机器学习 (ML) 话题的共同兴趣而聚集在一起。
我们使用 RSICD 数据集 中的卫星图像和说明对 OpenAI 的 CLIP 网络 进行了微调。CLIP 网络通过使用从互联网上找到的文本与图像对进行自监督训练来学习视觉概念。在推理过程中,给定文本描述,模型可以预测最相关的图像;或者给定图像,预测最相关的文本描述。CLIP 功能强大,足以在日常图像上以零样本方式使用。然而,我们认为卫星图像与日常图像有足够大的不同,因此用卫星图像对其进行微调会很有用。我们的直觉是正确的,正如评估结果(下文所述)所示。在这篇文章中,我们将详细介绍我们的训练和评估过程,以及我们未来在该项目上的工作计划。
我们项目的目标是提供一项有用的服务,并演示如何将 CLIP 用于实际用例。我们的模型可用于应用程序,通过文本查询搜索大量的卫星图像。此类查询可以描述图像的整体(例如,海滩、山脉、机场、棒球场等),或搜索或提及这些图像中的特定地理或人造特征。CLIP 也可以类似地针对其他领域进行微调,正如 medclip-demo 团队 对医学图像所展示的那样。
能够通过文本查询搜索大量图像是一项极其强大的功能,既可以用于社会公益,也可以用于恶意目的。可能的应用包括国防和反恐活动,在气候变化影响变得难以控制之前发现并解决这些影响等。不幸的是,这种权力也可能被滥用,例如被威权国家用于军事和警察监视,因此它也确实引发了一些伦理问题。
您可以在我们的项目页面上阅读有关该项目的信息,下载我们训练好的模型以用于您自己的数据推理,或者在我们的演示中查看其效果。
训练
数据集
我们主要使用 RSICD 数据集 对 CLIP 模型进行微调。该数据集包含约 10,000 张图像,这些图像是从 Google Earth、Baidu Map、MapABC 和 Tianditu 收集的。它免费提供给研究社区,以通过 探索遥感图像说明生成的模型和数据 (Lu et al, 2017) 来推进遥感说明研究。图像为 (224, 224) RGB 图像,具有各种分辨率,每张图像最多有 5 个关联的说明。

此外,我们还使用了 UCM 数据集 和 悉尼数据集 进行训练。UCM 数据集基于 UC Merced 土地利用数据集。它包含 2100 张图像,属于 21 个类别(每个类别 100 张图像),每张图像有 5 个说明。悉尼数据集包含来自 Google Earth 的澳大利亚悉尼图像。它包含 613 张图像,属于 7 个类别。图像为 (500, 500) RGB,每张图像提供 5 个说明。我们使用这些额外的数据集,因为我们不确定 RSICD 数据集是否足够大以对 CLIP 进行微调。
模型
我们的模型是原始 CLIP 模型(如下所示)的微调版本。模型的输入是分别通过 CLIP 文本编码器和图像编码器传递的一批说明和一批图像。训练过程使用 对比学习 来学习图像和说明的联合嵌入表示。在这个嵌入空间中,图像及其各自的说明会相互靠近,类似的图像和类似的说明也是如此。相反,不同图像的图像和说明,或不相似的图像和说明,则可能被推得更远。
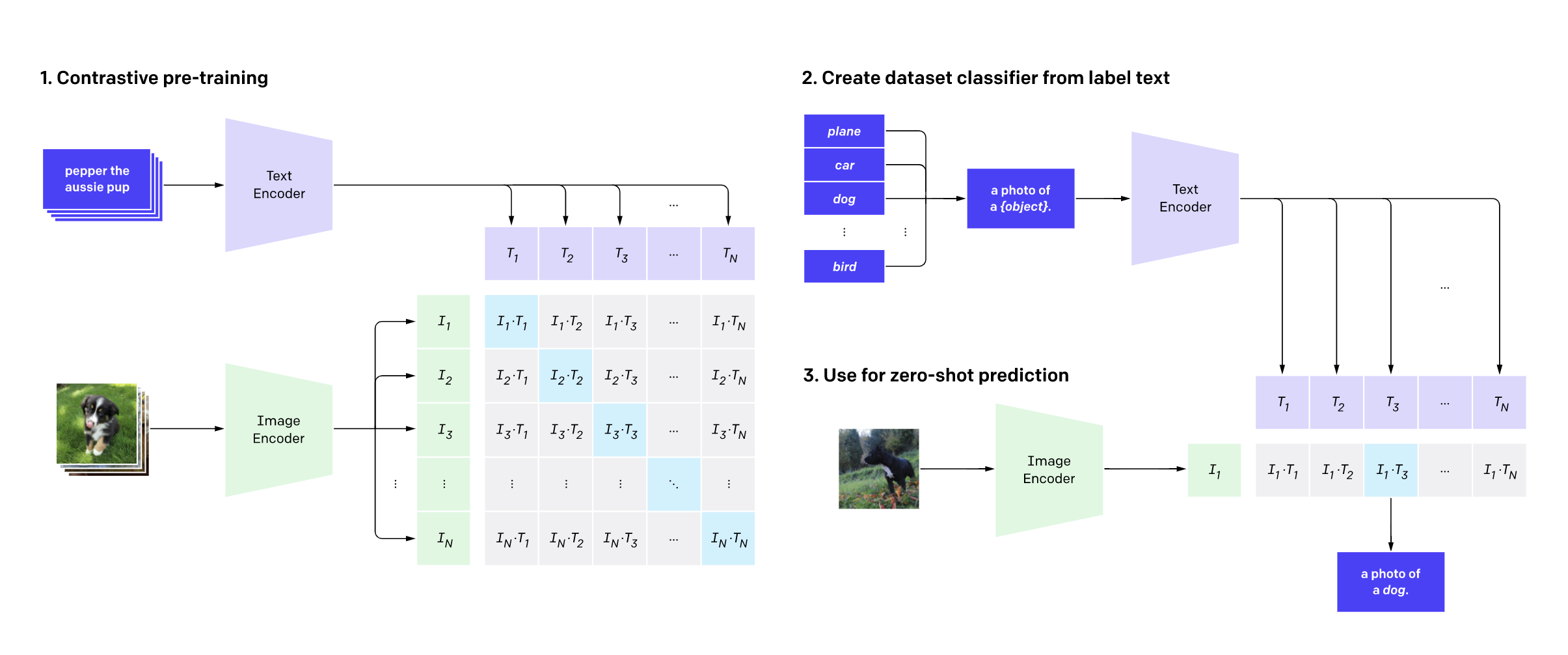
数据增强
为了对数据集进行正则化并防止由于数据集大小造成的过拟合,我们使用了图像和文本增强两种方法。
图像增强是使用 Pytorch 的 Torchvision 包中的内置转换进行内联完成的。使用的转换包括随机裁剪、随机调整大小和裁剪、颜色抖动以及随机水平和垂直翻转。
我们通过反向翻译增强了文本,以生成每张图像少于 5 个独特说明的图像的说明。Hugging Face 的 Marian MT 系列模型用于将现有说明翻译成法语、西班牙语、意大利语和葡萄牙语,然后再翻译回英语,以补充这些图像的说明。
如下图所示,图像增强显著减少了过拟合,而文本和图像增强则进一步减少了过拟合。
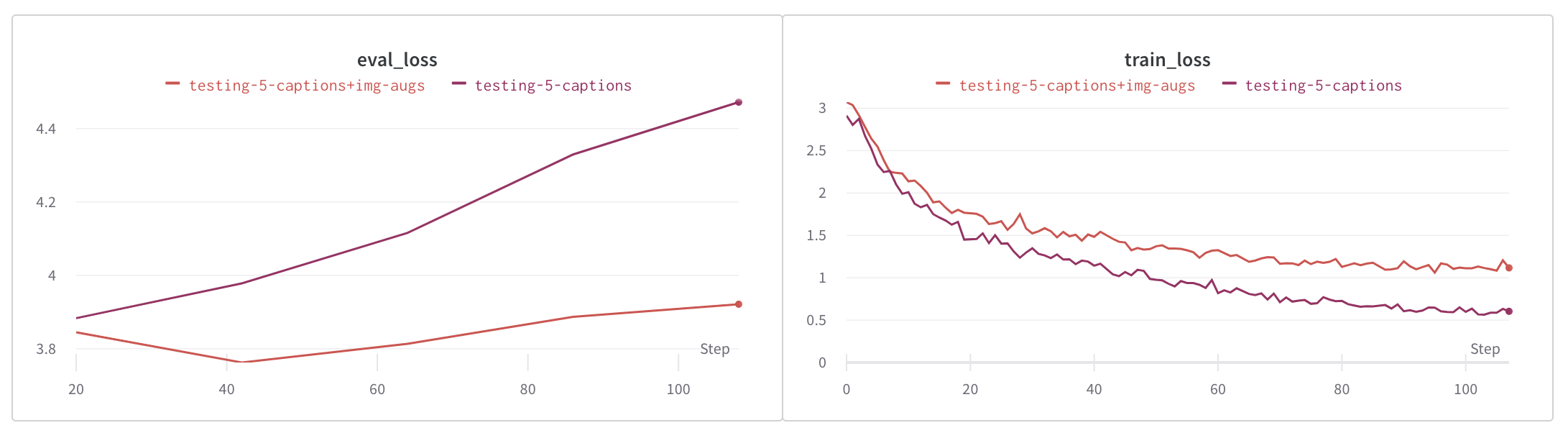
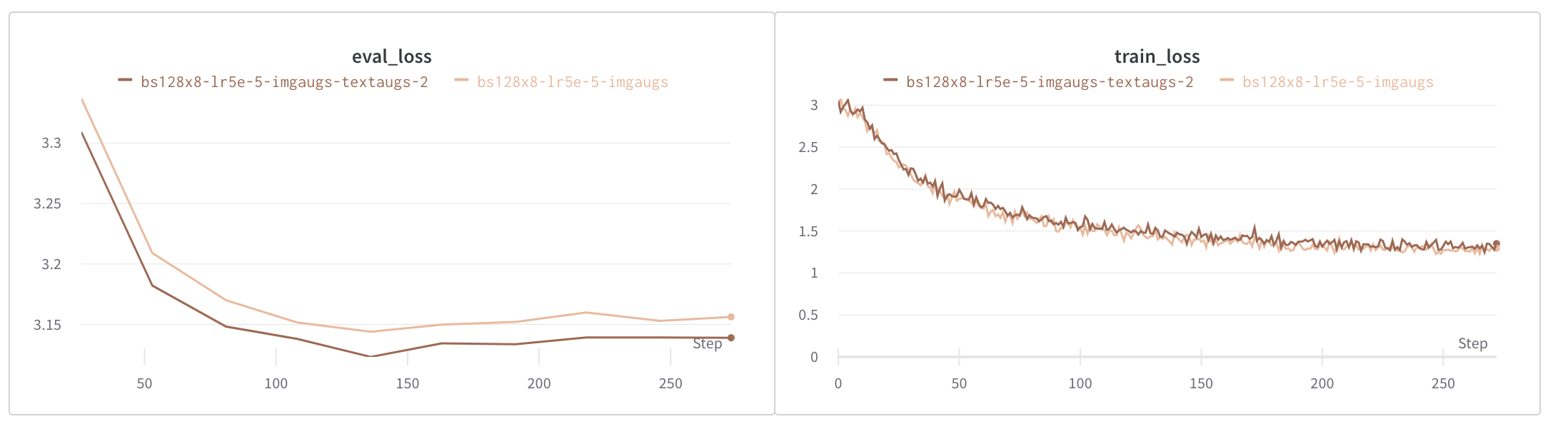
评估
指标
RSICD 测试集的子集用于评估。我们在此子集中发现了 30 种图像类别。评估通过将每张图像与一组 30 个形式为 "An aerial photograph of {category}" 的说明句子进行比较来完成。模型生成了 30 个说明的排序列表,从最相关到最不相关。对应于得分最高的 k 个说明(k=1、3、5 和 10)的类别与通过图像文件名提供的类别进行比较。分数在用于评估的整组图像上进行平均,并针对各种 k 值进行报告,如下所示。
baseline 模型代表预训练的 openai/clip-vit-base-path32 CLIP 模型。该模型使用 RSICD 数据集中的说明和图像进行微调,从而显著提升了性能,如下所示。
我们最好的模型是在图像和文本增强下训练的,批处理大小为 1024(8 个 TPU 核心上每个 128),并使用 Adam 优化器,学习率为 5e-6。我们的第二个基础模型使用相同的超参数训练,但我们使用了 Adafactor 优化器,学习率为 1e-4。您可以从下表中链接的模型存储库下载任一模型。
| 模型名称 | k=1 | k=3 | k=5 | k=10 |
|---|---|---|---|---|
| 基准 | 0.572 | 0.745 | 0.837 | 0.939 |
| bs128x8-lr1e-4-augs/ckpt-2 | 0.819 | 0.950 | 0.974 | 0.994 |
| bs128x8-lr1e-4-imgaugs/ckpt-2 | 0.812 | 0.942 | 0.970 | 0.991 |
| bs128x8-lr1e-4-imgaugs-textaugs/ckpt-42 | 0.843 | 0.958 | 0.977 | 0.993 |
| bs128x8-lr5e-5-imgaugs-textaugs/ckpt-8 | 0.831 | 0.959 | 0.977 | 0.994 |
| bs128x8-lr5e-5-imgaugs/ckpt-4 | 0.746 | 0.906 | 0.956 | 0.989 |
| bs128x8-lr5e-5-imgaugs-textaugs-2/ckpt-4 | 0.811 | 0.945 | 0.972 | 0.993 |
| bs128x8-lr5e-5-imgaugs-textaugs-3/ckpt-5 | 0.823 | 0.946 | 0.971 | 0.992 |
| bs128x8-lr5e-5-wd02/ckpt-4 | 0.820 | 0.946 | 0.965 | 0.990 |
| bs128x8-lr5e-6-adam/ckpt-11 | 0.883 | 0.968 | 0.982 | 0.998 |
1 - 我们最好的模型,2 - 我们第二好的模型
演示
您可以在这里访问 CLIP-RSICD 演示。它使用我们微调过的 CLIP 模型提供以下功能:
- 文本到图像搜索
- 图像到图像搜索
- 在图像中查找文本特征
前两个功能使用 RSICD 测试集作为其图像语料库。它们使用我们微调过的最佳 CLIP 模型进行编码,并存储在 NMSLib 索引中,该索引允许基于近似最近邻的检索。对于文本到图像和图像到图像搜索,查询文本或图像分别使用我们的模型进行编码,并与语料库中的图像向量进行匹配。对于第三个功能,我们将传入的图像分成多个补丁并对其进行编码,编码查询的文本特征,将文本向量与每个图像补丁向量进行匹配,并返回在每个补丁中找到该特征的概率。
未来工作
我们很高兴有机会进一步完善我们的模型。我们未来工作的一些想法如下:
- 使用 CLIP 编码器和 GPT-3 解码器构建一个序列到序列的模型,并将其训练用于图像字幕。
- 在来自其他数据集的更多图像字幕对上微调模型,并研究我们是否可以提高其性能。
- 调查微调如何影响模型在非 RSICD 图像字幕对上的性能。
- 调查微调模型对它未曾微调过的类别进行分类的能力。
- 使用其他标准(如图像分类)评估模型。


