使用 🤗 Transformers 对英文 ASR 进行 Wav2Vec2 微调







Wav2Vec2 是一种用于自动语音识别 (ASR) 的预训练模型,由 Alexei Baevski、Michael Auli 和 Alex Conneau 于 2020 年 9 月发布。
Wav2Vec2 使用新颖的对比预训练目标,从超过 50,000 小时的未标记语音中学习强大的语音表示。类似于 BERT 的掩码语言建模,该模型通过在将特征向量传递给 transformer 网络之前随机掩码它们来学习上下文语音表示。
首次证明,预训练后,在少量标记语音数据上进行微调可以达到与最先进的 ASR 系统相媲美的结果。仅使用 10 分钟的标记数据,Wav2Vec2 在 LibriSpeech 的纯净测试集上实现了低于 5% 的词错误率 (WER) - 参见 论文表 9。
在本笔记本中,我们将详细解释如何对任何英文 ASR 数据集微调 Wav2Vec2 的预训练检查点。请注意,在本笔记本中,我们将在不使用语言模型的情况下微调 Wav2Vec2。不使用语言模型作为端到端 ASR 系统使用 Wav2Vec2 要简单得多,并且已证明独立的 Wav2Vec2 声学模型取得了令人印象深刻的结果。出于演示目的,我们对大小为“base”的预训练检查点在相对较小的 Timit 数据集上进行微调,该数据集仅包含 5 小时的训练数据。
Wav2Vec2 使用连接时序分类 (CTC) 进行微调,这是一种用于训练神经网络解决序列到序列问题(主要在自动语音识别和手写识别中)的算法。
我强烈推荐阅读 Awni Hannun 撰写的写得非常好的博客文章 Sequence Modeling with CTC (2017)。
在开始之前,让我们从 master 安装 datasets 和 transformers。此外,我们需要 soundfile 包来加载音频文件,以及 jiwer 来使用 词错误率 (WER) 指标 评估我们微调的模型。
!pip install datasets>=1.18.3
!pip install transformers==4.11.3
!pip install librosa
!pip install jiwer
接下来,我们强烈建议在训练期间将您的训练检查点直接上传到 Hugging Face Hub。Hub 集成了版本控制,因此您可以确保在训练期间不会丢失任何模型检查点。
为此,您必须存储来自 Hugging Face 网站的身份验证令牌(如果您尚未注册,请在此处注册!)。
from huggingface_hub import notebook_login
notebook_login()
打印输出
Login successful
Your token has been saved to /root/.huggingface/token
Authenticated through git-crendential store but this isn't the helper defined on your machine.
You will have to re-authenticate when pushing to the Hugging Face Hub. Run the following command in your terminal to set it as the default
git config --global credential.helper store
然后您需要安装 Git-LFS 才能上传您的模型检查点
!apt install git-lfs
Timit 通常使用音素错误率 (PER) 进行评估,但到目前为止,ASR 中最常见的指标是词错误率 (WER)。为了使本笔记本尽可能通用,我们决定使用 WER 评估模型。
准备数据、分词器、特征提取器
ASR 模型将语音转写为文本,这意味着我们既需要一个将语音信号处理成模型输入格式(例如特征向量)的特征提取器,也需要一个将模型输出格式处理成文本的分词器。
在 🤗 Transformers 中,Wav2Vec2 模型因此附带了一个分词器,称为 Wav2Vec2CTCTokenizer,以及一个特征提取器,称为 Wav2Vec2FeatureExtractor。
让我们从创建负责解码模型预测的分词器开始。
创建 Wav2Vec2CTCTokenizer
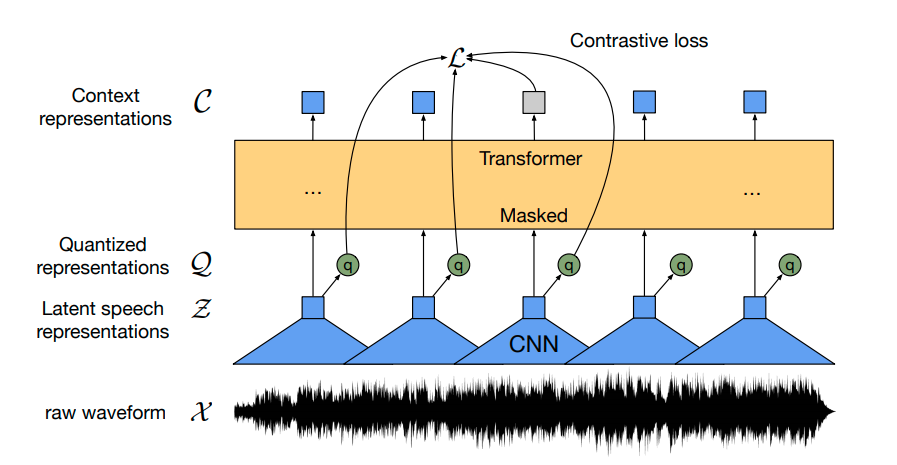
预训练的 Wav2Vec2 检查点将语音信号映射到一系列上下文表示,如上图所示。微调的 Wav2Vec2 检查点需要将这一系列上下文表示映射到其对应的转录,因此必须在 transformer 块(黄色所示)之上添加一个线性层。该线性层用于将每个上下文表示分类为一个标记类,类似于,例如,在预训练后,在 BERT 的嵌入之上添加一个线性层以进行进一步分类 - 参见 这篇博客文章的“BERT”部分。
此层的输出大小对应于词汇表中的标记数量,这**不**取决于 Wav2Vec2 的预训练任务,而仅取决于用于微调的标记数据集。因此,第一步,我们将查看 Timit 并根据数据集的转录定义词汇表。
让我们从加载数据集并查看其结构开始。
from datasets import load_dataset, load_metric
timit = load_dataset("timit_asr")
print(timit)
打印输出
DatasetDict({
train: Dataset({
features: ['file', 'audio', 'text', 'phonetic_detail', 'word_detail', 'dialect_region', 'sentence_type', 'speaker_id', 'id'],
num_rows: 4620
})
test: Dataset({
features: ['file', 'audio', 'text', 'phonetic_detail', 'word_detail', 'dialect_region', 'sentence_type', 'speaker_id', 'id'],
num_rows: 1680
})
})
许多 ASR 数据集仅提供每个音频文件 'file' 的目标文本 'text'。Timit 实际上提供了关于每个音频文件的更多信息,例如 'phonetic_detail' 等,这就是为什么许多研究人员在处理 Timit 时选择评估他们的模型在音素分类而不是语音识别方面的原因。但是,我们希望使笔记本尽可能通用,因此我们只考虑用于微调的转录文本。
timit = timit.remove_columns(["phonetic_detail", "word_detail", "dialect_region", "id", "sentence_type", "speaker_id"])
让我们写一个简短的函数来显示数据集的一些随机样本,并运行几次以感受一下转写文本的特点。
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
show_random_elements(timit["train"].remove_columns(["file", "audio"]))
打印输出
| 索引 | 转录 |
|---|---|
| 1 | 谁把皮划艇带到了河口? |
| 2 | 因此,它充当人们的锚。 |
| 3 | 她一整年都把你的深色西装放在油腻的洗涤水中。 |
| 4 | 我们不是酒鬼,她说。 |
| 5 | 最近的地质调查发现了地震活动。 |
| 6 | 赡养费损害了离婚男子的财富。 |
| 7 | 我们的整个经济将得到巨大的提升。 |
| 8 | 别让我带着那样的油腻抹布。 |
| 9 | 华丽的蝴蝶吃了大量的花蜜。 |
| 10 | 你要带我去哪儿? |
好的!转录看起来非常干净,语言似乎更像是书面文本而不是对话。考虑到 Timit 是一个朗读语音语料库,这很有道理。
我们可以看到转录中包含一些特殊字符,例如 ,.?!;:。如果没有语言模型,将语音块分类为这些特殊字符要困难得多,因为它们实际上不对应于特征声音单元。例如,字母 "s" 有一个或多或少清晰的声音,而特殊字符 "." 则没有。此外,为了理解语音信号的含义,通常不需要在转录中包含特殊字符。
此外,我们将文本标准化为仅包含小写字母。
import re
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"]'
def remove_special_characters(batch):
batch["text"] = re.sub(chars_to_ignore_regex, '', batch["text"]).lower()
return batch
timit = timit.map(remove_special_characters)
让我们看一下预处理后的转录。
show_random_elements(timit["train"].remove_columns(["file", "audio"]))
打印输出
| 索引 | 转录 |
|---|---|
| 1 | 总之,是时候给男孩加盐了 |
| 2 | 他们的基础似乎比单纯的权威更深 |
| 3 | 只有最好的球员才受欢迎 |
| 4 | 龙卷风经常摧毁数英亩的农田 |
| 5 | 你要带我去哪儿 |
| 6 | 感受当地风情 |
| 7 | 卫星 人造卫星 火箭 气球 下一个是什么 |
| 8 | 我给了他们几个选择,让他们自己设定优先级 |
| 9 | 在光线不足的地方阅读会让你眼睛疲劳 |
| 10 | 那只狗无情地追逐猫 |
很好!这看起来好多了。我们已经从转录中删除了大部分特殊字符,并将其规范化为全小写。
在 CTC 中,通常将语音块分类为字母,所以我们在这里也这样做。让我们提取训练和测试数据中所有不同的字母,并从这个字母集合构建我们的词汇表。
我们编写一个映射函数,将所有转录连接成一个长转录,然后将字符串转换为一组字符。重要的是将参数 batched=True 传递给 map(...) 函数,以便映射函数可以一次访问所有转录。
def extract_all_chars(batch):
all_text = " ".join(batch["text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocabs = timit.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=timit.column_names["train"])
现在,我们创建训练集和测试集中所有不同字母的并集,并将结果列表转换为一个带索引的字典。
vocab_list = list(set(vocabs["train"]["vocab"][0]) | set(vocabs["test"]["vocab"][0]))
vocab_dict = {v: k for k, v in enumerate(vocab_list)}
vocab_dict
打印输出
{
' ': 21,
"'": 13,
'a': 24,
'b': 17,
'c': 25,
'd': 2,
'e': 9,
'f': 14,
'g': 22,
'h': 8,
'i': 4,
'j': 18,
'k': 5,
'l': 16,
'm': 6,
'n': 7,
'o': 10,
'p': 19,
'q': 3,
'r': 20,
's': 11,
't': 0,
'u': 26,
'v': 27,
'w': 1,
'x': 23,
'y': 15,
'z': 12
}
很酷,我们看到字母表中的所有字母都出现在数据集中(这并不奇怪),而且我们还提取了特殊字符 " " 和 '。请注意,我们没有排除这些特殊字符,因为
- 模型必须学会预测何时一个单词结束,否则模型的预测将始终是一串字符,这将使得单词之间无法分离。
- 在英语中,我们需要保留
'字符来区分单词,例如,"it's"和"its",它们具有非常不同的含义。
为了更清楚地表明 " " 有其自己的标记类别,我们给它一个更明显的字符 |。此外,我们还添加了一个“未知”标记,以便模型以后可以处理在 Timit 训练集中未遇到的字符。
vocab_dict["|"] = vocab_dict[" "]
del vocab_dict[" "]
最后,我们还添加了一个与 CTC 的“空白标记”相对应的填充标记。“空白标记”是 CTC 算法的核心组件。欲了解更多信息,请参阅此处的“对齐”部分。
vocab_dict["[UNK]"] = len(vocab_dict)
vocab_dict["[PAD]"] = len(vocab_dict)
print(len(vocab_dict))
打印输出
30
酷,现在我们的词汇表已完成,包含 30 个标记,这意味着我们将添加到预训练 Wav2Vec2 检查点之上的线性层将具有 30 的输出维度。
现在让我们将词汇表保存为 json 文件。
import json
with open('vocab.json', 'w') as vocab_file:
json.dump(vocab_dict, vocab_file)
最后一步,我们使用 JSON 文件实例化一个 Wav2Vec2CTCTokenizer 类的对象。
from transformers import Wav2Vec2CTCTokenizer
tokenizer = Wav2Vec2CTCTokenizer("./vocab.json", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|")
如果想将刚刚创建的分词器与本笔记本中微调的模型重复使用,强烈建议将 tokenizer 上传到 🤗 Hub。我们将上传文件的仓库命名为 "wav2vec2-large-xlsr-turkish-demo-colab"
repo_name = "wav2vec2-base-timit-demo-colab"
然后将分词器上传到 🤗 Hub。
tokenizer.push_to_hub(repo_name)
太棒了,您可以在 https://huggingface.co/<your-username>/wav2vec2-base-timit-demo-colab 找到刚刚创建的仓库
创建 Wav2Vec2 特征提取器
语音是一种连续信号,要由计算机处理,首先必须将其离散化,这通常称为**采样**。采样率在此起着重要作用,因为它定义了每秒测量多少语音信号数据点。因此,更高的采样率会导致对*真实*语音信号的更好近似,但每秒也需要更多值。
预训练检查点期望其输入数据以或多或少与训练数据相同的分布进行采样。以两种不同速率采样的相同语音信号具有非常不同的分布,例如,采样率加倍会导致数据点长度加倍。因此,在对 ASR 模型的预训练检查点进行微调之前,验证用于预训练模型的数据的采样率是否与用于微调模型的数据集的采样率匹配至关重要。
Wav2Vec2 在 LibriSpeech 和 LibriVox 的音频数据上进行预训练,它们都以 16kHz 采样。我们的微调数据集 Timit 也很幸运地以 16kHz 采样。如果微调数据集以低于或高于 16kHz 的速率采样,我们首先必须对语音信号进行上采样或下采样,以匹配用于预训练的数据的采样率。
Wav2Vec2 特征提取器对象需要以下参数来实例化
feature_size:语音模型将特征向量序列作为输入。虽然此序列的长度显然不同,但特征大小不应改变。对于 Wav2Vec2,特征大小为 1,因为模型在原始语音信号上进行了训练 。sampling_rate: 模型训练时使用的采样率。padding_value:对于批量推理,较短的输入需要用特定值填充。do_normalize:输入是否应该进行零均值单位方差归一化。通常,语音模型在归一化输入后表现更好。return_attention_mask:模型是否应该在批量推理中使用attention_mask。通常,模型应该**始终**使用attention_mask来掩盖填充的标记。然而,由于Wav2Vec2的“base”检查点的一个非常特殊的设计选择,在不使用attention_mask时可以获得更好的结果。这**不**建议用于其他语音模型。欲了解更多信息,请参阅此问题。**重要**:如果要使用此笔记本微调large-lv60,则此参数应设置为True。
from transformers import Wav2Vec2FeatureExtractor
feature_extractor = Wav2Vec2FeatureExtractor(feature_size=1, sampling_rate=16000, padding_value=0.0, do_normalize=True, return_attention_mask=False)
太棒了,Wav2Vec2 的特征提取管道由此完全定义!
为了使 Wav2Vec2 的使用尽可能方便用户,特征提取器和分词器被包装到单个 Wav2Vec2Processor 类中,这样只需要一个 model 和 processor 对象。
from transformers import Wav2Vec2Processor
processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
数据预处理
到目前为止,我们还没有查看语音信号的实际值,只查看了转录。除了句子之外,我们的数据集还包含另外两个列名:路径和音频。路径表示音频文件的绝对路径。让我们看一下。
print(timit[0]["path"])
打印输出
'/root/.cache/huggingface/datasets/downloads/extracted/404950a46da14eac65eb4e2a8317b1372fb3971d980d91d5d5b221275b1fd7e0/data/TRAIN/DR4/MMDM0/SI681.WAV'
Wav2Vec2 期望输入为 16 kHz 的 1 维数组格式。这意味着必须加载并重新采样音频文件。
值得庆幸的是,数据集通过调用其他列音频自动完成了这项工作。让我们试一试。
common_voice_train[0]["audio"]
打印输出
{'array': array([-2.1362305e-04, 6.1035156e-05, 3.0517578e-05, ...,
-3.0517578e-05, -9.1552734e-05, -6.1035156e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/404950a46da14eac65eb4e2a8317b1372fb3971d980d91d5d5b221275b1fd7e0/data/TRAIN/DR4/MMDM0/SI681.WAV',
'sampling_rate': 16000}
我们可以看到音频文件已自动加载。这要归功于 datasets == 4.13.3 中引入的新的 "Audio" feature,它在调用时即时加载和重新采样音频文件。
采样率设置为 16kHz,这是 Wav2Vec2 所期望的输入。
太棒了,让我们听几段音频文件,以便更好地理解数据集并验证音频是否正确加载。
import IPython.display as ipd
import numpy as np
import random
rand_int = random.randint(0, len(timit["train"]))
print(timit["train"][rand_int]["text"])
ipd.Audio(data=np.asarray(timit["train"][rand_int]["audio"]["array"]), autoplay=True, rate=16000)
可以听到,说话者的语速、口音等都有变化。尽管如此,总体而言,录音听起来相对清晰,这对于朗读语音语料库来说是意料之中的。
让我们做最后一次检查,确认数据准备是否正确,通过打印语音输入的形状、其转写文本以及相应的采样率。
rand_int = random.randint(0, len(timit["train"]))
print("Target text:", timit["train"][rand_int]["text"])
print("Input array shape:", np.asarray(timit["train"][rand_int]["audio"]["array"]).shape)
print("Sampling rate:", timit["train"][rand_int]["audio"]["sampling_rate"])
打印输出
Target text: she had your dark suit in greasy wash water all year
Input array shape: (52941,)
Sampling rate: 16000
好的!一切看起来都没问题——数据是一维数组,采样率总是 16kHz,目标文本也已规范化。
最后,我们可以将数据集处理成模型训练所需的格式。我们将使用 map(...) 函数。
首先,我们通过简单地调用 batch["audio"] 来加载和重新采样音频数据。其次,我们从加载的音频文件中提取 input_values。在我们的例子中,Wav2Vec2Processor 仅对数据进行归一化。然而,对于其他语音模型,此步骤可能包括更复杂的特征提取,例如 对数梅尔频率倒谱系数提取。第三,我们将转录编码为标签 ID。
注意:此映射函数是 Wav2Vec2Processor 类如何使用的很好的例子。在“正常”情况下,调用 processor(...) 会重定向到 Wav2Vec2FeatureExtractor 的调用方法。然而,当将处理器包装到 as_target_processor 上下文中时,相同的方法会重定向到 Wav2Vec2CTCTokenizer 的调用方法。有关更多信息,请查阅文档。
def prepare_dataset(batch):
audio = batch["audio"]
# batched output is "un-batched" to ensure mapping is correct
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
with processor.as_target_processor():
batch["labels"] = processor(batch["text"]).input_ids
return batch
让我们将数据准备函数应用到所有样本上。
timit = timit.map(prepare_dataset, remove_columns=timit.column_names["train"], num_proc=4)
注意:目前 datasets 使用 torchaudio 和 librosa 进行音频加载和重采样。如果您希望实现自己的自定义数据加载/采样,请随意只使用 "path" 列并忽略 "audio" 列。
训练与评估
数据已处理,因此我们准备好开始设置训练管道。我们将使用 🤗 的 Trainer,为此我们主要需要执行以下操作
定义数据整理器。与大多数 NLP 模型不同,Wav2Vec2 的输入长度远大于输出长度。例如,输入长度为 50000 的样本的输出长度不超过 100。鉴于输入尺寸较大,动态填充训练批次效率更高,这意味着所有训练样本都应仅填充到其批次中最长的样本,而不是总体最长的样本。因此,微调 Wav2Vec2 需要一个特殊的填充数据整理器,我们将在下面定义。
评估指标。在训练期间,模型应以词错误率进行评估。我们应该相应地定义一个
compute_metrics函数。加载预训练检查点。我们需要加载预训练检查点并对其进行正确配置以进行训练。
定义训练配置。
在微调模型后,我们将在测试数据上对其进行正确评估,并验证它确实学会了正确转写语音。
设置训练器
让我们首先定义数据整理器。数据整理器的代码是从这个示例中复制的。
不深入细节,与常见的数据整理器不同,此数据整理器对 input_values 和 labels 进行不同的处理,因此对其应用单独的填充函数(再次利用 Wav2Vec2 的上下文管理器)。这是必要的,因为在语音中,输入和输出是不同的模态,这意味着它们不应由相同的填充函数处理。类似于常见的数据整理器,标签中的填充标记用 -100 填充,以便在计算损失时**不**考虑这些标记。
import torch
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.Wav2Vec2Processor`)
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
max_length (:obj:`int`, `optional`):
Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
max_length_labels (:obj:`int`, `optional`):
Maximum length of the ``labels`` returned list and optionally padding length (see above).
pad_to_multiple_of (:obj:`int`, `optional`):
If set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
7.5 (Volta).
"""
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
max_length: Optional[int] = None
max_length_labels: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
pad_to_multiple_of_labels: Optional[int] = None
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="pt",
)
with self.processor.as_target_processor():
labels_batch = self.processor.pad(
label_features,
padding=self.padding,
max_length=self.max_length_labels,
pad_to_multiple_of=self.pad_to_multiple_of_labels,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
return batch
让我们初始化数据整理器。
data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
接下来,定义评估指标。如前所述,ASR 中最主要的指标是词错误率 (WER),因此我们在这个 notebook 中也使用它。
wer_metric = load_metric("wer")
模型将返回一个 logits 向量序列
,
其中 和 。
一个 logits 向量 包含我们之前定义的词汇表中每个词的对数几率,因此 config.vocab_size。我们对模型最有可能的预测感兴趣,因此取 logits 的 argmax(...)。此外,我们通过将 -100 替换为 pad_token_id 并解码 ID,同时确保连续的标记**不**以 CTC 样式 分组来将编码的标签转换回原始字符串。
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
现在,我们可以加载预训练的 Wav2Vec2 检查点。分词器的 pad_token_id 必须定义模型的 pad_token_id,或者在 Wav2Vec2ForCTC 的情况下,也定义 CTC 的空白标记 。为了节省 GPU 内存,我们启用了 PyTorch 的 梯度检查点,并将损失减少设置为“mean”。
from transformers import Wav2Vec2ForCTC
model = Wav2Vec2ForCTC.from_pretrained(
"facebook/wav2vec2-base",
ctc_loss_reduction="mean",
pad_token_id=processor.tokenizer.pad_token_id,
)
打印输出
Some weights of Wav2Vec2ForCTC were not initialized from the model checkpoint at facebook/wav2vec2-base and are newly initialized: ['lm_head.weight', 'lm_head.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Wav2Vec2 的第一个组件由一系列 CNN 层组成,这些层用于从原始语音信号中提取具有声学意义但与上下文无关的特征。模型的这一部分在预训练期间已经得到了充分训练,并且如论文所述,不再需要进行微调。因此,我们可以将特征提取部分的所有参数的 requires_grad 设置为 False。
model.freeze_feature_extractor()
最后一步,我们定义所有与训练相关的参数。对其中一些参数进行更多解释:
group_by_length通过将输入长度相似的训练样本分组到一个批次中,使训练更高效。这可以通过大大减少通过模型的无用填充标记的总数来显著加快训练时间learning_rate和weight_decay经过启发式调整,直到微调变得稳定。请注意,这些参数强烈依赖于 Timit 数据集,可能不适用于其他语音数据集。
关于其他参数的更多解释,可以查看文档。
训练期间,每 400 个训练步骤会将一个检查点异步上传到 Hub。这允许您在模型仍在训练时也可以使用演示小部件。
注意:如果不想将模型检查点上传到 Hub,只需设置 push_to_hub=False。
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir=repo_name,
group_by_length=True,
per_device_train_batch_size=32,
evaluation_strategy="steps",
num_train_epochs=30,
fp16=True,
gradient_checkpointing=True,
save_steps=500,
eval_steps=500,
logging_steps=500,
learning_rate=1e-4,
weight_decay=0.005,
warmup_steps=1000,
save_total_limit=2,
)
现在,所有实例都可以传递给 Trainer,我们准备开始训练了!
from transformers import Trainer
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=timit_prepared["train"],
eval_dataset=timit_prepared["test"],
tokenizer=processor.feature_extractor,
)
为了使模型独立于说话者语速,在 CTC 中,连续的相同标记简单地被分组为单个标记。然而,在解码时,编码的标签不应分组,因为它们不对应于模型的预测标记,这就是为什么必须传递 group_tokens=False 参数。如果我们不传递此参数,像 "hello" 这样的词将被错误地编码并解码为 "helo"。 空白标记允许模型预测一个词,例如 "hello",通过强制它在两个 l 之间插入空白标记。我们模型对 "hello" 的符合 CTC 的预测将是 [PAD] [PAD] "h" "e" "e" "l" "l" [PAD] "l" "o" "o" [PAD]。
训练
训练将需要 90 到 180 分钟,具体取决于分配给此笔记本的 Google Colab 的 GPU。虽然训练好的模型在 Timit 的测试数据上取得了令人满意的结果,但它绝不是一个最优微调的模型。本笔记本的目的是演示如何对 Wav2Vec2 的 base、large 和 large-lv60 检查点在任何英语数据集上进行微调。
如果您想使用此 Google Colab 微调您的模型,您应该确保您的训练不会因为不活动而停止。一个简单的防止方法是将以下代码粘贴到此标签的控制台中(右键单击 -> 检查 -> 控制台选项卡并插入代码)。
function ConnectButton(){
console.log("Connect pushed");
document.querySelector("#top-toolbar > colab-connect-button").shadowRoot.querySelector("#connect").click()
}
setInterval(ConnectButton,60000);
trainer.train()
根据您的 GPU,这里可能会出现 "内存不足" 错误。在这种情况下,最好将 per_device_train_batch_size 减少到 16 或更少,并最终使用 gradient_accumulation。
打印输出
| 步骤 | 训练损失 | 验证损失 | 词错误率 (WER) | 运行时 | 每秒样本数 |
|---|---|---|---|---|---|
| 500 | 3.758100 | 1.686157 | 0.945214 | 97.299000 | 17.266000 |
| 1000 | 0.691400 | 0.476487 | 0.391427 | 98.283300 | 17.093000 |
| 1500 | 0.202400 | 0.403425 | 0.330715 | 99.078100 | 16.956000 |
| 2000 | 0.115200 | 0.405025 | 0.307353 | 98.116500 | 17.122000 |
| 2500 | 0.075000 | 0.428119 | 0.294053 | 98.496500 | 17.056000 |
| 3000 | 0.058200 | 0.442629 | 0.287299 | 98.871300 | 16.992000 |
| 3500 | 0.047600 | 0.442619 | 0.285783 | 99.477500 | 16.888000 |
| 4000 | 0.034500 | 0.456989 | 0.282200 | 99.419100 | 16.898000 |
最终 WER 应低于 0.3,考虑到最先进的音素错误率 (PER) 略低于 0.1(参见排行榜),并且 WER 通常比 PER 差,这是合理的。
您现在可以将训练结果上传到 Hub,只需执行此指令
trainer.push_to_hub()
你现在可以和所有的朋友、家人、心爱的宠物分享这个模型:他们都可以用“your-username/the-name-you-picked”这个标识符来加载它,例如:
from transformers import AutoModelForCTC, Wav2Vec2Processor
model = AutoModelForCTC.from_pretrained("patrickvonplaten/wav2vec2-base-timit-demo-colab")
processor = Wav2Vec2Processor.from_pretrained("patrickvonplaten/wav2vec2-base-timit-demo-colab")
评估
最后一部分,我们将在测试集上评估我们的微调模型并进行一些尝试。
让我们加载 processor 和 model。
processor = Wav2Vec2Processor.from_pretrained(repo_name)
model = Wav2Vec2ForCTC.from_pretrained(repo_name)
现在,我们将使用 map(...) 函数来预测每个测试样本的转录,并将预测保存到数据集本身中。我们将结果字典称为 "results"。
注意:由于此问题,我们故意以 batch_size=1 评估测试数据集。由于填充输入不会产生与非填充输入完全相同的输出,因此通过完全不填充输入可以获得更好的 WER。
def map_to_result(batch):
with torch.no_grad():
input_values = torch.tensor(batch["input_values"], device="cuda").unsqueeze(0)
logits = model(input_values).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_str"] = processor.batch_decode(pred_ids)[0]
batch["text"] = processor.decode(batch["labels"], group_tokens=False)
return batch
results = timit["test"].map(map_to_result, remove_columns=timit["test"].column_names)
现在让我们计算整体 WER。
print("Test WER: {:.3f}".format(wer_metric.compute(predictions=results["pred_str"], references=results["text"])))
打印输出
Test WER: 0.221
22.1% WER - 不错!我们的演示模型可能已经登上了官方排行榜。
让我们看看一些预测,了解模型犯了哪些错误。
打印输出
show_random_elements(results.remove_columns(["speech", "sampling_rate"]))
| 预测字符串 | 目标文本 |
|---|---|
| 旨在平衡您的员工福利待遇 | 旨在平衡您的员工福利待遇 |
| 大雾阻碍了他们准时到达 | 大雾阻碍了他们准时到达 |
| 幼儿应避免接触传染病 | 幼儿应避免接触传染病 |
| 人工智能是真的 | 人工智能是真的 |
| 他们的道具是两个梯子、一把椅子和一个棕榈扇 | 他们的道具是两个梯子、一把椅子和一个棕榈扇 |
| 如果人们更慷慨,就不需要福利了 | 如果人们更慷慨,就不需要福利了 |
| 鱼儿开始在小湖水面上疯狂跳跃 | 鱼儿开始在小湖水面上疯狂跳跃 |
| 她的右手一到气压变化就疼 | 她的右手一到气压变化就疼 |
| 只有律师爱百万富翁 | 只有律师爱百万富翁 |
| 最近的离经叛道者可能不在步行范围内 | 最近的犹太教堂可能不在步行范围内 |
很明显,预测的转录在声学上与目标转录非常相似,但经常包含拼写或语法错误。这并不令人惊讶,因为我们完全依赖 Wav2Vec2,而没有使用语言模型。
最后,为了更好地理解 CTC 的工作原理,值得更深入地研究模型的精确输出。让我们通过模型运行第一个测试样本,获取预测的 ID 并将其转换为相应的标记。
model.to("cuda")
with torch.no_grad():
logits = model(torch.tensor(timit["test"][:1]["input_values"], device="cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
# convert ids to tokens
" ".join(processor.tokenizer.convert_ids_to_tokens(pred_ids[0].tolist()))
打印输出
[PAD] [PAD] [PAD] [PAD] [PAD] [PAD] t t h e e | | b b [PAD] u u n n n g g [PAD] a [PAD] [PAD] l l [PAD] o o o [PAD] | w w a a [PAD] s s | | [PAD] [PAD] p l l e e [PAD] [PAD] s s e n n t t t [PAD] l l y y | | | s s [PAD] i i [PAD] t t t [PAD] u u u u [PAD] [PAD] [PAD] a a [PAD] t t e e e d d d | n n e e a a a r | | t h h e | | s s h h h [PAD] o o o [PAD] o o r r [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
该输出应该更清楚地说明 CTC 在实践中是如何工作的。该模型在某种程度上不受语速的影响,因为它已经学会了在需要分类的语音块仍然对应于同一个标记时,简单地重复相同的标记。这使得 CTC 成为语音识别的强大算法,因为语音文件的转录通常与其长度非常无关。
我再次建议读者查看这篇非常好的博客文章,以便更好地理解 CTC。












