嵌入式学习入门







查看此教程和配套的 Notebook:
理解嵌入
嵌入是对一段信息的数值表示,例如文本、文档、图像、音频等。这种表示捕获了被嵌入内容的语义含义,使其在许多行业应用中具有鲁棒性。
给定文本“投票的主要好处是什么?”,该句子的嵌入可以表示在向量空间中,例如,一个包含 384 个数字的列表(例如,[0.84, 0.42, ..., 0.02])。由于这个列表捕获了含义,我们可以做一些令人兴奋的事情,例如计算不同嵌入之间的距离,以确定两个句子的含义匹配程度。
嵌入不限于文本!您还可以创建图像的嵌入(例如,一个包含 384 个数字的列表),并将其与文本嵌入进行比较,以确定句子是否描述了图像。这个概念是图像搜索、分类、描述等强大系统的基础!
嵌入是如何生成的?一个名为 Sentence Transformers 的开源库允许您免费从图像和文本创建最先进的嵌入。本博客将展示一个使用此库的示例。
嵌入的作用是什么?
"[...] 一旦你理解了这个机器学习多功能工具(嵌入),你将能够构建从搜索引擎到推荐系统,再到聊天机器人等等。你不需要是具有机器学习专业知识的数据科学家才能使用它们,也不需要庞大的标注数据集。" - Dale Markowitz,Google Cloud。
一旦一段信息(一个句子、一个文档、一张图片)被嵌入,创造力就开始了;一些有趣的工业应用使用了嵌入。例如,Google 搜索使用嵌入来匹配文本到文本和文本到图片;Snapchat 使用它们来“在正确的时间向正确的用户投放正确的广告”;Meta(Facebook)使用它们进行社交搜索。
在能够从嵌入中获取智能之前,这些公司必须嵌入它们的信息。一个嵌入式数据集允许算法快速搜索、排序、分组等等。然而,这可能很昂贵且技术复杂。在这篇文章中,我们使用简单的开源工具来展示嵌入和分析数据集是多么容易。
嵌入式学习入门
我们将创建一个小型常见问题解答(FAQs)引擎:接收用户的查询,并确定哪个常见问题最相似。我们将使用美国社会保障医疗保险常见问题解答。
但首先,我们需要嵌入我们的数据集(其他文本可互换使用编码和嵌入这两个术语)。Hugging Face 推理 API 允许我们通过简单的 POST 调用轻松嵌入数据集。
由于嵌入捕获了问题的语义含义,因此可以比较不同的嵌入并查看它们之间的差异或相似程度。因此,您可以获得与查询最相似的嵌入,这相当于找到最相似的常见问题解答。查看我们的语义搜索教程,了解此机制如何工作的更详细解释。
简而言之,我们将
- 使用推理 API 嵌入 Medicare 的常见问题。
- 将嵌入式问题上传到 Hub 进行免费托管。
- 将客户的查询与嵌入式数据集进行比较,以确定哪个是与查询最相似的常见问题。
1. 嵌入数据集
第一步是选择一个现有的预训练模型来创建嵌入。我们可以从 Sentence Transformers 库中选择一个模型。在这种情况下,让我们使用 "sentence-transformers/all-MiniLM-L6-v2",因为它是一个小而强大的模型。在未来的文章中,我们将研究其他模型及其权衡。
登录到 Hub。您必须在账户设置中创建一个写入令牌。我们将把写入令牌存储在 `hf_token` 中。
model_id = "sentence-transformers/all-MiniLM-L6-v2"
hf_token = "get your token in https://huggingface.co/settings/tokens"
要生成嵌入,您可以使用 `https://api-inference.huggingface.co/pipeline/feature-extraction/{model_id}` 端点,并带有头信息 `{"Authorization": f"Bearer {hf_token}"}`。下面是一个接收包含文本的字典并返回包含嵌入列表的函数。
import requests
api_url = f"https://api-inference.huggingface.co/pipeline/feature-extraction/{model_id}"
headers = {"Authorization": f"Bearer {hf_token}"}
首次生成嵌入时,API 返回嵌入可能需要一段时间(大约 20 秒)。我们使用 `retry` 装饰器(通过 `pip install retry` 安装),这样如果在第一次尝试时 `output = query(dict(inputs = texts))` 不起作用,则等待 10 秒并再尝试三次。发生这种情况是因为在第一次请求时,模型需要下载并安装到服务器上,但随后的调用会快得多。
def query(texts):
response = requests.post(api_url, headers=headers, json={"inputs": texts, "options":{"wait_for_model":True}})
return response.json()
当前的 API 不强制执行严格的速率限制。相反,Hugging Face 会在所有可用资源之间均匀分配负载,并倾向于稳定的请求流。如果您需要嵌入多个文本或图像,Hugging Face 加速推理 API 将加快推理速度,并允许您选择使用 CPU 或 GPU。
texts = ["How do I get a replacement Medicare card?",
"What is the monthly premium for Medicare Part B?",
"How do I terminate my Medicare Part B (medical insurance)?",
"How do I sign up for Medicare?",
"Can I sign up for Medicare Part B if I am working and have health insurance through an employer?",
"How do I sign up for Medicare Part B if I already have Part A?",
"What are Medicare late enrollment penalties?",
"What is Medicare and who can get it?",
"How can I get help with my Medicare Part A and Part B premiums?",
"What are the different parts of Medicare?",
"Will my Medicare premiums be higher because of my higher income?",
"What is TRICARE ?",
"Should I sign up for Medicare Part B if I have Veterans' Benefits?"]
output = query(texts)
作为响应,您将获得一个列表的列表。每个列表都包含一个常见问题解答的嵌入。模型 "sentence-transformers/all-MiniLM-L6-v2" 将输入问题编码为 13 个大小为 384 的嵌入。让我们将该列表转换为一个形状为 (13x384) 的 Pandas `DataFrame`。
import pandas as pd
embeddings = pd.DataFrame(output)
它类似于这个矩阵
[[-0.02388945 0.05525852 -0.01165488 ... 0.00577787 0.03409787 -0.0068891 ]
[-0.0126876 0.04687412 -0.01050217 ... -0.02310316 -0.00278466 0.01047371]
[ 0.00049438 0.11941205 0.00522949 ... 0.01687654 -0.02386115 0.00526433]
...
[-0.03900796 -0.01060951 -0.00738271 ... -0.08390449 0.03768405 0.00231361]
[-0.09598278 -0.06301168 -0.11690582 ... 0.00549841 0.1528919 0.02472013]
[-0.01162949 0.05961934 0.01650903 ... -0.02821241 -0.00116556 0.0010672 ]]
2. 在 Hugging Face Hub 上免费托管嵌入
🤗 Datasets 是一个用于快速访问和共享数据集的库。让我们使用用户界面(UI)在 Hub 中托管嵌入数据集。然后,任何人都可以用一行代码加载它。您还可以使用终端共享数据集;请参阅文档了解步骤。在本条目的配套笔记本中,您将能够使用终端共享数据集。如果您想跳过本节,请查看包含嵌入式常见问题的 `ITESM/embedded_faqs_medicare` 存储库。
首先,我们将嵌入从 Pandas `DataFrame` 导出到 CSV。您可以以任何您喜欢的方式保存数据集,例如 zip 或 pickle;您不需要使用 Pandas 或 CSV。由于我们的嵌入文件不大,我们可以将其存储在 CSV 中,`datasets.load_dataset()` 函数在下一节中将轻松推断出它(请参阅数据集文档),即我们不需要创建加载脚本。我们将把嵌入保存为 `embeddings.csv`。
embeddings.to_csv("embeddings.csv", index=False)
按照以下步骤在 Hub 中托管 `embeddings.csv`。
- 点击 Hub UI 右上角的用户图标。
- 使用“新建数据集”创建数据集。
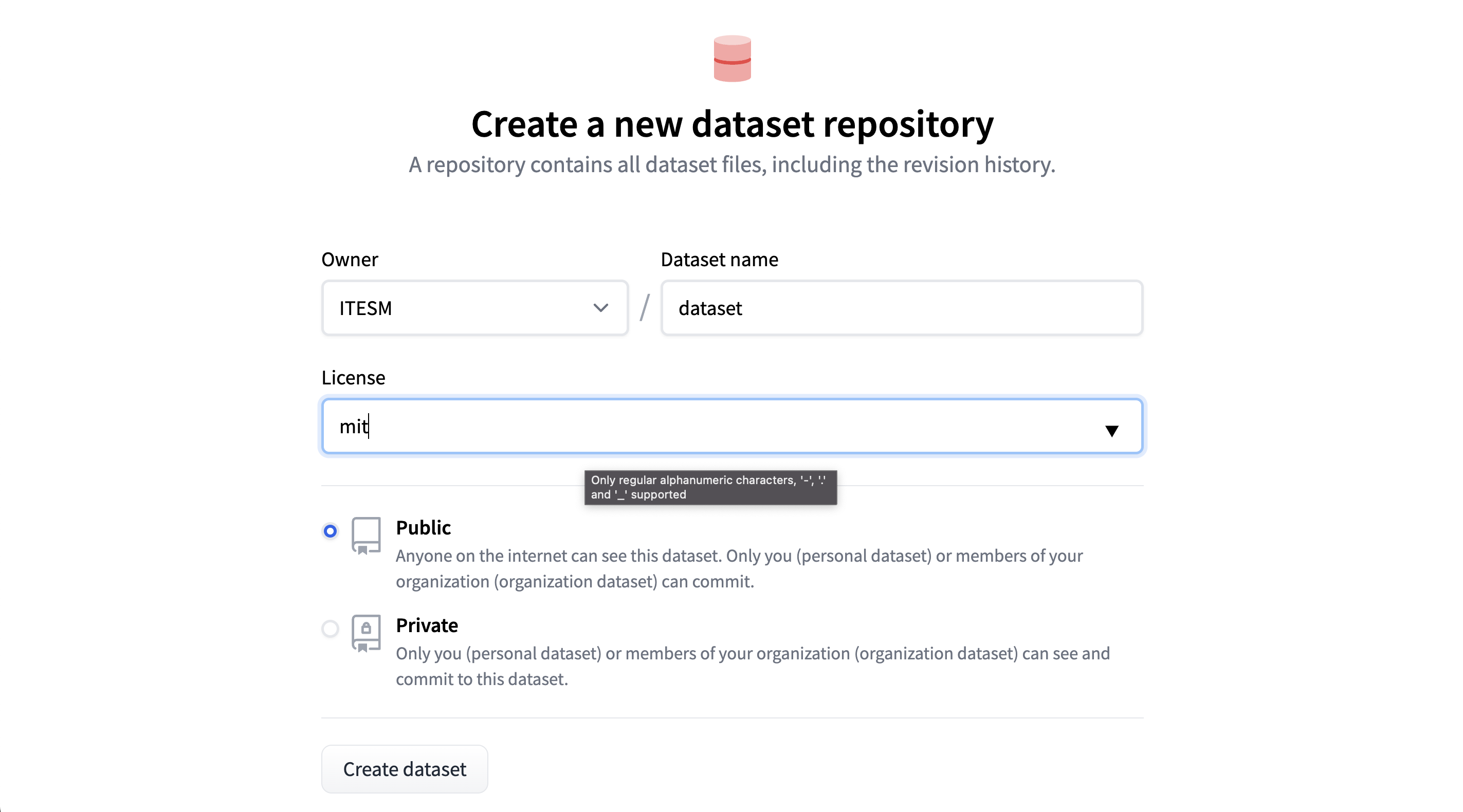
- 选择数据集的所有者(组织或个人)、名称和许可证。选择您希望它是私有还是公开。创建数据集。
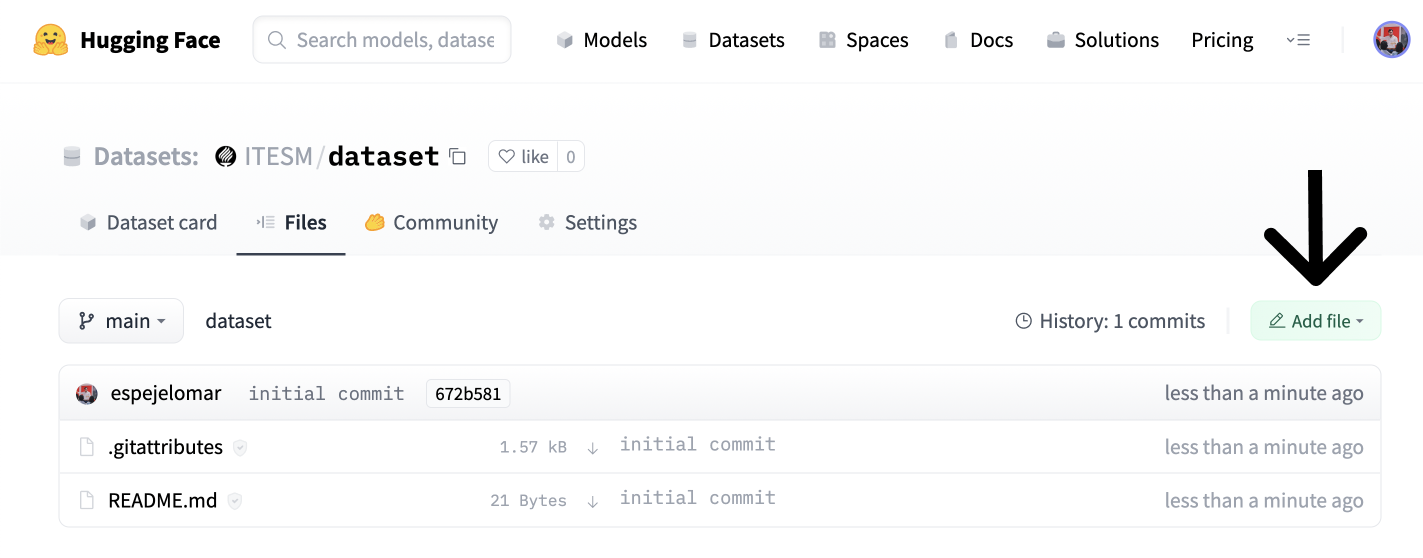
- 转到“文件”选项卡(如下图所示),然后单击“添加文件”和“上传文件”。
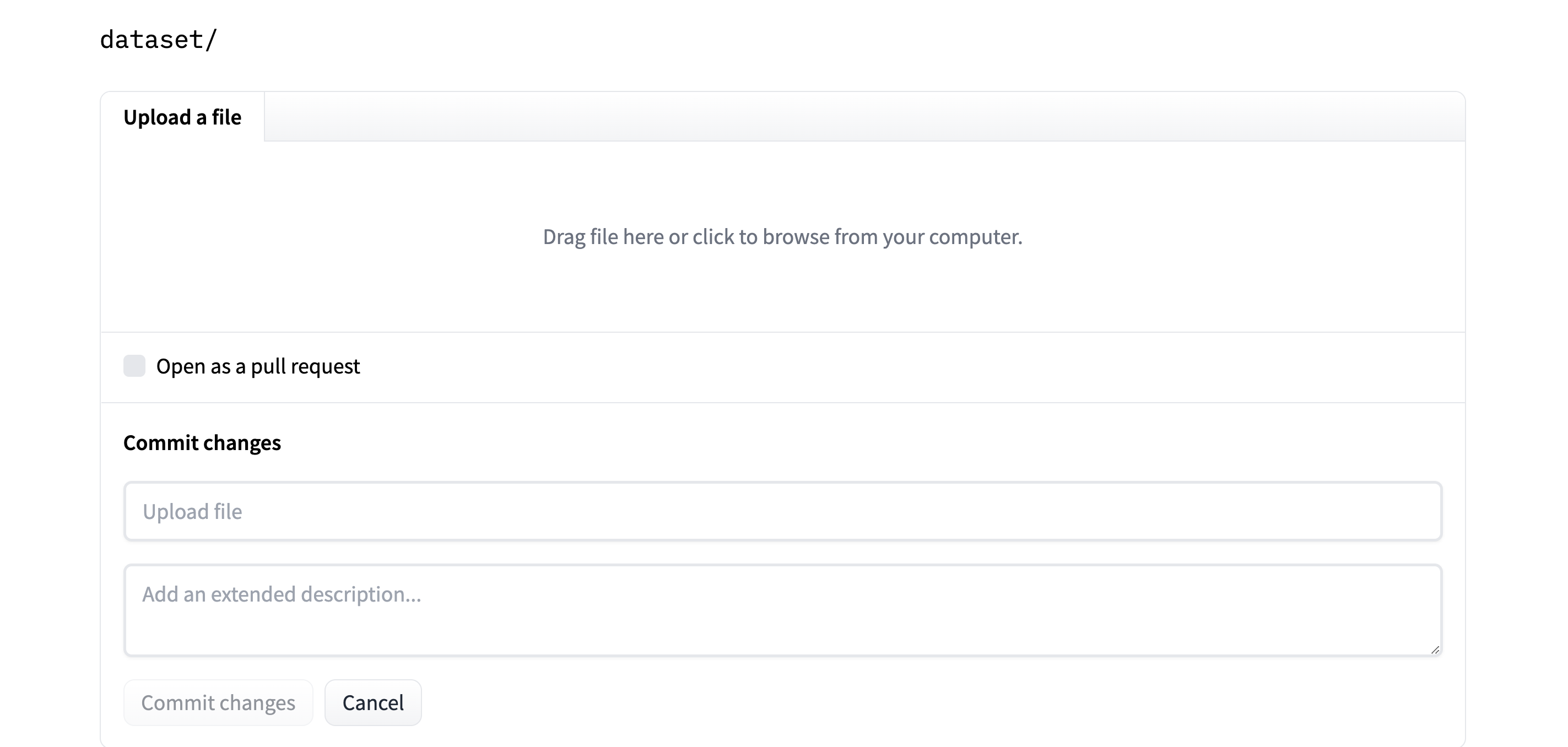
- 最后,拖放或上传数据集,并提交更改。
现在数据集已免费托管在 Hub 上。您(或任何您希望共享嵌入的人)都可以快速加载它们。让我们看看如何操作。
3. 获取与查询最相似的常见问题
假设一位 Medicare 客户询问:“Medicare 如何帮助我?”。我们将**找到**我们的哪些常见问题最能回答用户的查询。我们将创建一个查询的嵌入,它可以代表其语义含义。然后,我们将其与 FAQ 数据集中的每个嵌入进行比较,以确定在向量空间中哪个嵌入最接近查询。
使用 `pip install datasets` 安装 🤗 Datasets 库。然后,从 Hub 加载嵌入式数据集并将其转换为 PyTorch `FloatTensor`。请注意,这不是操作 `Dataset` 的唯一方法;例如,您可以使用 NumPy、Tensorflow 或 SciPy(请参阅文档)。如果您想使用真实数据集进行练习,`ITESM/embedded_faqs_medicare` 存储库包含嵌入式 FAQ,或者您可以使用本博客的配套笔记本。
import torch
from datasets import load_dataset
faqs_embeddings = load_dataset('namespace/repo_name')
dataset_embeddings = torch.from_numpy(faqs_embeddings["train"].to_pandas().to_numpy()).to(torch.float)
我们使用之前定义的查询函数来嵌入客户的问题,并将其转换为 PyTorch `FloatTensor` 以便高效操作。请注意,加载嵌入数据集后,我们可以使用 `Dataset` 的 `add_faiss_index` 和 `search` 方法,使用 faiss 库来识别最接近嵌入查询的常见问题。这里有一个不错的替代教程。
question = ["How can Medicare help me?"]
output = query(question)
query_embeddings = torch.FloatTensor(output)
您可以使用 Sentence Transformers 库中的 `util.semantic_search` 函数来识别哪些常见问题(FAQs)与用户的查询最接近(最相似)。此函数默认使用余弦相似度作为确定嵌入接近度的函数。但是,您也可以使用其他函数来测量向量空间中两点之间的距离,例如点积。
使用 `pip install -U sentence-transformers` 安装 `sentence-transformers`,并搜索与查询最相似的五个常见问题。
from sentence_transformers.util import semantic_search
hits = semantic_search(query_embeddings, dataset_embeddings, top_k=5)
`util.semantic_search` 识别 13 个常见问题中每个问题与客户查询的接近程度,并返回一个包含最靠前的 `top_k` 个常见问题的字典列表。`hits` 看起来像这样
[{'corpus_id': 8, 'score': 0.75653076171875},
{'corpus_id': 7, 'score': 0.7418993711471558},
{'corpus_id': 3, 'score': 0.7252674102783203},
{'corpus_id': 9, 'score': 0.6735571622848511},
{'corpus_id': 10, 'score': 0.6505177617073059}]
`corpus_id` 中的值允许我们索引在第一部分中定义的 `texts` 列表,并获得五个最相似的常见问题
print([texts[hits[0][i]['corpus_id']] for i in range(len(hits[0]))])
以下是与客户查询最接近的 5 个常见问题:
['How can I get help with my Medicare Part A and Part B premiums?',
'What is Medicare and who can get it?',
'How do I sign up for Medicare?',
'What are the different parts of Medicare?',
'Will my Medicare premiums be higher because of my higher income?']
此列表代表与客户查询最接近的 5 个常见问题。很棒!我们在这里主要使用了 PyTorch 和 Sentence Transformers 作为数值工具。但是,我们也可以使用 NumPy 和 SciPy 等工具自行定义余弦相似度和排名函数。
更多学习资源
如果您想了解更多关于 Sentence Transformers 库的信息
- Hub 组织,获取所有新模型和下载模型的说明。
- Nils Reimers 的推文,比较了 Sentence Transformer 模型与 GPT-3 嵌入。剧透:Sentence Transformers 非常棒!
- Sentence Transformers 文档,
- Nima 的推文串,关于最近的研究。
感谢阅读!








