2024年视觉语言模型设计选择








插图:Truisms (Jenny Holzer, 1977–79)
视觉与语言模型是**AI**领域的新兴热门,以**非常**快的速度带来了令人惊叹的成果。
有些很大,有些很小,有些是非常复杂的机器,有些则非常简单,有些只能处理一张图片,有些可以处理长达一小时的视频,还有一些也可以生成图片。
我们可以从所有这些不同的模型中学到的是它们做出的选择以及所产生的效果。特别是,在这篇博客文章中,我们将通过描述视觉语言模型近期发展中一些流行的设计来关注视觉和语言的自动理解。如果想了解更多关于视觉语言模型的实践性文章,请查阅Merve Noyan和Edward Beeching在HuggingFace上的博客文章。
共享潜在空间中的视觉与语言
CLIP是一个简单而有效的框架,它共同学习视觉编码器和文本编码器,训练它们将图像和文字投影到共享的潜在空间中,使得图像与其文字描述彼此接近。

插图:CLIP 对比预训练 (OpenAI Blog)
它是大多数最新多模态视觉语言模型的基本构建模块,例如,在文本条件图像生成(如所有Stable Diffusion模型)中用作文本编码器,或在语言和视觉聊天机器人(如LLaVA)中用作图像编码器。
在旨在理解语言和视觉的框架中,CLIP的ViT图像编码器(或更新的CLIP启发技术,如SigLIP)通常被用作视觉骨干网络。
一个关键优势是CLIP的ViT中的潜在 token 表示可能具有某种跨模态 / 联觉能力,因为它们已经**大部分**与它们的描述对齐。
**“大部分”**,因为图像的潜在表示与文本的潜在表示对齐,这些文本经过了分词器和 Transformer 编码器,而在大多数情况下,编码后的图像会与新嵌入的文本 token 一起输入到语言模型中。
为了使视觉 token 与文本 token 重新对齐,并(可选地)压缩、聚焦或选择将转发到语言模型的视觉信息,编码后的图像 token 会由“视觉抽象器”模型处理。
利用“视觉抽象器”对预训练模型进行整合和对齐
当使用CLIP的图像编码器时,图像大多已与文本预先对齐,我们只需将CLIP的潜在表示映射到文本 token 嵌入,使用一个最小的投影层,该层将在图像/文字描述对上进行训练。这正是LLaVA框架背后的思想。
 插图:LLaVA 架构 (LLaVA 博客)
插图:LLaVA 架构 (LLaVA 博客)
作者将这种映射称为“投影”,它在图像/文字描述对上进行训练,同时保持视觉和语言模型冻结。这种投影和语言模型在“视觉指令微调”阶段进行调整,这是第二个更昂贵的训练阶段,旨在训练模型遵循视觉任务指令。
在最初的LLaVA中,这个抽象器是一个简单的线性投影。在随后的版本(LLaVA 1.5和1.6/NeXT)中,它被替换为更具表现力的多层感知机(MLP)。
尽管这种“投影”策略简约有效,但其缺点是保留了编码图像的token数量,即ViT的个token。对于某些应用(例如视频理解),token总数可能会暴涨,并且高度冗余。在这种情况下,“视觉抽象器”可以在固定的token预算下从不同数量的图像中选择信息,常用的选择是Q-Former(BLIP-2)或Perceiver Resampler(Flamingo)抽象器。两者都使用学习到的查询和注意力来选择给定token预算下的显著视觉信息,但Q-Former也受输入文本的条件限制。
Cha 等人更深入地研究了其他视觉抽象器策略,基于卷积神经网络(C-Abstractor)或可变形注意力(D-Abstractor),以及允许选择输出 token 数量的自适应平均池化。
Li 等人提出,对于视频理解,每个帧只保留两个 token:一个只编码帧信息(称为“内容”token),另一个则以输入文本为条件,旨在编码上下文信息(称为“上下文”token)。
所有这些想法都依赖于对多个预训练模型进行对齐和过滤,以利用它们的多模态能力。
合并模态的方法有很多:Alayrac 等人选择在 Transformer 块之间使用门控交叉注意力来处理Flamingo,而对于LLaVA,Liu 等人更倾向于将视觉嵌入作为新 token 添加到语言模型中,并保持其架构不变。
根据选择的不同,图像可以被视为文本 token 可以引用的附加信息,也可以被视为一堆可以与文本 token 连接并以类似方式处理的 token。如果推向极端,后者类似于将图像建模为一种外语。
图像是一种外语吗?
正如Dosovitskiy 等人通过他们的 ViT 模型经验证明的那样,图像可以使用与文本相同的架构进行处理,并达到最先进的性能。图像被分割成小块,这些小块被嵌入并由语言模型处理,就像它们是文本 token 一样。实际上,图像变成了一种外语,而Wang 等人则非常字面地测试了这一点。他们的BeiT 3 模型遵循 ViT 架构,并具有多模态特性,因为该模型从头开始训练,图像和文本 token 在同一模型中处理,但使用不同的专家。
Adept 的Fuyu框架介于对齐预训练模型和使用所有模态训练模型之间。他们通过将图像 patch 嵌入直接输入语言模型来简化架构和训练过程。有了这个框架,无需考虑如何扩展视觉编码器与语言模型,也无需考虑训练阶段的顺序,并且模型能够处理不同分辨率的图像。这最后一个特性后来被Li 等人在其 OtterHD 模型中进行了改进。
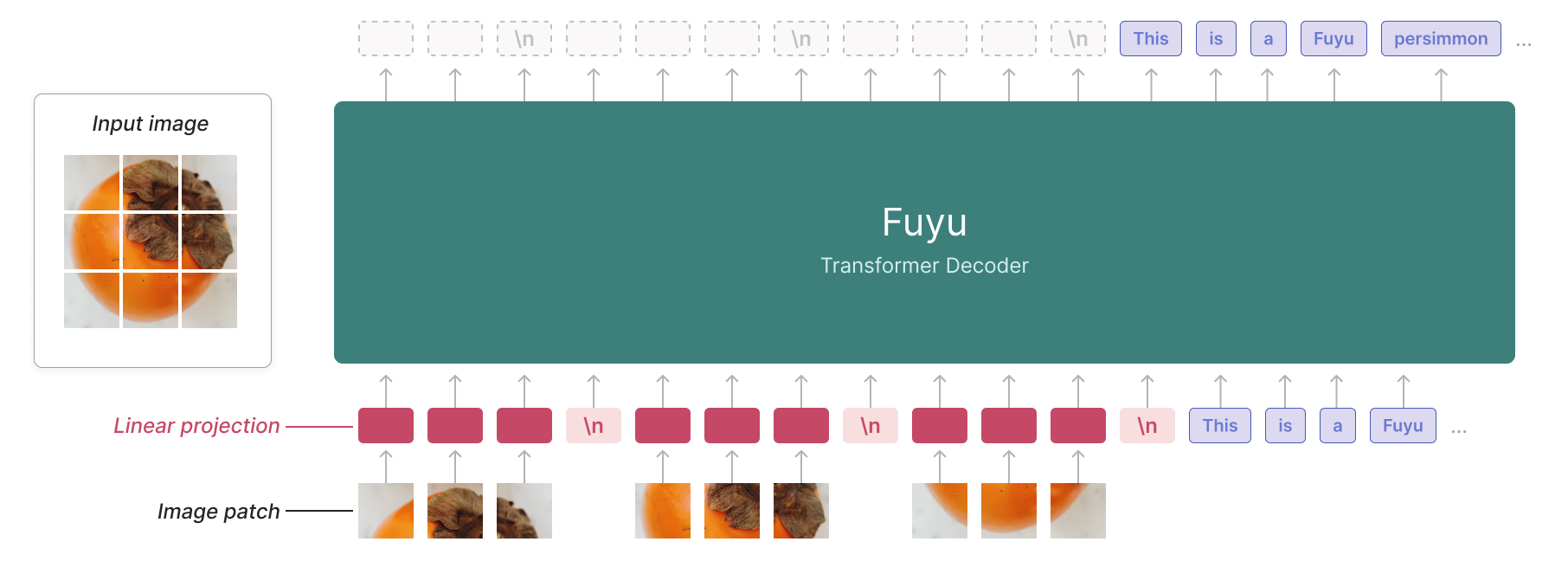 插图:Fuyu 架构 (Adept 博客)
插图:Fuyu 架构 (Adept 博客)
作者声称 Fuyu 框架“更容易理解、扩展和部署”,但没有提供有关所用数据量或训练此类模型的成本的信息。如果其成本比 LLaVA 框架高出几个数量级,而结果却相当,那也毫不奇怪。
图像**是**外语吗?粒度论
我们可能需要思考的一个方面是模态的粒度。
Alayrac 等人早期关于多模态模型的工作提出根据模态的粒度在不同点合并模态。音频和视觉被视为细粒度,而文本则更粗粒度。
论文写道
这一策略基于观察,即视觉和音频空间是细粒度的(吉他有许多不同的视觉或声音),而文本域则更粗粒度,因为其目标是抽象掉细节(例如,一个简单的“吉他”单词)。
这个想法支持首先对图像进行预处理,例如,在使用图像编码器之后将结果嵌入馈送到语言模型。
然而,我们确定知道视觉相对于文本的细粒度程度吗?并且所有文本 token 都具有相同的粒度吗?
有人可能会争辩说,一些在不同语境下具有多种含义的词,与例如停用词相比,具有不同的粒度。一个可以朝这个方向解释的例子是Raposo 等人最近的 Mixture-of-Depths 工作,它表明并非所有 token 都需要相同的模型深度。
并非所有视觉 token 都像文档和真实世界图片那样细粒度。
在这种情况下,也许更好的解决方案是直接将所有内容一次性输入模型,让它自行判断每个 token 需要多少处理。
融会贯通
总结一下我们目前讨论的视觉语言模型设计
视觉编码策略:
- 预训练视觉编码器:利用预训练且已对齐的模型(例如 LLaVA)
- 原始图像块:无信息丢失,端到端训练(例如 Fuyu)
视觉语言对齐策略:
- 投影:将视觉嵌入映射以与语言模型对齐(例如 LLaVA)
- 重采样:将所有视觉信息重采样为固定数量的 token(例如 Flamingo)
- 文本条件重采样:根据文本查询将所有视觉信息重采样为固定数量的 token(例如 BLIP-2)
多模态融合策略:
- 交错视觉和语言 token:将视觉嵌入作为文本嵌入进行处理(例如 LLaVA)
- 模态专家:语言和视觉嵌入由语言模型中的不同专家处理(例如 BeiT 3)
- 交叉注意力:语言 token 可以使用 Transformer 块之间的交叉注意力来关注图像嵌入(例如 Flamingo)。这种策略在最近的视觉语言模型开发中大多被弃用,很可能是因为它引入了大量新参数。
以下是一些开源视觉语言模型的例子(参见这篇博客文章)及其选择:
| 模型名称 | 视觉编码策略 | 视觉-语言对齐策略 | 多模态融合策略 |
|---|---|---|---|
LLaVA-NeXT (llava-v1.6-vicuna-7b) |
预训练视觉编码器 (clip-vit-large-patch14-336) |
投影 (MLP) | 交错视觉和语言 token |
DeepSeek-VL (deepseek-vl-7b-base) |
两个预训练视觉编码器 (ViT-SO400M-14-SigLIP-384 和 sam-vit-base) |
投影 (MLP) | 交错视觉和语言 token |
moondream2 (moondream2) |
预训练视觉编码器 (ViT-SO400M-14-SigLIP-384) |
投影 (MLP) | 交错视觉和语言 token |
CogVLM (cogvlm-base-490-hf) |
预训练视觉编码器 (EVA02_CLIP_E) |
投影 (MLP) | 模态专家 |
Fuyu-8B (fuyu-8b) |
原始图像块 | 投影 (线性) | 交错视觉和语言 token |
Kosmos-2 (kosmos-2-patch14-224) |
预训练视觉编码器 (clip-vit-large-patch14-336) |
重采样 | 交错视觉和语言 token |
Qwen-VL (Qwen-VL) |
预训练视觉编码器 (CLIP-ViT-g-14-laion2B-s12B-b42K) |
重采样 | 交错视觉和语言 token |
Yi-VL (Yi-VL-34B) |
预训练视觉编码器 (CLIP-ViT-H-14-laion2B-s32B-b79K) |
投影 (MLP) | 交错视觉和语言 token |
Idefics (idefics-80b) |
预训练视觉编码器 (CLIP-ViT-H-14-laion2B-s32B-b79K) |
重采样 | 交叉注意力 |
Idefics 2 (idefics2-8b) |
预训练视觉编码器 (siglip-so400m-patch14-384) |
重采样 | 交错视觉和语言 token |
哪种决策最适合不同的用例?
一个重要的决定是我们将视觉语言模型建立在哪些预训练模型之上。我们并没有真正讨论基础语言模型,但它们的上下文大小和语言能力(它能处理哪些语言?它能读写代码吗?)在下游性能中至关重要。同样,如果存在预训练的视觉编码器,其图像分辨率兼容性在某些任务中可能会成为问题,以及其训练的领域(照片、文档?),都是需要考虑的关键属性。
整个视觉语言模型架构的设计选择也需要考虑到下游用例。
在视频理解任务中,使用投影对齐策略可能导致大量输入 token 且存在大量冗余。在有限的上下文长度预算下,重采样(文本条件或非文本条件)可能是一种经济高效的方式,专注于视觉输入中最显著的信息。
对于需要关注输入图像中细微细节的任务,可以考虑裁剪部分输入,同时输入多个分辨率,或者舍弃整个预训练图像编码器,以便更容易地适应不同分辨率。
当涉及到训练所得模型时,所用数据集的选择也至关重要,它将影响模型在某些任务上的表现,例如无OCR文档理解或视觉提示理解。
基准测试如何?
基准测试可能有助于做出选择,但目前,针对视觉语言模型设计选择的大规模实验很少,且偏向于图像字幕任务。
由于常见评估的性质主要针对字幕问题(8个基准测试中有3个是字幕),字幕数据显著提升了零样本性能。
(摘自MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training)
模型基准测试结果对于比较视觉语言模型设计也没有太大启发性,因为它们基于不同性能的语言模型和视觉编码器,并且使用了非常不同的计算量和数据进行训练。
尽管如此,以下是一些在某些基准测试上比较现有视觉语言模型的方法:
- OpenVLM 排行榜显示了各种模型在不同视觉语言基准上的分数。
- Vision Arena根据用户的盲选投票给出视觉语言模型的 Elo 评分。
视觉语言模型何去何从?
显然,没有人能确切知道。但是我们可以从痛苦的教训中得到一些启示:所有这些巧妙地利用和对齐不同模态的预训练模型,以及过滤和聚焦视觉内容以适应给定 token 预算的技巧,都只是临时解决方案。在某个时候,我们可能会拥有端到端训练的模型,它们能够根据越来越庞大的数据集的统计数据自行解决所有问题。例如,Fuyu-MoD式(无限上下文)模型。
目前,我们最好深思熟虑地做出选择,以便在有限的训练预算和计算条件下设计出对不同任务有用的视觉语言模型。





