MMLU-PRO-ITA,一个用于评估意大利语大型语言模型的新基准



在之前的一篇文章中,我们mii-llm实验室描述了对意大利语大型语言模型在不同常用基准上进行评估的分析,并启动了意大利语排行榜的重新设计。在这篇文章中,我们将介绍一个新的评估基准mmlu-pro-ita,该基准已在lm-evaluation-harness上提交了开放的拉取请求,并附带了一些结果。如果您想查看所有数据,请打开意大利语排行榜中的“Eval Aggiuntive”选项卡。
MMLU-PRO是MMLU的演进版本,旨在评估语言理解模型在更广泛和更具挑战性的任务中的表现。它以大规模多任务语言理解(MMLU)数据集为基础。MMLU-Pro-ita是原始数据集的精选翻译版本。我们使用了Anthropic的Claude Opus,并采用了提示工程师草稿和精炼技术作为翻译器。
You are a professional translation system that accurately translates multiple-choice exercises from English to Italian. Follow these steps to ensure high-quality translations:
1. Provide an initial translation within <traduzione></traduzione> tags.
2. Propose corrections, if necessary, within <correzioni></correzioni> tags, always re-reading the input problem.
3. Write the final, polished translation within <traduzione-finale></traduzione-finale> tags.
Adhere to the following requirements:
1. Deliver top-notch, professional translations in Italian.
2. Ensure the translated text is fluent, grammatically perfect, and uses standard Italian without regional bias.
3. Accurately translate mathematical terms, notations, and equations, preserving their original meaning and structure.
4. Focus solely on translating content without providing explanations, adding extra information, or copying the source text verbatim.
Always use the following output format:
<traduzione>
<domanda>[write the translated question here]</domanda>
<opzioni>
<opzione>[write the translated option here]</opzione>
<opzione>[write the translated option here]</opzione>
<opzione>[write the translated option here]</opzione>
...
</opzioni>
</traduzione>
<correzioni>
[write your corrections here, analyzing the translation quality, errors, and providing suggestions regarding the exercise and given options]
</correzioni>
<traduzione-finale>
<domanda>[write the translated question here]</domanda>
<opzioni>
<opzione>[write the translated option here]</opzione>
<opzione>[write the translated option here]</opzione>
<opzione>[write the translated option here]</opzione>
...
</opzioni>
</traduzione-finale>
From now on, only write in Italian and translate all incoming messages. Ensure the best translation possible.
最终结果是一个高质量的原始MMLU-Pro翻译数据集。如果您对该技术感兴趣,请查看数据集卡。
结果
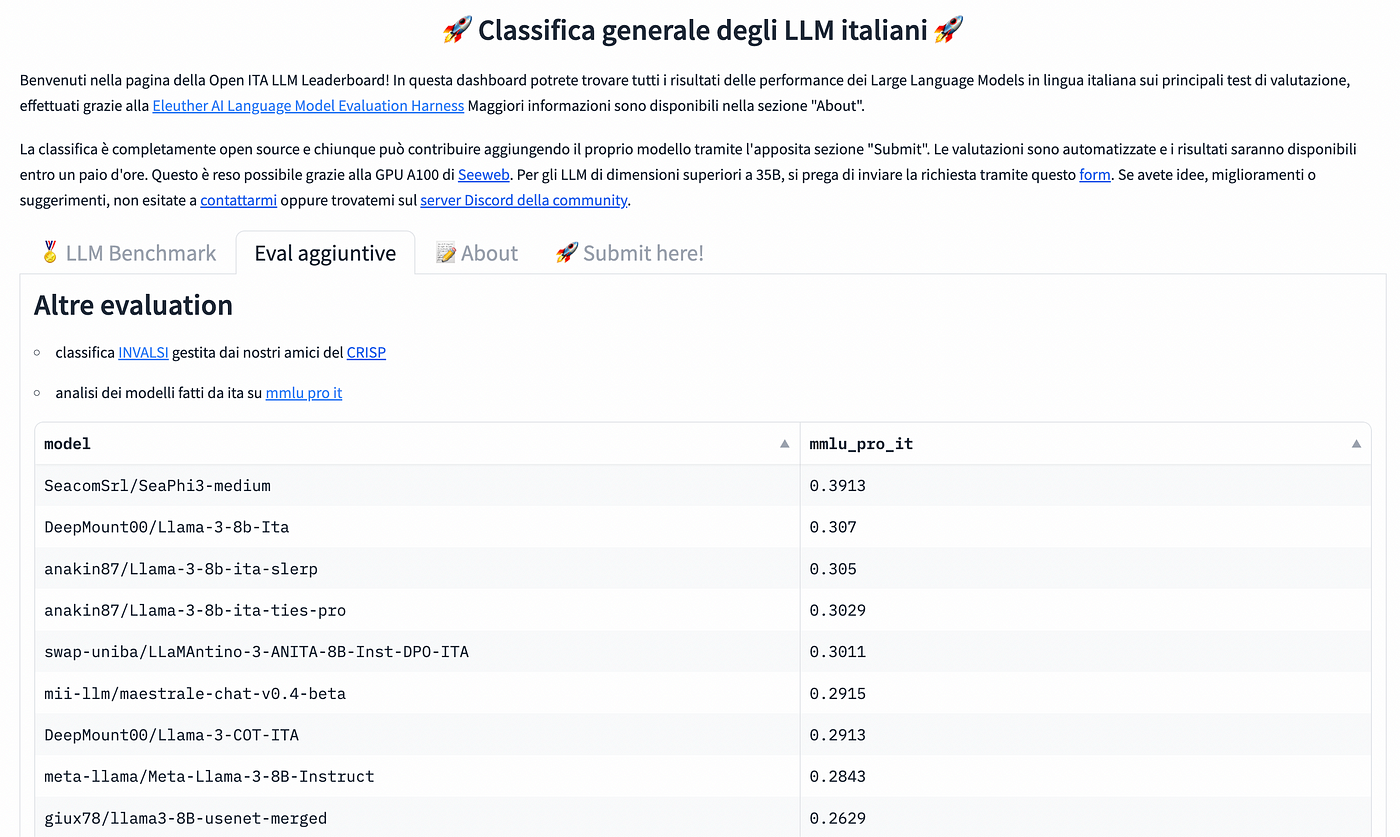
在下面的图表中是MMLU-Pro-ita上的排名。令人惊讶的是,
microsoft/Phi-3medium-4k-instruct是表现最好的模型。Phi-3系列模型是用合成数据训练的,很可能主要用英语,从我们的经验来看,它们对意大利语的掌握不是很好,也不容易进行微调。尽管如此,它仍位居第一。
在第二位,我们找到了Phi-3的一个微调版本seacom/SeaPhi3-medium。
在llama3家族中,第三名是微调版本DeepMount00/Llama-3b-Ita。
合并模型anakin87/Llama-3–8b-ita-slerp排名第四,也很有趣。
Mistral家族中表现最好的模型排在第六位,是mii-llm/maestrale-chat-v0.4-beta,这是我们最喜欢的模型之一。
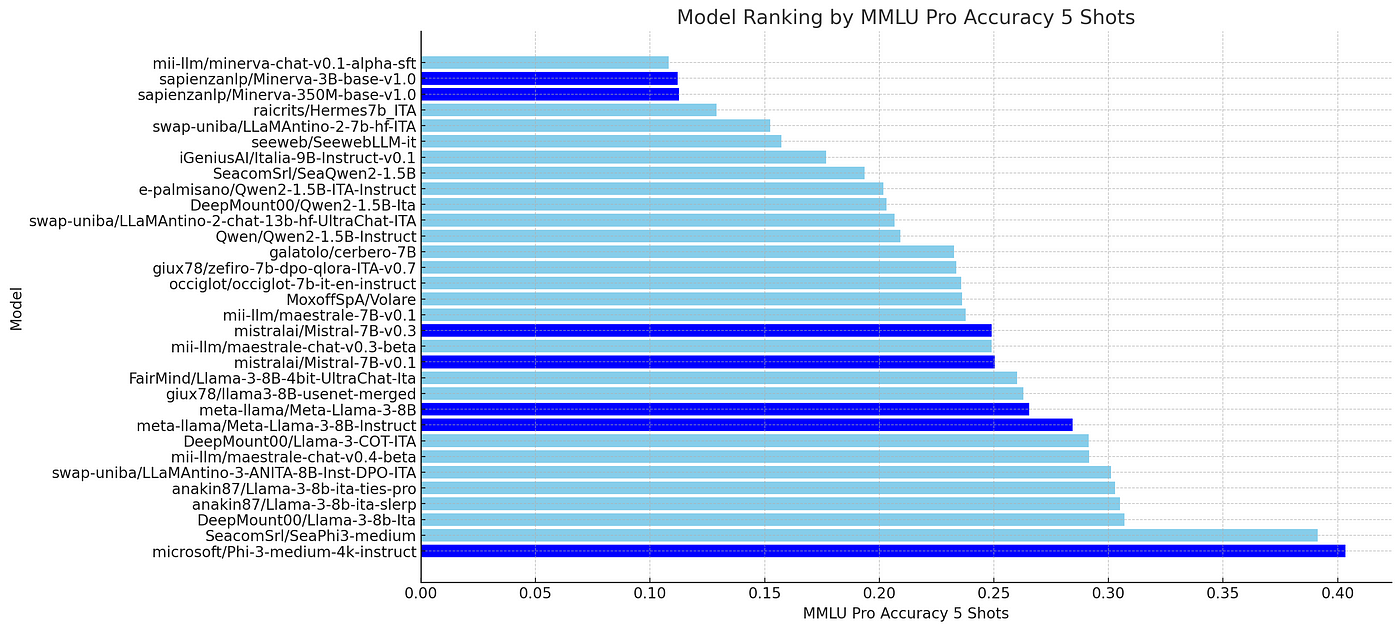
微调模型
对于微调模型,另一个重要的指标是相对于其基线模型的百分比增益。这对于评估训练的成功程度很有用,也很好地说明了微调步骤中使用的数据的质量和数量。下面的图表显示,DeepMount00/Llama-3b-Ita和mii-llm/maestrale-chat-v0.4-beta是相对于其基础模型改进最大的模型,这表明它们在mmlu-pro-it任务中使用了最完整和最好的数据集。
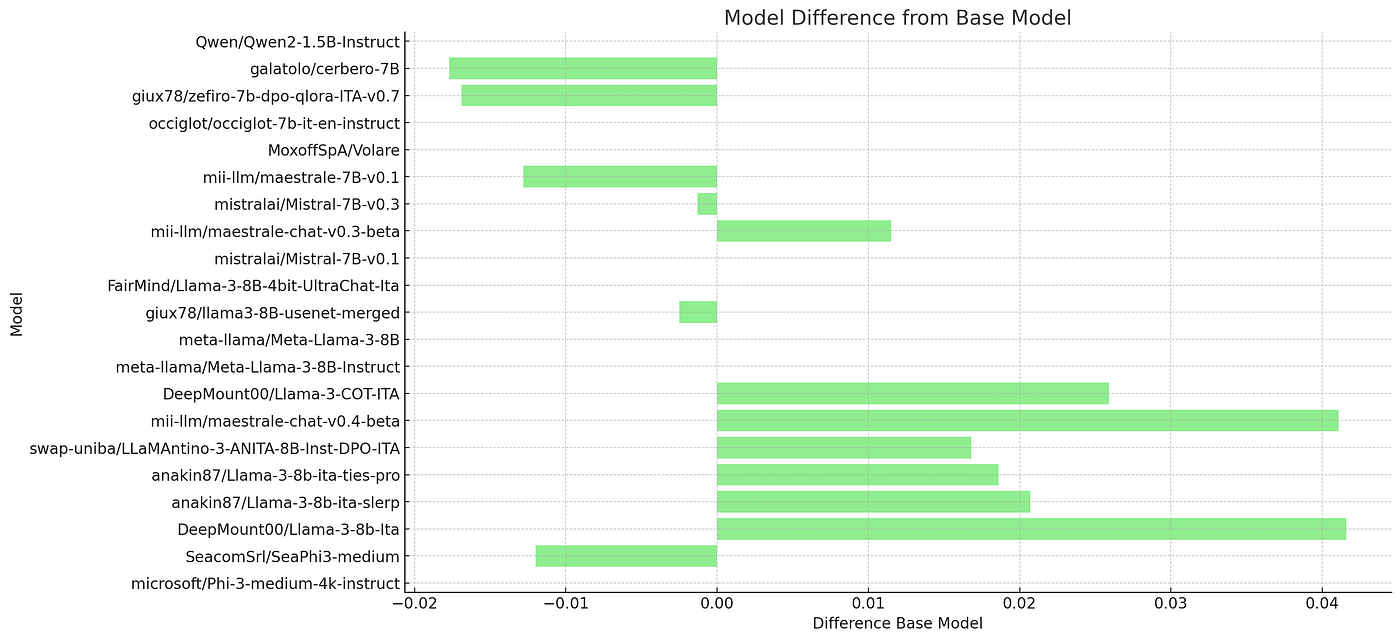
Maestrale 系列
对我们熟悉的Maestrale进行深入分析发现,例如,持续预训练倾向于侵蚀少量特定知识,从而降低MMLU性能,同时灌输更多的语言特定知识。相反,基于SFT和KTO的后续版本倾向于增加MMLU主题的特定知识,这表明这些任务的数据集质量很高。
关于评估和基准
评估和基准往往只测试模型的一种或一小部分能力,并且受文化知识和偏见的影响。这意味着它们只能作为模型性能的指标,而不能用于判断特定用例的模型。我预计我们将在未来几个月和几年内看到模型的快速领域专业化,以及评估和基准的领域专业化。例如,MMLU系列基准通过评估模型从大量文本中吸收了多少知识来测试其在主题上的知识。
但这同时也意味着,如果模型训练数据集中不存在或未充分体现此类知识,那么您的模型表现将不佳。这就是为什么主要在意大利语数据上训练的基础模型,例如sapienzanlp/minerva-llms和iiGeniusAI/Italia-9B-Instruct-v0.1,在MMLU挑战中表现不佳的原因。我是基础模型的忠实粉丝,我们认为特定领域的基础SLM也将会有一席之地。我们正在为此努力。
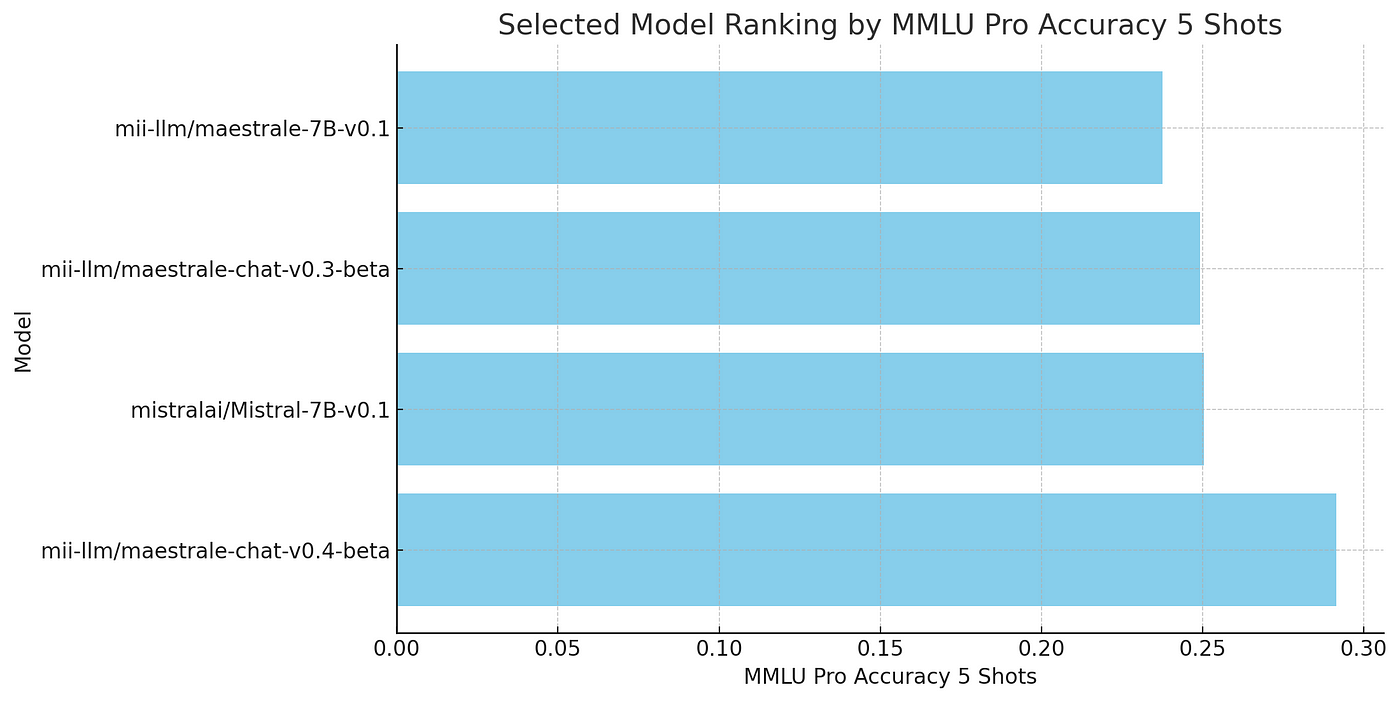
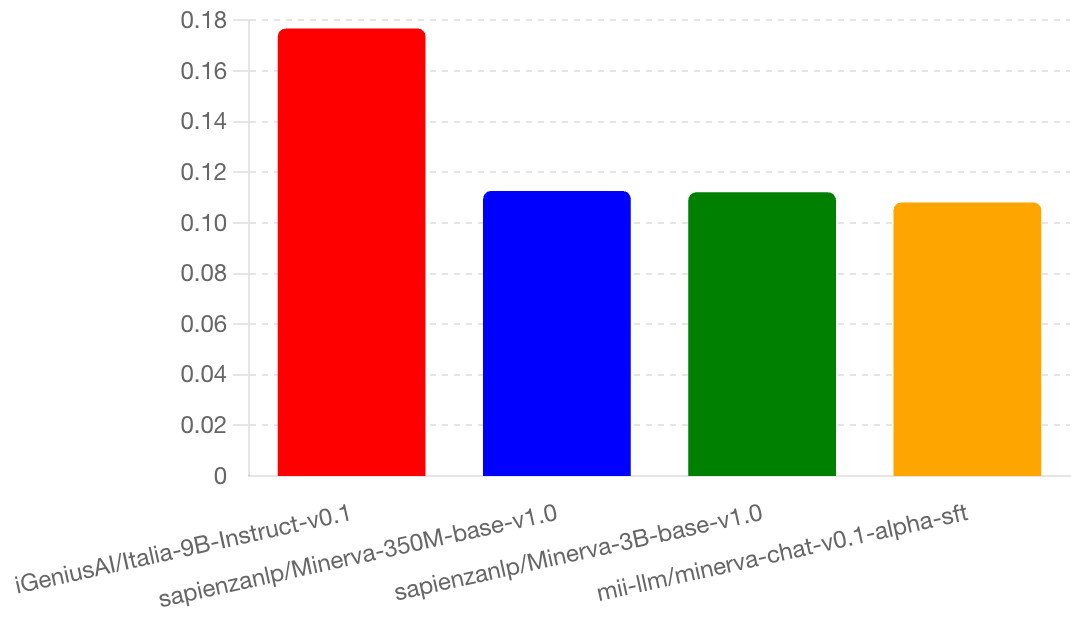
Igenius Italia 对比 Minerva
如以下图表所示,iGeniusAI/Italia-9B-Instruct-v0.1这个90亿参数的模型比sapienzanlp/minerva-llms表现更好,但后者最大的模型只有30亿参数。另一个奇怪之处是,3.5亿参数的模型比30亿参数的模型表现更好,这可能是一个值得深入研究的有趣现象。
结论
大型语言模型领域的评估和基准发展迅速,我们的愿景是,在未来几个月和几年内,将诞生超专业化的LLM,因此,许多针对不同领域的新基准也将随之出现。我们也准备发布一个新的基于意大利语的评估基准。敬请关注并加入我们的社区研究实验室。