通过 Optimum 上手 Hugging Face Transformers for IPU


事实证明,Transformer 模型在自然语言处理、音频处理和计算机视觉等广泛的机器学习任务中极为高效。然而,这些大型模型的预测速度可能使其不适用于对话式应用或搜索等对延迟敏感的用例。此外,在现实世界中优化其性能需要大量的时间、精力和技能,这超出了许多公司和组织的能力范围。
幸运的是,Hugging Face 推出了 Optimum,这是一个开源库,它使得在各种硬件平台上降低 Transformer 模型的预测延迟变得更加容易。在这篇博文中,您将学习如何为 Graphcore 智能处理单元 (IPU) 加速 Transformer 模型,这是一种高度灵活、易于使用的并行处理器,专为 AI 工作负载而设计。
Optimum 遇见 Graphcore IPU
通过 Graphcore 和 Hugging Face 之间的这次合作,我们现在将 BERT 作为首个经过 IPU 优化的模型推出。在接下来的几个月中,我们将推出更多这类经过 IPU 优化的模型,涵盖视觉、语音、翻译和文本生成等应用。
Graphcore 的工程师已经使用 Hugging Face transformers 为我们的 IPU 系统实现并优化了 BERT,以帮助开发者轻松地训练、微调和加速他们最先进的模型。
开始使用 IPU 和 Optimum
让我们以 BERT 为例,帮助您开始使用 Optimum 和 IPU。
在本指南中,我们将在 Graphcore 的云端机器学习平台 Graphcloud 中使用 IPU-POD16 系统,并遵循 Graphcloud 入门 中的 PyTorch 设置说明。
Graphcore 的 Poplar SDK 已安装在 Graphcloud 服务器上。如果您的设置不同,可以在 PyTorch for the IPU:用户指南中找到适用于您系统的说明。
设置 Poplar SDK 环境
您需要运行以下命令来设置多个环境变量,以启用 Graphcore 工具和 Poplar 库。在运行 Poplar SDK 2.3 版本的最新 Ubuntu 18.04 系统上,您可以找到/opt/gc/poplar_sdk-ubuntu_18_04-2.3.0+774-b47c577c2a/ 中。
要使用 PyTorch,您需要运行 Poplar 和 PopART (Poplar Advanced Runtime) 的两个启用脚本
$ cd /opt/gc/poplar_sdk-ubuntu_18_04-2.3.0+774-b47c577c2a/
$ source poplar-ubuntu_18_04-2.3.0+774-b47c577c2a/enable.sh
$ source popart-ubuntu_18_04-2.3.0+774-b47c577c2a/enable.sh
为 IPU 设置 PopTorch
PopTorch 是 Poplar SDK 的一部分。它提供的函数允许 PyTorch 模型在 IPU 上运行,且只需极少的代码更改。您可以按照指南 为 IPU 设置 PyTorch 创建并激活一个 PopTorch 环境。
$ virtualenv -p python3 ~/workspace/poptorch_env
$ source ~/workspace/poptorch_env/bin/activate
$ pip3 install -U pip
$ pip3 install /opt/gc/poplar_sdk-ubuntu_18_04-2.3.0+774-b47c577c2a/poptorch-<sdk-version>.whl
安装 Optimum Graphcore
现在您的环境已具备所有 Graphcore Poplar 和 PopTorch 库,您需要在此环境中安装最新的 🤗 Optimum Graphcore 包。这将是 🤗 Transformers 库和 Graphcore IPU 之间的接口。
请确保您在上一步中创建的 PopTorch 虚拟环境已激活。您的终端应显示一个前缀,如下所示,表示 poptorch 环境的名称
(poptorch_env) user@host:~/workspace/poptorch_env$ pip3 install optimum[graphcore] optuna
克隆 Optimum Graphcore 仓库
Optimum Graphcore 仓库包含了在 IPU 上使用 Optimum 模型的示例代码。您应该克隆该仓库并切换到 example/question-answering 目录,其中包含 BERT 的 IPU 实现。
$ git clone https://github.com/huggingface/optimum-graphcore.git
$ cd optimum-graphcore/examples/question-answering
现在,我们将使用 run_qa.py 在 SQUAD1.1 数据集上微调 BERT 的 IPU 实现。
运行示例以在 SQuAD1.1 上微调 BERT
run_qa.py 脚本只适用于具有快速分词器(由 🤗 Tokenizers 库支持)的模型,因为它使用了这些分词器的特殊功能。我们的 BERT 模型就是这种情况,您应将其名称作为 --model_name_or_path 的输入参数。为了使用 IPU,Optimum 将从传递给 --ipu_config_name 参数的路径中查找 ipu_config.json 文件。
$ python3 run_qa.py \
--ipu_config_name=./ \
--model_name_or_path bert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--output_dir output \
--overwrite_output_dir \
--per_device_train_batch_size 2 \
--per_device_eval_batch_size 2 \
--learning_rate 6e-5 \
--num_train_epochs 3 \
--max_seq_length 384 \
--doc_stride 128 \
--seed 1984 \
--lr_scheduler_type linear \
--loss_scaling 64 \
--weight_decay 0.01 \
--warmup_ratio 0.1 \
--output_dir /tmp/debug_squad/
深入了解 Optimum-Graphcore
获取数据
获取数据集的一个非常简单的方法是使用 Hugging Face Datasets 库,它使开发人员可以轻松地在 Hugging Face Hub 上下载和共享数据集。它还具有基于 git 和 git-lfs 的预构建数据版本控制,因此您只需指向同一个仓库即可迭代更新数据版本。
在这里,数据集附带了训练和验证文件,以及数据集配置,以帮助确定在每个模型执行阶段使用哪些输入。参数 --dataset_name==squad 指向 Hugging Face Hub 上的 SQuAD v1.1。您也可以提供自己的 CSV/JSON/TXT 训练和评估文件,只要它们遵循与 SQuAD 数据集或 Datasets 库中其他问答数据集相同的格式即可。
加载预训练模型和分词器
为了将单词转换为词元 (token),此脚本需要一个快速分词器。如果您没有传入一个,它将显示错误。作为参考,这是支持的分词器列表。
# Tokenizer check: this script requires a fast tokenizer.
if not isinstance(tokenizer, PreTrainedTokenizerFast):
raise ValueError("This example script only works for models that have a fast tokenizer. Checkout the big table of models
"at https://huggingface.co/transformers/index.html#supported-frameworks to find the model types that meet this "
"requirement"
)
参数 ```--model_name_or_path==bert-base-uncased`` 加载 Hugging Face Hub 中可用的 bert-base-uncased 模型实现。
来自 Hugging Face Hub 的描述
“BERT 基础模型 (uncased):在英语上使用掩码语言建模 (MLM) 目标进行预训练的模型。它在这篇论文中被引入,并首次在这个仓库中发布。该模型不区分大小写:它不区分 english 和 English。”
训练和验证
您现在可以使用 Optimum 中提供的 IPUTrainer 类来利用整个 Graphcore 软件和硬件堆栈,并以最少的代码更改在 IPU 中训练您的模型。感谢 Optimum,您可以即插即用最先进的硬件来训练您最先进的模型。
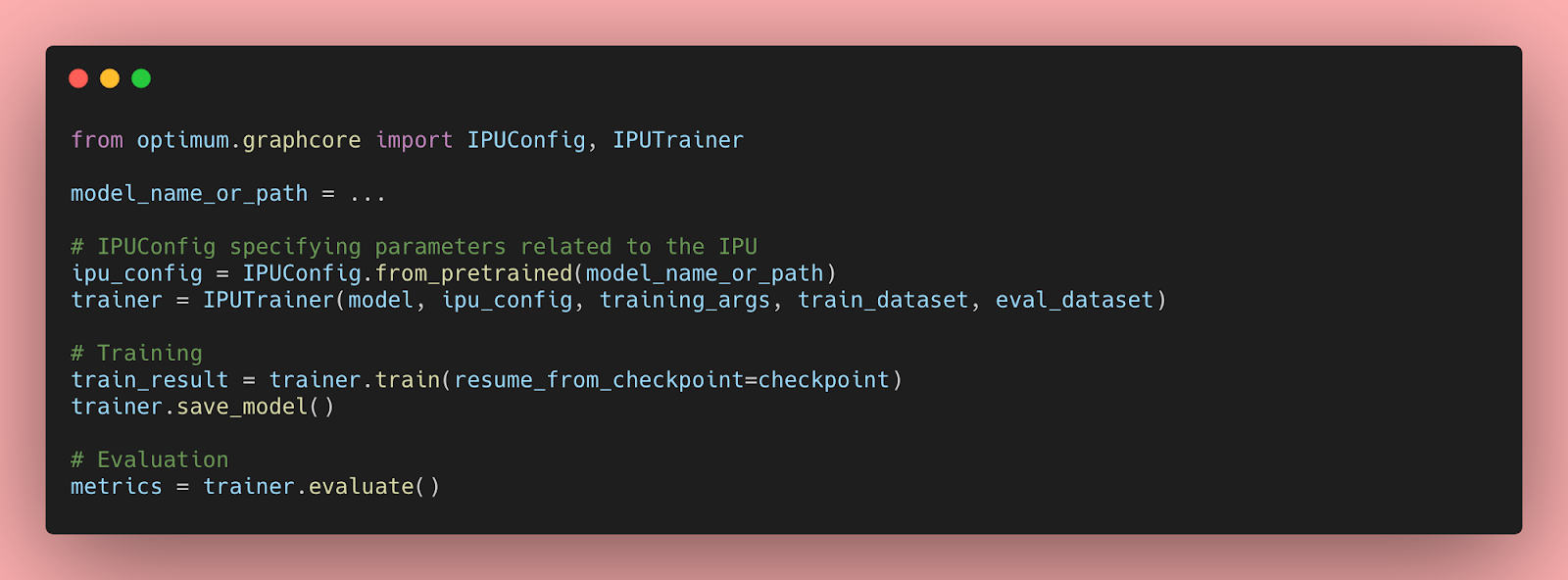
为了训练和验证 BERT 模型,您可以将参数 --do_train 和 --do_eval 传递给 run_qa.py 脚本。使用上述超参数执行脚本后,您应该会看到以下训练和验证结果
"epoch": 3.0,
"train_loss": 0.9465060763888888,
"train_runtime": 368.4015,
"train_samples": 88524,
"train_samples_per_second": 720.877,
"train_steps_per_second": 2.809
The validation step yields the following results:
***** eval metrics *****
epoch = 3.0
eval_exact_match = 80.6623
eval_f1 = 88.2757
eval_samples = 10784
您可以在 Optimum-Graphcore:SQuAD 示例中查看 IPU BERT 实现的其余部分。

