引入 HELMET:全面评估长上下文语言模型














联系方式:hyen@cs.princeton.edu
论文:https://arxiv.org/abs/2410.02694
网站:https://princeton-nlp.github.io/HELMET
代码和数据:https://github.com/princeton-nlp/HELMET
自去年十月首次发布HELMET以来,长上下文语言模型的发展速度比以往任何时候都快,我们很高兴看到社区对HELMET的采用,例如微软的Phi-4和AI21的Jamba 1.6。在首次发布后,我们向评估套件中添加了更多模型并进行了额外的分析。我们很高兴分享我们的新结果,并将在ICLR 2025上展示HELMET!
在这篇博客中,我们将描述HELMET的构建、我们的主要发现以及实践者如何在未来的研究和应用中使用HELMET来区分各种LCLM。最后,我们将提供一份HELMET与HuggingFace配合使用的快速入门指南。
评估长上下文语言模型既具有挑战性又很重要
从总结大量法律文档到即时学习新任务,长上下文语言模型(LCLM)具有巨大的潜力,可以改变我们使用和与语言模型互动的方式。语言模型一直受到其上下文窗口的限制,大约为2K到8K个token(例如ChatGPT、Llama-2/3)。最近,模型开发者不断增加其模型的上下文窗口,最新模型如GPT-4o、Claude-3和Gemini-1.5支持高达数百万个token的上下文窗口。

然而,随着上下文窗口的增加,以前的自然语言基准(例如Scrolls)不再适合评估LCLM。因此,困惑度和合成任务(例如大海捞针)成为LCLM最流行的评估指标,但它们通常不反映真实世界性能。模型开发者也可能在其他任意数据集上进行评估,这使得模型比较复杂。此外,LCLM的现有基准可能会显示出令人困惑和反直觉的结果,使得难以理解不同模型的优缺点(图1)。
在这项工作中,我们提出了HELMET(如何有效且彻底地评估长上下文模型),这是一个用于评估LCLM的综合基准,它在多个方面改进了现有基准——多样性、可控性和可靠性。我们评估了59个近期LCLM,发现跨不同应用评估模型对于理解其能力至关重要,并且前沿LCLM在复杂任务上仍然受限。
现有评估过度依赖合成任务
随着工业界和开源社区LCLM的发展,拥有可靠的方法来评估和比较这些模型变得至关重要。然而,当前模型通常在不同的基准上进行评估(表1)。
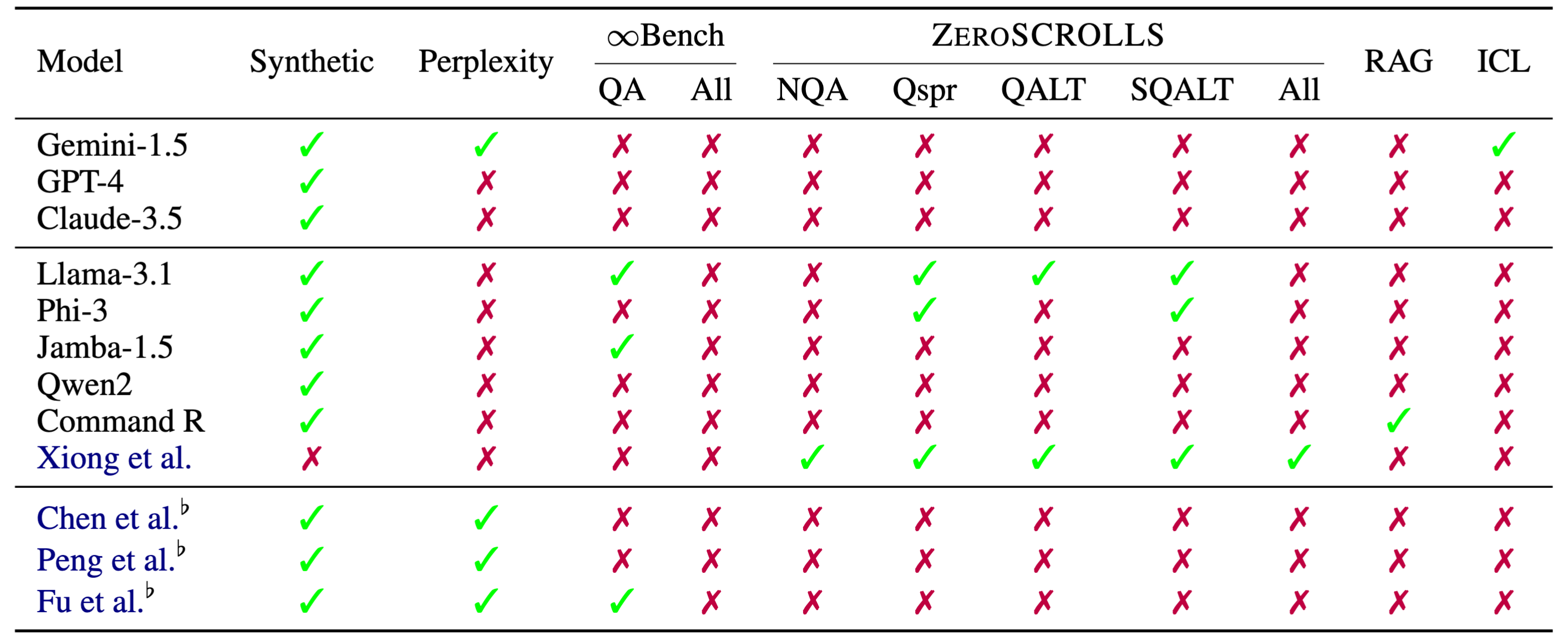
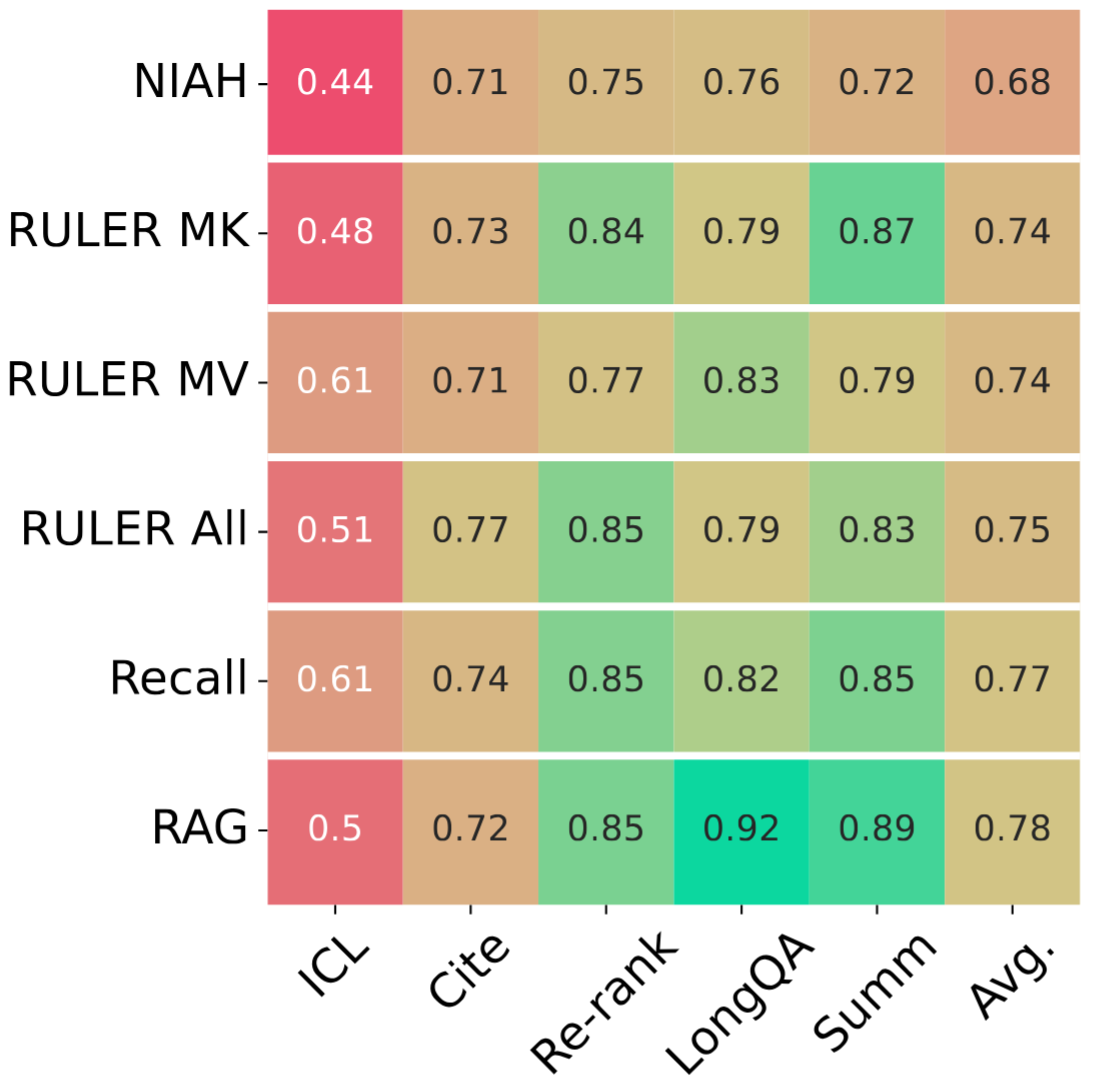
评估长上下文语言模型的常见做法是使用困惑度或合成任务,例如大海捞针(NIAH)。然而,最近的研究表明,困惑度与下游性能相关性不佳(Fang et al., 2024)。在图2中,我们展示了像NIAH这样的合成任务与真实世界性能不相关,但更复杂的合成任务与真实世界任务具有更高的相关性。
在现有具有实际应用的基准中,例如ZeroScrolls(Shaman et al., 2023)、LongBench(Bai et al., 2024)和InfiniteBench(Zhang et al., 2024),仍然存在关键限制:
- 下游任务覆盖不足:通常侧重于特定领域
- 对于测试前沿LCLM来说长度不足:旧的问答数据集通常限制在<32K个token(例如QASPER、QuALITY)
- 不可靠的指标:ROUGE等N-gram匹配指标噪音大——它们与人类判断相关性不佳(Goyal et al., 2023)且无法区分模型
- 与基础模型不兼容:需要指令微调,这意味着它们不能用于基础模型开发
因此,我们提出了HELMET来解决这些限制,并对LCLM进行全面评估。
为LCLM制定多样化、可控且可靠的评估
我们设计HELMET时考虑了以下期望:
- 下游任务的广泛覆盖
- 可控的长度和复杂度
- 基础模型和指令微调模型的可靠评估
表2显示了基准的概览。在我们的实验中,我们评估了从8K到128K个token的输入长度,但HELMET可以轻松扩展到更长的上下文长度。
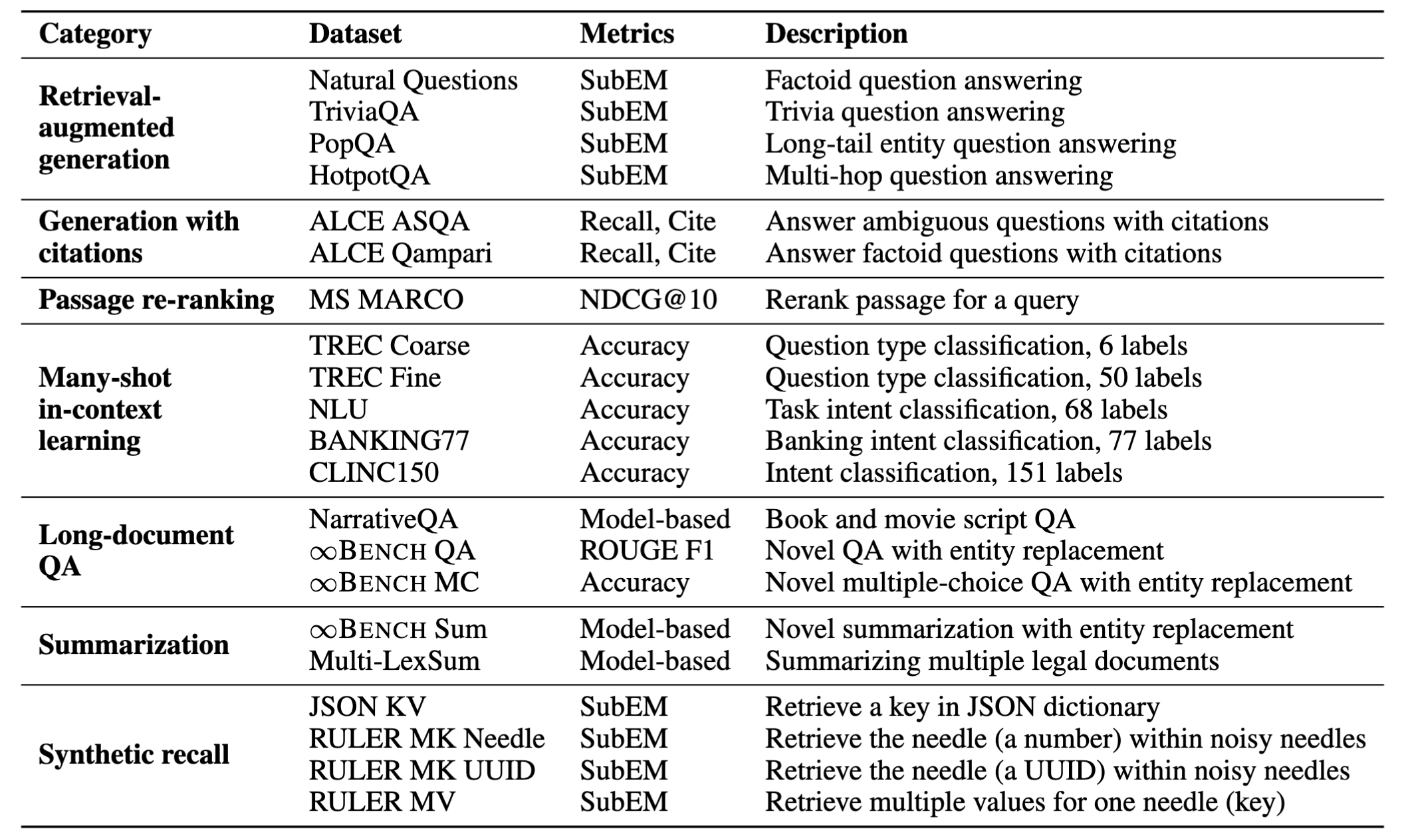
相对于现有基准的主要改进
广泛覆盖:HELMET包含一系列多样化的任务,例如带有真实检索段落的检索增强生成、带引用的生成和摘要。我们精心选择具有自然长上下文的数据集,以反映实际应用。这些数据集辅以可靠的评估设置,例如基于模型的评估和人工研究。
可控的长度和难度:评估LCLM时需要考虑的一个重要维度是输入长度,因为更长的输入可以提供更多信息,同时挑战模型处理嘈杂上下文的能力。在我们的任务中,我们可以通过更改检索段落的数量(RAG、Cite、Re-rank)、演示的数量(ICL)或输入文档的长度(LongQA、Summ)来控制输入长度。虽然LongQA和Summ不能轻易扩展到更长的上下文,但我们特意选择了具有自然文档长度远大于100K个token的数据集,以便它们仍可用于评估前沿LCLM。
可靠评估:许多现有基准仍使用基于n-gram的指标,例如ROUGE,尽管它们与人类判断的相关性很差(Goyal et al., 2023)。我们采用基于模型的评估,该评估在模型之间和不同输入长度之间显示出更好的可区分性(图3)。此外,我们的人工研究表明,我们的指标与人类判断具有高度一致性。

稳健的提示:现有的长上下文基准通常要求模型遵循指令,但许多模型开发都围绕基础模型展开,这些模型必须依靠合成任务或困惑度进行评估。因此,我们通过上下文学习示例支持我们的部分任务的基础模型。这大大提高了基础模型的性能,更能反映实际应用。
LCLM在实际任务中仍有很长的路要走
我们的实验和分析包括一套全面的59个LCLM。据我们所知,这是对长上下文模型在不同应用上最彻底和最受控的比较。这些模型涵盖了领先的专有模型和开源模型,我们还考虑了具有不同架构(例如全注意力Transformer、混合架构)和位置外推技术的模型。在本节中,我们将重点介绍我们实验中的几个关键发现。
评估长上下文能力需要多样化的评估
长上下文基准通常是针对特定应用(例如摘要或问答)构建的,这限制了对更广泛背景下LCLM的理解。我们检查了模型在广泛真实任务中的表现,发现不同类别之间并不总是相关联(图4)。
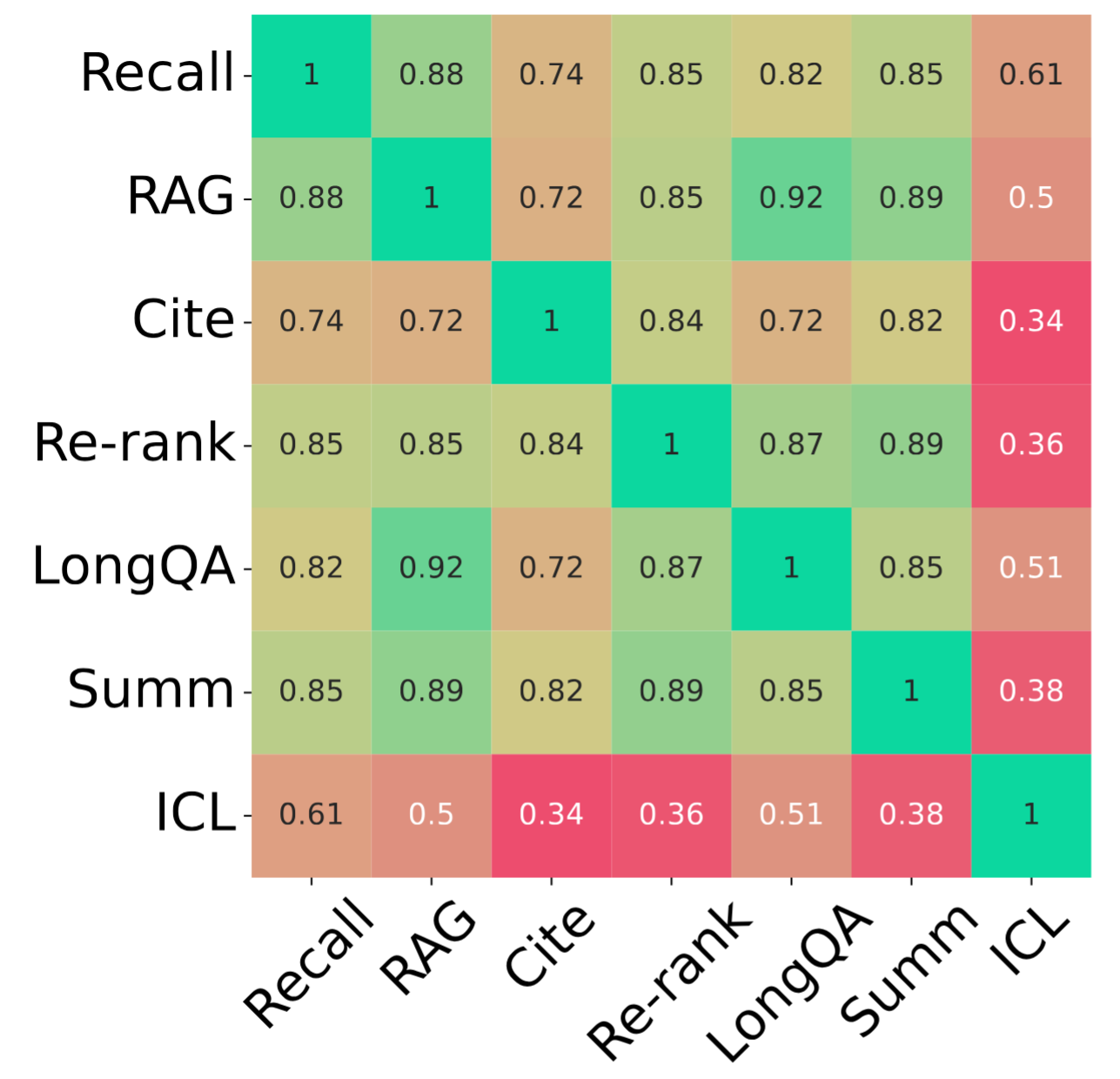
尽管某些任务(例如RAG和MS-MARCO)由于其基于检索的性质而彼此适度相关,但其他任务(例如Summ和Cite)则显示出很少的相关性。值得注意的是,ICL与其他任务的相关性最低,这表明它是一个独特的任务,需要模型具备不同的能力。因此,模型开发者应该在这些不同的轴上进行评估,以更全面地了解模型的能力。
模型性能随长度和任务复杂度的增加而下降
我们展示了前沿专有模型以及少数开源模型在HELMET上的结果。更多结果可在论文和网站上找到。

首先,我们观察到开源模型在复杂任务上落后于闭源模型。尽管在召回等简单任务上差距似乎很小,但在引用等更复杂的任务上差距会扩大。
此外,性能随长度增加而下降是取决于类别的。即使是最先进的模型,如GPT-4o和Gemini,在重新排序等任务上性能也会显著下降。这种性能变化无法通过简单地查看合成任务性能来观察。
最后,在所有类别中没有明显的赢家,因此需要跨不同轴进行评估。更多分析,例如不同位置外推方法的性能和“中间遗失”现象,可以在论文中找到。
使用HELMET进行未来开发
如何运行HELMET
使用HELMET非常简单!只需克隆我们的GitHub仓库,设置好环境后即可运行!
我们提供了多种加载模型的方式,可在配置文件中进行配置:
- 使用HuggingFace的
transformers库 - 使用HuggingFace的TGI在您的机器上启动模型端点
- 使用HuggingFace的Inference Endpoints启动远程模型端点
- 使用vllm在您的机器上启动模型端点。注意:您可以在Intel Gaudi加速器上启动vllm端点。
- 使用模型提供商的API
选项1. 使用HuggingFace的transformers库
只需使用我们仓库中的config yamls,然后运行以下评估:
python eval.py --config configs/rag.yaml --model_name_or_path <model_name>
在幕后,使用了HuggingFace的transformers库,并自动支持本地和远程模型。
选项2. 使用HuggingFace的TGI
首先,按照TGI github上的说明启动模型端点。然后,在您的配置文件中,指定端点URL。例如,您可以有一个config.yaml,如下所示:
input_max_length: 131072
datasets: kilt_nq
generation_max_length: 20
test_files: data/kilt/nq-dev-multikilt_1000_k1000_dep6.jsonl
demo_files: data/kilt/nq-train-multikilt_1000_k3_dep6.jsonl
use_chat_template: true
max_test_samples: 100
shots: 2
stop_new_line: true
model_name_or_path: tgi:meta-llama/Llama-3.1-8B-Instruct # need to add "tgi:" prefix
use_tgi_serving: true # add this line in your config
然后使用下面的命令运行基准测试:
export LLM_ENPOINT=<your-tgi-endpoint> # example: "https://10.10.10.1:8080/v1"
python eval.py --config configs/config.yaml --endpoint_url $LLM_ENDPOINT
选项3. 使用HuggingFace的推理端点
首先按照此处的说明设置端点。获取端点URL和您的API密钥。然后使用与选项2中相同的config yaml,并运行以下命令:
export LLM_ENPOINT=<your-hf-inference-endpoint> # example: "https://XXXX.us-east-1.aws.endpoints.huggingface.cloud/v1"
export API_KEY=<your-hf-api-key>
python eval.py --config configs/config.yaml --endpoint_url $LLM_ENDPOINT --api_key $API_KEY
选项4. 使用VLLM
您可以在系统上使用vllm启动模型端点,包括Intel Gaudi2和Gaudi3加速器。有关如何使用vllm在Intel Gaudi加速器上运行HELMET的说明,请参见此处。
您可以使用与选项2相同的示例config.yaml,除了两行更改,如下所示:
model_name_or_path: meta-llama/Llama-3.1-8B-Instruct # no prefix needed
use_vllm_serving: true # use vllm instead of tgi
然后使用下面的命令运行基准测试:
export LLM_ENPOINT=<your-vllm-endpoint>
python eval.py --config configs/config.yaml --endpoint_url $LLM_ENDPOINT
选项5. 使用模型提供商的API
我们支持来自OpenAI、Anthropic、Google和TogetherAI的API。请参考我们仓库中的说明。
更快地开发
我们建议在模型开发过程中使用Recall和RAG任务进行快速迭代。这些任务在快速评估和与其他实际任务的相关性之间取得了良好的平衡。您可以通过以下方式轻松运行这些评估:
python eval.py --config configs/rag.yaml --model_name_or_path <model_name>
与现有模型的快速比较
评估LCLM通常很昂贵,尤其是在长上下文情况下,考虑到它们的计算和内存成本。例如,在一个70B模型上以所有长度运行HELMET需要一个拥有8*80GB GPU的节点,耗时数百个GPU小时,这可能成本高昂。通过在HELMET上进行评估,研究人员只需参考我们的结果即可直接将其模型与现有模型进行比较,我们的结果涵盖了59个不同大小和架构的模型。您可以在我们的网站上找到排行榜。
展望未来
HELMET是朝着更全面评估长上下文语言模型迈出的一步,但LCLM仍有许多令人兴奋的应用。例如,我们最近发布了LongProc,这是一个用于评估LCLM在长篇生成和遵循程序方面的基准,这对于开发能够以思维步骤生成数万个token的推理模型至关重要。尽管摘要任务具有较长的输出(最多1K个token),但LongProc专注于更长的输出,最多8K个token。与HELMET类似,LongProc也采用可靠的评估设置和多样化的任务设计。我们正在努力将LongProc整合到HELMET的评估套件中,并希望这将为LCLM在长篇任务上的评估提供更全面的视角。
致谢
我们感谢夏梦舟、Howard Chen、叶曦、何映辉、Lucy He、Alexander Wettig、Sadhika Malladi、Adithya Bhaskar、Joie Zhang以及普林斯顿语言与智能(PLI)小组的其他成员提供的宝贵反馈。这项工作得到了微软加速基础模型研究(AFMR)提供的Azure OpenAI积分和英特尔资助的大力支持。
引用
如果您觉得HELMET有用,请考虑引用我们的论文:
@inproceedings{yen2025helmet,
title={HELMET: How to Evaluate Long-Context Language Models Effectively and Thoroughly},
author={Howard Yen and Tianyu Gao and Minmin Hou and Ke Ding and Daniel Fleischer and Peter Izsak and Moshe Wasserblat and Danqi Chen},
year={2025},
booktitle={International Conference on Learning Representations (ICLR)},
}







