AMD + 🤗: 基于 AMD GPU 的大语言模型开箱即用加速









今年早些时候,AMD 和 Hugging Face 宣布建立合作伙伴关系,在 AMD 的 AI Day 活动中加速 AI 模型。我们一直致力于将这一愿景变为现实,让 Hugging Face 社区能够轻松地在 AMD 硬件上以最佳性能运行最新的 AI 模型。
AMD 正在为世界上一些最强大的超级计算机提供动力,包括欧洲最快的超级计算机 LUMI,它拥有超过 10,000 个 MI250X AMD GPU。在此次活动中,AMD 发布了其最新一代的服务器 GPU,即 AMD Instinct™ MI300 系列加速器,该系列加速器将很快普遍上市。
在这篇博文中,我们将介绍我们在为 AMD GPU 提供出色的开箱即用支持以及改进最新服务器级 AMD Instinct GPU 的互操作性方面取得的进展。
开箱即用加速
你能在下面找到 AMD 特定的代码更改吗?别费劲了,与在 NVIDIA GPU 上运行相比,这里根本没有 AMD 特定的代码 🤗。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "01-ai/Yi-6B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
with torch.device("cuda"):
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.float16)
inp = tokenizer(["Today I am in Paris and"], padding=True, return_tensors="pt").to("cuda")
res = model.generate(**inp, max_new_tokens=30)
print(tokenizer.batch_decode(res))
我们一直在努力的一个主要方面是能够无需任何代码更改即可运行 Hugging Face Transformers 模型。我们现在支持所有 Transformers 模型和 AMD Instinct GPU 上的任务。我们的合作不会止步于此,因为我们正在探索对 Diffusers 模型和其他库以及其他 AMD GPU 的开箱即用支持。
实现这一里程碑是我们团队和公司之间的一项重大努力和合作。为了维持对 Hugging Face 社区的支持和性能,我们已经在我们的数据中心构建了 Hugging Face 开源库在 AMD Instinct GPU 上的集成测试——并能够与 Verne Global 合作,在冰岛部署 AMD Instinct 服务器,从而最大程度地减少这些新工作负载的碳影响。
除了原生支持,我们合作的另一个主要方面是为 AMD GPU 上可用的最新创新和功能提供集成。通过 Hugging Face 团队、AMD 工程师和开源社区成员的合作,我们很高兴地宣布支持:
- AMD 开源项目 ROCmSoftwarePlatform/flash-attention 中的 Flash Attention v2 已原生集成到 Transformers 和 Text Generation Inference 中。
- 来自 vLLM 的 Paged Attention,以及 Text Generation Inference 中用于 ROCm 的各种融合内核。
- 使用 Transformers 在 ROCm 驱动的 GPU 上运行 DeepSpeed 现已正式验证并支持。
- GPTQ 是一种常用的权重压缩技术,用于减少模型内存需求,通过与 AutoGPTQ 和 Transformers 直接集成,在 ROCm GPU 上得到支持。
- Optimum-Benchmark,一个用于轻松测试 AMD GPU 上 Transformers 性能的实用工具,支持正常和分布式设置,以及受支持的优化和量化方案。
- 使用 Optimum 库,通过 ROCMExecutionProvider 在 ROCm 驱动的 GPU 上执行 ONNX 模型。
我们非常高兴能将这些最先进的加速工具提供给 Hugging Face 用户,并且易于使用,并通过我们针对 AMD Instinct GPU 的新持续集成和开发管道提供持续的支持和性能。
一个具有 128 GB 高带宽内存的 AMD Instinct MI250 GPU 具有两个独立的 ROCm 设备(GPU 0 和 1),每个设备具有 64 GB 高带宽内存。
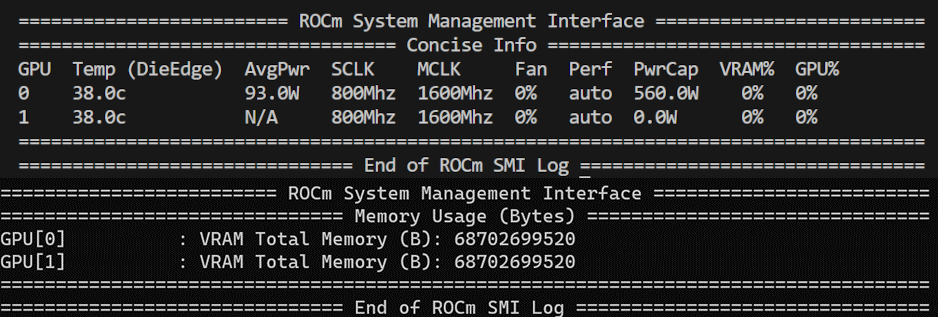
这意味着,只需一张 MI250 GPU 卡,我们就可以拥有两个 PyTorch 设备,可以非常方便地使用张量和数据并行来实现更高的吞吐量和更低的延迟。
在博客文章的其余部分,我们报告了通过大型语言模型进行文本生成所涉及的两个步骤的性能结果:
- 预填充延迟:模型计算用户提供的输入或提示表示所需的时间(也称为“首个 token 的时间”)。
- 每 token 解码延迟:在预填充步骤之后,以自回归方式生成每个新 token 所需的时间。
- 解码吞吐量:在解码阶段每秒生成的 token 数量。
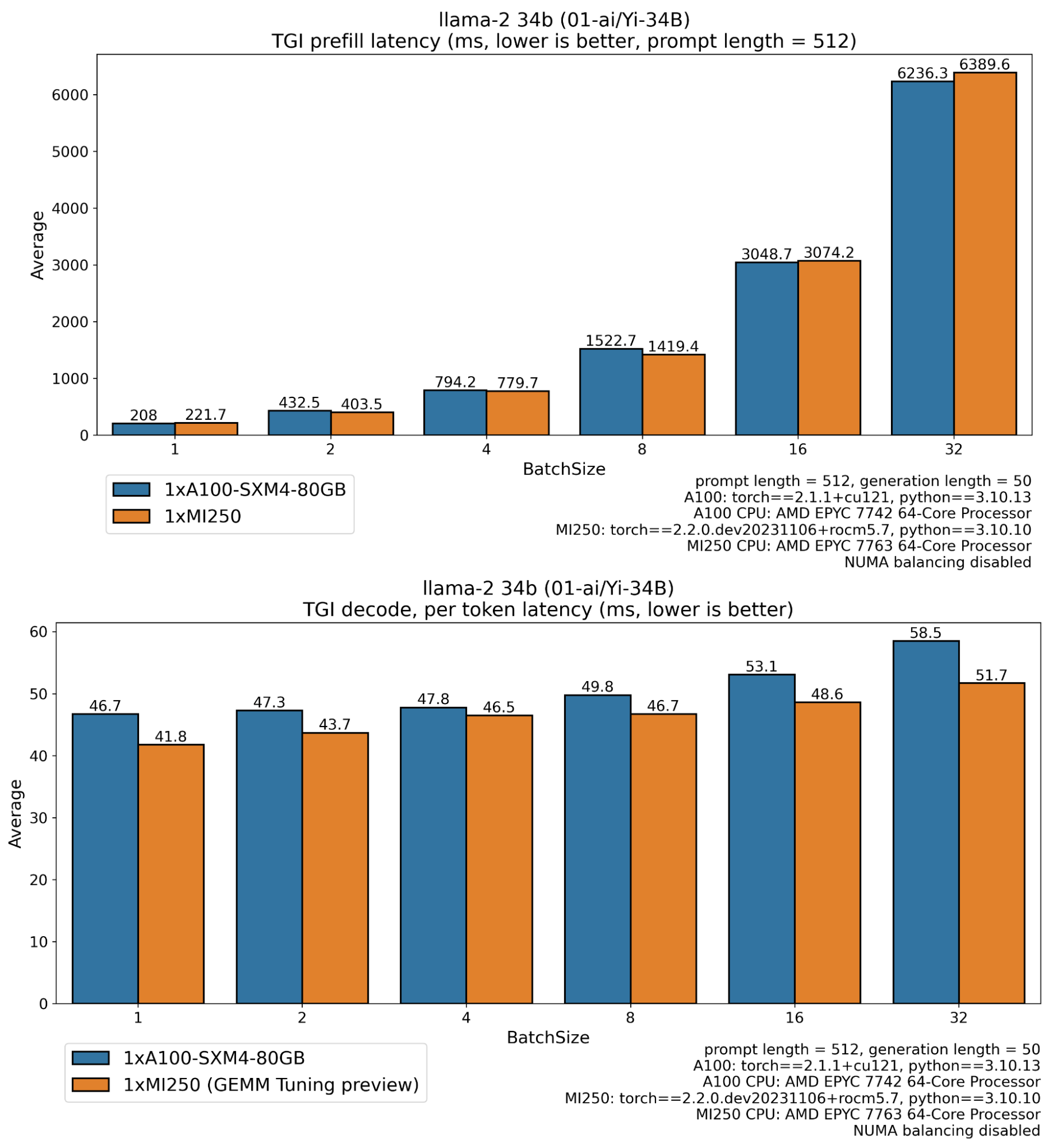
使用 `optimum-benchmark` 并在 MI250 和 A100 GPU 上运行推理基准测试,有无优化,我们得到以下结果:
在上面的图表中,我们可以看到 MI250 的性能表现,特别是在生产环境中,当请求以大批量处理时,MI250 比 A100 卡多输出 2.33 倍以上的 token(解码吞吐量),并且首个 token 的时间(预填充延迟)减少了一半。
如下所示,运行训练基准测试时,一张 MI250 卡可以容纳更大的训练样本批次,并实现更高的训练吞吐量。
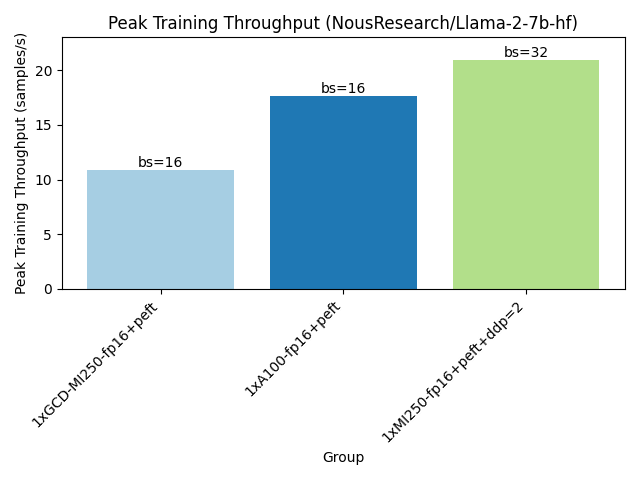
生产解决方案
我们合作的另一个重要重点是为 Hugging Face 生产解决方案构建支持,从 Text Generation Inference (TGI) 开始。TGI 提供了一个端到端的解决方案,用于大规模部署大型语言模型进行推理。
最初,TGI 主要面向 Nvidia GPU,利用了对 Ampere 架构后进行的最新优化,例如 Flash Attention v1 和 v2、GPTQ 权重量化和 Paged Attention。
今天,我们很高兴地宣布 TGI 对 AMD Instinct MI210 和 MI250 GPU 的初步支持,利用上面详细介绍的所有出色的开源工作,集成到一个完整的端到端解决方案中,随时可以部署。
在性能方面,我们花费了大量时间在 AMD Instinct GPU 上对文本生成推理进行基准测试,以验证并发现我们应该关注的优化点。因此,在 AMD GPU 工程师的支持下,我们已经能够实现与 TGI 已提供性能相匹配的性能。
在此背景下,以及我们正在 AMD 和 Hugging Face 之间建立的长期关系,我们一直在集成和测试 AMD GeMM Tuner 工具,该工具允许我们调整 TGI 中使用的 GeMM(矩阵乘法)内核,以找到实现更高性能的最佳设置。GeMM Tuner 工具预计将在即将发布的 PyTorch 版本中作为 PyTorch 的一部分发布,供所有人受益。
综上所述,我们很高兴展示第一批性能数据,这些数据展示了最新的 AMD 技术,使 AMD GPU 上的文本生成推理在 Llama 模型系列的推理解决方案中处于领先地位。
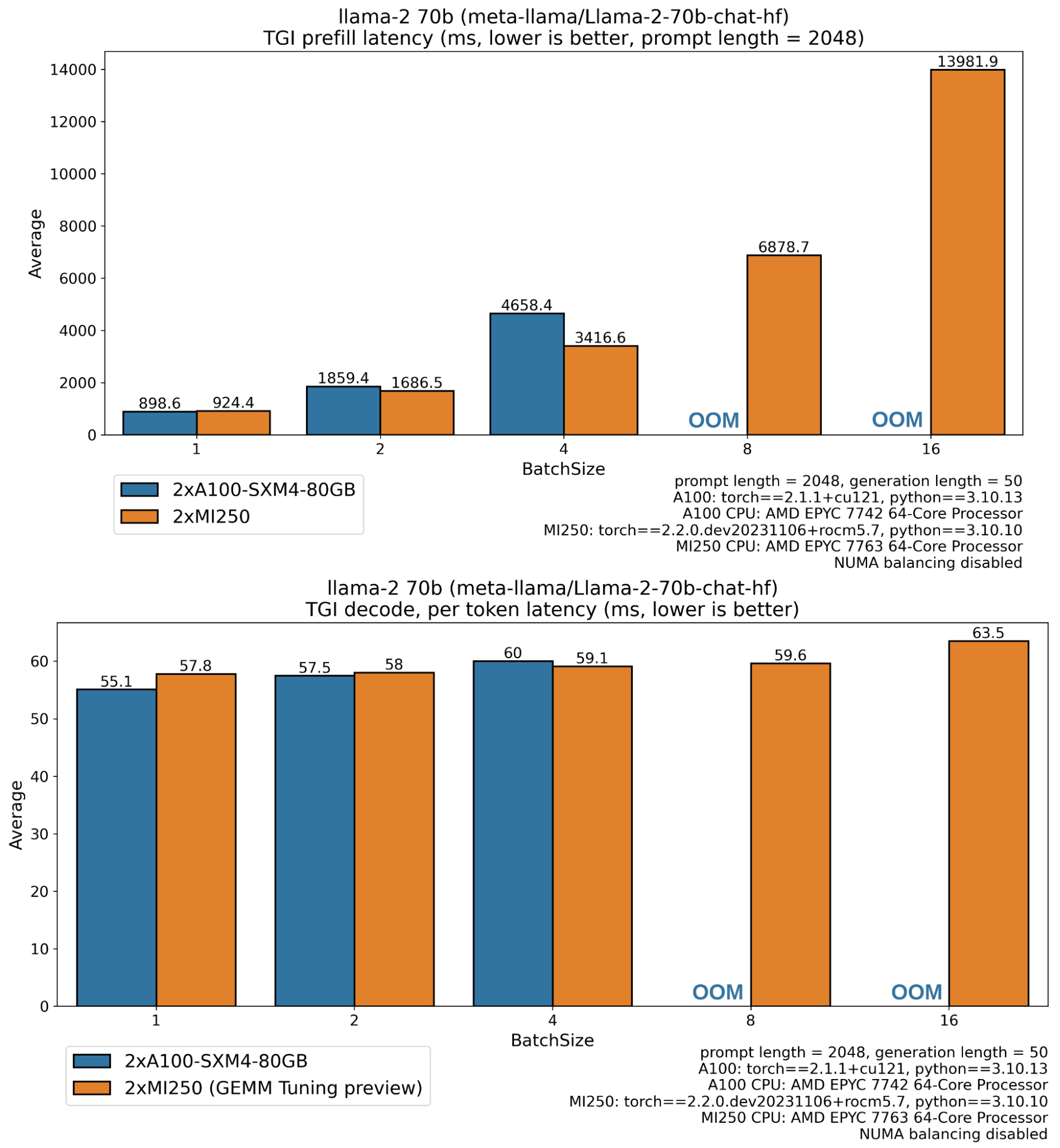
A100 缺失的条形图对应于内存不足错误,因为 Llama 70B 的权重在 float16 中为 138 GB,并且中间激活、KV 缓存缓冲区(序列长度 2048、批量大小 8 时 >5GB)、CUDA 上下文等需要足够的空闲内存。Instinct MI250 GPU 具有 128 GB 全局内存,而 A100 具有 80GB,这解释了 MI250 能够运行更大工作负载(更长序列、更大批量)的原因。
Text Generation Inference 已准备就绪,可通过 docker 镜像 `ghcr.io/huggingface/text-generation-inference:1.2-rocm` 在 AMD Instinct GPU 上部署到生产环境。请务必参阅文档,了解支持及其限制。
接下来是什么?
我们希望这篇博文能像我们 Hugging Face 一样,让你对与 AMD 的合作感到兴奋。当然,这仅仅是我们旅程的开始,我们期待在更多 AMD 硬件上实现更多用例。
在接下来的几个月里,我们将致力于为 AMD Radeon GPU 带来更多支持和验证,这些 GPU 可以用于你的台式机进行本地使用,从而降低了可访问性障碍,并为我们的用户带来了更大的多功能性。
当然,我们很快就会为 MI300 系列产品进行性能优化,确保开源和解决方案都能以我们在 Hugging Face 一直追求的最高稳定水平提供最新的创新。
我们的另一个重点领域将是 AMD Ryzen AI 技术,该技术为最新一代 AMD 笔记本 CPU 提供动力,允许在边缘设备上运行 AI。在编码助手、图像生成工具和个人助手越来越广泛可用的时代,提供能够满足隐私需求以利用这些强大工具的解决方案至关重要。在这种背景下,Ryzen AI 兼容模型已在 Hugging Face Hub 上可用,我们正在与 AMD 密切合作,在未来几个月内带来更多模型。