使用 🤗 数据集进行图像搜索





🤗
datasets 是一个让访问和共享数据集变得容易的库。它还使得高效处理数据变得容易——包括处理不适合内存的数据。
当 datasets 首次发布时,它主要与文本数据相关联。然而,最近,datasets 增加了对音频和图像的支持。特别是,现在有一个 datasets 图像特征类型。之前的一篇博客文章展示了如何将 datasets 与 🤗 transformers 结合使用来训练图像分类模型。在这篇博客文章中,我们将看到如何结合 datasets 和其他几个库来创建图像搜索应用程序。
首先,我们将安装 datasets。由于我们将处理图像,我们还将安装 pillow。我们还需要 sentence_transformers 和 faiss。我们将在下面更详细地介绍它们。我们还安装了 rich——我们在这里只会简要使用它,但它是一个非常有用的软件包,我真的建议进一步探索它!
!pip install datasets pillow rich faiss-gpu sentence_transformers
首先,让我们看看图像特征。我们可以使用出色的 rich 库来查看 Python 对象(函数、类等)。
from rich import inspect
import datasets
inspect(datasets.Image, help=True)
╭───────────────────────── <class 'datasets.features.image.Image'> ─────────────────────────╮ │ class Image(decode: bool = True, id: Union[str, NoneType] = None) -> None: │ │ │ │ Image feature to read image data from an image file. │ │ │ │ Input: The Image feature accepts as input: │ │ - A :obj:`str`: Absolute path to the image file (i.e. random access is allowed). │ │ - A :obj:`dict` with the keys: │ │ │ │ - path: String with relative path of the image file to the archive file. │ │ - bytes: Bytes of the image file. │ │ │ │ This is useful for archived files with sequential access. │ │ │ │ - An :obj:`np.ndarray`: NumPy array representing an image. │ │ - A :obj:`PIL.Image.Image`: PIL image object. │ │ │ │ Args: │ │ decode (:obj:`bool`, default ``True``): Whether to decode the image data. If `False`, │ │ returns the underlying dictionary in the format {"path": image_path, "bytes": │ │ image_bytes}. │ │ │ │ decode = True │ │ dtype = 'PIL.Image.Image' │ │ id = None │ │ pa_type = StructType(struct<bytes: binary, path: string>) │ ╰───────────────────────────────────────────────────────────────────────────────────────────╯
我们可以看到有几种不同的方式可以传入图像。我们稍后会再讨论这个问题。
datasets 库的一个非常好的功能(除了数据处理、内存映射等功能之外)是您可以“免费”获得一些不错的东西。其中之一是能够将 faiss 索引添加到数据集中。faiss 是一个“用于密集向量高效相似性搜索和聚类的库”。
datasets 文档展示了一个使用 faiss 索引进行文本检索的示例。在这篇文章中,我们将看看我们是否可以对图像做同样的事情。
数据集:“数字化书籍——被识别为装饰的图像。约 1510 年 - 约 1900 年”
这是一个图像数据集,这些图像是从大英图书馆数字化书籍集合中提取出来的。这些图像来自不同时期和广泛领域的书籍。图像是利用每本书的 OCR 输出中包含的信息提取的。因此,可以知道图像来自哪本书,但不一定知道图像中显示了什么。
为帮助克服这一问题,一些尝试包括将图像上传到 Flickr。这使得人们可以对图像进行标记或将其分类到不同的类别中。
还有一些项目使用机器学习对数据集进行标记。这项工作使得按标签搜索成为可能,但我们可能希望获得更“丰富”的搜索能力。对于这个特定的实验,我们将使用包含“装饰”的集合的一个子集。这个数据集稍微小一些,所以更适合进行实验。我们可以从大英图书馆的数据存储库获取完整数据:https://doi.org/10.21250/db17。由于完整数据集仍然相当大,您可能需要从一个较小的样本开始。
创建我们的数据集
我们的数据集包含一个文件夹,其中包含子目录,子目录中是图像。这是一种相当标准的图像数据集共享格式。得益于最近合并的拉取请求,我们可以直接使用 datasets 的 ImageFolder 加载器加载此数据集 🤯
from datasets import load_dataset
dataset = load_dataset("imagefolder", data_files="https://zenodo.org/record/6224034/files/embellishments_sample.zip?download=1")
让我们看看我们得到了什么。
dataset
DatasetDict({
train: Dataset({
features: ['image', 'label'],
num_rows: 10000
})
})
我们可以得到一个 DatasetDict,我们有一个带有图像和标签特征的数据集。由于这里没有训练/验证拆分,我们来获取数据集的训练部分。我们再来看看数据集中的一个示例,看看它长什么样。
dataset = dataset["train"]
dataset[0]
{'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=358x461 at 0x7F9488DBB090>,
'label': 208}
让我们从标签列开始。它包含图像的父文件夹。在这种情况下,标签列代表了图像所取书籍的出版年份。我们可以使用 dataset.features 查看其映射。
dataset.features['label']
在这个特定的数据集中,图像文件名也包含了一些关于图像来源书籍的元数据。有几种方法可以获取这些信息。
当我们查看数据集中的一个示例时,image 特征是一个 PIL.JpegImagePlugin.JpegImageFile。由于 PIL.Images 具有文件名属性,因此获取文件名的一种方法是访问它。
dataset[0]['image'].filename
/root/.cache/huggingface/datasets/downloads/extracted/f324a87ed7bf3a6b83b8a353096fbd9500d6e7956e55c3d96d2b23cc03146582/embellishments_sample/1920/000499442_0_000579_1_[The Ring and the Book etc ]_1920.jpg
因为我们可能希望稍后轻松访问此信息,所以让我们创建一个新列来提取文件名。为此,我们将使用 map 方法。
dataset = dataset.map(lambda example: {"fname": example['image'].filename.split("/")[-1]})
现在我们可以看一个例子,看看它是什么样子。
dataset[0]
{'fname': '000499442_0_000579_1_[The Ring and the Book etc ]_1920.jpg',
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=358x461 at 0x7F94862A9650>,
'label': 208}
我们现在已经获取了元数据。我们来看看一些图片吧!如果访问一个示例并索引到 image 列中,我们将看到我们的图片 😃
dataset[10]['image']

注意:在这篇博文的早期版本中,下载和加载图像的步骤要复杂得多。新的 ImageFolder 加载器使这个过程变得容易得多 😀 特别是,我们不再需要担心如何加载图像,因为数据集已经为我们处理了这一点。
将所有内容推送到中心!

🤗 生态系统中最棒的事情之一是 Hugging Face Hub。我们可以使用 Hub 来访问模型和数据集。它通常用于与他人共享工作,但它也可以作为进行中工作的有用工具。datasets 最近添加了一个 push_to_hub 方法,允许您以最小的麻烦将数据集推送到 Hub。这可以通过让您传递一个已经完成所有转换等的数据集来提供很大帮助。
目前,我们将把数据集推送到 Hub,并暂时保持私有。
根据您运行代码的位置,您可能需要进行身份验证。您可以使用 huggingface-cli login 命令进行身份验证,或者,如果您在笔记本中运行,则使用 notebook_login。
from huggingface_hub import notebook_login
notebook_login()
dataset.push_to_hub('davanstrien/embellishments-sample', private=True)
注意:在这篇博客文章的早期版本中,我们必须做更多步骤来确保在使用
push_to_hub时嵌入图像。得益于这个拉取请求,我们不再需要担心这些额外的步骤。我们只需要确保embed_external_files=True(这是默认行为)。
切换机器
至此,我们已经创建了一个数据集并将其移动到 Hub。这意味着可以在其他地方继续工作/使用数据集。
在这个特定的例子中,访问 GPU 很重要。使用 Hub 作为传递数据的方式,我们可以在笔记本电脑上开始工作,然后在 Google Colab 上继续工作。
如果我们将代码转移到新机器上,我们可能需要重新登录。登录后,我们就可以加载数据集了。
from datasets import load_dataset
dataset = load_dataset("davanstrien/embellishments-sample", use_auth_token=True)
创建嵌入 🕸
我们现在有了一个包含大量图像的数据集。为了开始创建我们的图像搜索应用程序,我们需要嵌入这些图像。有多种方法可以尝试这样做,但一种可能的方法是使用 sentence_transformers 库通过 CLIP 模型。OpenAI 的 CLIP 模型学习图像和文本的联合表示,这对于我们想要做的事情非常有用,因为我们想要输入文本并获得图像。
我们可以使用 SentenceTransformer 类下载模型。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('clip-ViT-B-32')
该模型将以图像或文本作为输入,并返回一个嵌入。我们可以使用 datasets 的 map 方法来使用该模型编码所有图像。当我们调用 map 时,我们返回一个字典,其中键 embeddings 包含模型返回的嵌入。我们还在调用模型时传递 device='cuda';这确保我们在 GPU 上进行编码。
ds_with_embeddings = dataset.map(
lambda example: {'embeddings':model.encode(example['image'], device='cuda')}, batched=True, batch_size=32)
我们可以通过使用 push_to_hub 推送回 Hub 来“保存”我们的工作。
ds_with_embeddings.push_to_hub('davanstrien/embellishments-sample', private=True)
如果我们将代码迁移到不同的机器上,我们可以通过从 Hub 加载来重新获取我们的工作 😃
from datasets import load_dataset
ds_with_embeddings = load_dataset("davanstrien/embellishments-sample", use_auth_token=True)
我们现在有一个新列,其中包含图像的嵌入。我们可以手动搜索这些并将其与一些输入嵌入进行比较,但数据集有一个 add_faiss_index 方法。它使用 faiss 库来创建用于搜索嵌入的高效索引。有关此库的更多背景信息,您可以观看此 YouTube 视频。
ds_with_embeddings['train'].add_faiss_index(column='embeddings')
Dataset({
features: ['fname', 'year', 'path', 'image', 'embeddings'],
num_rows: 10000
})
图像搜索
注意:这些示例是根据完整版数据集生成的,因此您可能会得到略微不同的结果。
我们现在拥有一切所需,可以创建一个简单的图像搜索。我们可以使用编码图像的相同模型来编码一些输入文本。这将作为我们尝试寻找相似示例的提示。让我们从“蒸汽机”开始。
prompt = model.encode("A steam engine")
我们可以使用数据集库中的另一个方法 get_nearest_examples 来获取与我们输入提示嵌入相似的图像。我们可以传入我们想要返回的结果数量。
scores, retrieved_examples = ds_with_embeddings['train'].get_nearest_examples('embeddings', prompt, k=9)
我们可以索引到它检索的第一个示例
retrieved_examples['image'][0]

这不太像蒸汽机,但也不是完全奇怪的结果。我们可以绘制其他结果,看看返回了什么。
import matplotlib.pyplot as plt
plt.figure(figsize=(20, 20))
columns = 3
for i in range(9):
image = retrieved_examples['image'][i]
plt.subplot(9 / columns + 1, columns, i + 1)
plt.imshow(image)

其中一些结果看起来与我们的输入提示相当接近。我们可以将其封装在一个函数中,以便更轻松地尝试不同的提示。
def get_image_from_text(text_prompt, number_to_retrieve=9):
prompt = model.encode(text_prompt)
scores, retrieved_examples = ds_with_embeddings['train'].get_nearest_examples('embeddings', prompt, k=number_to_retrieve)
plt.figure(figsize=(20, 20))
columns = 3
for i in range(9):
image = retrieved_examples['image'][i]
plt.title(text_prompt)
plt.subplot(9 / columns + 1, columns, i + 1)
plt.imshow(image)
get_image_from_text("An illustration of the sun behind a mountain")

尝试一堆提示 ✨
现在我们有了一个获取一些结果的函数,我们可以尝试各种不同的提示。
其中一些我会选择宽泛的“类别”提示,例如“乐器”或“动物”,而另一些则是具体的,例如“吉他”。
出于兴趣,我还尝试了一个布尔运算符:“猫或狗的插图”。
最后我尝试了一些更抽象的东西:“一个空虚的深渊”
prompts = ["A musical instrument", "A guitar", "An animal", "An illustration of a cat or a dog", "an empty abyss"]
for prompt in prompts:
get_image_from_text(prompt)




我们可以看到这些结果并非总是正确的,但通常是合理的。这似乎已经对在该数据集中搜索图像的语义内容有用。然而,我们可能暂时不会按原样分享它……
创建 Hugging Face Space?🤷🏼
这种项目下一步显而易见的行动是创建一个 Hugging Face Space 演示。我已经在其他模型上这样做了。
从我们目前所达到的阶段开始,设置一个 Gradio 应用程序是一个相当简单的过程。这是该应用程序的屏幕截图。
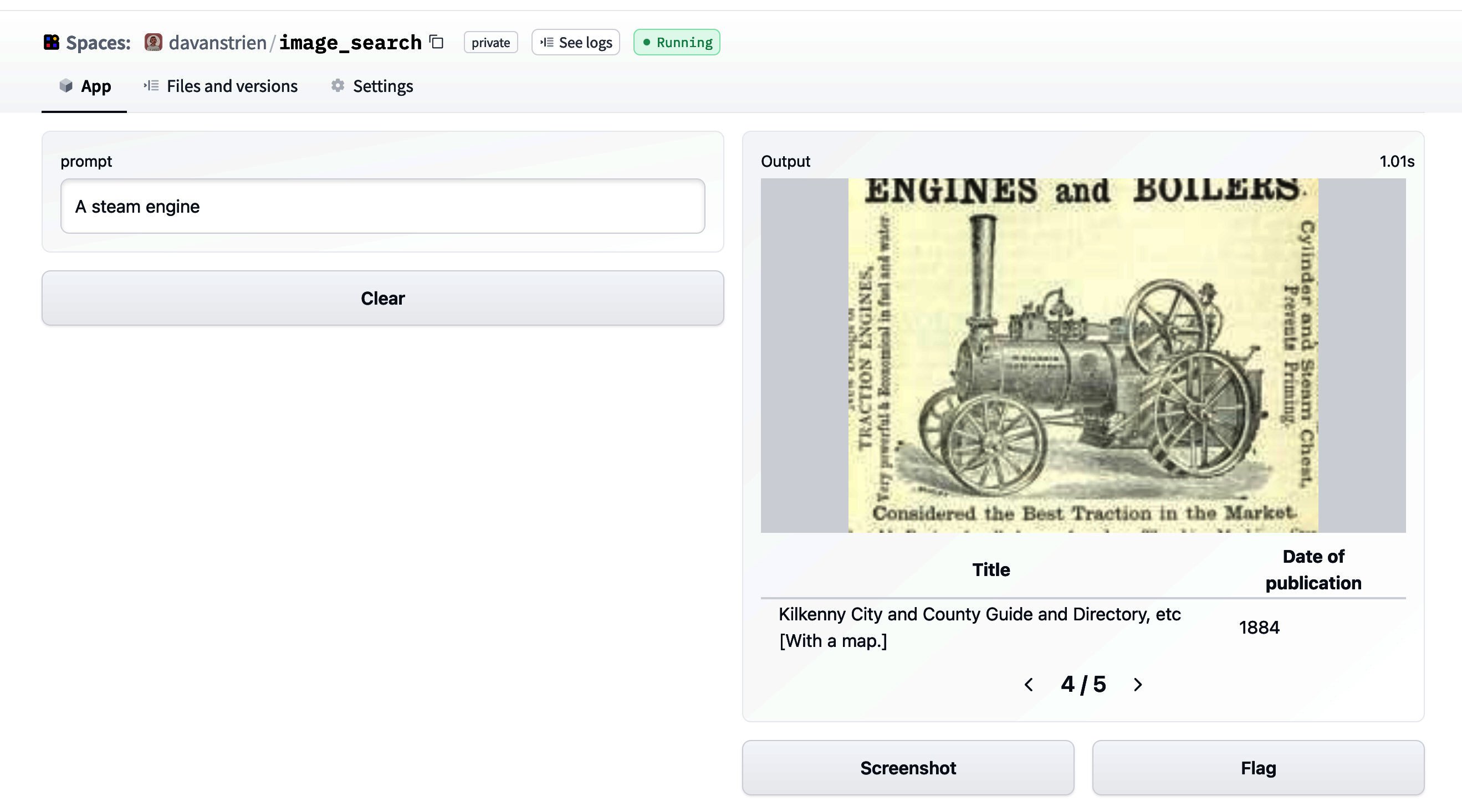
然而,我对立即公开它有点犹豫。查看 CLIP 模型的模型卡,我们可以了解其主要预期用途。
主要预期用途
我们主要设想该模型将由研究人员使用,以便更好地了解计算机视觉模型的鲁棒性、泛化能力以及其他功能、偏见和限制。来源
这与我们在此感兴趣的内容相当接近。特别是,我们可能对模型如何处理我们数据集中的图像(主要是 19 世纪书籍中的插图)感兴趣。我们数据集中的图像与训练数据(可能)大相径庭。一些图像也包含文本的事实可能对 CLIP 有帮助,因为它显示出一定的OCR 能力。
然而,查看模型卡中超出范围的用例
超出范围的用例
该模型的任何部署用例——无论是商业的还是非商业的——目前都超出了范围。非部署用例,例如在受限环境中的图像搜索,也不建议使用,除非对具有特定固定类分类法的模型进行彻底的域内测试。这是因为我们的安全评估表明,由于 CLIP 性能随不同类分类法的变化而变化,因此对任务特定测试的需求很高。这使得未经测试和不受限制地部署该模型在任何用例中目前都可能有害。> 来源
这表明“部署”不是一个好主意。虽然我得到的结果很有趣,但我还没有对模型进行足够的测试(也没有进行更系统的评估以了解其性能和偏差),因此对“部署”它没有信心。另一个额外的考虑是目标数据集本身。图像取自涵盖各种主题和时间段的书籍。有大量书籍代表殖民态度,因此其中包含的一些图像可能会以负面方式代表某些人群。这可能与允许任意文本输入编码为提示的工具结合起来造成不良后果。
也许有办法解决这个问题,但这需要更多的思考。
结论
尽管我们没有一个漂亮的演示来展示,但我们已经看到了如何使用 datasets 来
- 将图像加载到新的
Image特征类型中 - 使用
push_to_hub“保存”我们的工作,并用它在机器/会话之间移动数据 - 为图像创建
faiss索引,我们可以用它从文本(或图像)输入中检索图像。

