Fish Speech V1 - 新的多语言开源 TTS 模型







介绍
Fish Audio 最新的 TTS 模型 Fish Speech V1 已发布,并可在 Hugging Face 上获取。代码可在 Github 上找到。通过此次发布,我们兑现了五个月前在大型多语言数据集上训练模型的承诺,甚至超越了它。
Fish Speech 1 是一系列 TTS 模型,每个模型都在英语、中文和日语语音上训练了 5 万小时,总计 **15 万小时**。这种广泛的训练需要 16xA800 GPU 一周的时间,之后在 1000 小时高质量混合语言数据集上进行了 SFT。我们发布了预训练模型和 SFT 模型,从而产生了我们见过的最强大的开源文本转语音模型。
值得注意的是,Fish Speech 是唯一一个以每秒约 20 个 token 运行的开源 TTS 模型。这种速度使我们能够更快地生成内容(在 4090 GPU 上每秒约 20 秒),从而减少丢失或重复单词和句子的可能性。
我们计划在接下来的一周发布 Medium (400M) 和 Large (1B) 的预训练模型和 SFT 模型。
演示
我们提供了以下演示
- Fish Audio 网站 (medium sft):https://fish.audio/text-to-speech/
- Hugging Face Space (medium sft):https://huggingface.co/spaces/fishaudio/fish-speech-1
根据您的数据进行微调
开源 Fish Speech 允许每个人自定义和试验它。要微调该软件,请遵循以下步骤
- 将您的数据分成 10 秒的块,存储相应的文本,并将其量化。
- 开始微调您的语言模型。
- (可选)微调 VQ 解码器以增强音色相似性。
社区在我们的文档页面上提供了分步教程:https://speech.fish.audio/en/。
技术细节
规模扩展
考虑到扩展定律,我们将模型从 4 亿参数扩展到 10 亿参数,并将数据大小从 1 万小时增加到 15 万小时。这带来了显著的改进。
稳定解码
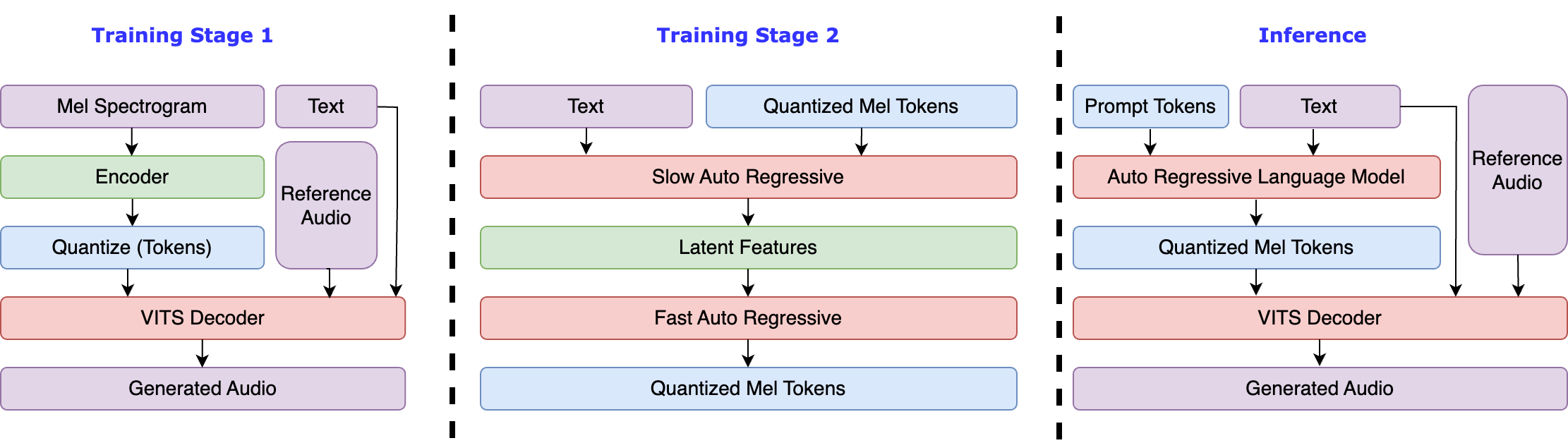
然而,我们发现 Fish Speech 1 的生成不稳定,在使用朴素码本解码策略时可能会引入伪影和丢失单词。因此,我们探索了各种码本解码策略,包括
- 朴素 (Fish Speech V0.4):同时解码所有码本。
- AR+NAR (bark):使用类似 GPT 的模型解码最重要的码本(依赖于 RVQ),然后使用类似 BERT 的模型解码其余码本。
- 延迟模式 (Parler TTS, Stable TTS):将编码掩码移动一位。
- 双重 AR,也称为慢速-快速 (UniAudio):使用一个 AR 解码隐藏特征(每秒约 20 个 token),然后使用另一个 AR 解码码本。
我们发现双重 AR 是语音生成最可靠的方法,因为其他方法无法保证码本之间的依赖关系。当码本数量显著增加(而非 RVQ)时,所有其他方法都失败了。
更好的压缩率
另一个关键方面是矢量量化。各种论文表明,随着码本大小的增加,VQ 的码本利用率急剧下降。因此,我们探索了 Vector Quantize PyTorch 提供的 FSQ 和 LFQ。FSQ 表现最佳。
在残差量化或分组量化之间进行选择带来了另一个问题。分组量化具有更好的压缩比,但缺乏强烈的依赖性(如 RVQ 中的从粗到细),使其更难学习。我们发现双重 AR 可以正确预测它们。
下一步
我们计划在未来几周内将我们的模型整合到 TTS 领域。在接下来的几个月里,我们将继续收集预训练数据,以将我们的模型扩展到更多语言。此外,我们旨在通过引入 RLHF 来提高我们的数据质量。





