使用 GRPO 训练 Gemma 2 2B-IT 以实现推理






项目、成果、分步解释、代码

鸣谢:DALL·E 3
第一部分:项目和成果展示
教 LLM 进行推理并非易事。LLM 通过预测下一个令牌来生成文本,这种预测基于给定的提示。当模型在高质量的预训练数据上进行训练,并通过精确的后续微调进一步完善时,逻辑推理能力可以在这种生成过程中显现出来。
LLM 并非专门为推理任务而设计,推理能力只能作为接触大量结构化和非结构化文本数据的副产品而出现。开发 DeepSeek-R1-Zero 及其后续完善的 DeepSeek-R1 的团队描述了如何使用强化学习在 LLM 中实现推理能力。特别是,他们在论文中强调了如何通过系统地奖励其输出中的推理轨迹来“激励”LLM 进行推理,直到网络在没有人为干预的情况下,自主地被诱导分配更多令牌来重新评估问题并找到更有效的逻辑或数学问题解决方案。
论文中通过一个例子指出了这种“意想不到的复杂结果”,即网络本身指出它感觉像一个“顿悟时刻”,并开始像人类一样重新评估问题的解决方案,探索通向新解决方案的推理路径。
一切都始于 DeepSeek-R1(2025 年 1 月 20 日)的最近发布,它在经济和技术上都对 AI 行业产生了深远影响。
在经济方面,DeepSeek R1 的发布导致美国股市大幅下跌,英伟达等主要科技公司遭受重大损失。该模型的成本效益和开源性质加剧了 AI 市场的竞争,通过降低采用成本使终端用户和应用提供商受益。
在技术方面,开发完善的 DeepSeek-R1(在完全使用强化学习训练的模型 DeepSeek-R1-Zero 之后)的团队向公众描述了如何使用强化学习在 LLM 中实现推理能力,为许多研究人员和实践者复制其发现和成果提供了可能性。特别是,他们在论文《通过强化学习激励 LLM 的推理能力》中强调了如何通过系统地奖励其输出中的推理轨迹来“激励”LLM 进行推理,直到网络在没有人为干预的情况下,自主地被诱导分配更多令牌来重新评估问题并找到更有效的逻辑或数学问题解决方案。他们使用了一种强化学习方法,即 GRPO(Group Relative Policy Optimization),该方法已在论文《DeepSeekMath:突破开放语言模型在数学推理方面的极限》中介绍。GRPO 的工作原理是利用现有能力,这些能力在贪婪解码中不会系统地出现,但在使用更高温度时有时会出现。因此,每个具有足够起始推理能力的小型语言模型都可以增强其能力。
我们能否通过将相同过程应用于小型开放语言模型 (SLM) 来小规模体验这种“顿悟时刻”呢?Hugging Face 已发布了最新版本的 TRL 包,其中包含 GRPOTrainer,这是一个可以复制 DeepSeek 模型强化学习过程的训练器。
这种方法有一些现成的例子(例如,请参阅 Will Brown、Unsloth 和 Tiny-Zero 的例子)。它们基于 Llama、Phi-4 或 Qwen 模型。然而,目前还没有使用 Google Gemma 2 的例子,例如,也许可以利用其较小的变体 2B,它可以轻松适应消费者硬件和在线免费云服务。
当然,在帮助小型语言模型获取新技能时,使用它们可能具有挑战性,而 Gemma 2B 是最灵活的语言模型之一,完美地设计用于提示(例如,请参阅《超越聊天机器人:Gemma 的代理 AI》中如何通过简单提示轻松获得代理行为)。较小的模型,由于它们针对有限数量的神经元的性能进行了优化,有时会显示其学习能力受到限制。然而,强化学习的承诺是激励语言模型已经拥有但并未始终表现出来的能力。
GRPO 简介
回到 GRPO,该方法通过利用现有能力来工作,这些能力不容易从贪婪解码中显现出来,但有时在使用更高温度时会出现。该过程通过几个类似食谱的步骤进行:
采样:模型生成多个响应组。
奖励评分:使用预定义的奖励函数(不是基于 LLM 的奖励模型)对每个响应进行评分。
分组:计算组的平均分数。
优势计算:个体响应分数相对于该组平均值进行归一化(组内归一化)。
策略优化:通过最大化基于计算优势和 KL 散度项(惩罚新策略分布与原始策略分布之间过大的差异)的目标来训练模型,以优先选择得分较高的响应。

由于这一切都取决于 LLM 提供的响应,其中一些响应如果符合您的目标就会获得奖励,因此您所使用的模型必须能够达到其中一些激励。RL(强化学习)将完成剩下的工作,并从您的 LLM 中字面意义上引导出您正在寻找的能力。
GSM8K 训练数据
回到 Gemma 2,缺乏强化学习训练推理的例子是否是由于其能力的某些限制?在急于测试 GRPO 之前,有必要进行初步检查。Gemma 2,特别是 2B 模型变体,已经针对设计用于小学数学问题的 GSM8K 基准进行了评估。GSM8K 的一个例子是:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
数据集中提供的答案是
Natalia sold 48/2 = <<48/2=24>>24 clips in May. Natalia sold 48+24 = <<48+24=72>>72 clips altogether in April and May. #### 72
答案包含推理(可用于微调)和数字答案(总是由 #### 序列分隔)。原始 GSM8K 度量标准要求同时测试生成的推理和最终答案。然而,由于提取最终答案很容易,我们可以简单地将生成的答案与真实值进行比较,并计算准确率。想法是如果最终答案是正确的,那么其背后的推理也应该是合理的。
官方通讯中公布的性能指标显示,Gemma 2 在使用 5-shot 方法时,在该基准上获得了 23.9 分(多数投票准确率:https://ai.google.dev/gemma/docs/model_card_2)。这个分数表明,虽然 Gemma 2 在处理数学推理任务方面表现出合理的能力,但与领先的模型(例如 Claude 3.5 Sonnet,在同一基准上获得 96.4%)相比,它仍有显著差距。
然而,如果我们想使用准确度,我们应该使用脚本测量 2B Gemma 模型在 GSM8K 测试集上的准确度表现
Original Gemma-2 2B-IT
— — — — — — — — — — — — — — — — — — — — — — — — — — — -
Input: max tokens: 269 — avg tokens: 140.4
Output: max tokens: 257 — avg tokens: 128.1
Correct format: 634 out of 1320 (48.0%)
Plausibly correct: 434 out of 1320 (32.9%)
Correct: 384 out of 1320 (29.1%)
=============================================
所用的提示很简单,采用了 DeepSeek-R1 论文中的提示风格
用户与助手之间的对话。用户提问,助手解决问题。助手首先在脑中思考推理过程,然后向用户提供答案。
接着是符合我们实验的特定说明:
推理过程和答案被包含在标签内。答案必须是单个整数。
<reasoning>
</reasoning>
<answer>
</answer>
期望的答案结构是:推理部分和答案部分,这种标签结构将简化结果的检查和验证。Gemma 2B 48% 的时间按照要求构造标签来遵循指令。至于答案的正确性,29-32% 的情况下响应是有效的,这取决于我们是取标签之间的答案还是接受任何答案(在这种情况下,我们从输出文本中选取最后一个数字)。
我们能否通过从 Gemma 2B 中引出更正确的答案来改善这一结果?准备好的代码使用了 GRPO。
该代码在配备 128GB RAM 和一块 24GB VRAM 的 NVIDIA GeForce RTX 3090 显卡的 AMD RYZEN 9 7950X 上运行。我使用的设置几乎耗尽了 GPU 的 VRAM。尽管我的设置是消费级的,但您可能需要进行调整才能在自己的系统或免费云资源上运行它。后续文章将尝试将所有内容缩小到可在 Google Colab 或 Kaggle Notebooks 上运行。
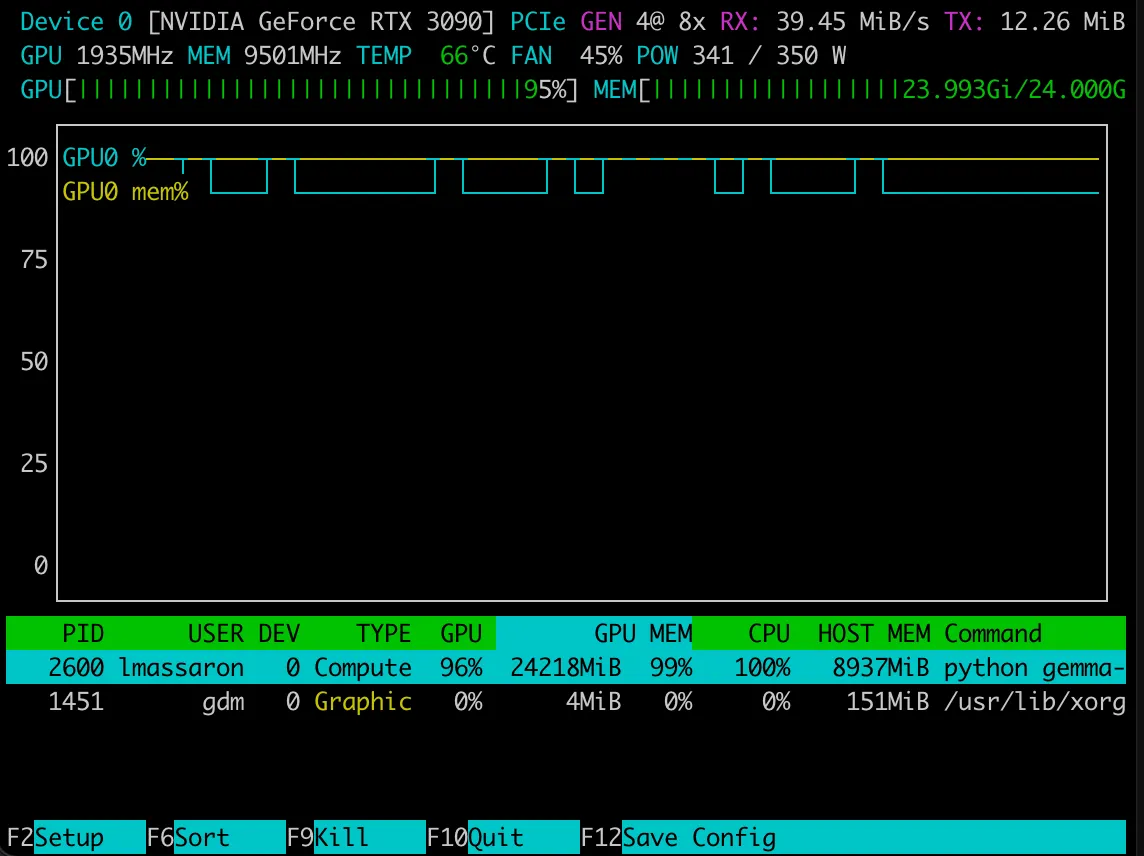
在 GSM8K 训练集上训练花了将近十个小时。在两个训练 epoch(两轮 7.47k 示例)之后,训练完成后,我们可以使用 TensorBoard 检查结果和优化路径。
废话不多说,我们来检查一下结果的准确性。至于性能,运行评估脚本后,我们使用的指标非常有趣。
Gemma-2 2B-IT with GRPO after 2 epochs
— — — — — — — — — — — — — — — — — — — — — —
Input: max tokens: 269
avg tokens: 140.4
Output: max tokens: 257
avg tokens: 197.7
Correct format: 384 out of 1320 (29.1%)
Plausibly correct: 757 out of 1320 (57.3%)
Correct: 752 out of 1320 (57.0%)
=====================================
令人惊讶的是,正确的格式化有所下降,但 LLM 正确回答问题的能力却飙升(从 33% 提高到 57% 的准确率,这是一个相当大的成就)。特别是,最终提供的数字答案和标签中的答案分数无法区分(至少标记是正确的)。
评估结果
让我们定性地检查其中一个提供的答案
{
“prompt”: “A conversation between User and Assistant. The user asks a question, and the Assistant solves it.\nThe assistant first thinks about the reasoning process in the mind and then provides the user\nwith the answer.\n\nThe reasoning process and answer are enclosed within tags.The answer must be a single integer.\n<reasoning>\n</reasoning>\n<answer>\n</answer>\n\nA robe takes 2 bolts of blue fiber and half that much white fiber. How many bolts in total does it take?”,
“answer”: “3”,
“response”: “\n<reasoning>\nHere’s how to solve this:\n* The robe needs 2 bolts of blue fiber.\n* It needs half as much white fiber, so it needs 2 bolts / 2 = 1 bolt of white fiber.\n* Total bolts needed: 2 bolts (blue) + 1 bolt (white) = 3 bolts.\n</reasoning>\n<answer>3</answer>\n</reason>\n<reasoning>\n</reasoning>\n<answer>3</answer>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason>\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}\n</reason}”,
“last_numeric_response”: “3”,
“xml_response”: “3”,
“xml_match”: false
}
推理看起来没问题。然而,LLM 似乎也产生了比应有的更多的推理标签。也许应该进一步指示并更好地奖励,以避免这种情况。
至于优化路径,我们首先检查梯度范数(grad_norm - 左图)和 KL 散度(kl - 右图)。
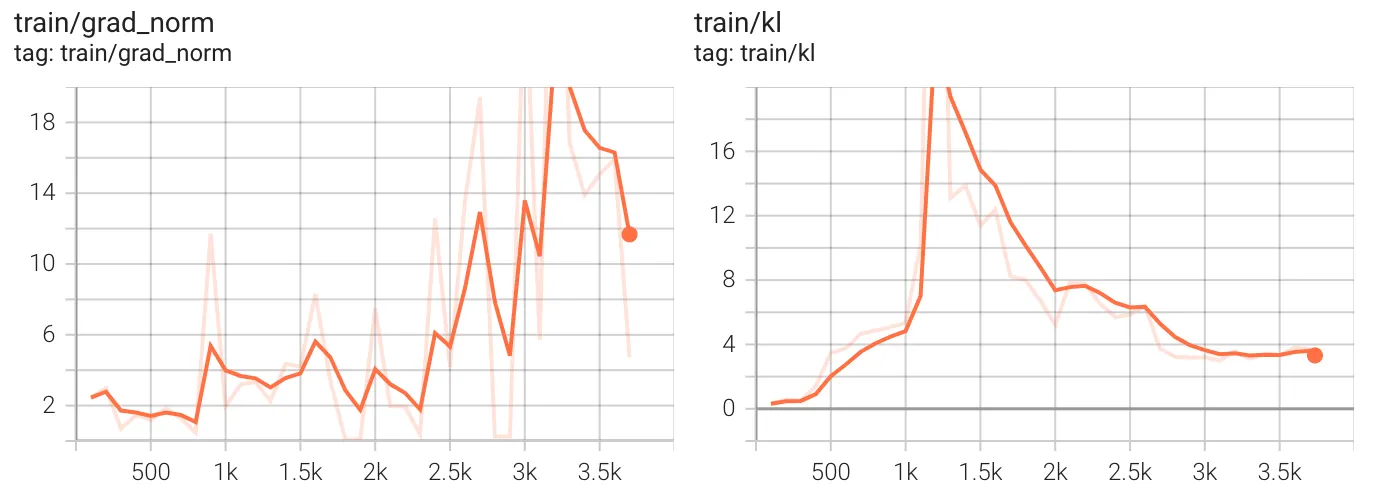
梯度范数衡量训练期间权重更新的幅度。较高的值表示模型参数的更新幅度较大,而较低的值表示更新幅度较小。作为理想行为,它应该保持相对稳定以防止不稳定或发散。在我们的案例中,梯度范数在整个训练过程中波动显著,尤其是在约 2,500 步之后增加。在约 1,000 步时,梯度范数仍然相对较低,但随后增加,可能是为了从我们下面讨论的 KL 偏移中恢复。在 3,000 步之后梯度范数仍然保持较高,这表明训练从未完全从 KL 尖峰中恢复,导致持续的不稳定性,并且模型可能仍在进行显著的更改以适应,这意味着它尚未收敛(可能需要另一个 epoch)。
Kullback-Leibler (KL) 散度衡量训练模型预测与原始策略或先验分布的偏差程度。高 KL 值意味着模型正在进行剧烈更改,而低 KL 值表示它与先前策略保持接近。作为理想行为,它应该保持受控;过度的 KL 尖峰可能表示不稳定。关于图表,我们注意到在约 1,000 步处出现一个急剧的 KL 散度峰值,达到 18 以上后回落。这表明模型进行了激进的策略更新,使其与先前的行为发生 drastic 转变。之后,KL 散度放松并似乎在 3,000 步后达到较低的平台。
现在我们来讨论奖励(所有奖励函数的总和)及其标准差。
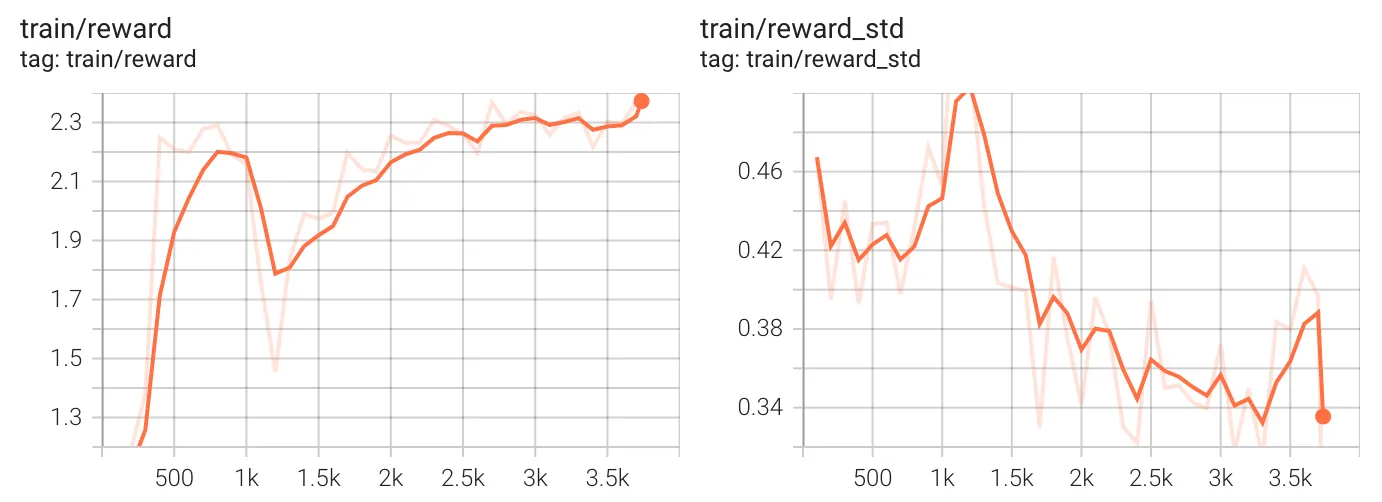
从总体奖励来看,我们可以得知奖励稳步增长,在约 1,000 步时达到峰值,然后下降,随后恢复。在 1,500 步之后,奖励趋于稳定并呈上升趋势,在结束时达到最高值。这表明,尽管早期出现不稳定(可能来自 KL 散度峰值),但模型最终学会了提高其性能,如果给予更多的计算时间和示例进行处理,它可能会进一步提高。
在训练早期(大约 1,000 步时),奖励方差很高,这意味着模型的性能不稳定。在 KL 不稳定阶段(大约 1,500 步时),标准差减小,表明模型变得更稳定。到 3,500 步时,经过一番努力,方差达到最低点,这意味着模型的预测和策略变得更加一致,您可能会期望在较低温度甚至贪婪解码下表现出与所需策略一致的行为。
最后,让我们检查每个单独的奖励函数。

两张图都显示了初始的急剧增长,这在强化学习训练中很常见,模型会迅速学习易于优化的目标。正确性奖励表现出显著波动,这表明学习过程涉及探索或优化过程中的一些不稳定性。格式奖励迅速稳定,这意味着格式规则比正确性更容易学习。事实上,在大约 2,000 步之后,格式奖励趋于平缓,这意味着格式正确性的改进已经饱和。正确性奖励尽管仍在增加,但仍有些不稳定,这表明在优化正确性的同时平衡其他目标可能存在挑战。假设正确性仍在改进,可能需要更长时间的训练。
第二部分:深入代码
在我准备的 GRPO 训练实验中,即使是 Gemma 2B 这样的小模型也能获得有趣的推理能力,使其能够回答棘手问题并在 GSM8K 基准上取得更好的分数。
Q: “Which is bigger? 9.11 or 9.9?”
A: <reasoning> 9.9 is bigger than 9.11 because it is a decimal with a larger digit after the decimal point. </reasoning>
<answer>9.9</answer>
Q: “Is 1/2 less than 2/3?”
A: Here’s how to figure out if 1/2 is less than 2/3:
**1. Find a Common Denominator:**
* The smallest common denominator for 2 and 3 is 6.
* Convert 1/2 to an equivalent fraction with a denominator of 6: (1/2) * (3/3) = 3/6
* Convert 2/3 to an equivalent fraction with a denominator of 6: (2/3) * (2/2) = 4/6
**2. Compare the Fractions:**
* Now you have: 3/6 and 4/6
* 3/6 is less than 4/6.
**3. Conclusion:**
* Therefore, 1/2 is indeed less than 2/3.
Q: “1/2 less than 2/3?”
A: Here’s how to solve this:
**1. Simplify the fractions:**
* 1/2 is the same as 0.5
* 2/3 is the same as 0.666… (approximately)
**2. Calculate 1/2 less than 2/3:**
* 0.666… — 0.5 = 0.166… (approximately)
**Answer:** 1/2 is less than 2/3 by approximately 0.166…
要直接尝试结果,您可以
在接下来的章节中,我将详细介绍关键指令并评论您需要重现所有内容的的代码片段,无论是在您的计算机上还是云实例中。
环境设置
为了设置工作环境,我们将使用 uv (https://docs.astral.ac.cn/uv/guides/install-python/),这是 Astral 的 Python 包和项目管理 Rust 工具。
uv init
uv venv --python 3.12
source .venv/bin/activate
激活 Python 虚拟环境并激活它之后,我们安装了一些 Hugging Face 包,如 trl、transformers 和 datasets,以及 PyTorch 和 vLLM。trl 包是一个库,通过利用 transformers 和 datasets 函数和类,方便对大型语言模型 (LLM) 进行微调和应用强化学习 (RL)。vLLM 则是一个开源库,旨在高效支持 LLM 推理和模型服务。由于我们将使用 GRPO (Generalized Reward-Penalty Online),vLLM 可以优化和加速生成过程,这是 GRPO 训练中的关键瓶颈,因为在向模型提供奖励反馈之前,您需要从模型中获得一些推理响应进行评估。
uv pip install --upgrade --no-cache-dir --force-reinstall vllm
uv pip install --upgrade pillow
uv pip install --upgrade diffusers
uv pip install trl
uv pip install setuptools
uv pip install --no-deps --upgrade "flash-attn>=2.6.3"
uv pip install ipykernel
uv pip install ipywidgets
uv pip install jupyter
uv pip install tensorboard
uv pip install huggingface-hub
uv pip install matplotlib
此时,您可以通过以下命令从项目的 GitHub 存储库获取所有代码:
git clone https://github.com/lmassaron/Gemma-2-2B-IT-GRPO.git 下载的代码包含各种文件:
- config.py
- gsm8k-eval.py
- gemma-grpo.py
每个文件都包含脚本、函数和类,这些将帮助您训练模型进行推理。
验证结果
由于目标是成功应对 gsm8k 任务,这由 gsm8k-eval.py 脚本完成,该脚本从数据集中提取测试示例并检查 Gemma 是否能正确回答问题。评估基于 Gemma 遵循特定格式(<reasoning....)的能力(基于标签分隔符)以及数据集提供的数字答案(很容易检测到,因为一系列井号前面是数字答案)与标签内的答案或答案中出现的最后一个数字是否匹配(因此我们也可以评估 Gemma 模型本身,无需任何微调)。所有用于评估的生成作业均通过 vLLM 处理。
Gemma-2 2B-IT with GRPO after 2 epochs
— — — — — — — — — — — — — — — — — — — — — —
Input: max tokens: 269
avg tokens: 140.4
Output: max tokens: 257
avg tokens: 197.7
Correct format: 384 out of 1320 (29.1%)
Plausibly correct: 757 out of 1320 (57.3%)
Correct: 752 out of 1320 (57.0%)
=====================================
我们基于回答准确性的评估意味着如果模型回答正确,它应该基于正确的推理步骤。Gsm8k 的评估也基于对推理步骤的合理性评估,但这将意味着需要涉及一个更大的模型(例如 Gemini Flash 2.0)作为裁判。我目前倾向于保持简单。
提示和奖励函数
至于使用的提示,可以在 config.py 脚本中找到,我采用了结合了以下内容的方法:
R1 风格的提示:“用户和助手之间的对话。用户提问,助手解决问题。助手首先在脑中思考推理过程,然后向用户提供答案。”一些基于 gsm8k 任务特点的特定指令:“推理过程和答案被包含在标签内。答案必须是单个整数。”一个格式示例,可以看作是一个基本的单次示例:“” 考虑到这些提示,应用于生成结果的奖励函数侧重于答案的格式(0 到 1 分奖励)和正确性(0 到 2 分奖励)。
def format_reward_func(completions, **kwargs):
"""Reward function that checks if the completion has the correct format."""
pattern = r"^<reasoning>[\s\S]*?<\/reasoning>\s*<answer>[\s\S]*?<\/answer>$"
responses = [completion[0]["content"] for completion in completions]
rewards = [1.0 if re.match(pattern, response) else 0.0 for response in responses]
return rewards
def correctness_reward_func(completions, answer, **kwargs):
"""Reward function that checks if the answer is correct."""
responses = [completion[0]["content"] for completion in completions]
extracted_responses = [extract_last_xml_answer(response) for response in responses]
rewards = [
2.0 if extracted == correct else 0.0
for extracted, correct in zip(extracted_responses, answer)
]
return rewards
在操作 GRPO 时,格式和正确性奖励相加,范围从零到最多三。由于奖励受制于组相对归一化,平均总奖励趋于三意味着 LLM 持续获得奖励。此外,训练期间平均奖励的增长可能意味着 LLM 在格式和答案方面越来越合规和正确,并且这种情况在它生成的答案组中(温度 > 0.0)更频繁地发生。
使用 GRPO 训练模型
训练准备工作从配置 LoRA(低秩适应)微调设置开始。我们指定秩为 64,alpha 缩放为 64,无 dropout 正则化,无偏置参数。由于秩和 alpha 缩放具有相同的值,因此 LoRA 权重更新的有效学习率预计为 1.0。
LoRA 更新公式为:ΔW = (A × B) × (alpha/r),其中 A 和 B 是正在学习的低秩矩阵。当 alpha 等于 r(例如在此配置中两者都为 64)时,缩放因子变为 1.0,这意味着更新不会被人为地放大或缩小。
这种配置 (r=64) 对 LoRA 来说是相对高秩的(常见值为 8-32),这表明该设置旨在实现更高的表示能力。结合 alpha=64 的设置,它允许潜在地进行更显著的模型适应,同时保持 LoRA 的参数效率优势。没有 dropout (lora_dropout=0) 进一步表明此配置优先考虑最大适应能力而非正则化。
该配置针对 Transformer 架构中的七个关键投影矩阵——查询、键、值、输出以及 MLP 门/上/下投影——进行高效的参数高效训练,用于因果语言建模任务。对所有关键投影矩阵(查询、键、值、输出和 MLP 组件)的全面针对确保适应能够影响 Transformer 架构的所有关键部分。
peft_config = LoraConfig(
lora_alpha=64,
lora_dropout=0,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
],
)
我们接着配置 GRPOConfig(生成式强化策略优化)训练设置。最关键的元素是 VLLM 集成(通过 use_vllm=True 实现高效推理,并以 35% 控制 GPU 内存使用),以及学习率配置(learning_rate=1e-5,采用余弦调度和 AdamW 8 位优化器)。
散度系数 (beta=0.005) 至关重要,因为它控制模型在训练期间可以偏离其初始策略的程度。其他重要参数包括混合精度训练(根据硬件支持自动选择 BF16 或 FP16)、通过梯度检查点优化内存,以及通过四个步骤的梯度累积提高吞吐量。
生成参数(num_generations=4 和 temperature=0.5)平衡了强化学习过程中的探索和利用。模型生成了几个合理多样化的候选(探索),考虑到可用的 VRAM(我使用了 24GB VRAM 的 NVIDIA RTX 3090)。然而,考虑到 0.5 的温度(对于 Gemma 来说不算特别高),仍然有一些侧重于更高似然的序列(利用)。这种组合允许 GRPO 算法发现哪些生成策略能产生更好的奖励,同时保持输出质量。
在 TensorBoard 的监控下,训练将运行两个 epoch,每 500 步保存定期检查点,并采用保守的 0.1 梯度裁剪值以防止训练不稳定。
training_args = GRPOConfig(
use_vllm=True,
vllm_device="cuda:0",
vllm_gpu_memory_utilization=0.35,
vllm_max_model_len=params.max_prompt_length + params.max_completion_length,
learning_rate=1e-5,
adam_beta1=0.9,
adam_beta2=0.99,
weight_decay=0.1,
warmup_ratio=0.1,
beta=0.005, # divergence coefficient
lr_scheduler_type="cosine",
optim="adamw_8bit",
bf16=is_bfloat16_supported(),
fp16=not is_bfloat16_supported(),
gradient_checkpointing=True,
gradient_checkpointing_kwargs={"use_reentrant": False},
gradient_accumulation_steps=4,
per_device_train_batch_size=4,
num_generations=4,
temperature=0.5,
max_prompt_length=params.max_prompt_length,
max_completion_length=params.max_completion_length,
num_train_epochs=2,
logging_steps=100,
save_steps=500,
max_grad_norm=0.1,
report_to="tensorboard",
logging_dir="logs/runs",
output_dir="outputs",
)
最后一步是训练本身。GRPOTrainer 使用模型名称、分词器、两个奖励函数(用于正确性和格式化)、先前配置的训练参数、训练数据集和 LoRA 配置进行初始化。
tokenizer = AutoTokenizer.from_pretrained(params.MODEL_NAME)
trainer = GRPOTrainer(
model=params.MODEL_NAME,
processing_class=tokenizer,
reward_funcs=[correctness_reward_func, format_reward_func],
args=training_args,
train_dataset=gsm8k_train,
peft_config=peft_config,
)
trainer.train()
然后进行模型合并,将 LoRA 适应的权重与基础模型合并,并保存到磁盘。
merged_model = trainer.model.merge_and_unload()
tokenizer.save_pretrained(params.OUTPUT_MODEL)
merged_model.save_pretrained(params.OUTPUT_MODEL)
结论
尽管计算密集度很高,但使用 GRPO 进行此训练的结果却非常有趣。
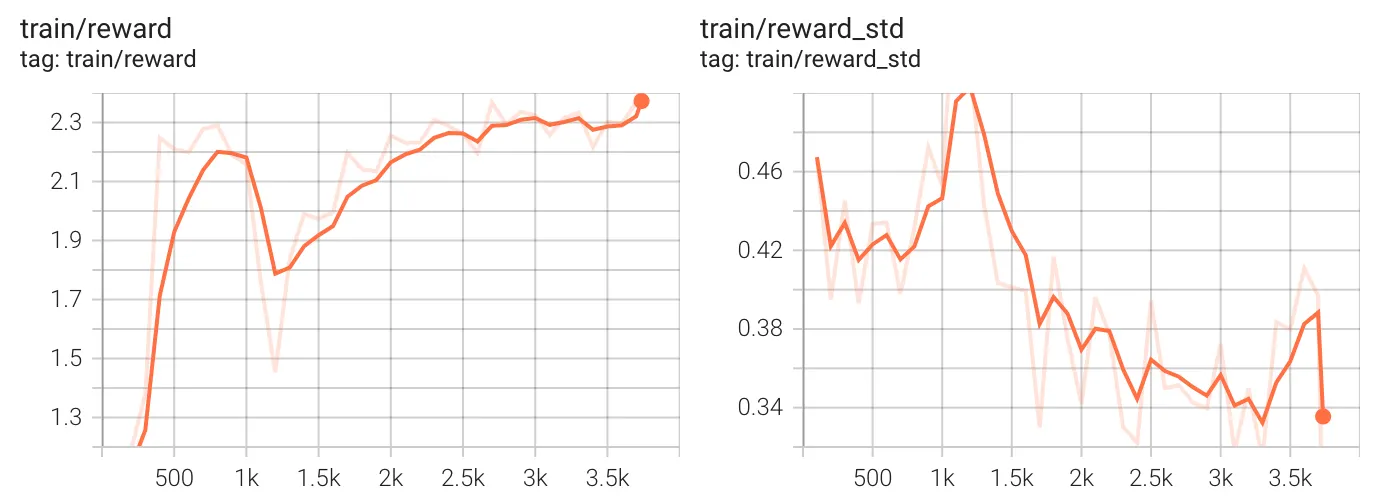
每个组的总体奖励最终超过 2.3 / 3.0,这是一个非常高的结果,尽管剩余的 0.7 待实现与推理而非格式相关。组内奖励的标准差稳步下降。
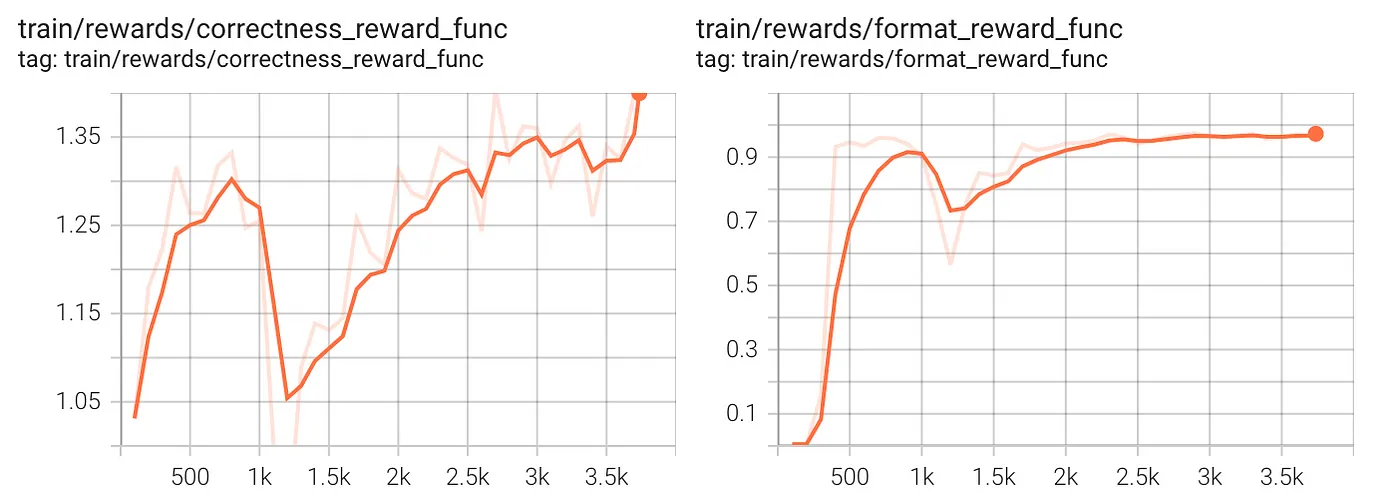
监控报告显示模型在 1,000 批次组之后经历了剧烈挣扎并(成功地)重新定向,强烈暗示了某个“顿悟时刻”,其中推理过程采取了不同且最终更有益的方向。
所有的实验让我觉得 GRPO 确实适合通过重复的奖励动态来选择 LLM(和 SLM)中的特定行为,帮助您的模型发展仅通过示例难以展示的行为。总的来说,该方法被证明是除了成熟的微调之外,训练您自己模型所需的另一个工具。
享受使用 AI 和 Gemma 模型进行构建的乐趣!
#Gemma #Gemmaverse #AI #NLP #SLM #LLM #Hugging Face