使用 NVIDIA 的 LogitsProcessorZoo 控制语言模型生成








使用语言模型生成文本通常涉及根据概率分布选择下一个 token。贪婪搜索之类的直接方法会选择最有可能的 token,但这可能导致通用或重复的输出。为了增加多样性和控制,更高级的解码策略,如束搜索、核采样和 top-k 采样,被广泛使用。这些策略由 🤗 Transformers 库支持,使我们能够灵活地塑造模型的输出。
但是,如果我们想更进一步,通过直接修改概率分布来控制文本生成过程本身,那该怎么办呢?这就是logit 处理发挥作用的地方。Hugging Face 的 LogitsProcessor API 允许您自定义语言模型头的预测分数,从而对模型行为进行细粒度控制。🤗 Transformers 库不仅提供了一组丰富的内置 logits 处理器,还使社区能够创建和共享针对独特用例的自定义处理器。
NVIDIA 的 LogitsProcessorZoo 应运而生,它是一系列功能强大、模块化的 logits 处理器,旨在完成特定任务,例如控制序列长度、强制使用关键短语或指导多项选择答案。NVIDIA 的库与 Hugging Face 的 generate 方法完全兼容,是 logits 处理领域社区驱动创新的一个绝佳范例。
在这篇文章中,我们将探讨 NVIDIA 的 LogitsProcessorZoo 如何增强和扩展现有功能,深入探讨其特性并演示它如何优化您的 AI 工作流程。
语言模型中的 Logits 是什么?
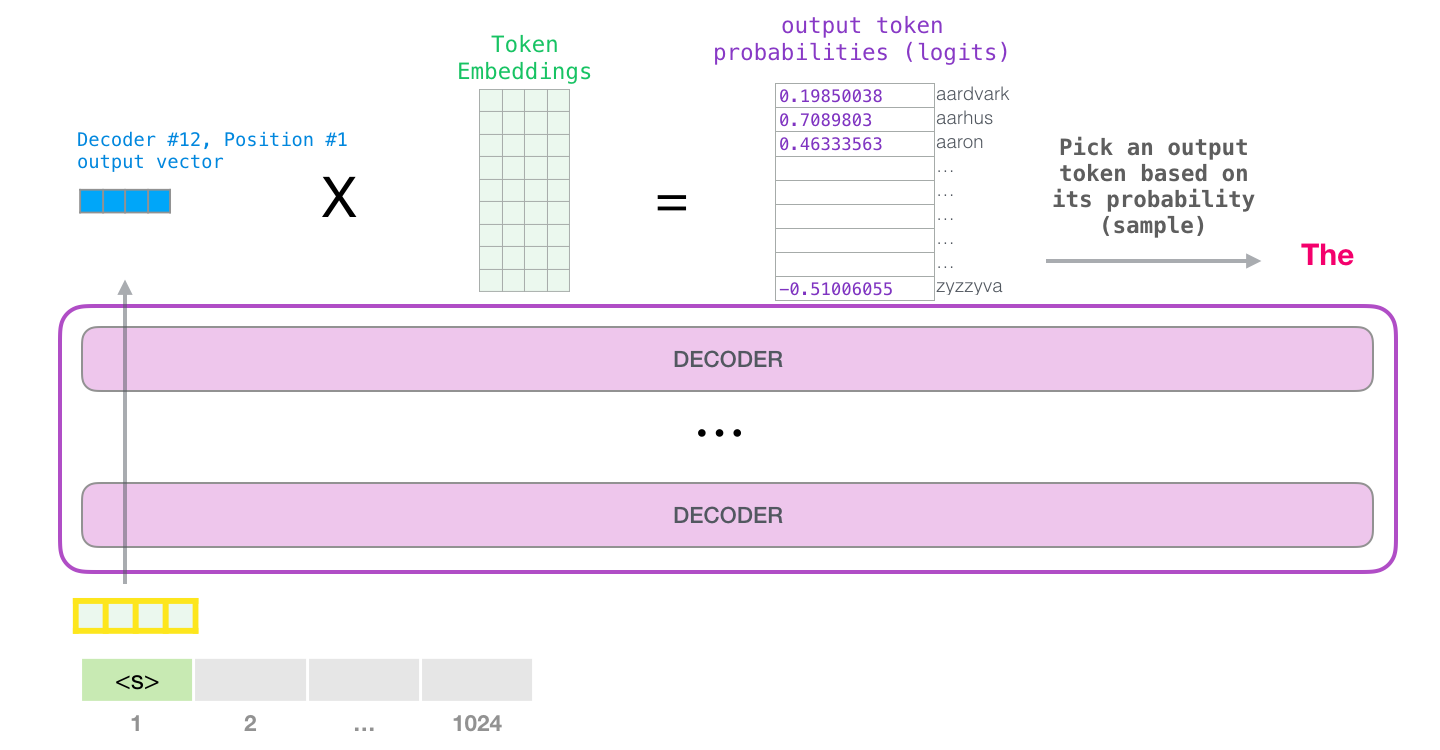 摘自:https://jalammar.github.io/illustrated-gpt2/
摘自:https://jalammar.github.io/illustrated-gpt2/
Logits 是语言模型为其词汇表中的每个 token 生成的原始、未归一化的分数。这些分数通过 softmax 函数转换为概率,从而指导模型选择下一个 token。
以下是 logits 如何适应生成过程的示例:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Load a model and tokenizer
model_name = "meta-llama/Llama-3.2-1B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
# Input text
prompt = "The capital of France is"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# Get logits
with torch.inference_mode():
outputs = model(**inputs)
logits = outputs.logits
# Logits for the last token
last_token_logits = logits[:, -1, :]
这些 logits 代表模型对每个潜在的下一个词的置信度。使用 softmax,我们可以将它们转换为概率并解码为生成的文本。
# Prediction for the next token
next_token_probs = torch.nn.functional.softmax(last_token_logits, dim=-1)
# Decode logits to generate text
predicted_token_ids = torch.argmax(next_token_probs, dim=-1)
generated_text = tokenizer.batch_decode(predicted_token_ids, skip_special_tokens=True)
print("Generated Text:", generated_text[0])
>>> Generated Text: Paris
虽然此管道演示了原始 logits 如何转换为文本,但值得注意的是 🤗 Transformers 简化了此过程。例如,generate() 方法会自动处理这些转换,包括应用 softmax 函数和从概率分布中采样。
然而,原始 logits 对于采样或施加任务特定约束等常见任务可能不理想。有关在生成过程中有效处理 logits 的更多详细信息,请参阅 Hugging Face 的生成博客文章。这就是logit 处理变得不可或缺的原因,它可以根据特定需求调整输出。
为什么要处理 Logits?
在控制输出行为时,原始 logits 常常力不从心。例如:
- 缺乏约束:它们可能不遵守所需的格式、语法规则或预定义的结构。
- 过度概括:模型可能优先选择通用响应,而不是特定、高质量的输出。
- 任务不匹配:序列可能过早结束、过于冗长或遗漏关键细节。
Logit 处理使我们能够在生成之前通过修改这些原始分数来调整模型的行为。
NVIDIA 的 LogitsProcessorZoo
NVIDIA 的 LogitsProcessorZoo 通过针对特定任务量身定制的模块化组件简化了 logits 的后处理。让我们探索其功能并了解如何使用它们。要跟随操作,请前往此笔记本并尝试 logits 处理器。
使用以下命令安装库:
pip install logits-processor-zoo
为了演示处理器,我们将创建一个简单的 LLMRunner 类,该类初始化模型和分词器,并公开 generate_response 方法。然后我们将向 generate_response 方法提供不同的处理器,并观察它们的作用。
# Adapted from: https://github.com/NVIDIA/logits-processor-zoo/blob/main/example_notebooks/transformers/utils.py
class LLMRunner:
def __init__(self, model_name="meta-llama/Llama-3.2-1B-Instruct"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto",
)
def generate_response(self, prompts, logits_processor_list=None, max_tokens=1000):
if logits_processor_list is None:
logits_processor_list = []
for prompt in prompts:
conversation = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt},
]
inputs = self.tokenizer.apply_chat_template(
conversation,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
return_dict=True,
).to(self.model.device)
outputs = self.model.generate(
**inputs,
max_new_tokens=max_tokens,
min_new_tokens=1,
logits_processor=LogitsProcessorList(logits_processor_list),
)
gen_output = self.tokenizer.batch_decode(
outputs, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# Extract only the generated output after the original input length
generated_text = gen_output[0][
len(
self.tokenizer.decode(
inputs["input_ids"][0], skip_special_tokens=True
)
) :
].strip()
print(f"Prompt: {prompt}")
print()
print(f"LLM response:\n{generated_text}")
runner = LLMRunner()
1. GenLengthLogitsProcessor
通过调整序列结束 (EOS) token 的可能性来控制生成序列的长度。
此处理器在需要控制生成文本长度的场景中特别有用,例如生成简洁摘要、限制冗余输出或根据特定用例定制响应。例如,它可以帮助确保聊天机器人提供简短而有意义的响应,同时通过在需要时完成句子来保持语法完整性。
example_prompts =[
"Tell me a story about a kid lost in forest."
]
# generate short response
print(runner.generate_response(
example_prompts,
[GenLengthLogitsProcessor(runner.tokenizer, boost_factor=0.1, p=2, complete_sentences=True)]
))
LLM 响应:从前,在一片茂密的森林里,住着一个名叫蒂米的小男孩。蒂米和他的父母以及小妹妹艾玛一起参加了家庭露营旅行。他们已经走了好几个小时,茂密的树木似乎把他们围了起来。当太阳开始下山时,蒂米意识到他已经离家远去了。起初,蒂米没有惊慌。他想叫喊他的父母和艾玛,但他的声音因为唱篝火歌曲而嘶哑。他环顾四周,但树木似乎永远延伸着,使得他无法看到任何熟悉的标志物。随着夜幕降临,蒂米的恐惧开始蔓延。
# generate long response
print(runner.generate_response(
example_prompts,
[GenLengthLogitsProcessor(runner.tokenizer, boost_factor=-10.0, p=0, complete_sentences=False)]
))
LLM 响应:从前,在茂密而充满活力的森林里,住着一个名叫马克斯的小男孩。马克斯是一个好奇心强、喜欢冒险的八岁孩子,他热爱探索户外。一个阳光明媚的下午,当他在森林里漫步时,他偶然发现了一条他从未见过的小径。马克斯对这个发现感到兴奋,决定沿着小径走,看看它会通向哪里。森林里生机勃勃,阳光透过树木过滤下来,营造出一种神奇的氛围。马克斯走了大约 20 分钟,他的眼睛扫视着周围,寻找任何文明的迹象。当太阳开始下山,给森林投下温暖的橙色光芒时,马克斯意识到他迷路了。他没有电话,没有钱包,也无法与家人联系。恐慌开始蔓延,马克斯开始感到害怕和孤独。惊慌失措的马克斯开始在森林里奔跑,心跳加速,双腿颤抖。他偶然发现了一片空地,看到了远处微弱的光线。当他靠近时,他看到了空地中央的一个小木屋。烟囱里冒着烟,马克斯能听到有人轻轻哼唱的歌声。...
在上面的示例中,我们使用 `GenLengthLogitsProcessor` 来缩短和延长模型生成的响应。
2. CiteFromPromptLogitsProcessor
提升或降低提示中的 token,以鼓励类似的输出。
这在需要上下文保留的任务中尤其有价值,例如根据段落回答问题、生成包含特定细节的摘要或在对话系统中产生一致的输出。例如,在分析用户评论的给定代码片段中,此处理器确保模型生成与评论内容密切相关的响应,例如强调对产品价格的看法。
example_prompts =[
"""
A user review: very soft, colorful, expensive but deserves its price, stylish.
What is the user's opinion about the product's price?
""",
]
# Cite from the Prompt
print(runner.generate_response(
example_prompts,
[CiteFromPromptLogitsProcessor(runner.tokenizer, example_prompts, boost_factor=5.0)],
max_tokens=50,
))
LLM 响应:根据用户评论,用户对产品价格的看法是:用户非常满意,但价格昂贵,但产品时尚、柔软、色彩丰富,这是用户愿意支付的价格。
请注意生成如何引用输入提示。
3. ForceLastPhraseLogitsProcessor
强制模型在其输出结束前包含特定短语。
此处理器在结构化内容生成场景中特别有用,在这些场景中,一致性或遵守特定格式至关重要。它非常适合生成引用、正式报告或需要特定措辞以保持专业或有条理的呈现的输出等任务。
example_prompts = [
"""
Retrieved information from: https://en.wikipedia.org/wiki/Bulbasaur
Bulbasaur is a fictional Pokémon species in Nintendo and Game Freak's Pokémon franchise.
Designed by Atsuko Nishida, Bulbasaur is a Grass and Poison-type, first appearing in Pocket Monsters: Red and Green (Pokémon Red and Blue outside Japan) as a starter Pokémon.
Since then, it has reappeared in sequels, spin-off games, related merchandise, and animated and printed adaptations of the franchise.
It is a central character in the Pokémon anime, being one of Ash Ketchum's main Pokémon for the first season, with a different one later being obtained by supporting character May.
It is featured in various manga and is owned by protagonist Red in Pokémon Adventures.
What is Bulbasaur?
""",
]
phrase = "\n\nReferences:"
batch_size = len(example_prompts)
print(runner.generate_response(
example_prompts,
[ForceLastPhraseLogitsProcessor(phrase, runner.tokenizer, batch_size)]
))
LLM 响应:根据维基百科文章检索到的信息,妙蛙种子是《宝可梦》系列中的虚构宝可梦。它是一种草系和毒系的宝可梦,并出现在各种媒体形式中,包括: - 作为第一代宝可梦游戏(包括《宝可梦红》和《宝可梦蓝》)中的初始宝可梦。 - 作为宝可梦动画中的主要角色,它是小智最早的宝可梦之一。 - 作为宝可梦漫画中的角色,由主角小赤拥有。 - 作为各种其他宝可梦媒体中的角色,例如衍生游戏和相关商品。妙蛙种子也是宝可梦系列的核心角色,经常与其他宝可梦一起出现,是宝可梦世界的关键组成部分。参考资料:- https://en.wikipedia.org/wiki/Bulbasaur
phrase = "\n\nThanks for trying our RAG application! If you have more questions about"
print(runner.generate_response(example_prompts,
[ForceLastPhraseLogitsProcessor(phrase, runner.tokenizer, batch_size)]
))
LLM 响应:妙蛙种子是《宝可梦》系列中的虚构宝可梦。它是一种草系和毒系的宝可梦,其特点是独特的外观。感谢您试用我们的 RAG 应用程序!如果您对妙蛙种子有更多疑问,请随时提出。
每次生成时,我们都能够在生成结束前添加 `phrase` 字符串。
4. MultipleChoiceLogitsProcessor
引导模型通过选择给定选项之一来回答多项选择题。
此处理器在需要严格遵守结构化答案格式的任务中特别有用,例如测验、调查或决策支持系统。
example_prompts = [
"""
I am getting a lot of calls during the day. What is more important for me to consider when I buy a new phone?
0. Camera
1. Battery
2. Operating System
3. Screen Resolution
Answer:
""",
]
mclp = MultipleChoiceLogitsProcessor(
runner.tokenizer,
choices=["0", "1", "2", "3"],
delimiter="."
)
print(runner.generate_response(example_prompts, [mclp], max_tokens=1))
LLM 响应:1
在这里,我们的模型除了选项之外什么都没有生成。这在使用代理或将模型用于多项选择题时是一个非常有用的属性。
总结
无论您是生成简洁摘要、编写聊天机器人响应,还是解决多项选择题等结构化任务,logit 处理器都提供了有效控制输出的灵活性。这使得它们在需要精确性、遵守约束或任务特定行为的场景中具有无价的价值。
如果您有兴趣进一步探索如何使用 logit 处理器控制生成,以下是一些入门资源:
- 如何使用 Transformers 生成文本 – 🤗 Transformers 中文本生成的入门指南。
- Hugging Face:生成策略 – 了解贪婪搜索、束搜索和 top-k 采样等解码策略。
- Hugging Face:LogitsProcessor API – 深入了解 logits 处理在 🤗 Transformers 中如何工作以及如何创建自定义 logits 处理器。
- NVIDIA 的 LogitsProcessorZoo – 探索 NVIDIA 库中可用的所有 logits 处理器,包括示例和用例。
借助 NVIDIA 的 LogitsProcessorZoo 和 Hugging Face 的工具,您拥有一个强大的生态系统,可以将您的语言模型应用程序提升到新的水平。尝试这些库,构建自定义解决方案,并与社区分享您的创作,以突破生成式 AI 的可能性边界。