你普通的 8GB MacBook 隐藏的 AI 算力,足以运行 70B LLM 模型,让你大开眼界!








你是不是认为你的 Apple MacBook 只能用来做 PPT、上网和追剧?如果这样想,那你可真是不懂 MacBook。
实际上,MacBook 不仅颜值在线,其 AI 能力也相当不俗。MacBook 内部搭载了一颗实力强劲的 GPU,其架构尤为适合运行 AI 模型。
**我们已发布了 AirLLM 新版本 2.8。它允许普通的 8GB MacBook 运行顶级 70B(十亿参数)模型!**而且这无需任何量化、剪枝或模型蒸馏压缩。
我们的目标是实现 AI 的民主化,让以前需要八块 A100 GPU 才能运行的顶级模型,如今在普通设备上也能运行。
一个 70B 模型,仅模型文件就超过 100GB。一台拥有 8GB 内存的普通 MacBook 是如何运行它的呢?MacBook 内部到底隐藏着怎样的惊人算力?今天,我们将为您揭示这些。
MacBook 的 AI 能力
Apple 实际上是 AI 领域一个非常有潜力的参与者。iPhone 和 MacBook 已经整合了许多 AI 模型,用于计算摄影、面部识别和视频处理。
智能手机和笔记本电脑上实时运行 AI 模型需要高性能。因此,Apple 不断发展和增强其自主研发的 GPU 芯片。
计算摄影和视频处理在底层操作上与大型语言模型基本相似,主要涉及大型矩阵的各种加减乘除运算。因此,Apple 自主研发的 GPU 芯片在生成式 AI 时代也能轻松具备竞争力。
Apple 的 M1、M2、M3 系列 GPU 实际上是非常适合 AI 计算的平台。
我们来看一些数据。
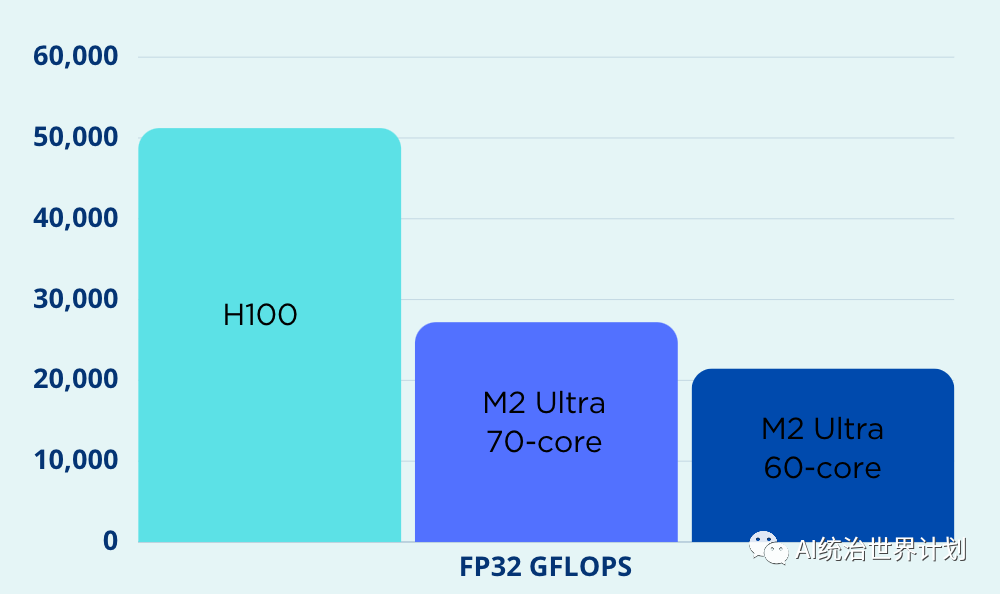
衡量 GPU 能力的主要指标之一是 FLOPS(每秒浮点运算次数),它衡量每单位时间能进行多少浮点运算。Apple 最强大的 M2 Ultra GPU 仍然落后于 Nvidia。
**然而,Apple 的优势在于内存。**大型语言模型的训练和推理常常受到内存限制。内存不足(OOM)问题是大型语言模型的一个主要噩梦。Apple 的 GPU 和 CPU 可以共享内存空间,从而实现更灵活的扩展。**M2 Ultra GPU 的内存最高可达 192GB,远远超过 Nvidia H100 的最大 80GB。**
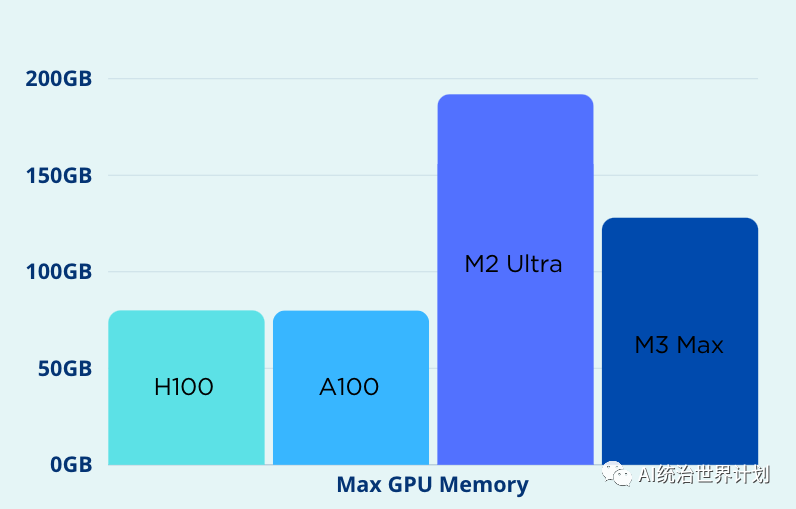
Nvidia 只能优化 GPU 架构;它无法控制 CPU。**但 Apple 可以统一优化 GPU、CPU、内存、存储等。例如,Apple 的统一内存架构允许 GPU 和 CPU 之间真正共享内存。**数据不再需要在 CPU 和 GPU 内存之间来回传输,从而无需各种零拷贝优化技术,并实现最佳性能。
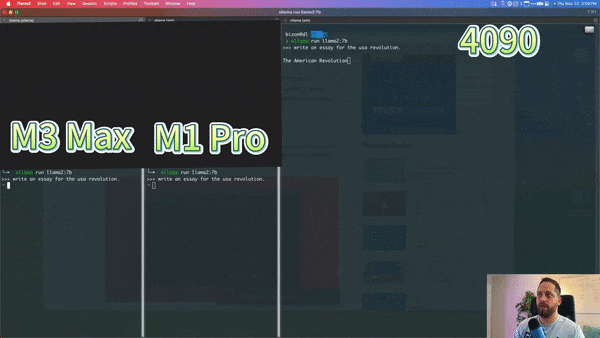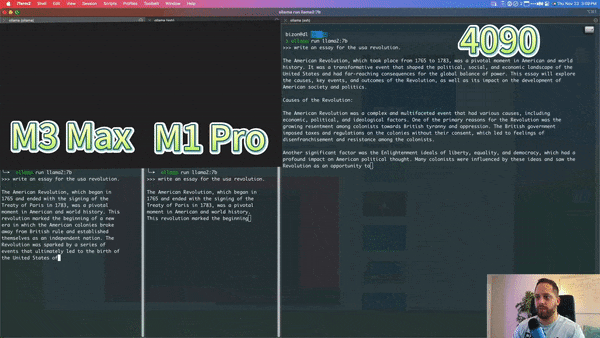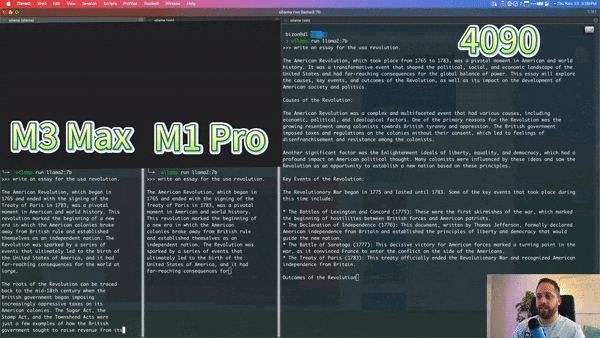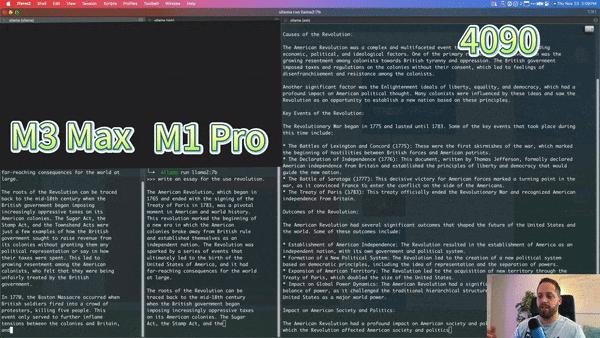
以下是 YouTube 播主对 M3 Max、M1 Pro 和 Nvidia 4090 运行 7b llama 模型进行的比较,M3 Max 的速度接近 4090
MLX 平台
Apple 发布了一个开源深度学习平台 MLX。
MLX 与 PyTorch 非常相似。其编程接口和语法与 Torch 非常接近。熟悉 PyTorch 的用户可以轻松过渡到 MLX 平台。
由于其硬件架构设计的优势,MLX 天然支持统一内存。**内存中的张量在 GPU 和 CPU 之间共享,无需数据传输,省去了大量额外开销。**
虽然 MLX 的功能不如 PyTorch 丰富,但我喜欢它的简洁、直接和清晰。或许由于 PyTorch 所背负的向后兼容性包袱,MLX 可以更灵活,更有效地进行权衡和优化性能。
AirLLM Mac
AirLLM 新版本增加了基于 XLM 平台的支持。实现方式与 PyTorch 版本相同。
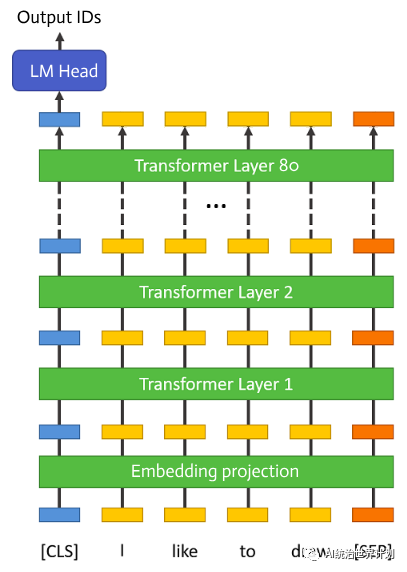
如上图所示,大型语言模型之所以庞大且占用大量内存,主要是因为其结构包含许多“层”。一个 70B 模型多达 80 层。**但在推理过程中,每一层都是独立的,只依赖于上一层的输出。**
因此,在运行完一层之后,其内存可以被释放,只保留该层的输出。基于这一理念,AirLLM 实现了**分层推理**。
有关更详细的解释,请参阅我们之前的博客:这里。
使用 AirLLM 非常简单,只需几行代码。
AirLLM 完全开源,可在 GitHub Repo 上找到。
欢迎访问我们的 GitHub 页面并与我们交流。也欢迎提出建议和贡献!
我们将继续公开分享 AI 领域的最新、最有效的新方法和新进展,为开源社区做出贡献。请关注我们。