上下文是寻找黄金段落的黄金: 评估和训练上下文文档嵌入








 传统嵌入方法(右上方)生成的嵌入不包含必要的上下文信息。我们的轻量级训练方法(InSeNT)训练上下文嵌入模型,该模型在编码段落时**感知**文档范围内的上下文(右下方),并能将文档范围内的信息整合到单个块表示中,从而提高嵌入相关性,并在不增加推理成本的情况下改善下游检索性能。
传统嵌入方法(右上方)生成的嵌入不包含必要的上下文信息。我们的轻量级训练方法(InSeNT)训练上下文嵌入模型,该模型在编码段落时**感知**文档范围内的上下文(右下方),并能将文档范围内的信息整合到单个块表示中,从而提高嵌入相关性,并在不增加推理成本的情况下改善下游检索性能。
概述
密集检索器通常独立嵌入每个段落。当相关线索分散在多个段落中时,这些模型会错误地对结果进行排名。**ConTEB**(上下文文本嵌入基准)量化了这一弱点;**InSeNT** + **后期分块池化**是解决此问题的一种有前途的方法,其微调阶段很小,几乎没有运行时开销,并在 ConTEB 上带来了巨大收益。
为什么上下文很重要?
搜索应用程序很少处理推文长度的文本。技术手册、合同、科学论文和支持工单很容易达到数千个标记。然而,用户仍然期望在段落层面获得答案。当决定性证据部分地位于段落边界之外时,一个只“看到”单个块的模型很可能会失败。上下文可以帮助解决歧义,例如区分单词的多种含义或解析代词和实体引用。当文档具有结构化格式时,例如在法律或科学文本中常见的情况,上下文也至关重要,了解段落在目录中的位置对于理解至关重要。

在上面的例子中,如果没有利用文档上下文来嵌入粗体句子“他们扩展了 […]”,那么它将是模棱两可的:我们是在谈论拿破仑军队还是巴西足球?
检索系统如何*实际*分块文档
在嵌入之前,几乎所有生产流水线都会将每个文档分解为更小的、对模型和读者友好的单元。常见策略包括:
| 策略 | 典型参数 | 原理与权衡 |
|---|---|---|
| 固定长度滑动窗口 | k ≈ 128–1024 标记,部分重叠 |
实现简单;重叠减少边界效应但增加索引大小。 |
| 结构感知块 | 标题、段落、列表项 | 保留语义单元但产生高度可变的长度。 |
| 混合 | 结构块内的固定窗口 | 结合了可预测性和对篇章结构的一定尊重。 |
设计者必须平衡 (i) 尊重 Transformer 的最大输入,(ii) 为下游阅读理解保留足够的上下文,以及 (iii) 控制索引增长和延迟。实际上,没有哪种分块方案能够保证每个问题的证据都完全自包含。
ConTEB:一个惩罚上下文盲点的基准
ConTEB 引入了八个检索任务,其中回答问题*需要*超出任何单个块的信息。一些数据集是合成和受控的(例如,足球、地理);另一些则来源于现实世界的 RAG 工作负载,例如 NarrativeQA 或 Covid-QA。“健全性测试”(NanoBEIR)确保改进不会以牺牲传统的自包含任务为代价。

深入理解:我们如何为嵌入添加上下文?
ConTEB 的早期结果表明,在上下文是关键的设置中,标准检索方法表现不佳!我们的方法尝试通过两个关键组件整合上下文信息:最近提出的 后期分块 技术,以及我们称之为 **InSeNT** 的自定义训练方法。
后期分块:在嵌入整个文档*之后*进行池化
如前所述,密集检索器通常将长文档 $d$ 分解为更小的、固定长度的**块**
独立编码每个块,然后将块向量集视为文档的“表示”
这种*早期分块*策略会阻止 $c_i$ 中的任何标记在编码期间看到来自其他块的标记。
*后期分块*思想
- 一次长正向传播。 连接所有块,让编码器在*整个*文档中进行上下文处理
- 事后恢复块级向量。 对于每个原始块 $c_i$,对其在 $H$ 中的标记嵌入求平均
结果集
保留了下游检索代码所需的相同*形状*,但每个块向量现在都受益于完整文档上下文:早期段落中的标记可以影响后期段落的表示(反之亦然),从而捕获长距离依赖关系,而无需任何训练更改。
后期分块首先计算整个文档的标记嵌入,然后将它们池化回块向量,让每个块在遇到检索引擎之前“知道”所有其他块。
InSeNT:序列内负样本训练
后期分块主要设计用于无需重新训练底层嵌入模型。我们发现,虽然它通常能够实现块之间的信息传播,但通过精心设计的轻量级训练阶段,可以极大地优化这种信息流。

在对比性微调过程中,InSeNT 将通常的*批内*负样本(来自其他文档的文本序列)与**序列内负样本**——来自同一(后期分块的)文档的其他块——混合在一起。
直观地说,用来自*不同*文档的块对比训练后期分块模型,鼓励了每个文档内的信息传播,并改善了文档识别。另一方面,同一文档块之间的对比项确保每个块保留其特异性,并相对于其邻近块保持可识别。
一个小的混合权重 (λ ≈ 0.1) 平衡了这两个互补但又有些矛盾的目标。

这项工作的一个有趣发现是,在训练过程中同时拥有序列内和批内负样本对于良好的下游性能绝对至关重要。
经验增益
结果很清楚!在构建 ConTEB 文档的相关嵌入时,上下文是金。仅使用后期分块就能带来巨大的 nDCG 增益(+9.0),而 InSeNT 则进一步大幅提高了性能,平均而言,相对于标准嵌入方法,nDCG@10 提升了 23.6。在 NanoBEIR(自包含查询)上的性能略有下降,这表明在传统基准上存在轻微的退步,可以通过在训练混合中添加重放数据来纠正。

我们进一步证明了上下文嵌入能够更好地随着语料库大小扩展,并且对次优分块策略更具鲁棒性。
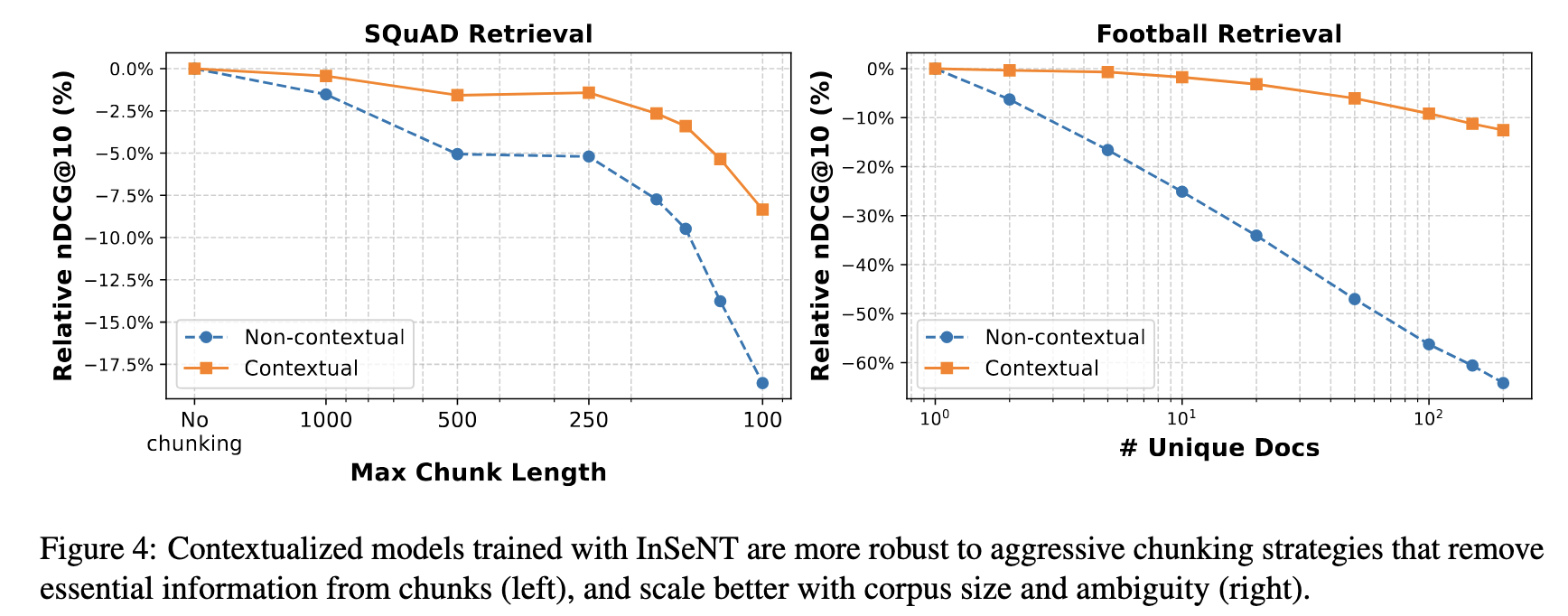 使用 InSeNT 训练的上下文模型对从块中删除基本信息的激进分块策略(左)更具鲁棒性,并且能够更好地随语料库大小和歧义性扩展(右)。
使用 InSeNT 训练的上下文模型对从块中删除基本信息的激进分块策略(左)更具鲁棒性,并且能够更好地随语料库大小和歧义性扩展(右)。
后期交互模型如何?
后期交互模型(ColBERT-style)为每个段落保留多个向量(通常每个标记一个),并使用称为 MaxSim 的多向量到多向量匹配操作来获得标量查询-文档相关性分数。熟悉我们团队工作的人都知道我们是它们的忠实粉丝!这些模型往往比它们的密集对应物表现更好,代价是增加了存储成本,并且在长上下文设置中特别出色。
有趣的是,尽管 LI 模型擅长长上下文检索,但它们不适合开箱即用的后期分块(相对于不使用 LI 的 ModernColBERT,nDCG@10 降低了 0.3)。我们认为,由于标记嵌入的训练不进行池化,这些模型学习了非常局部的特征,无法利用邻近标记的信息。一旦使用我们的方法进行训练,ModernColBERT+InSeNT 在所有方面都显示出巨大的性能提升(相对于 ModernColBERT + 后期分块,nDCG@10 提升了 11.5),这表明它利用外部上下文的能力增强了。
实际上,这意味着要使用 LI 模型进行后期分块上下文化,您确实需要对其进行训练!
顺带一提,这个项目源于使用 ColPali 模型进行后期分块而未进行再训练,但结果令人失望。这项工作获得的结果为改进视觉检索器(例如 ColPali)提供了一个有希望的方向,使其能够整合超出其嵌入单个页面的信息。
资源
- HuggingFace 项目页面: 集中所有内容的 HF 页面!
- (模型)ModernBERT: 使用 InSENT 损失和后期分块训练的上下文 ModernBERT 双编码器
- (模型)ModernColBERT: 使用 InSENT 损失和后期分块训练的上下文 ModernColBERT
- 排行榜:即将推出
- (数据)ConTEB 基准数据集:ConTEB 中包含的数据集。
- (代码)上下文文档引擎:用于训练和运行我们架构推理的代码。
- (代码)ConTEB 基准测试:一个用于评估 ConTEB 基准上的文档检索系统的 Python 包/CLI 工具。
- 预印本:包含所有细节的论文!
第一作者联系方式
- Manuel Faysse: manuel.faysse@illuin.tech
- Max Conti: max.conti@illuin.tech
引用
如果您在研究中使用本组织的任何数据集或模型,请引用原始工作,如下所示:
@misc{conti2025contextgoldgoldpassage,
title={Context is Gold to find the Gold Passage: Evaluating and Training Contextual Document Embeddings},
author={Max Conti and Manuel Faysse and Gautier Viaud and Antoine Bosselut and Céline Hudelot and Pierre Colombo},
year={2025},
eprint={2505.24782},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2505.24782},
}
致谢
这项工作部分由 ILLUIN Technology 和 ANRT France 的资助支持。这项工作是利用 GENCI Jeanzay 超级计算机的 HPC 资源,在 AD011016393 资助下完成的。






