使用 TGI 大规模进行 LLM 推理







引言
优化大型语言模型(LLM)以实现高效推理是一项复杂的任务,理解该过程同样具有挑战性。本文旨在帮助那些希望深入了解 HuggingFace 的 文本生成推理(TGI) 的人,TGI 是一种用于在生产环境中部署 LLM 的高效优化解决方案。在 Adyen,TGI 已被采纳为我们内部 GenAI 平台中 LLM 推理的首选方法。
正如之前 文章 中所讨论的,其开源性质带来的主要优势包括:成本节约、增强的数据隐私、技术控制以及定制的灵活性。这种开源精神与人工智能社区的透明度和协作进步的承诺相符。
我们将从 LLM 推理的快速回顾开始,涵盖**预填充**和**解码**的关键步骤。然后,我们将介绍 TGI,并深入探讨其两个主要组件:**服务器**和**推理引擎**。我们还将提供**相关指标**和性能考虑因素的见解。最后,我们将提供关键要点来总结讨论。本文旨在提供一个详细而简洁的指南,为任何希望通过 TGI 最大化 LLM 在生产中潜力的人提供有价值的见解和实用要点。
LLM 推理概述
LLM 推理过程可分为两个主要阶段:预填充和解码。这些阶段协同工作以生成对输入提示的响应,每个阶段在整个过程中都扮演着独特的角色。
预填充
在预填充阶段,输入**提示在 CPU 上被标记化**,然后传输到 GPU。标记化是将单词转换为更小单元(称为标记)的过程,模型可以更有效地处理这些单元。例如,给定提示“美国的首都在哪里?”模型将句子标记化,并在 GPU 上**通过加载的模型进行一次前向传递**来处理它,生成一个初始标记。这个初始传递相对较快,因为它只需要通过模型一次即可生成第一个标记,例如响应提示的“华盛顿”。
解码
解码阶段是 LLM **自回归**性质发挥作用的地方。在此阶段,模型一次生成一个标记,建立在预填充阶段的初始标记之上。每个新生成的标记都附加到输入序列中,为模型处理创建新的上下文。例如,如图 1 所示,在生成“华盛顿”作为初始标记后,新序列变为“美国的首都是哪里?华盛顿”。然后使用此更新的序列生成下一个标记。
模型以迭代方式继续此过程,每个新标记都会影响下一个标记的生成。这种自回归方法允许模型保持上下文并生成连贯的响应。解码阶段一直持续到生成序列结束 (EOS) 标记或达到由 max_new_tokens 指定的最大序列长度。此时,生成的序列在 CPU 上进行反标记化,将标记转换回可读文本。

图 1:预填充和解码流程 [1]
为何将预填充和解码分离?
预填充和解码阶段的分离至关重要,因为每个阶段的计算特性都不同。预填充阶段只需要一次前向传递,而解码阶段涉及多次传递,每次传递都依赖于先前生成的标记。解码阶段的这种自回归性质导致处理时间更长,并且计算开销与总序列长度呈二次方增长。
为了优化此过程并缓解二次方增长,采用了名为 **KV 缓存 [6]** 的技术。KV 缓存保存预填充和解码阶段在每个标记位置生成的中间状态,称为 KV 缓存。通过将这些 KV 缓存存储在 GPU 内存中,模型避免了重新计算的需要,从而减少了计算开销。这种优化对于解码阶段尤其有利,提高了其效率并有助于管理与自回归标记生成相关的更长处理时间。
TGI:深入探讨
TGI 集成了众多最先进的技术,可提供流畅的**低延迟**和**高吞吐量**推理,使其成为生产环境中对性能和可扩展性至关重要的理想选择。它提供了一个简单而多功能的启动器来服务各种 LLM,并提供通过 Open Telemetry 和 Prometheus 指标实现的分布式跟踪,用于全面的监控。TGI 支持 **Flash Attention** 和 **Paged Attention** 等高级注意力机制,确保优化和高效的推理。该框架还通过各种参数和每请求配置提供精细控制,例如用于结构化输出生成的引导式解码。
在提供基于 LLM 的应用程序时,模型服务可以分为两个主要组件:引擎和服务器(如图 2 所示)。引擎处理与模型和批处理请求相关的所有事务,而服务器则专注于转发用户请求。在 TGI 中,这些组件相应地命名:**服务器**被称为 router,**引擎**被称为 text_generation_server。

图 2:LLM 后端架构 [2]
路由器:队列和连续批处理
TGI 路由器的主要目的是管理传入请求,防止引擎遇到内存相关问题,并确保 LLM 推理的平稳高效。它采用**智能连续批处理算法,动态地将请求添加到运行中的批次中以优化性能**。这种动态批处理方法在延迟和吞吐量之间取得了平衡。
初始化时,路由器会在推理引擎上触发一个预热阶段。我们将在下一节中介绍,但基本上在此阶段,路由器会确定部署的 LLM 的底层硬件(GPU)的最大容量。
MAX_BATCH_PREFILL_TOKENS:在预填充阶段,GPU 在单次前向传递中可处理的最大标记数。MAX_BATCH_TOTAL_TOKENS:在预填充和解码步骤中可同时处理的最大标记数。
路由器的连续批处理算法旨在防止**内存不足**(OOM)错误。与静态批处理不同(请求等待前一个批处理完成),连续批处理允许将新请求动态添加到正在运行的批处理中。这意味着“*通过连续批处理,您可以找到一个最佳点。通常,延迟是用户最关心的关键参数。但在相同硬件上为 10 倍的用户带来 2 倍的延迟减慢是可接受的权衡*” [3]
路由器动态批处理的逻辑在提供的伪代码中进行了说明
# Initialize the batch and token budgets
batch = []
token_budget = max_batch_total_tokens
# Function to add requests to the prefill batch until the max_tokens budget is reached
def add_requests_to_prefill_batch(requests, batch, max_tokens):
while requests and sum(request.tokens for request in batch) < max_tokens:
batch.append(requests.pop(0))
return batch
# Add initial requests to the prefill batch
batch = add_requests_to_prefill_batch(request_queue, batch, max_batch_prefill_tokens)
# Prefill the batch
prefill(batch)
# Main loop to manage requests
while batch:
# Update the token budget based on current batch
batch_max_tokens = sum(request.input_tokens + request.max_new_tokens for request in batch)
token_budget = max_batch_total_tokens - batch_max_tokens
# Add new requests to the batch based on token budgets
new_batch = add_requests_to_batch(request_queue, [], min(max_batch_prefill_tokens, token_budget))
# If new requests were added, handle prefill and decoding
if new_batch:
# Stop decoding and prefill the new batch
prefill(new_batch)
# Extend the original batch with the new requests
batch.extend(new_batch)
# Decode the current batch
decode(batch)
# Filter out completed requests that have reached EOS or max_new_tokens
batch = [request for request in batch if not request.reached_EOS and request.tokens_generated < request.max_new_tokens]
# Update token budget by subtracting tokens from completed requests
completed_requests = [request for request in batch if request.reached_EOS or request.tokens_generated >= request.max_new_tokens]
for request in completed_requests:
token_budget = token_budget - request.input_tokens + request.tokens_generated
为了更好地说明 TGI 的连续批处理算法是如何工作的,我们通过表 1 中的以下初始设置来具体示例。最初,没有请求正在处理,因此总令牌预算等于 MBT。
| 变量名 | 值 | 缩写 |
|---|---|---|
MAX_BATCH_TOTAL_TOKENS |
20.5k | MBT |
MAX_BATCH_PREFILL_TOKENS |
10k | MBP |
TOTAL_TOKEN_BUDGET |
20.5k | TTB |
队列 |
20 个请求 |
表 1:连续批处理示例的环境设置。
在图 3 中,前 10 个请求顺利地通过了预填充和解码步骤,并且 TTB 也相应地进行了更新。在此之后,队列中有 10 个请求,另外 10 个请求正在解码,每个请求都从 TTB 中占用了一些预算,直到它们达到 max_new_tokens 或生成 EOS 标记。
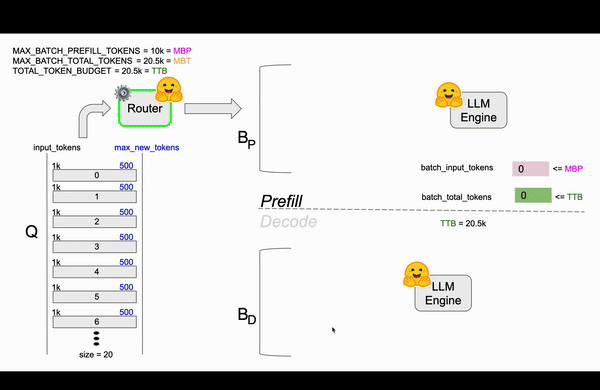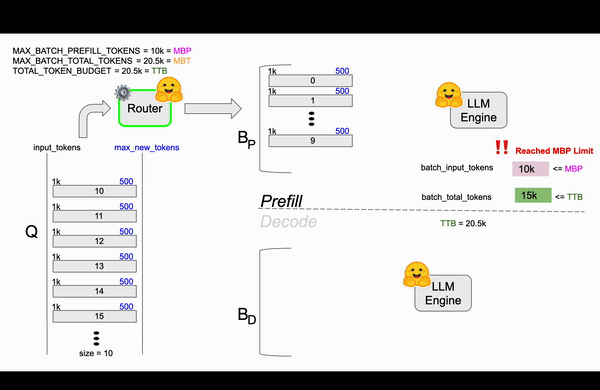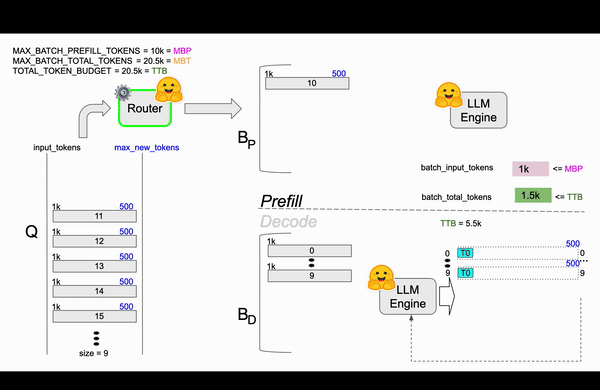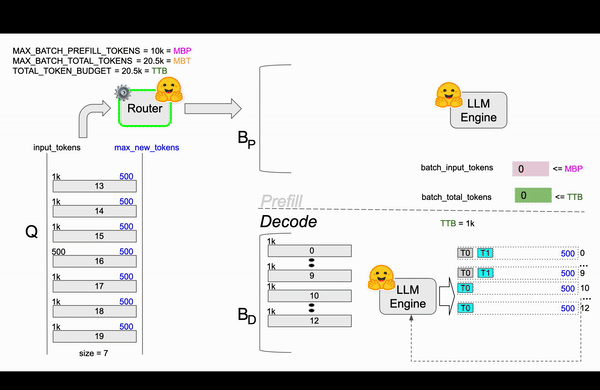
图 3:基于 TGI 路由器代码 的 TGI 连续批处理动画。
我们遇到了一种情况,即第 13、14 和 15 个请求将超出可用令牌预算,阻止它们进行预填充步骤。如图 4 所示,第 16 个请求的令牌计数较小,符合 TTB,并成功预填充了缓存,加入了正在运行的解码批次。此时,令牌预算已完全用尽,我们必须等待当前正在运行的请求完成。

图 4:基于 TGI 路由器代码 的 TGI 连续批处理动画。
最终,在图 5 中,第 0、9 和 16 个请求处理完成,释放了令牌预算空间。这允许第 14 和 15 个请求继续进行预填充和解码,剩余 1000 个令牌的 TTB。随着流程的继续,更多请求完成,为队列中剩余的请求(第 17、18 和 19 个)腾出预算以进行处理。

图 5:基于 TGI 路由器代码 的 TGI 连续批处理动画。
从图 3 可以看到一个重要的观察结果。前 10 个请求(第 0 个到第 9 个)一起通过了预填充步骤,但它们并未使 20.5k 令牌的可用 TTB 饱和。这就提出了一个问题:为什么没有更多请求被添加到批次中?答案在于单次前向传递的令牌预算,即 MBP。这 10 个请求使 MBP 饱和,而 MBP 是预填充阶段特有的。在后续步骤中,路由器会添加请求以填充解码步骤的内存,但这些请求无法在早期包含,因为它们会超出 MBP 预算。这种情况突出了 MBP 和 MBT 之间的区别:虽然 MBP 专注于预填充阶段,但 MBT 表示总令牌预算,解码受益于内存优化。
MBP 和 MBT 之间的区别可以通过考虑预填充和解码阶段的性质来进一步解释。在预填充步骤中,LLM 引擎处理 i# 请求输入标记i 。例如,对于 4 个请求,每个请求包含 500 个 input_tokens 和 500 个 max_new_tokens,4 个请求的批处理会在预填充阶段处理 2000 个标记,并解码另外 2000 个标记。这看起来令人困惑,因为两个阶段处理相同的标记负载。然而,由于 KV 缓存机制,对内存的影响不同。
在预填充期间,引擎对所有 2000 个标记执行完整的前向传递,以获取每个输入标记的注意力查询、键和值,从而为每个序列输出第一个解码标记。相比之下,在解码期间,第 N 个标记受益于 KV 缓存,其中所有先前标记的注意力键、查询和值都已缓存。因此,解码就像只对一个标记(第 N 个标记)执行前向传递。由于解码是自回归的,它逐个标记进行,使得 4 个序列的 2000 个标记的生成类似于同时处理 4 个标记。相比之下,预填充需要将所有 2000 个标记通过模型进行第一次新标记生成。
TGI 提供了可配置的参数,可以根据特定用例微调预填充和解码阶段的行为。这些参数设置为环境变量(WAITING_SERVED_RATIO、MAX_WAITING_TOKENS 和 MAX_BATCH_SIZE),允许自定义两个阶段之间的权衡。
TGI 开发人员在服务器层面使用 Rust 实现连续批处理是一个战略选择。在这种情况下,Rust 的速度是您最好的盟友,因为 Python 每次决策都会增加几毫秒。更准确地说,严格的类型化和真正的并发性使 Rust 在 Python 上获得了巨大的优势。考虑到规模,这个决策可能会在一个请求批次中发生 100 次,这将为端到端延迟增加数百毫秒。
推理引擎:预热和推理优化
推理引擎负责处理来自路由器的请求。本质上,它将模型加载到 GPU 的内存中,然后运行预填充和解码阶段。我们将介绍我们认为 TGI 推理引擎最重要的功能:*预热、KV 缓存、Flash attention 和 Paged attention*。
预热
此阶段在开始处理任何请求之前运行。首先,它根据可用硬件和部署的模型估算适当的令牌预算,以确保在推理过程中不会发生 OOM 错误。此外,如果启用,它会记录CUDA 图形以用于一系列批处理大小的 LLM 前向传播:从高层次看,这是一种有效记录固定大小输入(即批处理大小)的 GPU 操作的方法,可在重播时减少 CPU-GPU 通信开销 [4]。为了估算预填充令牌预算,引擎会将 input_tokens = max_input_tokens 和 max_new_tokens = max_total_tokens - max_input_tokens 的请求添加到批处理中,直到它使 MAX_BATCH_PREFILL_TOKENS 饱和。然后,此批处理通过预填充转发,如果发生 OOM 错误,TGI 将强制您减小 MAX_BATCH_PREFILL_TOKENS。成功完成后,TGI 将继续估算总令牌预算。
对于总令牌预算估算,引擎将可用内存映射到可处理令牌的总数。首先,引擎计算可用 VRAM 的 95%,留下 5% 的错误空间,其中 可用 VRAM = GPU VRAM - 模型 VRAM - 预填充 KV 缓存 VRAM。然后,可用内存除以处理令牌块所需的内存 [5],得到可以同时处理的令牌总数。此值设置为 MAX_BATCH_PREFILL_TOKENS,本质上是块中令牌数乘以适合内存的块数。
推理优化
此外,对于 TGI 来说,这个引擎已经配备了用于优化 LLM 推理的常见最先进算法,例如:PagedAttention [5] 和 Flash Attention [7]。
**PagedAttention** 通过优化推理期间内存的管理方式来解决 LLM 内存受限的特性。在 GPU 中,每次内存移动都会影响延迟和吞吐量,为每个请求重新创建 KV 缓存张量效率低下。PagedAttention 将 KV 缓存分成 *N* 页,允许每个请求使用 *n* 个在完成后释放的页。这种分页系统消除了重新分配张量的需要,而是将页重新用于新请求,从而减少了不必要的内存移动。尽管这可能会损害内核中的缓存局部性,但内存重新分配的减少使这种权衡变得值得 [5]。
**FlashAttention** 是一种有价值但并非关键的 LLM 推理优化。其主要影响在于启用无填充张量的使用。以前,注意力计算需要形状为 [batch_size, seq_len, ...] 的张量,这需要填充较短的序列以匹配最长的序列,导致由于这些额外的填充标记而增加内存移动和 VRAM 使用。FlashAttention 消除了这种需要,显著减少了 VRAM 消耗。虽然 FlashAttention 论文中强调的 SRAM 优势在训练期间(计算受限)最有利,但减少的 VRAM 使用和增强的效率在推理期间仍然提供显着的性能提升,尤其是在长序列的情况下 [7]。
TGI:相关指标
延迟和吞吐量驱动因素
请记住!LLM 推理涉及两个关键阶段:**预填充**和**解码**。预填充速度影响**首个标记时间**(TTFT),因为在处理完输入上下文之前无法开始标记生成。然后,解码速度影响**每输出标记时间**(TPOT),它衡量预填充后标记的生成速率。TTFT 和 TPOT 对于用户体验都至关重要,并在定义 LLM 推理性能方面发挥着重要作用。此外,推理性能也受到内存(也称为 GPU 的 VRAM)驱动的吞吐量影响。可用 VRAM 主要由模型大小和 KV 缓存决定。**VRAM 使用**直接影响最大批处理大小和序列长度。
总之,LLM 推理的特点是**VRAM 使用**、**TTFT** 和 **TPOT**。为了估算这些指标,必须考虑要处理的数据量和计算所需的 FLOPs(浮点运算)。
GPU:高级概述
为了理解下一节,您至少需要对 GPU 的作用有一个大致了解。简单来说,它加载数据(从称为 **HBM** / VRAM 的 GPU 内存到计算单元的 SRAM)并计算 **FLOPs**(如矩阵乘法等数学运算)。这些操作受限于 HBM 每秒可以“移动”的内存量以及 SM 每秒可以执行的 FLOPs 数量 [11]。一个非常重要的概念需要记住是计算密集型与内存密集型。如果内存无法以保持处理器忙碌的速度提供工作,则该作业被称为内存密集型。相反,如果其瓶颈在于处理器的速度,则该作业被称为计算密集型。
指标计算
现在我们将看到预填充和解码之间的巨大差异,以及它们的分离如何影响性能。预填充将模型从内存中加载一次以并行处理所有输入令牌,这导致一个**计算密集型**过程,每个读取字节的操作次数很高。相比之下,解码是一个**内存密集型**过程,因为它会加载模型 max_new_tokens 次,每次生成一个令牌(每个读取字节的操作次数很少)[9]。
假设我们使用 **16 位**精度在 **A100 GPU** 上服务 **Llama-7b**。我们将计算 VRAM 要求和不同的时间:预填充、解码、TTFT、TPOT 和总时间。为此,我们需要在表 2 中定义几个常量。
| 变量 | 值 |
|---|---|
S:输入序列令牌 |
512 |
O:输出令牌 |
1024 |
B:批处理大小 |
4 |
H:隐藏维度 |
4096 |
L:变换器层数 |
32 |
N:模型参数 |
7e9 |
| GPU FLOPs 速率 | 312 TFLOPs/s |
| GPU 高带宽内存速率 | 1.5 TB/s |
表 2:令牌负载、模型和硬件特性。
为了推导出 TTFT、TPOT 和总时间,我们首先需要计算预填充和解码时间。预填充和解码阶段都有计算时间和内存时间。在计算方面,令牌的嵌入需要与模型的权重矩阵或参数相乘;这占 N 次计算。因此,对于预填充步骤,我们处理批处理中所有序列的整个输入,我们有 B*S 个令牌,因此我们执行 N*B*S 次计算 [10]。另一方面,对于解码步骤,我们只处理批处理中每个序列的一个令牌,即 B*1 个令牌,因此我们执行 N*B*1 次计算。但是,我们不能忘记,我们使用 16 位精度,这意味着每次计算我们使用 2 字节。相比之下,对于内存时间,我们需要将 N 个模型参数加载到内存中,每个参数存储在 2 字节(16 位精度)中。操作摘要如表 3 所示。
| 阶段 | 计算时间 | 内存时间 | 类型 |
|---|---|---|---|
| 预填充(Prefill) | (2 * N * B * S) / FLOPs 速率 = 91.9 毫秒 | (2 * N) / HBM 速率 = 9.3 毫秒 | 计算受限 |
| 解码(Decode) | (2 * N * B * 1) / FLOPs 速率 = 0.17 毫秒 | (2 * N) / HBM 速率 = 9.3 毫秒 | 内存受限 |
表 3:预填充和解码阶段的计算和内存类型背后的数学
现在我们有了这些,我们可以计算 TTFT、TPOT 和总时间。在表 4 中,我们取计算时间和内存时间中的最大值,因为它们彼此重叠,并且最长的一个是主导时间,使过程受计算或内存限制。
| 指标 | 值 |
|---|---|
| TTFT:首个标记时间 | max((2 * N * B * S) / FLOPs 速率, (2 * N HBM 速率)) = 91.9 毫秒 |
| TPOT:每输出标记时间 | max((2 * N * B * 1) / FLOPs 速率, (2 * N HBM 速率)) = 9.3 毫秒 |
| 总时间 | TTFT + TPOT * O = 9.5 秒 |
表 4:TTFT、TPOT 和总时间背后的数学原理
我们目前已经计算了影响延迟的因素,接下来看看影响吞吐量的因素。为此,我们将计算可用于推理的 VRAM,可用越多,并行处理的令牌就越多。请记住,我们使用的是 2 字节精度,A100 具有 80GB VRAM。如表 5 所示,在处理任何请求之前,KV 缓存是空的,因此 VRAM 仅包含 model_size = 2*N GB。一旦 TGI 为一批请求进行预填充,VRAM 使用量就会在 model_size 的基础上增加 kv_cache_size。图 6 中显示的 KV 缓存大小解释如下:对于每个令牌,有两个向量,一个用于键,一个用于值,这些向量都存在于每个注意力头 L 中,维度为 H。最初,在预填充之后,有 B*S 个令牌。

图 6:KV 缓存大小(预填充令牌)与变换器组件的数学关系。
灵感来自 [10]
最终,当 TGI 完成解码时,`kv_cache_size` 将会按比例增长到 `S+O`。
| 推理阶段 | 已用 VRAM | 空闲 VRAM |
|---|---|---|
| 预填充之前 | model_size = 14 GB | 80 - 14 = 66GB |
| 预填充之后 | model_size + kv_cache_size = 14.12 GB | 80 - 14.12 = 65.88GB |
| 解码之后 | model_size + kv_cache_size = 14.6 GB | 80 - 14.6 = 65.4GB |
表 5:VRAM 使用量背后的数学原理。
如表 5 所示,在我们的示例中,由于 A100 GPU 具有 80GB 的 VRAM,我们可以轻松处理这样的令牌负载。但是,如果我们将令牌负载增加到 S=3000、O=2000 和 B=32,这将导致 已用 VRAM = 14GB+67GB = 83.8GB > 80GB。因此,我们无法在单个 A100 GPU 上处理此令牌负载。我们必须使用更小的模型、具有更多 VRAM 的 GPU,或者利用张量并行跨更多硬件,或者我们可以量化模型权重。
各用例的相关指标
根据下游应用程序的用例,您将关心不同的性能指标。例如,如果您正在提供 RAG 应用程序,那么您可能会非常关心延迟,而不太关心吞吐量,特别是您会关心 TTFT 和 TPOT 要快于最终用户的阅读速度。或者,如果您有一个应用程序可以总结发送到客户支持区域的每张传入工单,那么您会关心完成摘要所需的总时间。在这种情况下,您的用例对 TTFT 的依赖较少,而更多地依赖于 TPOT 乘以摘要所需的令牌数量。另一方面,如果您正在通宵处理金融文档以进行分类,那么您主要关心的是一次可以容纳多少文档,也就是说,您将完全忽略延迟,只关心吞吐量。
在这些应用程序中估算延迟和吞吐量时,至关重要的是要以令牌而非请求来思考。建议像图 7 中那样绘制系统中令牌的流向,保持简单,模型中输入了多少令牌?输出了多少?简单的聊天与 RAG 应用程序不同。

图 7:聊天与文件 RAG 应用程序的令牌预算比较。
例如,在图 7 中,我们比较了文件 RAG 应用程序与普通聊天应用程序需要处理的令牌数量。文件 RAG 应用程序还需要一个聊天界面,允许用户对上传的文件进行查询,因此我们用紫色区分了 RAG 应用程序明确需要的内容,用橙色区分了聊天应用程序需要的内容。我们可以看到,如果考虑初始文件上传,总输入令牌为 109k,如果不考虑,则只有 9k 令牌。但是,如果我们只计算橙色令牌,我们会发现聊天应用程序只需要 5k 输入令牌和 1k 输出令牌,这几乎是文件 RAG 应用程序所需的一半。
要点
解码步骤的自回归性质是延迟和吞吐量的关键瓶颈。为了缓解这些问题,TGI 采用了多种技术来降低延迟并提高解码时的吞吐量:Paged Attention [5]、KV Caching [6] 和 Flash Attention [9] 等。
TGI 的 `router` 利用了生成可能会因为 `EOS` 标记而意外结束,并且解码令牌预算大于预填充令牌预算的优势。因此,它不是静态批处理,而是不断地将请求批量发送到 `inference engine`,交织预填充-解码步骤并过滤掉已完成的请求。
选择的 LLM 和 GPU 是性能(吞吐量和延迟)最重要的驱动因素。更准确地说,性能是 LLM 参数大小、GPU 的高带宽内存和 GPU 的 FLOPs 的函数。
使用 TGI 时,以令牌而非请求来思考至关重要。这意味着要了解您用例中的令牌流,并找到需要优化的相关每令牌指标。
TGI 的基准测试工具非常适合熟悉影响您用例的主要瓶颈。但是,它跳过了
router(未利用连续批处理),为了整体测试 TGI(router和inference engine),最好使用像 k6 这样的负载测试工具。
参考
[1] Thomas, D. (2024 年 5 月 29 日)。基准测试文本生成推理。Hugging Face。检索于 2024 年 6 月 29 日,网址:https://huggingface.co/blog/tgi-benchmarking
[2] 服务 LLM 意味着什么以及选择哪种服务技术。(2024 年 1 月 9 日)。Run:ai。检索于 2024 年 6 月 29 日,网址:https://www.run.ai/blog/serving-large-language-models
[3] Patry, N. (2023 年 5 月 1 日)。TGI 路由器文档。Github。https://github.com/huggingface/text-generation-inference/blob/main/router/README.md
[4] Reed, J. K.、Dzhulgakov, D. 和 Morales, S. (2023 年 8 月 29 日)。速度、Python:二选一。CUDA 图如何为深度学习启用快速 Python 代码。Fireworks.ai。检索于 2024 年 6 月 29 日,网址:https://blog.fireworks.ai/speed-python-pick-two-how-cuda-graphs-enable-fast-python-code-for-deep-learning-353bf6241248
[5] Kwon, W.、Li, Z.、Zhuang, S.、Sheng, Y.、Zheng, L.、Yu, C. H.、Gonzalez, J. E.、Zhang, H. 和 Stoica, I. (2023 年 9 月 12 日)。使用分页注意力高效管理大型语言模型服务的内存。arXiv.org。https://arxiv.org/abs/2309.06180
[6] Lienhart, P. (2023 年 12 月 22 日)。LLM 推理系列:3. KV 缓存解释 | 作者:Pierre Lienhart。Medium。检索于 2024 年 6 月 29 日,网址:https://medium.com/@plienhar/llm-inference-series-3-kv-caching-unveiled-048152e461c8
[7] Dao, T.、Fu, D. Y.、Ermon, S.、Rudra, A. 和 Ré, C. (2022 年 6 月 23 日)。FlashAttention:具有 IO 意识的快速高效内存精确注意力。arXiv.org。https://arxiv.org/abs/2205.14135
[8] Hugging Face. (n.d.). Flash Attention. Hugging Face. 检索于 2024 年 6 月 30 日,网址:https://huggingface.co/docs/text-generation-inference/en/conceptual/flash_attention
[9] Chen, J. (2023 年 12 月 19 日)。快速估算 LLM 推理速度和 VRAM 使用量:以 llama-7b 案例研究为例。https://www.jinghong-chen.net/estimate-vram-usage-in-llm-inference/
[10] Chen, Carol. (2022) "Transformer 推理算术", https://kipp.ly/blog/transformer-inference-arithmetic/
参考书目
KV 缓存解释
LLM 推理系列:3. KV 缓存揭秘 | 作者:Pierre Lienhart | Medium
高级变换器推理演练
延迟和吞吐量估算
快速估算 LLM 推理速度和 VRAM 使用量:以 Llama-7B 案例研究为例
高级变换器训练演练
根据令牌负载估算硬件需求的工具
https://github.com/adarshxs/TokenTally/tree/main
https://huggingface.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator/blob/main/index.html
PagedAttention 拆解
LLM 推理框架的基准测试研究






