PISCO-OSCAR:用于高效检索增强生成(RAG)的嵌入模型

Maxime Louis, Thibault Formal, Hervé Dejean, Stéphane Clinchant
Naver Labs Europe

检索增强生成(Retrieval-Augmented Generation,RAG)减少了幻觉,并提高了 LLM 输出的相关性和事实性。然而,使用检索到的文档进行生成会产生额外成本,因为 LLM 推理通常与输入大小呈二次方关系。
PISCO 和 OSCAR 模型的主要思想是用嵌入表示取代纯文本文档。这些嵌入应该:
- 尽可能多地承载原始文档的语义信息
- 在生成时能被 LLM 轻松高效地利用
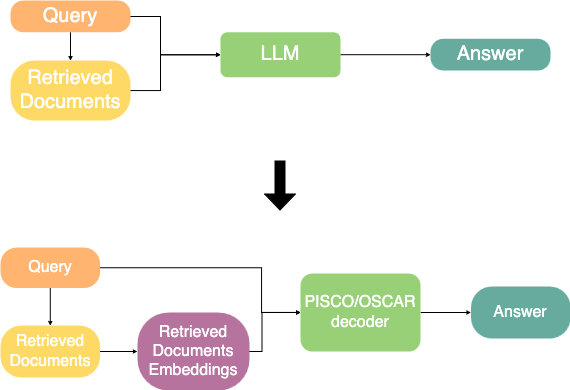
嵌入是通过编码器 LLM 计算的,该编码器 LLM 将文本映射为向量表示,作为 LLM 的隐藏状态。实际上,OSCAR 和 PISCO 可以将 N 个 token 的文本映射为 N/16 个嵌入,大大缩短了用于生成的最终提示,从而提高了效率。

PISCO:用于 RAG 的离线嵌入模型
PISCO 建议离线预处理整个文档集合:每个文档嵌入计算一次后离线存储在向量数据库中。请注意,存储文档/向量数据库很常见,因为检索通常需要它们。
答案本身是使用单独的解码器模型从问题和文档嵌入生成的。实际上,我们希望该解码器模型与之前使用的 LLM 完全相同,但我们尝试使用冻结其预训练权重的解码器 LLM 均未成功。尽管如此,专门为 RAG 微调 LLM 已经变得相当经典,以在更通用的管道中获得更高的基础性和准确性。
PISCO 模型通过蒸馏目标进行端到端训练。给定一组问题和相关检索到的文档,训练目标是使用文本增强生成作为标签的嵌入增强生成的交叉熵损失。此目标促使模型无论是在原始文本还是其嵌入上工作,都能输出相同的结果。损失信号通过生成器 LLM 和编码器 LLM 反向传播。

PISCO 训练管道。PISCO 使用同一骨干 LLM 的两个独立实例作为编码器和解码器。这使得编码器和解码器隐藏空间之间的映射更容易学习(特别是它可以在没有预训练任务的情况下实现,与以前的工作不同)。
评估显示 PISCO 显著优于现有工作。事实上,PISCO 的准确性接近其无压缩骨干(此处为 Mistral-7B)的准确性。

PISCO 优于现有 RAG 压缩方法。使用另外两个评估指标也可以得出类似的结论:
- 如 [Rau] 中所述,LLM 对标签和预测之间一致性的评估
- 使用 gpt-4o 对 PISCO 和其他模型进行成对比较
在效率方面,压缩实现了 5 倍的加速,这是通过典型 RAG 基准测试中的时间/浮点运算次数来衡量的。
| 模型 | GFlops | 时间 (秒) | 最大批量大小 |
|---|---|---|---|
| Mistral-7B | 11231 | 0.26 | 256 |
| PISCO-Mistral | 2803 | 0.06 | 1024 |
使用离线计算文档嵌入的计算增益。实验还表明,PISCO 模型可以泛化到其他领域(这意味着利用嵌入的能力至少部分与领域无关)、大量文档和支持其他语言。
我们分析了用于生成蒸馏标签的教师模型的影响,以及蒸馏本身(即使用常规标签)的消融研究。

蒸馏教师模型的影响:更好的教师模型并非最大的模型。这些结果表明,最好的教师模型并非总是最好的模型。(手动检查表明 Solar 和 Mistral 生成的标签更详细,但调整训练以适应 token 数量后,大部分改进仍然保留。)
我们开源了基于 Llama-3.1.8B-Instruct、Solar-10.7B 和 Mistral-7B 的 PISCO 模型。
- 论文:https://arxiv.org/2501.16075
- 模型:https://huggingface.co/collections/naver/pisco-67683f2b553e5dc6b8c3f156
OSCAR:用于 RAG 的在线嵌入模型
PISCO 需要预先计算嵌入以提高推理效率。OSCAR 模型是 PISCO 模型的改进,专门设计用于在线方式工作,即无需预先计算和存储文档嵌入。
首先,OSCAR 模型使用更快更小的编码器模型,以使压缩物有所值。OSCAR-N 层模型仅使用骨干 LLM 的前 N 层进行压缩。这种方法的优点是构建的嵌入与其通常用于生成的完整骨干原生兼容。此外,OSCAR-llama 模型使用 Llama-3.2–1B 作为编码器模型。这种方法需要对齐嵌入空间(特别是它们的维度!),我们通过使用一个 2 层 MLP 网络实现,该网络通过简单的对齐任务进行预训练。
其次,由于压缩是在线执行的,因此可以在压缩时使用查询,以生成文档的查询相关嵌入。实际上,这允许在较高压缩率下实现更强的性能,将压缩重点放在文档的相关方面。

第三,对查询+文档进行操作的压缩操作可以扩展到同时预测 [Rau] 中强大 RAG 管道中使用的重新排序分数。重新排序是检索过程的改进,通常使用交叉编码器模型确定每个(文档,查询)对的文档与查询的相关性得分。最初检索到的一小部分文档根据重新排序得分进行过滤。在 OSCAR 设置中,重新排序得分是免费获得的,只需在编码器模型中添加一个专用的重新排序得分头即可。它通过教师重新排序器的标准蒸馏损失进行训练。这类似于 Provence [Chirkova]。
训练也通过教师标签的端到端蒸馏完成。训练完成后,我们可以将 OSCAR 模型和竞争方法放在(效率,准确性)空间中。

推理时的平均浮点运算次数与 LLM 评估的准确性,这表明 OSCAR 比未压缩的骨干和竞争作品更有效且更快。对 PISCO 模型进行的额外评估也证实了这些发现,并说明了 OSCAR 对检索设置和领域变化的鲁棒性。
我们开源了使用 Llama-3.2-1B 作为编码器,以 Mistral-7B、Mistral-Small-24B 和 Qwen2-7B 作为骨干的 OSCAR 模型。
- 论文:https://arxiv.org/abs/2504.07109
- 模型:https://huggingface.co/collections/naver/oscar-67d446a8e3a2551f57464295
参考文献
[Rau] Rau, David, et al. "Bergen: A benchmarking library for retrieval-augmented generation." arXiv:2407.01102 (2024).
[Chirkova] Chirkova, Nadezhda, et al. "Provence: efficient and robust context pruning for retrieval-augmented generation." arXiv:2501.16214 (2025).