LLaVA-o1:让视觉语言模型逐步推理
社区文章 发布于 2024 年 11 月 19 日







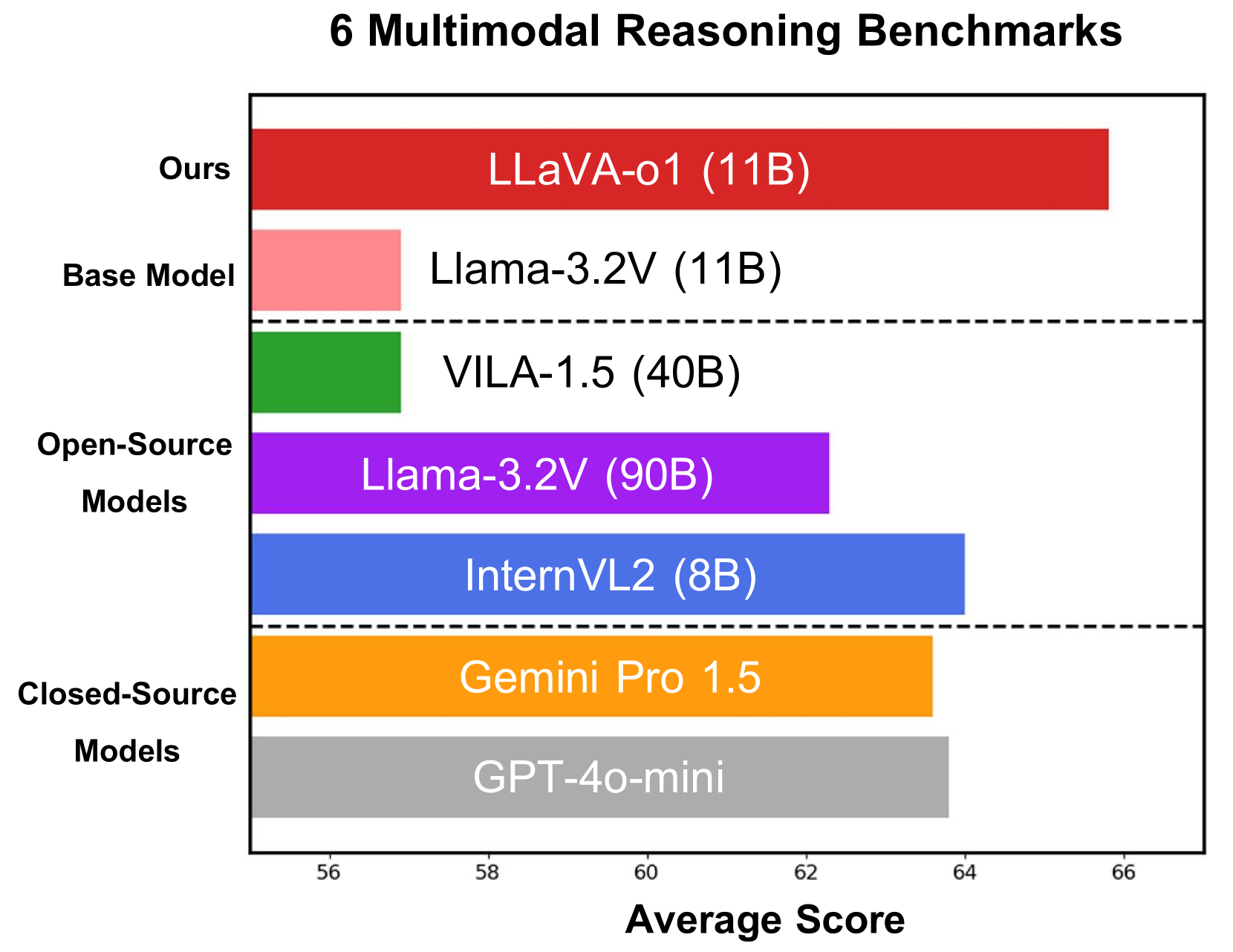
概述
- 一种名为 LLaVA-o1 的新方法提高了 AI 模型中的视觉推理能力
- 实现逐步推理以分析图像
- 在视觉推理基准测试中取得了最先进的性能
- 使用思维链提示来分解复杂的视觉任务
- 与现有视觉语言模型集成
通俗解释
LLaVA-o1 就像一个仔细勘察犯罪现场的侦探。它不会急于得出结论,而是将图像中所见的内容分解成更小、更易于管理的小步骤。这种方法反映了人类解决复杂视觉问题的自然方式。
正如我们可能会一个接一个地数物体,或者系统地比较图像的不同部分一样,LLaVA-o1 也遵循结构化的思维过程。与那些试图一次性回答图像问题的模型相比,这使得它的推理更加透明和准确。
该系统在处理复杂的视觉任务(如计数物体、比较特征和理解空间关系)方面表现出特别的优势。可以将其视为一次性解决难题与逐步指导解决难题之间的区别。
主要发现
视觉推理能力通过逐步处理得到显著提升。该模型实现了
- 复杂视觉推理任务的准确性提高了 15%
- 在计数和比较任务中表现更好
- 更一致和可解释的结果
- 处理多步视觉问题的能力增强
技术解释
思维链方法通过添加结构化推理步骤,在现有视觉语言模型的基础上进行构建。该系统通过多个阶段处理视觉信息:
- 初始视觉特征提取
- 顺序推理步骤
- 最终答案综合
模型架构将视觉编码器与语言处理组件集成,实现视觉和文本理解之间的无缝通信。这使得对视觉内容进行更复杂的推理成为可能。
批判性分析
虽然 LLaVA-o1 显示出喜人的成果,但仍存在一些局限性。逐步推理可能计算密集,可能会限制实际应用。该模型也可能难以处理高度抽象或模糊的视觉场景。
这项研究可以从以下方面受益:
- 在不同视觉领域进行更广泛的测试
- 评估计算效率
- 调查失败案例
- 评估视觉推理中的偏见
结论
智能视觉语言推理器如 LLaVA-o1 代表了人工智能视觉理解方面的重要一步。逐步方法为视觉推理任务提供了更透明、更可靠的方法。这项进展可能会影响从自动驾驶汽车到医学图像分析的应用,尽管实际实施的挑战仍有待解决。





