预训练中的程序性知识驱动大型语言模型的推理能力


概述
• 研究探讨大型语言模型 (LLM) 如何利用预训练数据中的程序性知识
• 研究表明预训练知识比之前认为的更能驱动推理能力
• 开发了一种新颖的影响追踪方法,用于分析文档对模型输出的影响
• 研究结果显示,模型严重依赖初始训练期间学习到的程序模式
通俗易懂的解释
大型语言模型在初始训练过程中学习基础推理技能,这类似于人类在生命早期学习基本问题解决模式的方式。这些模型不是记忆具体的答案,而是学习解决问题的通用方法。
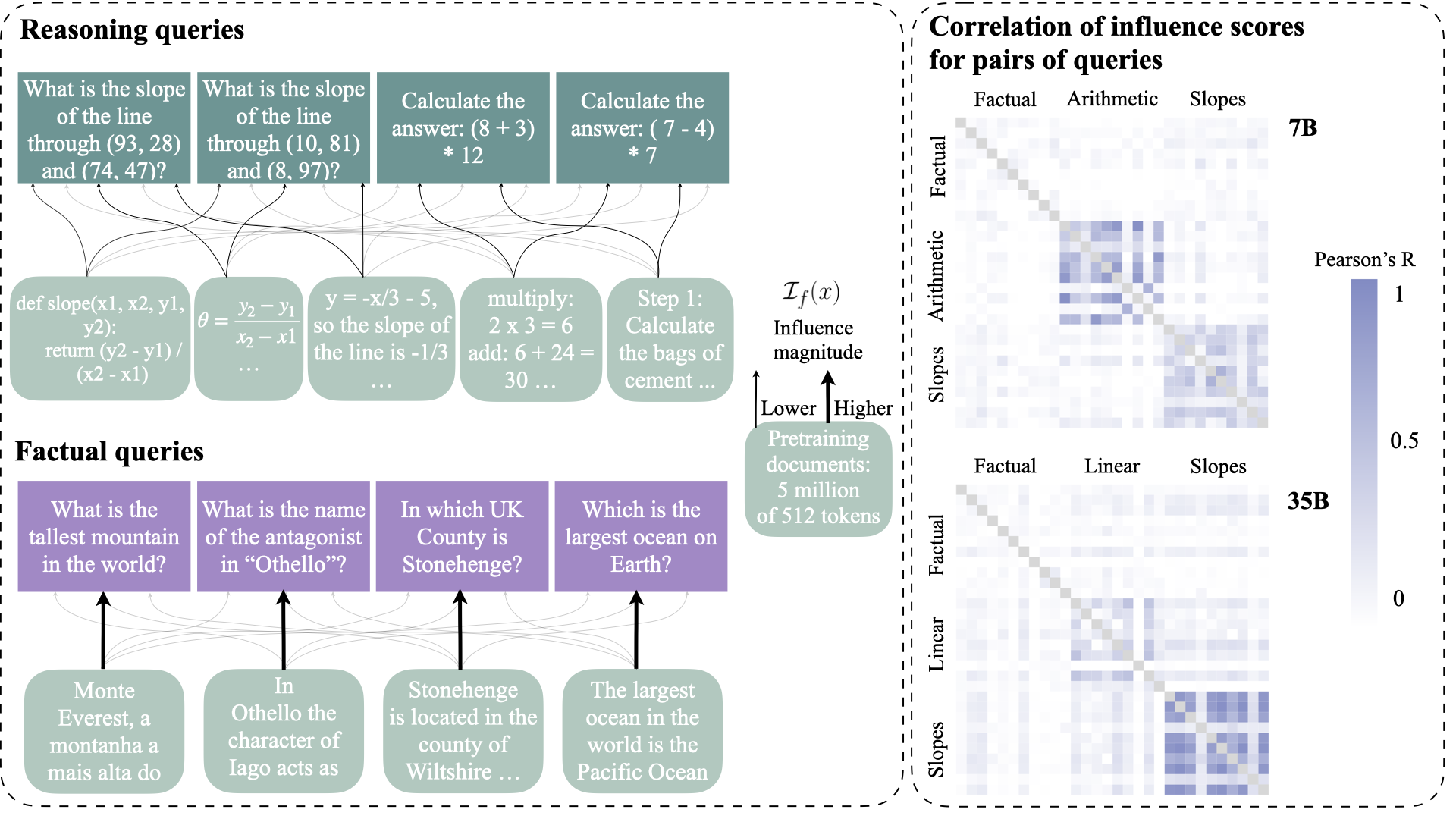
研究人员开发了一种方法来追踪不同训练文档如何影响模型的推理能力。这就像在沙滩上追踪足迹一样,这种方法揭示了哪些训练经验塑造了模型的问题解决策略。
可靠的推理来自于接触大量逻辑思维模式的例子。就像孩子通过看许多例子来学习解决谜题一样,语言模型通过处理数百万包含程序性知识的文档来发展推理能力。
主要发现
这项研究发现,预训练期间获得的程序性知识在模型推理中起着至关重要的作用。模型不仅仅是记忆答案,它们还学习通用的问题解决方法。
学习动态表明,接触程序性文本有助于模型发展系统的推理能力。该研究发现预训练数据与下游推理性能之间存在很强的联系。
模型在与训练期间遇到的程序模式一致的任务上表现出更好的推理能力。这表明精心策划训练数据可以增强推理能力。
技术解释
研究人员开发了一种影响追踪方法来分析预训练文档如何影响模型输出。这涉及根据训练样本对特定推理任务的影响来计算其重要性分数。
程序性知识的转移通过接触训练数据中的分步解释、逻辑论证和问题解决演示来实现。该研究追踪了这些知识如何影响下游任务的性能。
该方法揭示,模型在解决新的推理挑战时严重依赖预训练期间学习到的程序模式。这表明推理能力来自接触结构化思维模式,而不是特定任务的微调。
批判性分析
当前研究存在一些局限性。影响追踪方法可能无法捕捉所有相关的训练影响,并且分析主要集中在英语内容上。
该研究未能充分解决不同类型的程序性知识如何交互作用,或者如何优化训练数据选择以增强推理能力。需要更多的工作来理解知识转移的精确机制。
除了准确性之外,模型在不同领域和任务类型中推理的可靠性和一致性仍然存在疑问。
结论
这项研究表明,预训练期间获得的程序性知识从根本上塑造了语言模型的推理方式。研究结果表明,精心策划训练数据可以带来更强大和可靠的人工智能系统。
该研究为通过更好地理解知识转移机制来提高模型推理能力开辟了新途径。未来的工作应侧重于优化训练数据选择和开发更强大的推理能力评估方法。