基于保守数据过滤的稳健ASR错误纠正


概述
- 本文介绍了一种使用保守数据过滤的自动语音识别(ASR)错误纠正的新方法。
- 该方法侧重于训练数据质量,通过过滤掉可能导致错误纠正的示例。
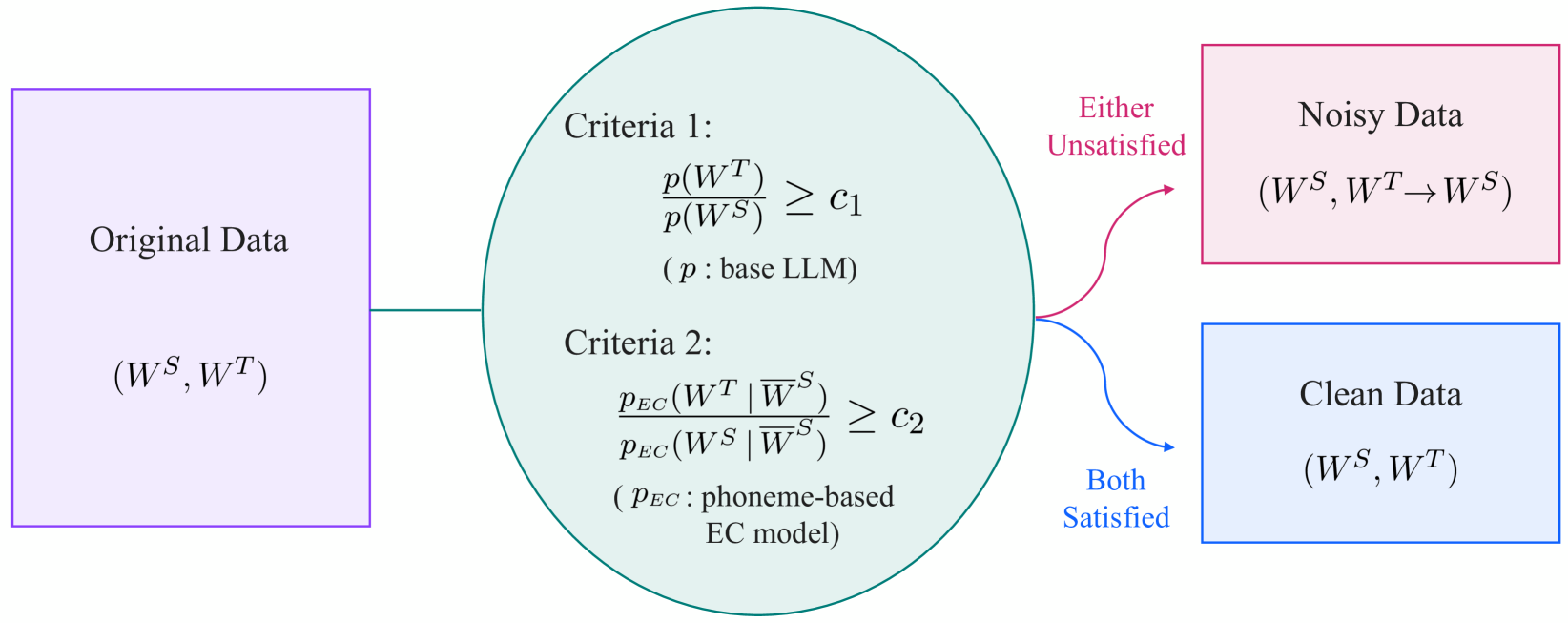
- 提出了两个过滤标准:确保纠正能提高语言可接受性,以及保持原始文本和纠正文本之间的语义相似性。
- 实验证明,在ASR错误纠正任务中,尤其是在对噪声数据的鲁棒性方面,性能有所提高。
通俗易懂的解释
本文通过仔细选择训练数据来改进ASR错误纠正,从而实现更准确、更可靠的纠正。
ASR系统虽然日益复杂,但仍然会出错。纠正这些错误对于从转录服务到语音助手的许多应用都至关重要。然而,当前的纠正方法有时会引入新的错误或使现有错误恶化,尤其是在ASR输出非常嘈杂的情况下。这通常是由于用于训练纠正模型的数据存在问题。想象一下,试图从一本充满错误的教科书中学习语法——你最终可能会学到错误的规则!同样,如果ASR错误纠正模型在“纠正”实际上比原始错误更糟糕的数据上进行训练,那么它就不会非常有效。现有方法,例如《通过关注两者进行错误纠正》(Error Correction by Paying Attention to Both)中提到的方法,在嘈杂环境中往往表现不佳。
本研究通过引入一种更谨慎的训练数据选择方法来解决这个问题。其思想是过滤训练数据,只保留那些纠正能真正改善文本的示例。这通过应用两个主要标准来完成:1)纠正是否使句子在语法上更正确?2)纠正是否保留了句子的原始含义?通过关注这两个方面,模型可以从高质量的示例中学习,并避免被错误的纠正误导。这使得错误纠正系统更加稳健和可靠,即使初始ASR输出错误百出。这种保守的方法可以补充改进底层ASR模型的工作,例如那些探索《面向极致边缘计算的基于Conformer的语音识别》(Conformer-based Speech Recognition for Extreme Edge Computing)的工作。此外,在ASR系统需要持续学习新语言且训练数据质量不一的场景中,它也可能很有益。
主要发现
- 保守数据过滤显著提高了ASR错误纠正模型的性能,特别是在嘈杂条件下。
- 所提出的方法通过关注语言和语义上合理的训练示例,增强了纠正系统的鲁棒性。
- 实验表明,各种评估指标均有所改善,这表明微小错误和重大错误均有所减少。这些结果与当前对《生成式AI中的准确性、训练数据和模型输出》(Accuracy, Training Data, and Model Outputs in Generative AI)之间关系的理解相符。
技术解释
本文提出了一种用于ASR错误纠正训练数据的新型过滤机制。核心思想是只选择那些纠正后的句子在语言上更具可接受性且在语义上与原始句子相似的训练示例。这解决了嘈杂训练数据的问题,因为不正确的纠正可能会对模型的性能产生负面影响。第一个标准,语言可接受性,通过语言模型来衡量,这些模型评估句子的语法正确性和流畅性。第二个标准,语义相似性,通过句子嵌入技术进行评估。这衡量了原始句子和纠正后的句子之间意义的保留程度。这个过程确保模型从高质量的示例中学习,从而实现更准确和可靠的纠正。实验在标准ASR错误纠正数据集上进行。结果表明,在各种评估指标上都有显著改进,尤其是在原始ASR输出具有高错误率的场景中。保守的过滤方法被证明比传统方法更有效,特别是在具有挑战性的嘈杂环境中。
对领域的影响: 本研究通过解决训练数据质量的关键问题,为改进ASR错误纠正做出了贡献。所提出的方法有可能带来更稳健和可靠的ASR系统,这在基于语音的技术中具有广泛的应用前景。
批判性分析
尽管本文提出了一种有前景的方法,但仍有一些领域值得进一步探索。对语言模型和句子嵌入进行过滤的依赖引入了潜在的偏差和局限性。这些工具的有效性可能会因语言和领域而异。此外,过滤过程可能会无意中删除有价值的训练示例,特别是在原始句子语法严重不正确但仍传达预期含义的情况下。未来的研究可以探索更复杂的过滤策略,以考虑这些细微差别。另一个潜在的局限性在于应用过滤标准的计算成本,特别是对于大型数据集。探索更高效的过滤方法可以提高该方法的实用性。对语言可接受性和语义相似性的关注虽然至关重要,但可能无法完全捕捉人类语言的复杂性。未来的工作可以研究纳入其他因素,如语用考虑和上下文信息,以进一步完善过滤过程。
论文《基于保守数据过滤的稳健ASR错误纠正》(Robust ASR Error Correction with Conservative Data Filtering)主要侧重于句子层面的错误纠正。然而,ASR中的错误通常发生在词或子词层面。研究如何调整这种过滤方法来处理这些更细粒度的错误将是有益的。最后,论文的评估侧重于标准基准数据集。评估该方法在现实世界ASR数据上的有效性将很有价值,因为现实世界数据通常具有更大的可变性和噪声。
结论
本研究通过强调训练数据质量的重要性,为ASR错误纠正领域做出了宝贵贡献。所提出的保守过滤方法为增强ASR系统在嘈杂环境中的鲁棒性和可靠性提供了一种有前景的方法。尽管需要进一步研究以解决某些局限性,但基于语言和语义标准选择性过滤训练数据的核心思想对于提高ASR错误纠正技术的准确性和整体性能具有巨大潜力。这可以促进语音接口在各种应用中更无缝和有效地集成,从而影响我们与技术的日常互动方式。