潘德莫尼姆:变形金刚的故事







本文最初发布于此地

让我们思考不可思议,让我们做不可能之事,让我们准备好应对那不可言喻之物本身,看看我们是否能最终言喻它。~道格拉斯·亚当斯
Transformer的“Attention Is All You Need”论文已成为传奇。这可能是唯一一篇拥有维基百科页面的现代AI论文,截至本文撰写时,已被引用超过16万次。它已成为如此的传奇,以至于在2023年,也就是最新arXiv版本发布约六年之后,又发布了一个新版本,主要就是为了添加这个。
 图01:来自https://arxiv.org/abs/1706.03762v7
图01:来自https://arxiv.org/abs/1706.03762v7
这篇论文背后的故事及其思想的起源,与论文本身一样丰富而有趣。它讲述了一群人因为一个想法而走到一起,并为此全心投入、痴迷其中。这个故事内容丰富,如果拍成电影,一定会票房大卖。亚当·麦凯或大卫·芬奇,如果您读到这:我已准备好为这部即时经典编写剧本!保证。
这个故事之前已经被报道过,最著名的是Wired(我最喜欢的!)、The New Yorker、Bloomberg和Financial Times。尽管这些文章为广大读者提供了有价值的概览,但从技术角度来看,它们仍停留在表面。
在本文中,我旨在以我希望阅读的方式讲述Transformer的故事,并希望它能吸引其他对这一引人入胜的想法细节感兴趣的人。本叙述取材于视频采访、讲座、文章、推文/X,以及对文献的一些深入挖掘。我已尽力做到准确,但错误仍有可能发生。如果您发现任何不准确之处或有任何补充,请务必联系我,我将非常乐意进行必要的更新。
一切都始于注意力…
注意力的必然性
机器翻译是推动自然语言处理早期进展的主要引擎。谷歌对谷歌翻译(2006年推出)的投资凸显了这一点,因为它成为了一个关键项目,将大量资源投入到自然语言处理研究的特定领域。
但机器翻译不仅仅是简单的词语替换。一个复杂的问题很快浮现:对齐。语言并非简单地词对词的相互替换。要真正进行翻译,需要理解一种语言中的短语、句子结构,甚至文化语境如何与另一种语言中的对应部分对齐。简单来说,对齐是在翻译过程中将两种语言文本中对应的片段进行匹配的过程。
除了对齐之外,机器翻译的另一个基本但复杂度较低的障碍源于语言本身的性质:**可变长度输入**。与处理固定大小数据的计算机视觉问题不同,语言本质上是灵活的。机器翻译系统需要能够处理这种可变性,同时仍能产生连贯准确的翻译。
 图02:摘自《使用神经网络进行序列到序列学习》和《使用RNN编码器-解码器学习短语表示用于统计机器翻译》
图02:摘自《使用神经网络进行序列到序列学习》和《使用RNN编码器-解码器学习短语表示用于统计机器翻译》
为了解决可变长度输入问题,编码器-解码器架构在两篇同时发表的不同论文中被引入,并成为机器翻译的标准方法。其核心思想是将混乱的、可变长度的输入句子压缩成一个单一的、固定大小的向量,这是一种信息瓶颈。由编码器创建的这个固定大小的向量,旨在封装输入句子的全部含义。然后,解码器将利用这种固定大小的表示,逐词生成翻译后的句子。
虽然这种编码器-解码器方法提供了一种看似优雅的处理可变输入的方式,但它并非完美的解决方案。特别是对于非常长的句子,将整个句子的含义压缩到一个单一的固定大小向量中,不可避免地导致信息丢失和翻译质量下降。这就又回到了对齐问题!
与其强迫编码器将整个句子的含义压缩成一个固定的向量,为什么不让它将输入句子编码成一个向量序列,然后让解码器在翻译过程中(搜索)源句子中的正确单词呢?
 图03:来自https://github.com/google/seq2seq
图03:来自https://github.com/google/seq2seq
2014年,Dzmitry Bahdanau 是 Yoshua Bengio 实验室的实习生。他被分配到机器翻译项目,与 Kyunghyun Cho 和团队合作。他们的团队发布了引入编码器-解码器架构用于机器翻译的两篇论文之一(另一篇来自 Ilya Sutskever 和谷歌团队)。和许多人一样,他对将句子含义塞进单个向量的做法并不满意,这根本说不通!
受他中学翻译练习的启发,他想:与其强迫编码器将整个句子的意思压缩成一个固定大小的向量,为什么不让它将输入句子编码成一个向量序列,然后让解码器在翻译过程中(搜索)源句子中的正确单词,从而一劳永逸地解决压缩和对齐问题呢?而这个问题的答案就是通过联合学习对齐和翻译的神经机器翻译(又称注意力)论文。
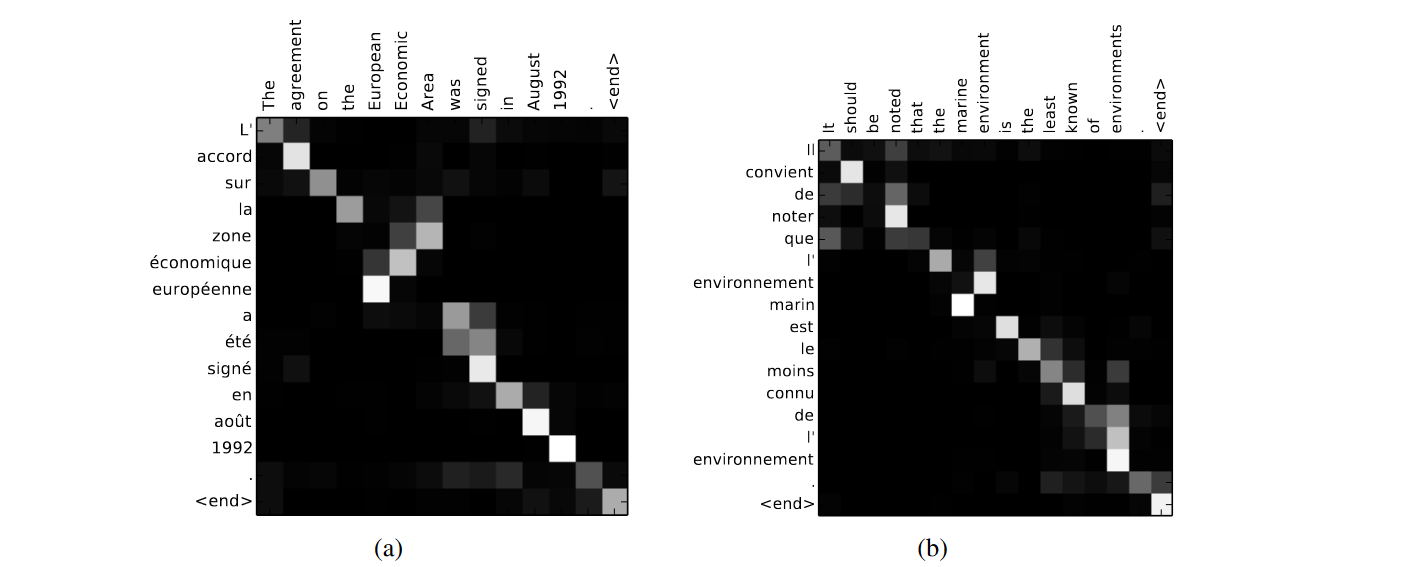 图04:RNNsearch-50发现的样本对齐。来自https://arxiv.org/abs/1409.0473
图04:RNNsearch-50发现的样本对齐。来自https://arxiv.org/abs/1409.0473
有趣的是,如果你阅读这篇论文,你会发现这种机制被称为RNNSearch。是Yoshua Bengio想出了“注意力”这个词,在一个简短的段落中解释了他们机制背后的直觉。
 图05:来自https://arxiv.org/abs/1409.0473
图05:来自https://arxiv.org/abs/1409.0473
注意力机制的起源和灵感背后的故事,是在Andrej Karpathy和Dzmitry Bahdanau之间的一封邮件往来中讲述的。后来,Andrej在X上发布了这条推文,分享了这一故事。
 图06:注意力起源故事。摘自Andrej Karpathy的推文
图06:注意力起源故事。摘自Andrej Karpathy的推文
虽然Dzmitry的论文常被认为是注意力机制普及的功臣(毕竟他们提出了一个绝妙的名字!),但其潜在概念在许多其他同期工作中也得到了探索。我尤其欣赏Dzmitry在其中一段中讨论的,他认为注意力思想是必然出现的,只是在等待合适的时机浮现。
但我认为这个想法不会再等更长时间才被发现。即使我、Alex Graves和这个故事中的其他人物当时没有进行深度学习,注意力也只是在深度学习中实现灵活空间连接的自然方式。这是一个几乎显而易见的想法,只是在等待GPU足够快,才能让人有动力并认真对待深度学习研究。~Dzmitry Bahdanau
注意力是必然的!
异端的种子:自注意力
我们提出了一种新的简单网络架构——Transformer,它完全基于注意力机制,完全摒弃了循环和卷积。——《Attention Is All You Need》
到2016年,注意力已在该领域站稳脚跟,谷歌宣布谷歌翻译在2006年推出十年后,将过渡到神经机器翻译引擎:谷歌神经机器翻译 (GNMT)。GNMT的详细信息和架构在一份全面的技术报告中进行了概述。
 图07:来自https://arxiv.org/abs/1609.08144
图07:来自https://arxiv.org/abs/1609.08144
这份报告上有很多大名鼎鼎的人物,如Jeff Dean、Oriol Vinyals、Greg Corrado、Quoc Le和Lukasz Kaiser,其中Lukasz Kaiser是《Attention is All You Need》的合著者之一。GNMT旨在利用神经机器翻译系统的能力,同时减轻其计算成本高昂和鲁棒性不足等弱点。所提出的系统是一个8层LSTM(RNN)编码器-解码器,并带有注意力机制,以及其他改进,如层间残差连接、词片分词和量化。
他们甚至尝试用强化学习来(微调)模型,但这只会提高BLEU分数,而没有带来人类可察觉的质量提升。这篇论文很有趣,也有很多见解,我鼓励大家阅读。
 图08:来自https://arxiv.org/abs/1609.08144
图08:来自https://arxiv.org/abs/1609.08144
让我们快速回顾一下我们现在所处的位置。我们拥有了可以从头到尾处理机器翻译等任务的编码器-解码器架构。多亏了注意力机制,我们不再需要将整个句子的含义塞进一个微小的向量中。此外,我们还有一个正在使用和优化这项技术的生产级系统。问题解决了吗,还是有更多值得探讨的呢?
 图09:来自https://arxiv.org/abs/1601.06733
图09:来自https://arxiv.org/abs/1601.06733
还有一个瓶颈。
 图10:来自https://arxiv.org/abs/1601.06733
图10:来自https://arxiv.org/abs/1601.06733
同年,爱丁堡大学的研究人员提出了长短期记忆网络(LSTMN)。受人类处理语言方式的启发,并借鉴了2014年引入的记忆网络,LSTMN旨在通过将每个输入token的表示存储在独特的记忆槽中,而不是将其压缩成固定大小的记忆,从而使LSTM能够利用注意力推断token之间的关系。
 图11:来自https://arxiv.org/abs/1601.06733
图11:来自https://arxiv.org/abs/1601.06733
有趣的是,我们现在可以将LSTMN插入到编码器-解码器设置中,这为我们提供了两种类型的注意力:“互注意力”(inter-attention),用于编码器和解码器之间;以及“内注意力”(intra-attention),用于同一序列中单词(token)之间的关系,如下图所示。
房间里的大象
哦,你们知道我们在这里受苦的人,请在祷告中不要忘记我们。~ 伊鲁兰公主的《穆阿迪布手册》
所以,这就是事情变得有趣,也是我们故事开始的地方。我们几乎收集了所有能召唤Transformer的关键成分:
编码器-解码器架构。
两种不同类型的注意力:互注意力(编码器与解码器之间)和自注意力(序列内部)。
残差连接。
现在的问题是:我们的配方中还缺少哪些关键成分?或者更准确地说,我们实际上可以(很乐意)放弃哪些(看似)必不可少的部分?
答案,你可能已经猜到了,是循环神经网络(RNN)。
没有一些技巧,RNN过去是,现在仍然是令人头痛的问题,而且有效地扩展它们是更大的挑战。它们根本性的缺陷在于它们的顺序处理;这不能“让加速器满意”。这就引出了一个问题:我们能否构思出一种克服这些限制的替代架构?
2016年,《Attention is All You Need》论文的合著者之一Jakob Uszkoreit,是一个研究团队的成员,他们正在研究这种可能性。他们提出的RNN替代方案是完全消除循环,仅依赖注意力机制。该团队专注于自然语言推理(NLI)任务,引入了可分解注意力(DecAtt)模型;这是一种简单的架构,只依赖于对齐,并且“相对于输入文本完全可计算分解”。
 图12:来自https://arxiv.org/abs/1606.01933
图12:来自https://arxiv.org/abs/1606.01933
通过将NLI任务分解为独立的子问题(如图所示),并仅使用互注意力和前馈网络,他们在SNLI数据集上取得了最先进的结果,其参数数量比LSTMN小了近一个数量级。此外,他们还探索了引入内注意力(来自LSTMN,在论文中称为句内注意力),这带来了显著的性能提升。
 图13:来自https://arxiv.org/abs/1606.01933
图13:来自https://arxiv.org/abs/1606.01933
在后续论文中,受这一鼓舞人心的结果的激励,他们将DecAtt模型与字符n-gram(而非单词)嵌入和预训练应用于问题释义识别任务。值得注意的是,这可能是第一篇使用“自注意力”一词的论文。
 图14:”自注意力”一词的诞生。来自https://arxiv.org/abs/1704.04565
图14:”自注意力”一词的诞生。来自https://arxiv.org/abs/1704.04565
他们的模型再次展现出卓越的性能,在Quora问题释义数据集上超越了多种更复杂的架构。
 图15:来自https://arxiv.org/abs/1704.04565
图15:来自https://arxiv.org/abs/1704.04565
但Jakob仍不满足。他希望通过使用更多数据来进一步推进这个想法。然而,团队其他人看法不同。他们对自己的成功非常满意,决定专注于将系统投入实际应用,而不是继续探索其极限。但Jakob有不同的看法。他认为自注意力是一种更好、更自然的计算机处理序列的方式。
他不仅仅对自注意力感兴趣;他沉迷于它。这不仅仅是一种智力上的好奇;它是一个决定性的焦点,类似于Geoffrey Hinton对神经网络的传奇奉献,或者Alec Radford对语言模型的强烈痴迷(也许是另一个故事)。Jakob对自注意力的关注拥有同样的强度,同样的改变领域潜能。
为什么不使用自注意力呢?~ Jakob Uszkoreit为他同事Illia Polosukhin面临的问题提出的解决方案。
但仅仅使用自注意力还不足以让我们走到今天。要真正发挥作用,它还需要其他部分。这些其他部分来自一个对这个想法坚定不移的新群体。现在,让我们简要谈谈Transformer的开发者们是如何汇聚一堂的。
汇聚一堂
“Attention is All You Need”背后的团队并非通过某个正式的项目指令组建起来的。相反,它更多是偶然发生,以一种自然的方式,就像事物慢慢地、平稳地(我们可以说,有机地)融合在一起。团队并非一蹴而就;更像是人们分批加入。将他们凝聚在一起的是他们对一个雄心勃勃的想法的强烈专注。
这一切都始于Jakob Uszkoreit和Illia Polosukhin,他们已经在Building 1945紧密合作。Ashish Vaswani在Building 1965从事机器翻译工作,紧邻Illia和Jakob的办公楼。距离足够近,足以让一个激进的新想法的耳语在办公园区内传播。被他偶然听到的东西所吸引,并被这个想法的宏伟潜力所吸引,Ashish短途步行到Building 1945并加入了他们。这三位——Jakob、Illia和Ashish——组成了项目的第一批成员。
在我们的故事中,一个反复出现的主题将变得显而易见:**新成员偶然听到小组的讨论,对他们的想法感到兴奋,并随后加入团队**。事实上,周围环境在促进这种自然扩张方面发挥了关键作用,正如我们将看到的。
Niki Parmer和Llion Jones加入了团队。Niki通过与Jakob的合作了解了这个想法,Llion则通过他与Illia的联系。有趣的是,尽管Llion与Illia合作,但他并不是直接从Illia那里听到自注意力的消息。相反,他从另一位同事那里听到了这个概念。Llion被这个概念所吸引,于是决定加入团队。他们的到来标志着团队组建的第二波。
回到环境的影响,值得注意的是,除了 Ashish 之外,团队的大部分成员都在 1945 号楼设有办公桌,但他们大多在 1965 号楼工作。这主要是因为 1965 号楼的微厨房里有一台**高级意式咖啡机**。这个看似微不足道的细节在团队的后续扩张中发挥了重要作用。
他们在1965号大楼工作,他们的工作吸引了Lukasz Kaiser,以及当时还是实习生的Aidan Gomez,都是在(再次)无意中听到他们的讨论后加入的。两人都在研究Tensor2Tensor。对于那些好奇Tensor2Tensor命运的人来说,它后来发展成了Trax,这是Google基于JAX构建的神经网络库之一。
Lukasz 就像一位大师,他能跟踪领域内发生的一切并加以采纳。因此,在 Tensor2Tensor 内部,有一些新出现的小东西,可能只有一篇论文提到,人们对此感兴趣,比如 LayerNorm 和学习率调度中的热身,但它们尚未真正普及。所有这些小部分都是默认开启的。所以,当 Noam、Ashish、Niki 和 Jakob 过来采纳 Tensor2Tensor 时,所有这些东西都是默认开启的。~ Aidan Gomez
同样,Noam Shazeer 在 1965 号楼的走廊里经过 Lukasz 的办公区时,听到了一段关于自注意力和替换 RNN 的讨论计划。他非常兴奋,立刻决定加入他们,这标志着团队成员的最后一波加入和团队的完整。
这些理论或直觉机制,比如自注意力,总是需要非常细致的实现,通常由少数经验丰富的“魔术师”来完成,才能显示出任何生命迹象。~ Jakob Uszkoreit
可以说,1965号楼的意式咖啡机至少应该在论文中获得一个致谢。
打破“精灵”的限制
我们已经从没有概念验证,到拥有了至少与当时最好的LSTM替代方案相媲美的东西。~ Jakob Uszkoreit
 图16:来自Transformer:一种用于语言理解的新型神经网络架构
图16:来自Transformer:一种用于语言理解的新型神经网络架构
宏伟的抱负
起初,我并不了解全貌,我以为那些只是些异常聪明的人在攻克机器翻译,也许是为了追求一个高得离谱的BLEU分数,然后偶然间发现了什么了不起的东西。但事实是,他们的抱负远不止于此。他们本质上是将机器翻译作为特洛伊木马,将他们的真实想法悄悄引入世界。他们的目标是创建一个能够理解各种输入(文本、图像和视频)的模型。一个多模态模型。更根本地说,一个未来深度学习不再那么依赖顺序处理的模型。
引用Ashish的话:
我们最初的抱负某种程度上失败了。我们开始这个项目是因为我们想模拟 token 的演变。它不仅仅是线性生成,而是文本或代码的演变。我们迭代、编辑,这使我们有可能模仿人类如何演化文本,同时也将它们作为过程的一部分。因为如果你像人类一样自然生成它,他们实际上可以得到反馈。~ Ashish Vaswani
以及论文的结论部分,其中他们承诺会再次回来:
 图17:来自https://arxiv.org/abs/1706.03762
图17:来自https://arxiv.org/abs/1706.03762
他们立即兑现了这个承诺。同月,他们紧随其开创性的“Attention is All You Need”论文,发布了“One Model To Learn Them All”,引入了**MultiModel**。这个新架构融合了卷积、注意力机制和稀疏门控专家混合等构建模块,以处理多样化的输入和输出模态。诚然,这个名字不如“Transformer”那么朗朗上口,而且这篇论文也没有得到足够的关注(并非双关语)。不过,我还是鼓励大家阅读这篇超前的论文。
 图18:来自https://arxiv.org/abs/1706.05137
图18:来自https://arxiv.org/abs/1706.05137
回到“Attention Is All You Need”……
尽管他们雄心勃勃,但重要的是,他们从一开始就力求尽可能地保持简单。他们甚至有一个早期的概念验证,其性能已经可以与当时现有的 LSTM 替代方案竞争。这很好地说明了加尔定律(Gall's Law):“一个复杂的系统,如果它能正常工作,那它必然是从一个简单的、能正常工作的系统演变而来的。一个从零开始设计的复杂系统永远不会正常工作,也无法修补使其正常工作。你必须从一个能正常工作的简单系统开始。”
在最初的基础上,他们开始添加和实验各种组件,这一过程通过 Tensor2Tensor 库得到了显著的便利。正如前面提到的,Lukasz 和 Aidan 在加入团队之前就已经在 Tensor2Tensor 上工作了。而 Tensor2Tensor 是另一个雄心勃勃的项目,致力于突破自回归和多模态学习的界限。该库在当时提供了许多新颖和新兴的组件,例如 Layer Normalization 和学习率预热调度。
我总觉得有点好笑,Lukasz 随便添加的那些东西,只是因为他玩玩而已,结果却都至关重要。~ Aidan Gomez
我想到的一个平行故事是旋转位置编码(RoPE)的故事,它最终彻底改变了神经网络处理位置编码的方式。引入RoPE的论文于2021年发表,并因其在EleutherAI的GPT-J中,以及后来在Meta的Llama(基于GPT-J的实现)中的采用而声名鹊起。确实,跟上文献进展是值得的!
说到位置编码,Noam Shazeer提出的无参数位置表示和多头注意力,被证明是取代LSTM和一般RNNs的最关键要素之一。2017年初左右,Noam(与Geoffrey Hinton、Jeff Dean等人一起)刚刚发布了稀疏门控专家混合层(MoE)论文。你可以猜到,当他提出多头注意力时,那篇论文中的想法可能在他的脑海中浮现。

于是,他们通过不断迭代,添加新组件并实验各种实现,继续完善他们的初始模型。有趣的是,他们的探索甚至在一个阶段引入了卷积。但最大的问题是:这些新添加的部分中,哪些真正提升了模型性能?又有哪些部分可以移除呢?
接下来是最引人入胜的部分!
消融实验
有趣的是,我们最初就是从那种最精简的版本开始的,对吧?然后我们添加了东西。我们添加了卷积,我想后来我们又把它们去掉了。~ Ashish Vaswani
这是一个很好的例子,说明了消融实验在加强已有的扎实工作中的关键作用。论文中详细介绍的广泛消融实验,极大地塑造了模型的最终架构,甚至影响了其标题,正如我们很快将看到的。有趣的是,论文中呈现的消融结果(如下表所示)仅代表了他们进行的全部实验中的一小部分。
 图20:来自https://arxiv.org/abs/1706.03762
图20:来自https://arxiv.org/abs/1706.03762
这就像他们遇到了加尔定律的一个变体!他们从一个简单的模型开始,逐步添加了几个组件来提高性能,然后通过战略性地移除元素进一步提高了性能。
奇妙的名字及其来源
我们有两个值得纪念的名字要探讨:架构本身和论文的标题。这些名字背后的故事是什么,创作者是如何想出它们的?让我们从“Transformer”开始。
“Transformer”从第一天起就存在,甚至曾是论文标题的有力竞争者。当Jakob、Illia和Ashish首次合作这个项目时,他们最初的论文工作标题是**“Transformers:迭代自注意力和各种任务处理”**。“Transformer”这个术语的灵感来源于两个关键方面:首先,系统转换输入数据以提取有意义信息的核心机制。虽然,正如许多人观察到的那样,这几乎可以描述所有机器学习系统,但它仍然是一个很棒的名字。其次,它也是对我们塞伯坦的朋友的俏皮致敬😃。这里是Jakob和Jensen Huang之间关于“Transformer”的对话:
Jakob:它符合模型所做的事情,对吧?每一步都实际转换了它所操作的整个信号,而不是必须一步一步地迭代它。
Jensen:按这个逻辑,几乎所有的机器学习模型都是Transformer!
Jakob:在那之前,没人想过用这个名字。
虽然“Transformer”从一开始就存在,但它并不是唯一的竞争者。在稍有不同的现实中,我们可能已经知道这种架构叫做“CargoNet”。要理解这个替代名称的理由,让我们听听Noam Shazeer怎么说:
有很多名字。我的意思是,比如有个叫 CargoNet 的。我写了一些东西,一层是卷积,一层是注意力,一层我称之为识别,或者类似前馈网络的东西。所以,卷积,注意力,识别,谷歌…… CargoNet!~ Noam Shazeer
一个关于Transformer和注意力的有趣轶事,可能通过这条推文而广为流传,这条推文当时引起了广泛讨论。它暗示了灵感来源于丹尼斯·维伦纽瓦2016年电影《降临》中的外星语言,而这部电影本身又改编自特德·姜1998年的中篇小说《你一生的故事》。对于那些不熟悉《降临》的人来说,电影中出现的外星语言有两种形式,反映了对时间的不同感知。一种形式将时间呈现为线性且顺序的,而另一种则将其描绘为同时且同步的,一个单一的圆形符号能够传达丰富的信息。是的,这里的类比非常明显,如果这是真的,那将是一个很棒的故事。但不幸的是,事实并非如此……
 图21:《降临》(2016)中的外星语言
图21:《降临》(2016)中的外星语言
这个轶事的起源可以追溯到《Hard Fork》播客的一集。在那一集中,主持人错误地解读了 Illia Polosukhin 在《金融时报》文章中将自注意力比作《降临》中的外星语言。然而,Illia 的比较并未暗示任何实际的灵感。这条推文可能促使 Andrej Karpathy 分享了他与 Dzmitry Bahdanau 关于注意力起源的电子邮件往来。
现在,论文标题。是Llion Jones想出了“Attention Is All You Need”。这发生在他们进行消融研究并发现注意力机制,在所有其他组件中,是最关键的时期。它也是对披头士乐队标志性歌曲“All You Need Is Love”的致敬。
所以,我想出了这个标题,基本上发生的事情是,在我们寻找标题的时候,我们正在进行消融实验,我们最近开始尝试移除模型的一些部分,只是为了看看它会变得多糟糕。出乎意料的是,它开始变得更好,包括移除了所有卷积。我当时想,“这工作得更好!”。这就是我当时的想法,所以标题就这么来了。~ Llion Jones
于是,在2017年6月12日星期一,“Attention Is All You Need”在arXiv上发布,这一天我们完全可以称之为**Transformer日**。
 图22:看!Transformer!
图22:看!Transformer!
最后,标志性的Transformer图是用Adobe Illustrator制作的。再无更多内幕!
Transformer之后的时代
没有Transformer,我认为我们不会走到今天。~ Geoffrey Hinton
Transformer改变了一切,这是不可否认的。但它当时是如何被接受的呢?现在回顾起来,我们很容易看到它巨大的影响。然而,重温NeurIPS 2017的提交评审,会发现各种意见,从“这非常令人兴奋!”到“这还可以”。让我们听听评审员1怎么说:

但我们不能忘记审稿人 #2!
我也很好奇这篇论文首次被引用的语境。有趣的是,我能找到的最早引用Transformer的论文是对深度强化学习概述的修订版。这份概述最初于2017年初发布,随后在7月15日(“Attention Is All You Need”发布约一个月后)重新提交。
 图24:来自https://arxiv.org/abs/1701.07274v3
图24:来自https://arxiv.org/abs/1701.07274v3
在最初成功的基础上,作者们并未止步于文本(正如他们所承诺的)。他们立即开始探索 Transformer 在各种其他领域的潜力。例如,他们开发了图像 Transformer,以探究注意力能否彻底改变计算机理解图像的方式;音乐 Transformer,以探索音乐生成(显而易见!);以及通用 Transformer,这是对 Transformer 模型的一种泛化尝试,它具有动态停止机制,根据不同 token 的难度分配不同的处理时间。所有这些都发生在2018年!
那么,Transformer 之后的时代呢?嗯,…
Transformer 架构的出现预示着现代人工智能热潮,它作为一股强大的催化剂,推动该领域进入了一个快速发展的新时代。时至今日,它仍然是支撑我们正在见证的大型语言模型 (LLM) 显著进步的基础技术。所以,是的,可以说它影响深远 😃。
