🤔👀🎬🖥️📖 Kimi-VL-A3B-Thinking-2506:快速导航









在我们首次发布开源多模态推理模型 Kimi-VL-A3B-Thinking 两个月后,我们更新了常规改进版本 Kimi-VL-A3B-Thinking-2506 (💬演示在此)。与之前的版本相比,新的 2506 版本提供了几项新的或改进的能力。
- 思考更智能,消耗更少令牌:2506 版本在多模态推理基准上取得了更好的准确率:MathVision 56.9 (+20.1),MathVista 80.1 (+8.4),MMMU-Pro 46.3 (+3.2),MMMU 64.0 (+2.1),同时平均思考长度减少了 20%。
- 通过思考看得更清楚:与之前专注于思考任务的版本不同,2506 版本在通用视觉感知和理解方面也能达到相同甚至更好的能力,例如 MMBench-EN-v1.1 (84.4)、MMStar (70.4)、RealWorldQA (70.0)、MMVet (78.4),超越或匹敌我们非思考模型 (Kimi-VL-A3B-Instruct) 的能力。
- 扩展到视频场景:新的 2506 版本在视频推理和理解基准上也有所改进。它在 VideoMMMU 上创造了开源模型的新 SOTA (65.2),同时在通用视频理解方面也保持了良好的能力 (Video-MME 71.9,与 Kimi-VL-A3B-Instruct 相当)。
- 扩展到更高分辨率:新的 2506 版本支持单张图像 320 万总像素 (1792x1792),比之前版本高出 4 倍。这在高分辨率感知和 OS-agent 接地基准上带来了显著的改进:V* Benchmark (不带额外工具) 83.2,ScreenSpot-Pro 52.8,OSWorld-G (带拒绝的完整集合) 52.5。
请参阅 模型页面 中的基准测试结果。在本博客中,我们提供了使用这个新模型处理图像、视频、PDF 和 OS 截图的简单示例。
开始
由于该模型将生成多达 32K 令牌,我们建议使用 VLLM 进行推理,它已支持 Kimi-VL 系列。
MAX_JOBS=4 pip install vllm==0.9.1 blobfile flash-attn --no-build-isolation
安装 flash-attn 很重要,以避免 CUDA 内存不足。
安装后,您可以按如下方式初始化模型和处理器
from transformers import AutoProcessor
from vllm import LLM, SamplingParams
model_path = "moonshotai/Kimi-VL-A3B-Thinking-2506"
llm = LLM(
model_path,
trust_remote_code=True,
max_num_seqs=8,
max_model_len=131072,
limit_mm_per_prompt={"image": 256}
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
然后,我们为这个思考模型定义默认采样参数(32K 输出令牌,温度=0.8),以及一个简单的片段来拆分思考和摘要部分。
sampling_params = SamplingParams(max_tokens=32768, temperature=0.8)
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
OUTPUT_FORMAT = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
通用图像理解
视觉常识

这是什么品种的猫?用一个词回答。
import requests
from PIL import Image
url = "https://huggingface.co/spaces/moonshotai/Kimi-VL-A3B-Thinking/resolve/main/images/demo6.jpeg"
image = Image.open(requests.get(url,stream=True).raw)
messages = [
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "What kind of cat is this? Answer with one word."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
thinking, summary = extract_thinking_and_summary(generated_text)
print(OUTPUT_FORMAT.format(thinking=thinking, summary=summary))
示例如下(由于温度原因,不同运行的响应可能有所不同)
思考
摘要
布偶猫
高分辨率图像上的视觉识别

孩子的鞋子和裙子是什么颜色?以 JSON 结构回答。
from PIL import Image
url = "https://vstar-seal.github.io/images/examples/sample4/origin.jpg"
image = Image.open(requests.get(url,stream=True).raw)
print(image.size)
messages = [
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "What is the color of the child's shoes and dress? Answer as a JSON struct."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
output_format = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
thinking, summary = extract_thinking_and_summary(generated_text)
print(output_format.format(thinking=thinking, summary=summary))
一个示例如下,正确回答了这张高分辨率图片中两者的颜色
思考
现在,将答案构造成 JSON 格式。问题要求回答孩子的鞋子和裙子的颜色。所以键“shoes”的值为“green”,键“dress”的值为(颜色,可能是蓝色?等等,再检查一下。裙子——看着图片,孩子的裙子是深蓝色的。鞋子是绿色的。所以
{ "shoes": "绿色", "dress": "蓝色" }
等等,需要更精确。再检查图片。孩子的鞋子:脚上穿着绿色的鞋子。裙子:衣服是一件深蓝色的裙子。所以这是正确的。
摘要
{
"shoes": "green",
"dress": "blue"
}
图像推理
图表推理
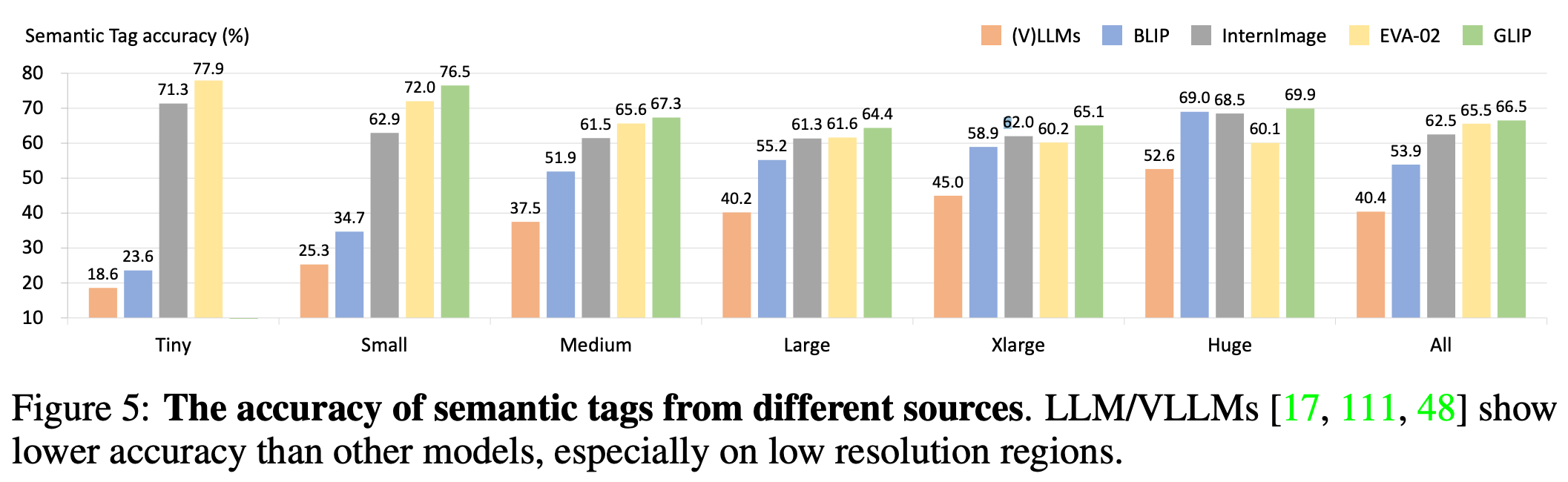
在 Tiny 类别中,哪个模型的语义标签准确率 (%) 最高?
from PIL import Image
url = "https://raw.githubusercontent.com/mathvista/data/main/images/4781.jpg"
image = Image.open(requests.get(url,stream=True).raw)
messages = [
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "Which model has the highest Semantic Tag accuracy (%) in the Tiny category?"}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
output_format = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
thinking, summary = extract_thinking_and_summary(generated_text)
print(output_format.format(thinking=thinking, summary=summary))
输出如下,不仅答案正确,思考过程中的信息也正确
思考
摘要
要确定 Tiny 类别中语义标签准确率 (%) 最高的模型,我们分析条形图中“Tiny”组的条形高度。
识别“Tiny”类别中的模型及其相应的准确率
- (V)LLMs:18.6%
- BLIP:23.6%
- InternImage:71.3%
- EVA-02:77.9%
- GLIP:(在视觉上没有明确标记数值,但视觉上“Tiny”中最高的条形是 EVA-02 的条形,为 77.9%)。
比较数值
其中,77.9% (EVA-02) 是最高的。
EVA-02 在 Tiny 类别中具有最高的语义标签准确率 (%)。
数学计算
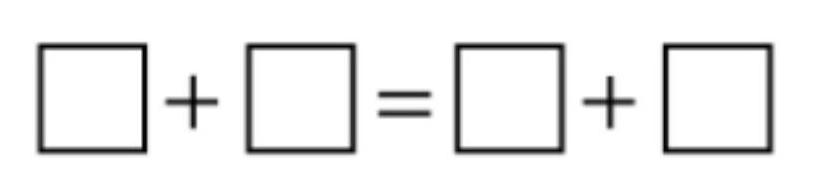
数字 1、3、4、5 和 7 中的四个填入方框,使计算正确。哪个数字没有被使用?
from PIL import Image
url = "https://mathllm.github.io/mathvision/visualizer/data/images/64.jpg"
image = Image.open(requests.get(url,stream=True).raw)
messages = [
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "Four of the numbers 1,3,4,5 and 7 are written into the boxes so that the calculation is correct. Which number was not used?"}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
output_format = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
thinking, summary = extract_thinking_and_summary(generated_text)
print(output_format.format(thinking=thinking, summary=summary))
该模型可以轻松处理这个简单的谜题
思考
让我们检查所有组合
1 + 3 = 4; 1 + 4 = 5; 1 + 5 = 6; 1 + 7 = 8;
3 + 4 = 7; 3 + 5 = 8; 3 + 7 = 10;
4 + 5 = 9; 4 + 7 = 11;
5 + 7 = 12.
现在我们需要两对数字的和相同。让我们寻找相等的和。
1 + 7 = 8,而 3 + 5 = 8。哦,这行得通!所以 1 + 7 = 3 + 5。让我们检查哪个数字被遗漏了。使用的数字是 1、7、3、5。所以剩下的数字是 4。让我们验证是否还有其他可能性,但我们来看看
还有另一对吗?1 + 5 = 6,有没有另一对和为 6 的?3 + 3,但我们没有两个 3。4 + 2,没有。所以那是不可能的。3 + 4 = 7,有没有另一对和为 7 的?1 + 6,没有。所以唯一可能的相同和是 1+7 和 3+5 的 8。因此,未使用的数字是 4。
摘要
为了解决这个问题,我们首先检查数字 1、3、4、5 和 7 的所有对的和。
计算两两之和
- ( 1 + 7 = 8 )
- ( 3 + 5 = 8 )
这两对的和相同,所以 (1 + 7 = 3 + 5)。这里使用的数字是 1、7、3 和 5。
因此,未使用的数字是 4。
OS-Agent 接地

任务说明:仔细检查截图,点击论文提交者的个人资料。
对于 OS-agent 接地任务,我们建议将温度设置为 0.2,以获得更稳定的接地结果。
os_agent_sampling_params = SamplingParams(max_tokens=8192, temperature=0.2)
from PIL import Image
url = "https://huggingface.co/moonshotai/Kimi-VL-A3B-Thinking-2506/resolve/main/figures/screenshot.png"
image = Image.open(requests.get(url,stream=True).raw)
messages = [
{"role": "system", "content": "You are a GUI agent. You are given a task and a screenshot of a computer screen. You need to perform a action and pyautogui code to complete the task. Provide your response in this format:\n\n## Action:\nProvide clear, concise, and actionable instructions.\n\n## Code:\nGenerate a corresponding Python code snippet using pyautogui that clicks on the identified UI element using normalized screen coordinates (values between 0 and 1). The script should dynamically adapt to the current screen resolution by converting the normalized coordinates to actual pixel positions."},
{"role": "user", "content": [{"type": "image", "image": ""}, {"type": "text", "text": "## Task Instruction:\n Inspect the screenshot carefully, and click into profile of the paper submitter."}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": image}}], sampling_params=os_agent_sampling_params)
generated_text = outputs[0].outputs[0].text
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
output_format = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
thinking, summary = extract_thinking_and_summary(generated_text)
print(output_format.format(thinking=thinking, summary=summary))
模型将以简洁的思考和最终答案回应,如下所示,正确点击论文提交者的虚线链接
思考
摘要
## 行动
点击论文提交者的个人资料。
## 代码
pyautogui.click(x=0.204, y=0.149)
长篇 PDF 理解

这个基准的最新技术水平是谁,并分析其性能?
在 Arxiv 上查看原始 PDF。
要回答 PDF 上的问题,我们可以直接将其渲染成页面
import fitz # pip install PyMUPDF
def download_arxiv_to_multi_image(pdf_url):
# ----------- Step 1: Download PDF -----------
print(f"Downloading PDF from {pdf_url}...")
response = requests.get(pdf_url)
local_pdf = os.path.basename(pdf_url)
with open(local_pdf, 'wb') as f:
f.write(response.content)
print("Download completed.")
# ----------- Step 2: Open PDF -----------
doc = fitz.open(local_pdf)
all_input_images = []
for page_num in range(len(doc)):
page = doc.load_page(page_num)
# Step 3: Render at native size (fast)
pix = page.get_pixmap()
# Step 4: Load pixmap into PIL Image
image = Image.open(io.BytesIO(pix.tobytes("png")))
all_input_images.append(image)
然后,我们可以将 PDF 转换为多张图像(本文为 21 张),并将其发送到模型中。
images = download_arxiv_to_multi_image("https://arxiv.org/pdf/2505.23359.pdf")
messages = [
{"role": "user", "content": [*[{"type": "image", "image": ""} for img in images], {"type": "text", "text": "Who is the state-of-the-art of this benchmark, and analyze its performance?"}]}
]
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": images}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
output_format = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
thinking, summary = extract_thinking_and_summary(generated_text)
print(output_format.format(thinking=thinking, summary=summary))
输出如下,不仅正确地指出了本文的最新技术水平,而且抓住了其主要思想的精髓。
思考
首先,我需要了解在这个上下文中“最新技术水平”的含义。它指的是在该基准上表现最好的模型。从提供的表格(表 2 和表 14)中,我可以看到评估结果。
查看表 2,它展示了各种模型在该基准上的性能。列出的模型包括 GPT-4o、o4-mini、Seed1.5-VL、Gemini-2.0-Flash、Gemini-2.5-Flash、Gemini-2.5-Pro,以及一些开源模型,如 mPLUG-Owl3、MiniCPM-V 2.6 等。每个模型都给出了准确率百分比。
从表格中可以看出,Gemini-2.5-Pro 的准确率最高,为 56.0%。这表现最为突出。其他模型如 GPT-4o 的准确率非常低(6.9%),大多数开源模型表现不佳(例如,mPLUG-Owl3 为 0.0%)。
为了确认,检查论文中的文本也提到“思考增强的 Gemini-2.5-Pro 显著优于所有其他模型,准确率达到 56.0%”。这与表格一致。
因此,最先进的模型是 Gemini-2.5-Pro,其性能明显优于其他模型,在该基准上实现了 56.0% 的准确率。
现在,分析其性能:该论文指出,大多数 SOTA MLLM 在以视觉为中心的复杂视频推理方面表现不佳,准确率非常低(例如,GPT-4o 为 6.9%)。相比之下,Gemini-2.5-Pro 表现出显著的改进,准确率达到 56.0%。这表明,扩展的思维链推理机制和“思考模式”对于解决 VIDEOREASONBENCH 中的挑战性任务至关重要。
总而言之,最先进的模型是 Gemini-2.5-Pro,其在该基准上的性能明显优于其他模型。
摘要
该基准的最新技术水平模型是 Gemini-2.5-Pro,准确率达到 56.0%。这显著优于其他模型,它们在以视觉为中心的复杂视频推理方面表现不佳——例如,GPT-4o 仅达到 6.9% 的准确率。该论文强调,扩展的思维链推理和明确的“思考”对于在该基准上的性能至关重要,而 Gemini-2.5-Pro 在这方面表现出色,大幅超越其他模型。大多数现有的视频理解基准缺乏扩展 CoT 链所需的推理深度,但 VIDEOREASONBENCH 旨在通过细粒度视觉感知和更高的推理复杂性来评估这些能力。结果清楚地表明,虽然大多数 MLLM 表现不佳,但 Gemini-2.5-Pro 经过思考增强的设计使其能够有效地处理挑战性任务。
视频理解
请将此视频分成场景,提供每个场景的开始时间、结束时间以及详细描述。
我们定义了以下辅助函数,用于将视频帧解码并调整大小,以便作为模型的输入图像。
import decord
import numpy as np
# ----------- Settings -----------
def resize_image_and_convert_to_pil(image, max_size=448):
with Image.fromarray(image) as img:
width, height = img.size
max_side = max(width, height)
scale_ratio = max_size / max_side
new_width, new_height = int(width * scale_ratio), int(height * scale_ratio)
img_resized = img.resize((new_width, new_height))
return img_resized
def fmt_timestamp(timestamp_sec):
hours = int(timestamp_sec // 3600)
minutes = int((timestamp_sec % 3600) // 60)
seconds = int(timestamp_sec % 60)
return "{:02d}:{:02d}:{:02d}".format(hours, minutes, seconds)
def get_video_frames(video_path, sample_fps=1, sample_frames=-1):
vr = decord.VideoReader(video_path)
if sample_fps > 0:
assert sample_frames < 0, "sample_frames and sample_fps cannot be set at the same time"
fps = vr.get_avg_fps()
video_duration = int(len(vr) / fps)
sample_frames = int(video_duration * sample_fps) + 1
elif sample_frames < 0:
raise ValueError("sample_fps and sample_frames cannot be set at the same time")
frame_inds = np.linspace(0, len(vr) - 1, sample_frames).round().astype(int)
frames = vr.get_batch(frame_inds).asnumpy()
timestamps = (frame_inds / fps).astype(np.int32)
return frames, timestamps
def build_messages(frames, timestamps, prompt, with_timestamp=True, max_size=448):
contents = []
images = [resize_image_and_convert_to_pil(frame) for frame in frames]
for timestamp in timestamps:
if with_timestamp:
timestamp_message = {
'type': 'text',
'text': fmt_timestamp(timestamp)
}
contents.append(timestamp_message)
part_message = {
'type': 'image',
'image': ''
}
contents.append(part_message)
prompt_content = {
'type': 'text',
'text': prompt
}
contents.append(prompt_content)
messages = [{'role': 'user', 'content': contents}]
return images, messages
然后我们按如下方式调用模型
prompt = 'Please split this video into scenes, providing start time, end time, and detailed descriptions for each scene.'
max_size = 448
with_timestamp = True
video_path = 'demo.mp4'
frames, timestamps = get_video_frames(video_path, sample_fps=1)
images, messages = build_messages(frames, timestamps, prompt, with_timestamp=with_timestamp, max_size=max_size)
text = processor.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = llm.generate([{"prompt": text, "multi_modal_data": {"image": images}}], sampling_params=sampling_params)
generated_text = outputs[0].outputs[0].text
def extract_thinking_and_summary(text: str, bot: str = "◁think▷", eot: str = "◁/think▷") -> str:
if bot in text and eot not in text:
return ""
if eot in text:
return text[text.index(bot) + len(bot):text.index(eot)].strip(), text[text.index(eot) + len(eot) :].strip()
return "", text
output_format = "--------Thinking--------\n{thinking}\n\n--------Summary--------\n{summary}"
thinking, summary = extract_thinking_and_summary(generated_text)
print(output_format.format(thinking=thinking, summary=summary))
输出如下
思考
首先,我需要对整体流程有一个很好的了解。它看起来像是精神之旅和极限运动的结合,可能带有一点纪录片的风格。让我们从最初的标题卡和主要人物的介绍开始。
场景 1:(00:00 - 00:36)介绍与祈祷
视频以一个非常黑暗的场景开场,几乎漆黑一片,唯一可见的元素是一束光。有一种期待感。然后,一位身着传统服装,可能是藏族服装的男子出现。他在一个昏暗的房间里,也许是寺庙或修道院。他开始祈祷,使用一个小小的金属转经筒。屏幕上的初始文字显示“THE NORTH FACE PRESENTS”。
场景 2:(00:36 - 01:27)自然过渡与进一步介绍
场景突然切换到白雪皑皑的山峰的惊人航拍画面。光线柔和而金色。文字出现:“A NEW FILM BY SHERPAS CINEMA。”转经筒被展示出来,旋转着,然后特写镜头显示一个旋转的金属物体,也许是转经筒的一部分。男子的眼睛被特写,他抬头望去,然后再次是旋转的转经筒。这是一个旅程的视觉隐喻。转经筒再次旋转,然后场景切换到各种山脉、冰晶、烛光祈祷大厅和星空下的山脉。这营造出一种精神和宁静的氛围。
场景 3:(01:27 - 01:48)冒险召唤与山地氛围
画面切换到一系列极限运动员,很可能是滑雪者和单板滑雪者,在白雪覆盖的山脉中。我们看到他们正在准备,眺望着广阔的山脉。这过渡到滑雪者和单板滑雪者在雪坡上穿行的蒙太奇,其中一些人正在表演技巧。这是一个明确的冒险召唤,展示了精神之旅与极限运动世界之间的对比。
场景 4:(01:48 - 02:38)极限运动蒙太奇
这是动作的核心。一段快节奏的极限运动蒙太奇:滑雪者和单板滑雪者在各种雪地环境中表演各种技巧和穿越挑战性地形。有他们跳跃、翻转和在粉雪中穿行的镜头。视觉效果充满活力,展示了他们的技能和山脉的美丽。
场景 5:(02:38 - 03:09)结论和片尾字幕
画面切回正在祈祷的男子。他的脸部特写镜头显示出沉思的表情。视频开始逐渐变黑,但在此之前,我们看到了一系列片尾字幕,显示了运动员、制作人员和赞助商的名字。最后的场景是极限运动动作的再次蒙太奇。
场景 6:(03:09 - 03:39)最终品牌和结束
视频以标题“INTO THE MIND”出现在广阔、开裂的盐滩上结束。然后,显示“THE NORTH FACE”标志,以及赞助商标志和网站“WWW.SHERPASCINEMA.COM”。整体信息是精神探索和极限冒险的结合。
我认为这个分解涵盖了视频的关键元素。开头男子精神之旅与运动员肾上腺素飙升的世界形成对比。视频似乎在宣传一种自由、冒险和自我发现的感觉。
摘要
好的,这是视频的场景分解:
视频开场几乎一片漆黑,一束光照亮了一个身着传统服饰(可能是藏族服饰)的人物(00:00)。金属容器中飘出烟雾,可能是香薰,增加了精神氛围。屏幕上出现文字:“THE NORTH FACE PRESENTS”(00:06)。
在 00:13,镜头缓慢推近一位长着长长灰胡子的老年男子,他戴着一顶传统的毛皮衬里帽子。他开始用藏语低声虔诚地祈祷,并转动一个小型金属转经筒(00:15 - 00:35)。
场景在 00:36 切换到白雪皑皑、崎岖山峰的壮丽阳光航拍画面,远处可能是喜马拉雅山脉的其他雄伟山峰。文字“A NEW FILM BY SHERPAS CINEMA”叠加在画面上(00:38)。视角继续,展示了山脉的广阔。
在 00:46,焦点转移到老人使用的转经筒旋转的金属转子的特写。紧接着是老人饱经风霜的眼睛的特写(00:47 - 00:55),然后是转经筒复杂金属设计的镜头(00:55)。场景随后转入一个动态序列(00:57 - 01:00),一位冲浪者乘着巨大的绿色海浪,象征着向冒险的转变。随后是水下镜头(00:59 - 01:02),显示冲浪者划水,然后从水下乘浪。
视频随后展示了更多令人惊叹的山地景色(01:02 - 01:06),重点是白雪皑皑的山峰和冰川。冰晶的特写(01:06 - 01:08)和快速燃烧的烛台灯中的蜡烛(01:09 - 01:12)强调了一种冥想的、精神的氛围。老人再次出现,转动着他的转经筒(01:13 - 01:16)。
一段令人惊叹的延时摄影捕捉了白雪皑皑山脉上星光璀璨的夜空,黎明的第一缕阳光正在破晓(01:16 - 01:19)。场景随后过渡到一片薄雾缭绕、空灵的山景(01:20),以及一块崎岖、泛红地面的特写(01:21),可能是火山岩或山体。更多雄伟的山景出现,首先是穿过云层(01:22 - 01:23),然后是白雪皑皑的森林,大雪纷飞(01:23 - 01:25)。
画面中展示了一条宽阔的泥泞河流的航拍镜头,河流有支流和森林覆盖的河岸(01:25 - 01:27)。转经筒旋转的特写镜头(01:27 - 01:28)引出了一系列极限运动员脸部的特写镜头(01:29 - 01:31),其中包括一位戴着北面品牌毛线帽的男子,另一位穿着红色夹克的男子,以及第三位戴着紫色毛线帽的男子,所有人都专注地看着镜头。
视频随后切换到广阔雪山山谷的令人惊叹的广角航拍镜头(01:32 - 01:37)。一群滑雪者正在穿越白雪皑皑的山脊(01:38 - 01:40)。在昏暗的房间里,一只手正在打开一本旧的皮革装帧的祈祷书,旁边是旋转的转经筒(01:40 - 01:42)。随后是云层在山峰上移动的延时摄影画面(01:42 - 01:45),以及广阔的、被风吹拂的雪山景观(01:46 - 01:47)。
一个大型传统藏族唐卡绘画的特写镜头(01:48 - 01:51)随后是原始、被风吹拂的雪山更广阔的景色(01:52 - 01:55)。随后是极限单板滑雪者和滑雪者在各种雪地环境中表演令人印象深刻的跳跃、翻转和滑雪动作的蒙太奇(01:56 - 02:17),从开阔的斜坡到茂密的粉雪森林。一个值得注意的序列是日落时从悬崖上进行的一次后空翻(02:17 - 02:19),以及另一位滑雪者在深粉雪中穿行(02:19 - 02:23)。
夜空再次出现(02:23 - 02:25),然后一名滑雪者在陡峭的斜坡上引发了一场大规模雪崩(02:25 - 02:28)。随后是雪晶的特写(02:29)和攀岩者在雪地中穿行的第一视角镜头(02:29 - 02:30),然后是更多的雪崩镜头(02:30 - 02:33)。滑雪者和单板滑雪者在壮丽的日落背景下跳跃和表演特技(02:33 - 02:38)。
视频随后回到老年男子深情祈祷的场景(02:39 - 02:43)。屏幕逐渐变黑,片尾字幕开始滚动(02:44),列出了影片中涉及的滑雪者、单板滑雪者、摄影师和工作人员的名字,并穿插着各种极限运动动作的快速剪辑,包括冲浪、单板滑雪、滑雪和激流皮划艇(02:45 - 03:08)。
最终的标题卡“INTO THE MIND”出现在一片广阔、开裂的盐滩上(03:09 - 03:13)。随后是“THE NORTH FACE”标志(03:14)、赞助商列表(03:15)和网站“WWW.SHERPASCINEMA.COM”(03:34)。视频以传统藏族寺庙建筑群的超现实艺术镜头结束,寺庙中有一个大型金色佛塔, superimposed with a mirrored image of the temple complex, as the "Sherpas Cinema" logo appears (03:27 - 03:33)。
结论
最后,我们希望这篇博客为您提供了如何充分利用 Kimi-VL-A3B-Thinking-2506 的清晰实用指南。尽管该模型仍远非完美,但其更高效的推理、改进的视觉理解以及对高分辨率和视频输入的支持可以为用户开辟新的可能性。本博客旨在将其顺利集成到您的项目中——无论您是分析图像、解析 PDF、构建 OS 代理还是开发基于视频的应用程序——并邀请您提供反馈,以便我们继续共同完善和学习。我们希望持续定期更新这款价格实惠且智能的视觉语言模型。
代表 Kimi-VL 团队





