使用计算机视觉绘制 OpenStreetMap 中的地图要素







 / [Unsplash](https://unsplash.com/photos/a-person-is-putting-pins-on-a-map-LT3prlHOVlU?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash)](https://blog.mozilla.ai/content/images/size/w1200/2025/03/stefancu-iulian-LT3prlHOVlU-unsplash.jpg) 照片由 Stefancu Iulian / Unsplash
照片由 Stefancu Iulian / Unsplash
原文链接:https://blog.mozilla.ai/map-features-in-openstreetmap-with-computer-vision/
代码:https://github.com/mozilla-ai/osm-ai-helper
HuggingFace Space 演示:https://huggingface.co/spaces/mozilla-ai/osm-ai-helper
动机
在 Mozilla.ai,我们相信人工智能 (AI) 有很多机会可以赋能由开放协作驱动的社区。
然而,这些机会需要精心设计,因为这些社区的许多成员(以及普通民众)越来越担心互联网上充斥的AI 垃圾。
基于此理念,我们开发并发布了 OpenStreetMap AI 助手蓝图。如果您热爱地图并对训练自己的计算机视觉模型感兴趣,那么您一定会喜欢深入研究这个蓝图。
为什么选择 OpenStreetMap?
数据是任何人工智能应用最重要的组成部分之一,而 OpenStreetMap 拥有一个充满活力的社区,他们协作维护和扩展最完整的开放地图数据库。
如果您没有听说过,OpenStreetMap 是一个由地图制作者社区创建的开放、可编辑的世界地图,他们贡献并维护有关道路、小径、咖啡馆、火车站等的数据。
结合其他来源(如卫星图像),这个数据库为训练不同的人工智能模型提供了无限的可能性。

作为 OpenStreetMap 的长期用户和贡献者,我希望构建一个端到端应用程序,其中模型首先使用这些数据进行训练,然后用于回馈社区。
其思想是使用人工智能来加速地图绘制过程中较慢的部分(在地图上漫游、绘制多边形),同时在关键部分(验证生成的数据是否正确)保持人工干预。
为什么选择计算机视觉?
大型语言模型(LLM)以及最近的视觉语言模型(VLM)正在占据人工智能领域的所有注意力,但仍有许多有趣的应用不需要(或不应该)使用这类模型。
OpenStreetMap 中许多地图要素都以多边形(“区域”)表示。事实证明,查找和绘制这些多边形对人类来说是一项非常耗时的任务,但计算机视觉模型可以很容易地为此任务进行训练(在提供足够数据的情况下)。
我们选择将查找和绘制地图要素的工作分解为两个计算机视觉任务,使用最先进的非LLM模型:
这些模型轻巧、快速且本地友好——使用不需要高端 GPU 即可运行的模型令人耳目一新。例如,YOLOv11 和 SAM2 的组合权重占用的磁盘空间(<250MB)比任何最小的视觉语言模型(如 SmolVLM (4.5GB))都要少得多。
通过结合这些模型,我们可以自动化大部分地图绘制过程,同时让人类掌握最终验证的控制权。
OpenStreetMap AI 助手蓝图
该蓝图可分为 3 个阶段
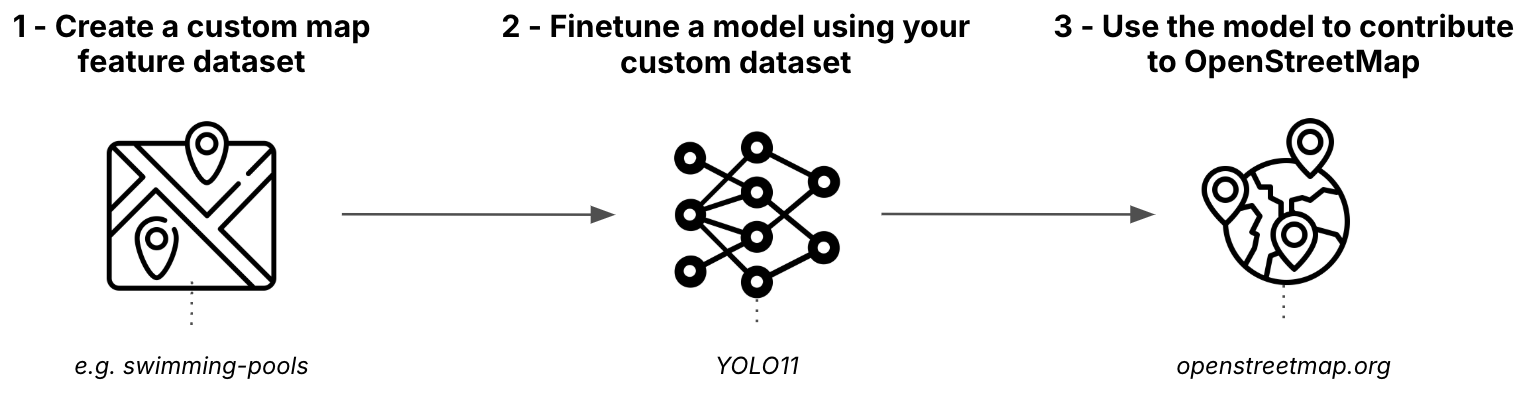
阶段 1:从 OpenStreetMap 创建目标检测数据集
第一阶段包括从 OpenStreetMap 获取数据,将其与卫星图像结合,并将其转换为适合训练的格式。
您可以在 创建数据集 Colab 中自行运行。
为了获取 OpenStreetMap 数据,我们使用
- Nominatim API 为用户提供选择感兴趣区域的灵活方式。在我们的游泳池示例中,我们使用 加利西亚 进行训练,并使用 维亚纳堡 进行验证。
- Overpass API,通过在所选感兴趣区域内使用特定的标签下载所有相关多边形。在我们的游泳池示例中,我们使用 leisure=swimming_pool,并舍弃同时标记有 location=indoor 的多边形。
所有多边形下载完成后,您可以选择一个缩放级别。我们使用此缩放级别首先识别所有包含多边形的图块,然后使用Mapbox的静态图块API下载它们。
经纬度坐标中的多边形被转换为相对于每个图块的像素坐标中的边界框,然后以Ultralytics YOLO 格式保存。
最后,数据集被上传到 Hugging Face Hub。您可以查看我们的示例 mozilla-ai/osm-swimming-pools。
阶段 2 - 微调目标检测模型
一旦数据集以正确的格式上传,微调 YOLOv11(或 Ultralytics 支持的任何其他模型)就相当容易了。
您可以在 微调模型 Colab 中自行运行,并查看所有可用超参数。
模型训练完成后,也会上传到 Hugging Face Hub。您可以查看我们的示例 mozilla-ai/swimming-pool-detector。
阶段 3 - 为 OpenStreetMap 做出贡献
一旦您拥有一个微调过的目标检测模型,您就可以使用它在多个图块上运行推理。
您可以在 运行推理 Colab 中自行运行推理。
我们还提供了一个托管演示,您可以在其中尝试我们的游泳池检测器示例:HuggingFace 演示。
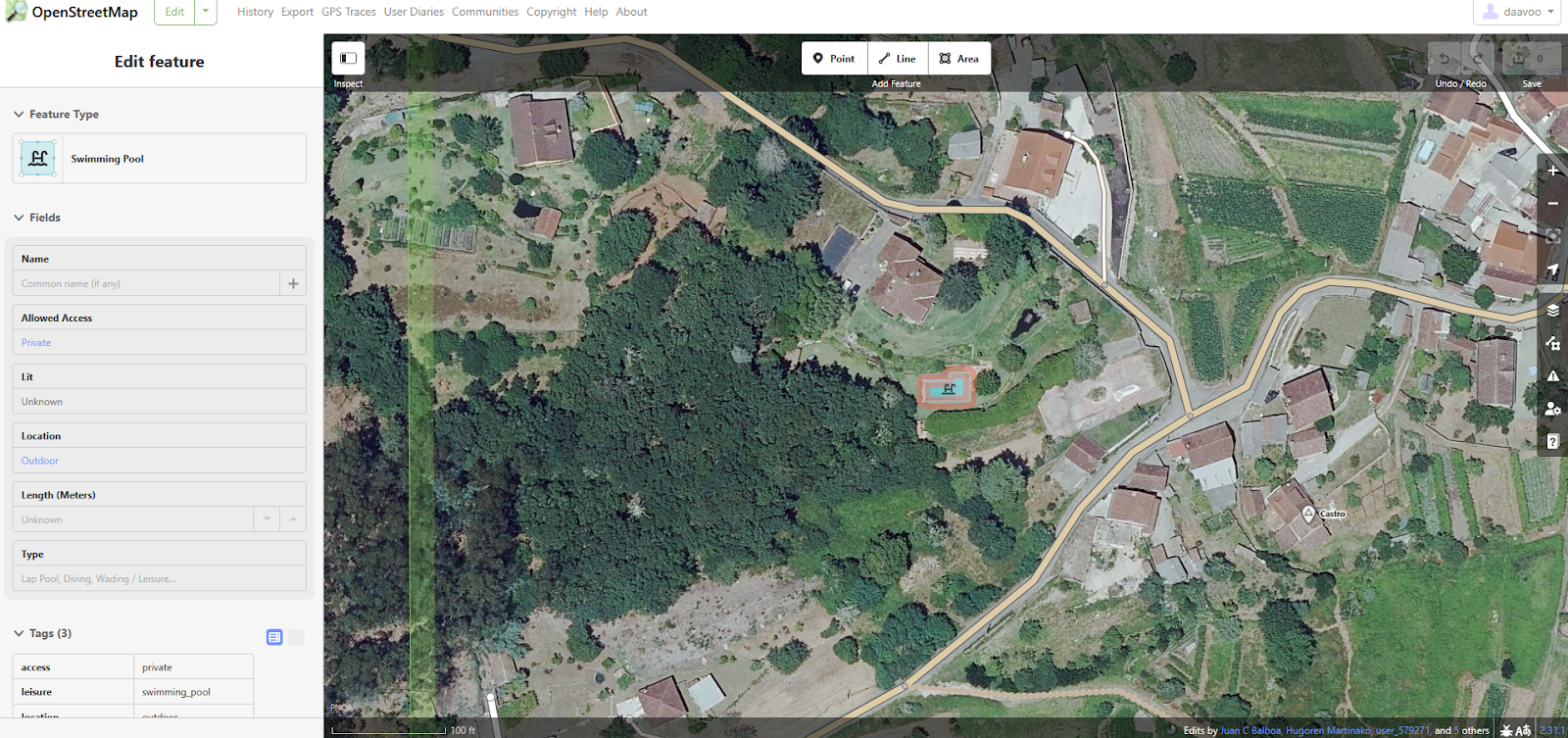
推理需要一些人工交互。首先,您需要选择地图上的一个兴趣点
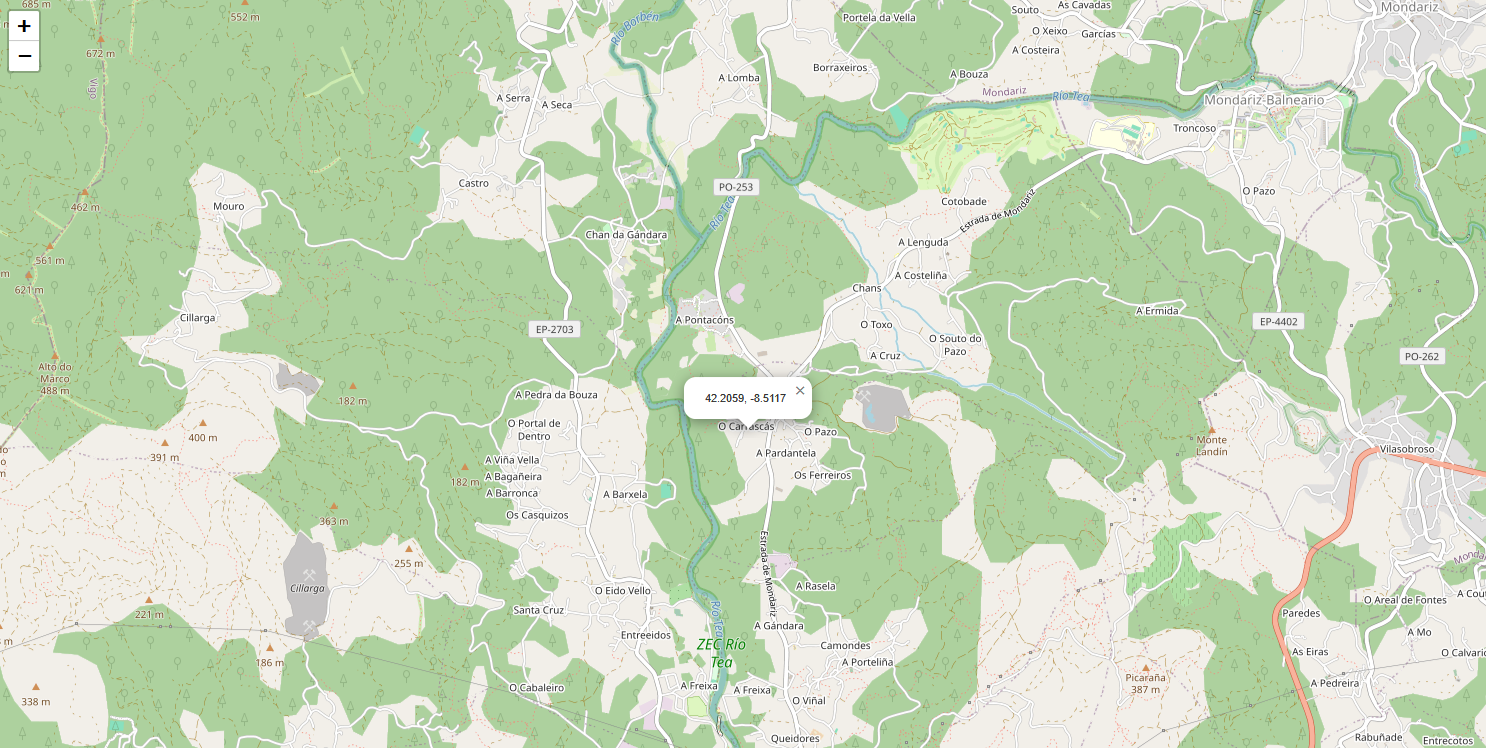
选择一个点后,将根据 margin 参数计算其周围的边界框。
所有现有的兴趣元素都从 OpenStreetMap 下载,所有图块都从 Mapbox 下载并合并以创建堆叠图像。

堆叠图像被分成重叠的图块。对于每个图块,我们运行目标检测模型 (YOLOv11)。如果检测到感兴趣的对象(例如游泳池),我们将边界框传递给分割模型 (SAM2) 以获得分割掩码。
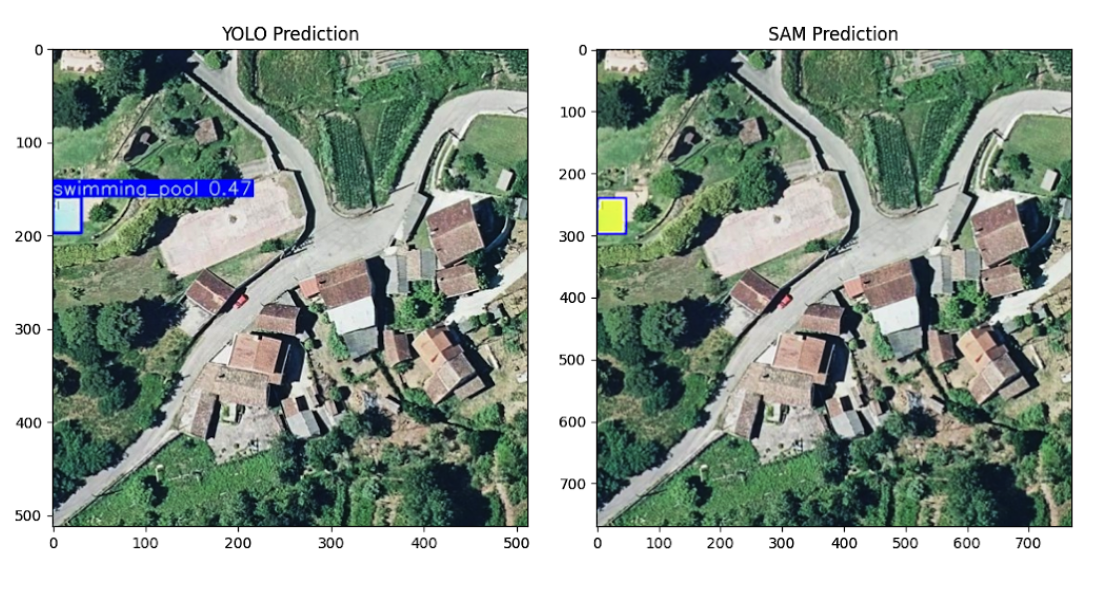
所有预测的多边形都将与从 OpenStreetMap 下载的现有多边形进行检查,以避免重复。所有被识别为 新 的多边形将逐一显示,以供人工验证和筛选。
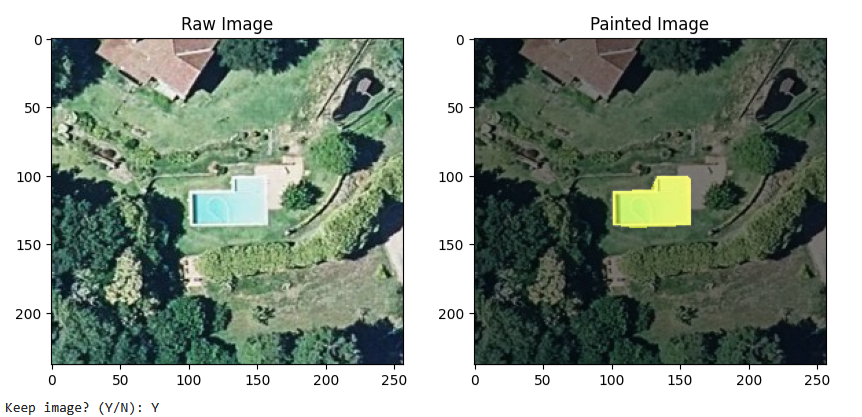
您选择保留的那些将以单个变更集上传到 OpenStreetMap。
结语
OpenStreetMap 是一个强大的开放协作范例,旨在创建丰富、由社区驱动的世界地图。
OpenStreetMap AI 助手蓝图表明,通过正确的方法,人工智能可以增强人类的贡献,同时将人工验证作为核心。在完全手动操作下,绘制 2-3 个游泳池大约需要 1 分钟,而使用蓝图,即使没有优化用户体验,我也可以在相同的时间内绘制大约 10-15 个(大约增加 5 倍)。
它还强调了 OpenStreetMap 等项目高质量数据的价值,这些数据可以轻松训练 YOLOv11 等模型来执行目标检测——这证明了您不应该总是将 LLM 扔到问题上。
我们非常希望您能尝试 OpenStreetMap AI 助手蓝图,并尝试训练一个针对不同地图要素的模型。如果您感兴趣,欢迎为仓库贡献力量,帮助改进它,或者分叉它以进一步扩展!
要查找我们发布的其他蓝图,请查看 蓝图中心。