MTEB:大规模文本嵌入基准







MTEB 是一个用于衡量文本嵌入模型在各种嵌入任务上性能的大规模基准。
🥇 排行榜 全面展示了在各种任务中最优秀的文本嵌入模型。
📝 论文 介绍了 MTEB 中任务和数据集的背景,并分析了排行榜的结果!
💻 Github 仓库 包含了用于基准测试和将任何您选择的模型提交到排行榜的代码。
为何需要文本嵌入?
文本嵌入是文本的向量表示,它编码了语义信息。由于机器需要数值输入来进行计算,文本嵌入是许多下游 NLP 应用的关键组成部分。例如,谷歌使用文本嵌入来驱动其搜索引擎。文本嵌入还可用于通过聚类在大量文本中发现模式,或作为文本分类模型的输入,例如在我们最近的 SetFit 工作中。然而,文本嵌入的质量高度依赖于所使用的嵌入模型。MTEB 旨在帮助您为各种任务找到最优秀的嵌入模型!
MTEB
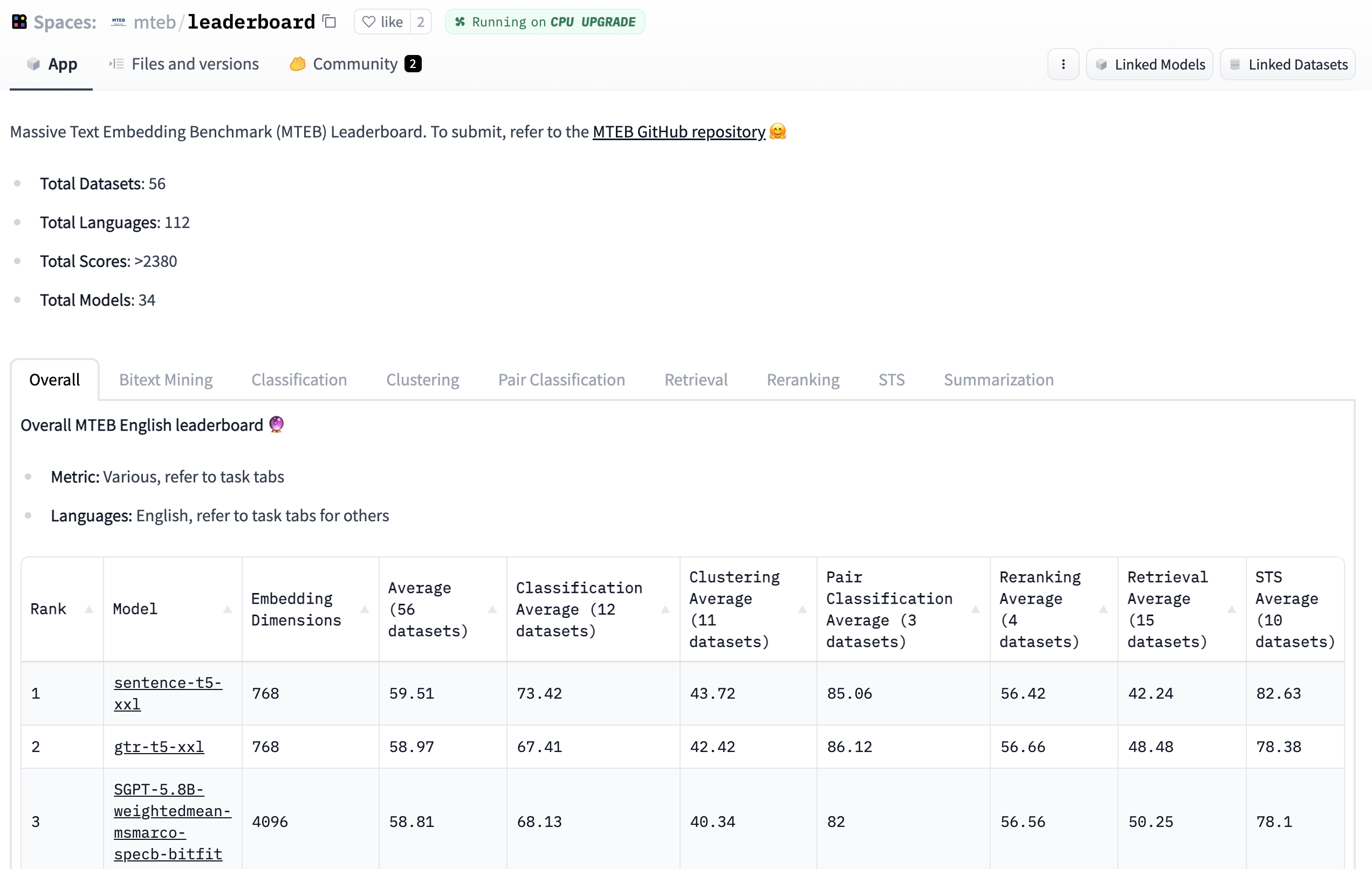
🐋 大规模: MTEB 包含 8 个任务的 56 个数据集,目前在排行榜上总结了超过 2000 个结果。
🌎 多语言: MTEB 包含多达 112 种不同语言!我们已经在双语文本挖掘、分类和 STS 任务上对几个多语言模型进行了基准测试。
🦚 可扩展: 无论是新任务、数据集、指标还是排行榜新增内容,任何贡献都非常受欢迎。请查看 GitHub 仓库以提交到排行榜或解决开放问题。我们希望您能加入我们,一起寻找最佳的文本嵌入模型!
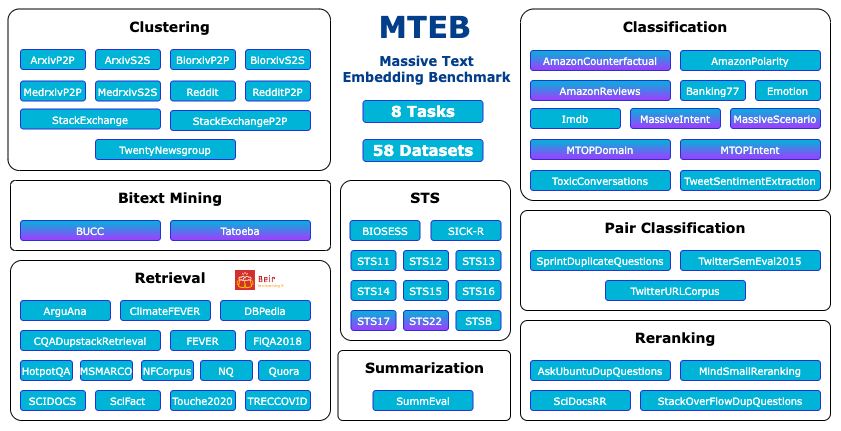
MTEB 中任务和数据集的概览。多语言数据集以紫色阴影标记。
模型
对于 MTEB 的初始基准测试,我们专注于声称达到最新技术水平的模型以及 Hub 上的热门模型。这导致了 Transformer 模型的大量出现。🤖
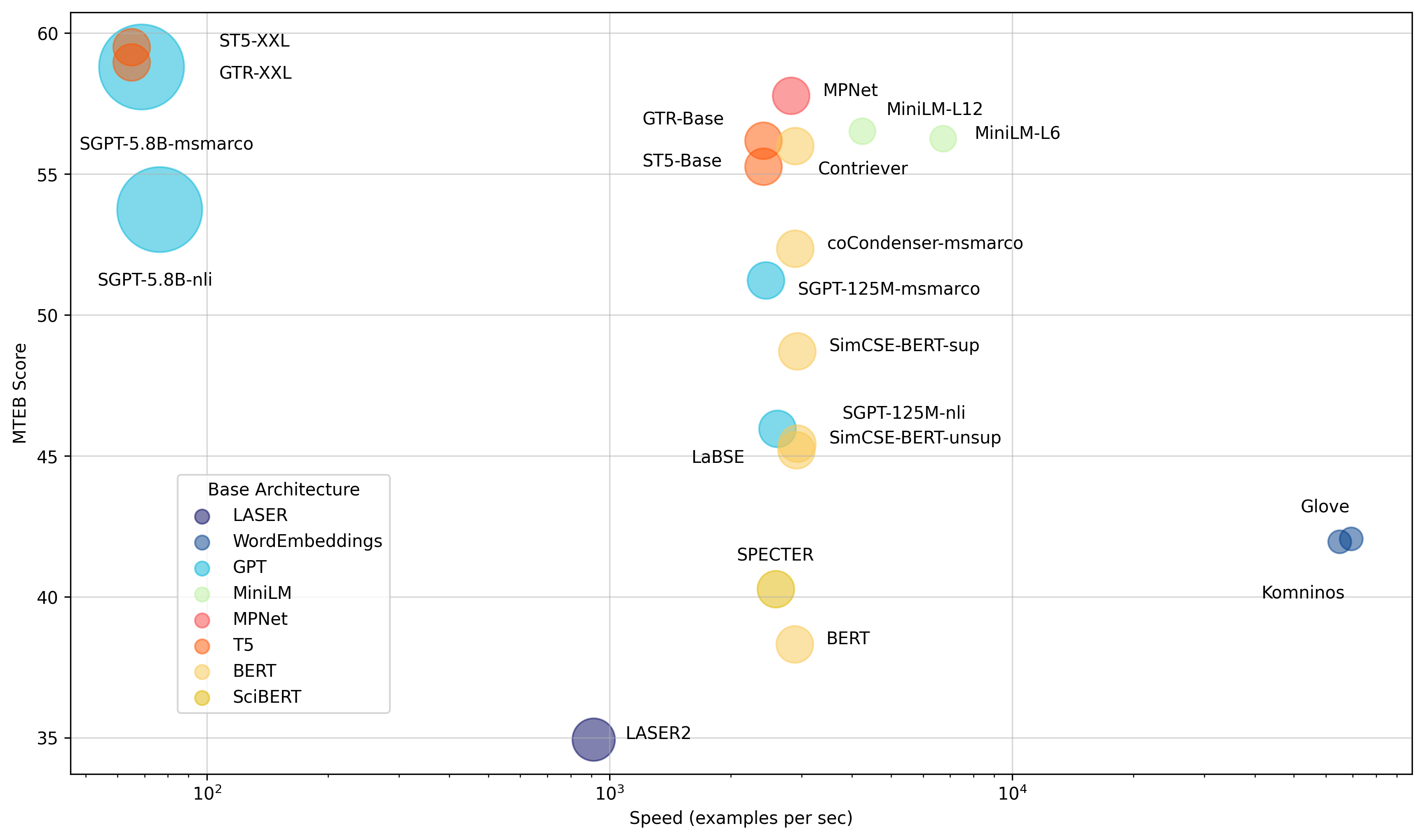
模型按平均英语 MTEB 分数 (y) vs 速度 (x) vs 嵌入大小 (圆圈大小) 进行比较。
我们将模型分为以下三个属性,以简化为您任务找到最佳模型的过程
🏎 极速 像 Glove 这样的模型速度很快,但由于缺乏上下文感知能力,平均 MTEB 分数较低。
⚖️ 速度与性能 稍慢但性能显著更强的 all-mpnet-base-v2 或 all-MiniLM-L6-v2 在速度和性能之间提供了良好的平衡。
💪 极致性能 数十亿参数的模型,如 ST5-XXL、GTR-XXL 或 SGPT-5.8B-msmarco 在 MTEB 上占据主导地位。它们也倾向于产生更大的嵌入,例如 SGPT-5.8B-msmarco 产生 4096 维的嵌入,需要更多存储空间!
模型性能因任务和数据集而异,因此我们建议在决定使用哪个模型之前,查看排行榜的各个选项卡!
为你的模型进行基准测试
使用 MTEB 库,您可以对任何生成嵌入的模型进行基准测试,并将其结果添加到公共排行榜。让我们来看一个快速的例子!
首先,安装库
pip install mteb
接下来,在一个数据集上对模型进行基准测试,例如在 Banking77 上测试 komninos 词嵌入。
from mteb import MTEB
from sentence_transformers import SentenceTransformer
model_name = "average_word_embeddings_komninos"
model = SentenceTransformer(model_name)
evaluation = MTEB(tasks=["Banking77Classification"])
results = evaluation.run(model, output_folder=f"results/{model_name}")
这应该会生成一个 results/average_word_embeddings_komninos/Banking77Classification.json 文件!
现在,您可以通过将其添加到 Hub 上任何模型的 README.md 文件的元数据中,将结果提交到排行榜。
运行我们的自动脚本来生成元数据
python mteb_meta.py results/average_word_embeddings_komninos
该脚本将生成一个 mteb_metadata.md 文件,内容如下:```sh
tags: - mteb model-index: - name: average_word_embeddings_komninos results: - task: type: Classification dataset: type: mteb/banking77 name: MTEB Banking77Classification config: default split: test revision: 0fd18e25b25c072e09e0d92ab615fda904d66300 metrics: - type: accuracy value: 66.76623376623377 - type: f1 value: 66.59096432882667
Now add the metadata to the top of a `README.md` of any model on the Hub, like this [SGPT-5.8B-msmarco](https://huggingface.co/Muennighoff/SGPT-5.8B-weightedmean-msmarco-specb-bitfit/blob/main/README.md) model, and it will show up on the [leaderboard](https://huggingface.co/spaces/mteb/leaderboard) after refreshing!
## Next steps
Go out there and benchmark any model you like! Let us know if you have questions or feedback by opening an issue on our [GitHub repo](https://github.com/embeddings-benchmark/mteb) or the [leaderboard community tab](https://huggingface.co/spaces/mteb/leaderboard/discussions) 🤗
Happy embedding!
## Credits
Huge thanks to the following who contributed to the article or to the MTEB codebase (listed in alphabetical order): Steven Liu, Loïc Magne, Nils Reimers and Nouamane Tazi.







