Nemotron-Personas:利用首个与真实世界分布对齐的合成人物数据集改进人工智能训练
社区文章 发布于2025年6月10日









合成人物,植根现实
我们很高兴发布 Nemotron-Personas,这是第一个与真实世界人口统计、地理和个性特征对齐的合成人物开放数据集。
该数据集使用 Gretel Data Designer(现已并入 NVIDIA,即将集成到 NeMo 中)创建,并借鉴了美国人口普查数据以及关于姓名和个性特征的学术研究。其结果是:一个可扩展、隐私安全且符合法规的用户行为建模基础,可用于人工智能系统。
人物不仅仅是虚构的角色——它们是真实世界多样性的压缩表示,旨在引导大型语言模型(LLM)产生更准确、更具包容性且更符合行为实际的输出。
人物驱动的训练最初由腾讯的 Scaling Synthetic Data with 1B Personas 推广,并被艾伦人工智能研究所的 Tülu 3 模型采用,正成为 LLM 和代理系统开发与评估的最佳实践——尤其是在需要安全、代表性训练数据的受监管行业中。
数据集中有什么?
- 总共60万个合成人物
- 10万条记录,包含22个字段:6个人物字段和16个上下文字段,允许用户专注于特定的人物子集
- 以美国人口普查人口统计和地理数据以及人格心理学研究为基础
- 涵盖560多种真实职业类别
- 包含丰富的叙述性字段,如
职业目标和抱负、技能和专长、爱好和兴趣(例如,专业、艺术、体育、烹饪) - 根据 CC BY 4.0 许可,可用于全部商业和非商业用途
所有数据均使用复合人工智能系统合成生成
- 概率图模型(PGM)以人口统计、地理、姓名和人格特质统计数据为基础;
- 开放权重大型语言模型(例如,
mistralai/Mistral-Nemo-Instruct-2407、mistralai/Mixtral-8x22B-v0.1)用于生成高保真人物叙述。
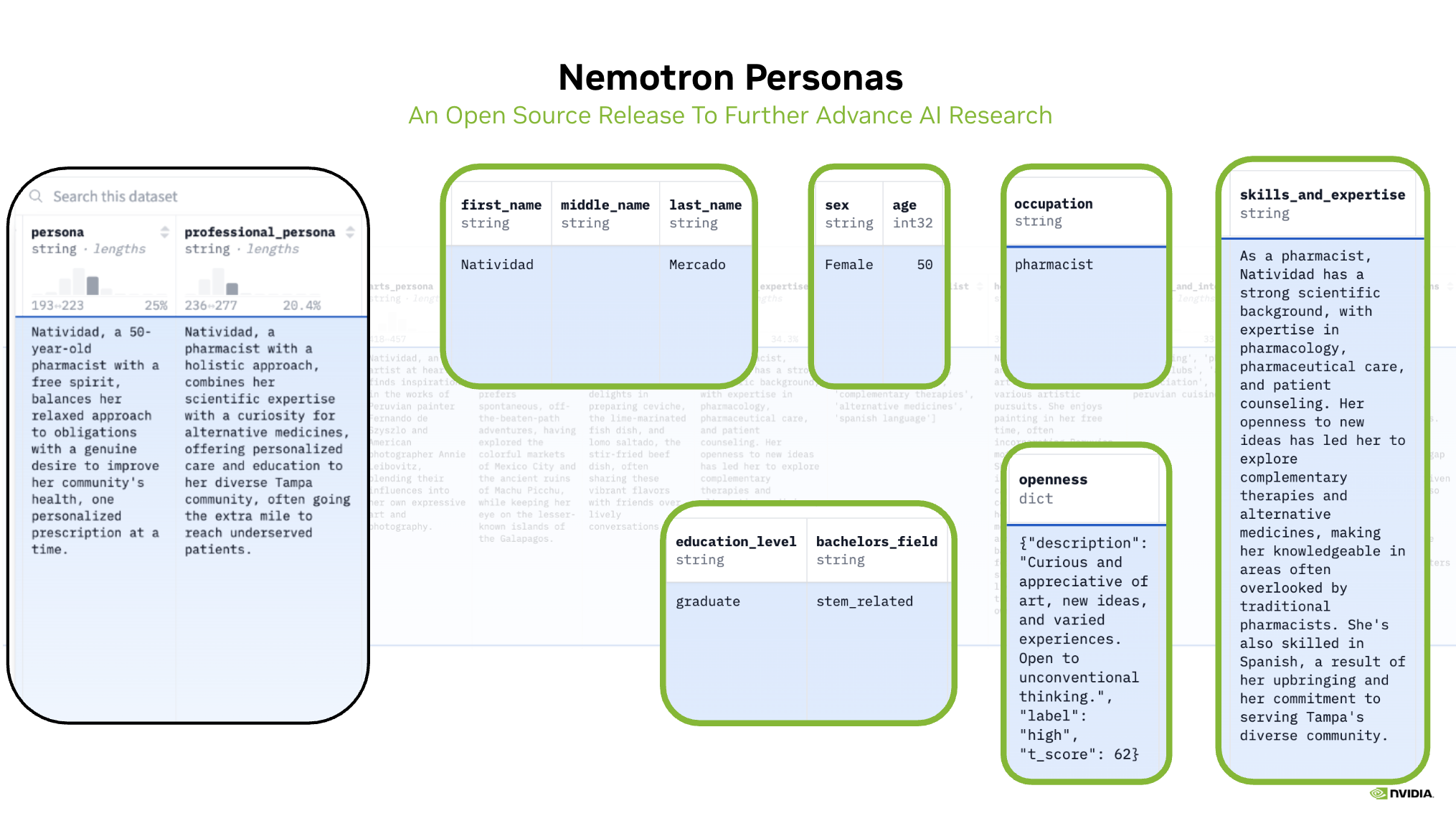 示例1:人物和专业人物(黑色部分)注入了真实世界的人口统计、地理和人格特质属性(绿色部分)。请注意由此产生的丰富交织的数据结构。
示例1:人物和专业人物(黑色部分)注入了真实世界的人口统计、地理和人格特质属性(绿色部分)。请注意由此产生的丰富交织的数据结构。
 示例2:运动和艺术人物(黑色部分)注入了地点、文化背景和爱好/兴趣(绿色部分)。同样,请注意生成人物的复杂性和质量。
示例2:运动和艺术人物(黑色部分)注入了地点、文化背景和爱好/兴趣(绿色部分)。同样,请注意生成人物的复杂性和质量。
专为开放研究和企业人工智能而构建
Nemotron-Personas 专为支持开源实验和生产级人工智能开发而构建
- LLM 训练和指令微调:通过多样化的视角指导模型输出,以提高响应的多样性、指令遵循能力和任务泛化能力。
- 安全性和安全性测试:使用人物对模型进行红队测试,模拟网络钓鱼目标,或测试社会工程防御——无需暴露真实用户数据。
- 受监管行业原型设计:金融、医疗保健和政府领域的企业可以模拟代表性人群,用于模型评估和公平性测试。
- 银行业:审计农村或服务不足申请人的贷款模型。
- 健康科技:评估不同人群的建议质量。
- 公共部门:根据与人口普查对齐的公民人物对资格机器人进行压力测试。
未来之路
此版本基于美国人口数据——但这仅仅是个开始。在未来的项目中,我们希望将此数据集扩展到包含
- 国际分布
- 领域特定变体(例如,
金融人物、医疗保健人物) - 时间维度以模拟用户随时间演变
有了正确的合成数据,世界任你闯荡。
如何使用
只需两行代码即可开始使用
from datasets import load_dataset
ds = load_dataset("nvidia/Nemotron-Personas")




