OpenReasoning-Nemotron:最先进的精炼推理模型系列











今天,我们宣布发布 OpenReasoning-Nemotron:一套从 DeepSeek R1 0528 671B 模型中精炼而来的具有推理能力的大型语言模型 (LLM)。我们的 7B、14B 和 32B 模型在新 DeepSeek R1 0528 精炼出的大规模高质量数据集上进行训练,在数学、科学和代码领域的各种推理基准测试中,就其各自的尺寸而言,均达到了最先进的性能。这些模型将可在 **Hugging Face**(1.5B、7B、14B、32B)上下载,这可能有助于在更强的基线上进行推理强化学习的进一步研究。这些模型可以作为研究提高推理效率的技术的良好起点,例如减少消耗的token数量或将这些模型定制到特定任务。此外,虽然这些模型不是通用聊天助手,但在保持其基准分数不变的情况下,使用或不使用验证奖励的偏好优化研究可能会为这些模型解锁新的应用。
大规模数据蒸馏
这些模型的基础是它们的数据集。我们利用强大的 DeepSeek R1 0528 模型,在数学、编码和科学领域生成了 **500 万个高质量的推理解决方案**。该数据集将在未来几个月内发布,使所有模型能够提高它们在这些领域的推理能力。虽然数据集尚未立即提供,但生成数据集、训练和评估模型的代码可在 NeMo-Skills 获取。
数据蒸馏的有效性
为了让具有不同计算能力的研究人员能够使用,我们发布了基于 Qwen 2.5 架构的四种模型。虽然原始的 DeepSeek R1 671B 模型附带了各种尺寸的蒸馏模型,但新的 DeepSeek R1 0528 671B 模型只发布了 8B 蒸馏模型。考虑到这给推理研究带来的限制,我们开发了四种尺寸的模型以适应研究需求。
在过去一年中,我们发布了 OpenMathReasoning 和 OpenCodeReasoning 数据集,这些数据集使公共模型能够通过推理在各种数学和编码基准测试中获得最先进的分数。这项工作的关键因素是用于蒸馏的 SFT 数据的规模——我们生成并训练了数百万个 R1 蒸馏数据样本。因此,我们发现我们在此领域的数据蒸馏模型远远超过了发布的原始蒸馏 R1 模型。
所有步骤均使用 NeMo-Skills 创建模型,包括数据生成、数据集预处理和后处理、模型转换、训练以及所有这些基准测试的评估。
基准测试结果:树立新标准
我们的模型在一系列具有挑战性的推理基准测试中表现出色。7B、14B 和 32B 模型始终为其尺寸类别创下新的最先进记录。
推理基准测试分数
此图和下表中的所有评估结果均为 pass@1。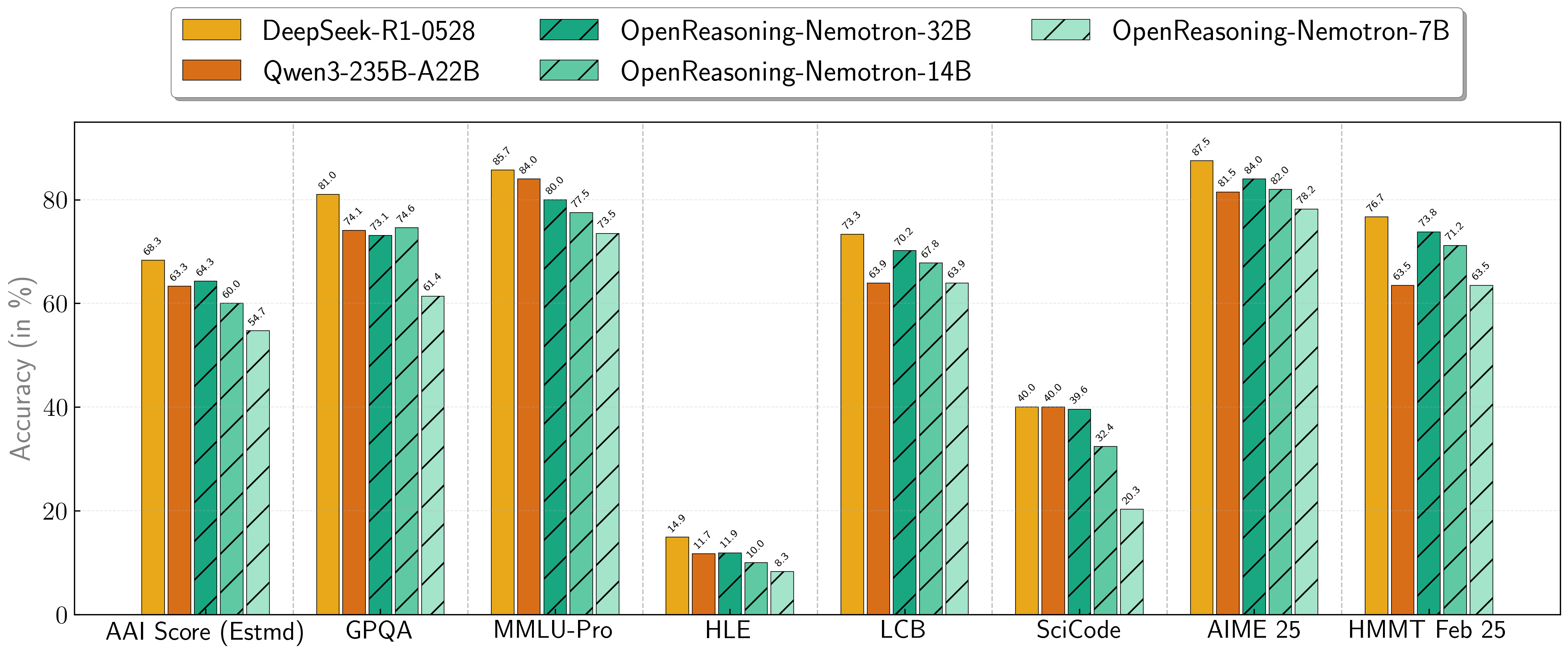
| 模型 | 人工智能分析指数* | GPQA | MMLU-PRO | HLE | LiveCodeBench* | SciCode | AIME24 | AIME25 | HMMT FEB 25 |
|---|---|---|---|---|---|---|---|---|---|
| 1.5B | 31.0 | 31.6 | 47.5 | 5.5 | 28.6 | 2.2 | 55.5 | 45.6 | 31.5 |
| 7B | 54.7 | 61.1 | 71.9 | 8.3 | 63.3 | 16.2 | 84.7 | 78.2 | 63.5 |
| 14B | 60.9 | 71.6 | 77.5 | 10.1 | 67.8 | 23.5 | 87.8 | 82.0 | 71.2 |
| 32B | 64.3 | 73.1 | 80.0 | 11.9 | 70.2 | 28.5 | 89.2 | 84.0 | 73.8 |
* 这是我们对人工智能分析指数的估计,并非官方分数。
* LiveCodeBench 版本 6,日期范围 2408-2505。
结合多个代理的工作
OpenReasoning-Nemotron 模型可以通过启动多个并行生成并通过 生成式解决方案选择 (GenSelect) 将它们组合在一起来以“重型”模式使用。为了添加这项“技能”,我们遵循了原始的 GenSelect 训练流程,但我们没有训练选择摘要,而是使用了 DeepSeek R1 0528 671B 的完整推理轨迹。我们只训练模型来选择数学问题的最佳解决方案,但令人惊讶地发现这种能力直接推广到代码问题!通过这种“重型”GenSelect 推理模式,OpenReasoning-Nemotron-32B 模型在数学和编码基准测试中接近甚至有时超过 o3 (高) 分数。
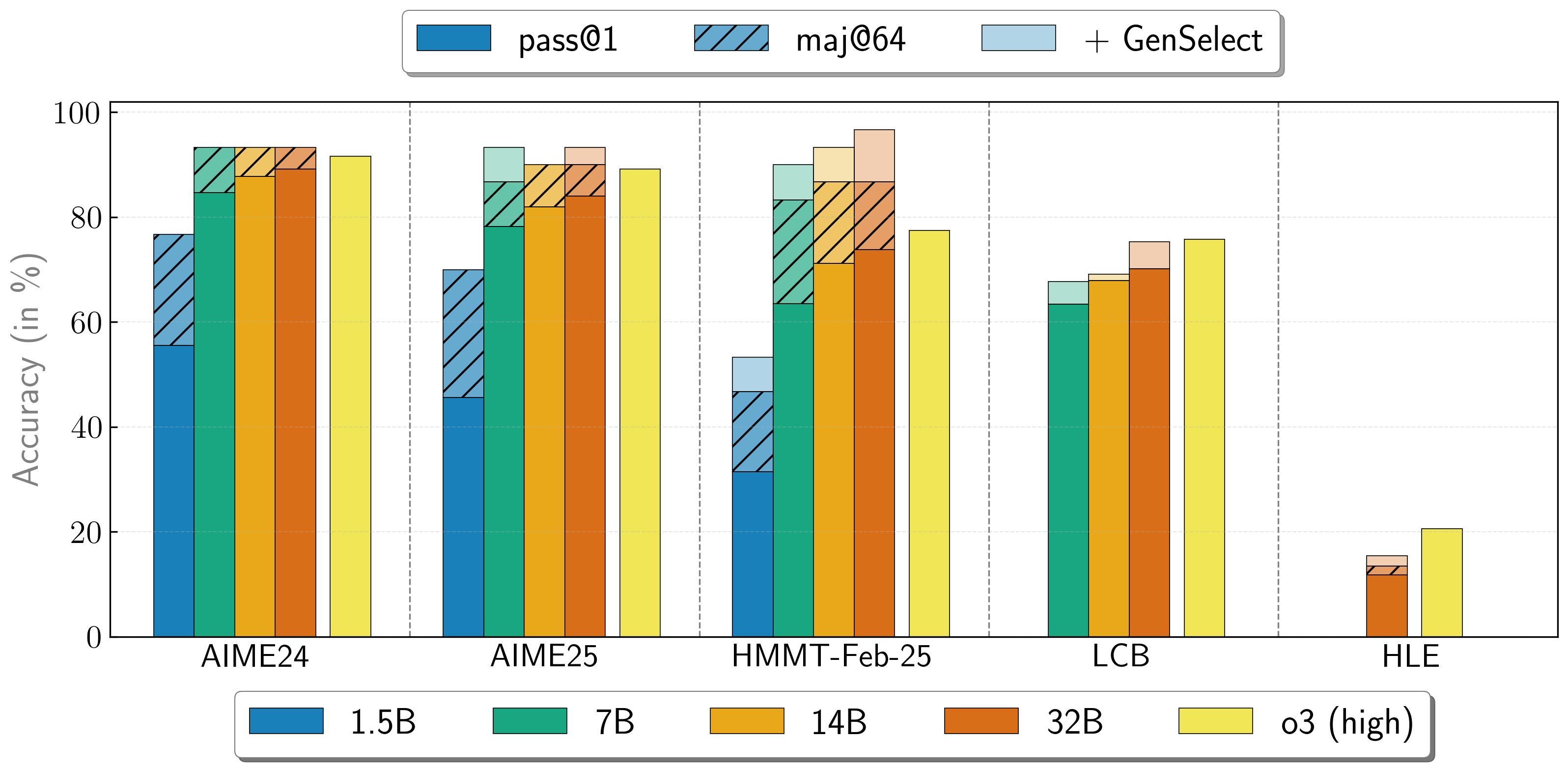
| 模型 | Pass@1 (平均@64) | 多数@64 | GenSelect |
|---|---|---|---|
| 1.5B | |||
| AIME24 | 55.5 | 76.7 | 76.7 |
| AIME25 | 45.6 | 70.0 | 70.0 |
| HMMT Feb 25 | 31.5 | 46.7 | 53.3 |
| 7B | |||
| AIME24 | 84.7 | 93.3 | 93.3 |
| AIME25 | 78.2 | 86.7 | 93.3 |
| HMMT Feb 25 | 63.5 | 83.3 | 90.0 |
| LCB v6 2408-2505 | 63.4 | 不适用 | 67.7 |
| 14B | |||
| AIME24 | 87.8 | 93.3 | 93.3 |
| AIME25 | 82.0 | 90.0 | 90.0 |
| HMMT Feb 25 | 71.2 | 86.7 | 93.3 |
| LCB v6 2408-2505 | 67.9 | 不适用 | 69.1 |
| 32B | |||
| AIME24 | 89.2 | 93.3 | 93.3 |
| AIME25 | 84.0 | 90.0 | 93.3 |
| HMMT Feb 25 | 73.8 | 86.7 | 96.7 |
| LCB v6 2408-2505 | 70.2 | 不适用 | 75.3 |
| HLE | 11.8 | 13.4 | 15.5 |
* 我们对数学应用 GenSelect@64,对科学和编码应用 GenSelect@16。
未来研究的坚实基础
本次发布的一个关键方面是我们的训练方法。这些模型仅使用**监督式微调 (SFT) 蒸馏**进行训练,不应用强化学习 (RL)。这一深思熟虑的选择展示了我们仅通过数据蒸馏可以达到多远的程度,并为研究社区提供了基于推理的强化学习技术的一个很好的起点。近期 AceReasoning-Nemotron 的工作表明,课程强化学习的时间表以及数学和代码强化学习的顺序纳入可以使推理模型的训练更加稳定。因此,我们结合了数学、科学和代码领域的数据,并使用最新的 R1 重新生成了解决方案,为进一步的强化学习研究提供了强大的基线,从接近最先进的分数开始。
您可以在 OpenReasoning-Nemotron 集合中找到这些模型的检查点。








