试验、错误与突破:我们利用强化学习迈向 OVD SOTA 的崎岖之路







TL;DR
本博客全面展示了通过强化学习优化视觉语言模型 (VLM) 以实现目标检测的实验结果,重点关注 Qwen2.5-VL-3B 和 7B 模型。主要发现包括:
奖励工程突破
- 加权和与余弦奖励结合实现了最佳性能(比基线 AP 奖励提高 1.8% mAP)
- 新颖的重复惩罚有助于减少冗余检测,同时保持高精度(77.08%)
模型大小影响
- 7B 模型表现出更强的初始格式依从性(格式分数 0.75 vs 0.4)
- 3B 模型通过提示工程展现出更大的改进潜力
训练数据洞察
- 纯目标检测优于混合方法(比混合训练提高 2.1% mAP)
- 小目标专业训练提高了精度(+16.37%),召回率的权衡最小
本博客文章总结了我们通过对视觉语言模型(VLM)中的目标检测进行强化学习(RL)的广泛实验所获得的关键发现和见解,特别关注 Qwen2.5-VL-3B 和 7B 模型。我们的实验涵盖了训练方法、数据准备策略、奖励函数和提示工程等各个方面。
1. 训练选项概览
1.1 训练数据集
COCO 数据集:包含 80 个类别的标准目标检测数据集
OVDEval 数据集:目标视觉检测评估数据集
https://github.com/om-ai-lab/OVDEval:https://github.com/om-ai-lab/OVDEval
- D³ 数据集:多样化目标检测数据集
https://github.com/shikras/d-cube:https://github.com/shikras/d-cube
1.2 评估数据集
COCO_filtered (COCO_pos_1):标注框少于 10 个的类别
COCO_pos_2:每个类别只有一个边界框的图像
COCO_pos_3:所有类别总框数少于 10 个的图像
REFCOCO:参考表达式理解基准(域内)
REFGTA:参考表达式理解基准(域外)
OVDEval:用于综合目标检测能力的测试集
1.3 强化学习奖励选项
AP50:IoU 阈值为 0.5 时的平均精度
AP:跨多个 IoU 阈值的平均精度
Weighted_sum:位置精度和检测完整性的组合
Cosine reward:促进响应效率
Repetition reward:惩罚输出中的重复模式
1.4 训练方法
监督微调 (SFT):直接从人工标注中学习
强化学习 (RL):从奖励信号中学习
基线模型:Qwen2.5-VL-3B 和 Qwen2.5-VL-7B
1.5 提示词格式
标准提示词:“将思考过程输出在 <think> </think> 标签内,最终答案输出在 <answer> </answer> 标签内。”
增强提示词:“首先在脑中思考推理过程,然后向用户提供答案。推理过程和答案分别包含在 <think> </think> 和 <answer> </answer> 标签内,即:<think> 在此处推理 </think><answer> 在此处回答 </answer>”
系统提示词变体:模型指令的其他配置
2. 评估数据集选项
2.1 COCO 数据集评估模式
COCO_filtered (COCO_pos_1) 数据集
COCO_filtered 数据集是从 COCO 数据集的 instances_val2017.json 文件中创建的。它过滤掉了具有超过 10 个标注框的类别,确保只包含标注框较少的类别。
COCO_pos_2 数据集
COCO_pos_2 数据集专注于每个类别仅包含一个边界框的图像。
COCO_pos_3 数据集
COCO_pos_3 数据集也源自 COCO 数据集的 instances_val2017.json 文件。它确保所有类别的总框数不超过 10 个。
在 COCO 数据集的评估中,我们有 3 种模式:
所有模式:包括 COCO 中的所有 80 个类别
正向模式:仅包括当前图像中存在的类别
每类别 1 个边界框模式:每个类别仅包括一个边界框
2.2 OVD 数据集评估模式
所有模式:结合正向和负向提示词
正向模式:仅包括图像中存在的类别
3. 训练数据集发现
3.1 小目标检测的权衡
当使用 MAP 奖励训练小目标(面积小于图像 0.5%)与常规单框数据时:
| 训练数据 | COCO_filtered (mAP) | 精度 (IoU=0.5) | 召回率 (IoU=0.5) |
|---|---|---|---|
| 仅小目标 | 22.3 | 71.39 | 43.36 |
| 常规单框 | 21.1 | 55.02 | 49.46 |
关键发现
小目标训练提高了精度(+16.37 分)
召回率略有下降(-6.1 分)
除非小目标检测是主要目标,否则请考虑使用平衡数据集
3.2 单区域标签的影响
单区域标签和目标检测 (OD) 的描述
单区域标签:
纯单区域方法采用不同的方法。它不检测目标及其边界,而是依赖给定的坐标,并要求模型从预定义选项列表中对位于给定坐标内的目标进行分类。本质上,这类似于多项选择题,模型被赋予图像中的一个位置(一个坐标框),并且必须从一组可能的选项中选择正确的对象类别。此方法强调基于特定坐标进行分类,并将区域与适当的对象类别进行匹配。
**OD (目标检测)**:
OD 方法侧重于检测图像中目标的位置和边界。模型通过绘制边界框来识别目标及其位置,性能使用 mAP 和 IoU 等指标进行衡量。OD 不仅对目标进行分类,还确定其在图像中的位置。
不同训练方法的比较
| 训练方法 | COCO_filtered (mAP) | 精度 (IoU=0.5) | 召回率 (IoU=0.5) |
|---|---|---|---|
| 纯单区域 | 18.4 | 66.01 | 34.57 |
| 混合 OD + 单区域 | 21.7 | 63.98 | 46.75 |
| 纯 OD (单类别) | 23.8 | 65.58 | 48.92 |
关键发现
纯目标检测 (OD) 优于混合方法
混合数据集优于纯单区域训练
包含单区域标签数据可能会阻碍目标检测性能
4. 强化学习奖励函数优化
4.1 不同奖励函数的比较
| 训练数据 | 奖励方法 | COCO_pos_3 (mAP) | 精度 (IoU=0.5) | 召回率 (IoU=0.5) |
|---|---|---|---|---|
| OVDEval | AP50 | 27.1 | 70.17 | 58.05 |
| OVDEval | AP | 27.4 | 71.11 | 57.86 |
| OVDEval | weighted_sum | 27.5 | 71.32 | 57.72 |
| OVDEval | weighted_sum,余弦奖励 | 29.3 | 76.95 | 59.11 |
| OVDEval | weighted_sum,余弦奖励,重复奖励 | 28.8 | 77.08 | 57.98 |
- 边界框的 AP 或 AP50
在我们的实验中,我们使用 ovdeval 作为训练数据集,并使用 COCO_pos_3 进行验证。平均精度 (AP) 分数从 27.1 提高到 27.4。这个单一的比较突出表明 AP 始终优于 AP50。其原因在于,AP50 的二值阈值提供了有限的反馈,而 AP 则提供了更精细、连续的反馈。这种连续反馈机制使模型能够改进其边界框预测,从而提高精度和整体模型性能。
- 奖励规则设计
在我们的探索过程中,我们考虑为目标检测任务实现自定义规则。重点主要在于两个方面:预测框与真实框之间的空间重叠,以及整体检测完整性。空间重叠通常使用交并比 (IoU) 来衡量,IoU 是两个框重叠区域与联合区域面积之比。较高的 IoU 表示预测框在空间位置上更接近真实框。在检测完整性方面,重要的是要考虑漏检和误报。漏检指的是未检测到的真实目标,而误报指的是错误检测到的非目标区域。完整性通过计算漏检率和误报率进行评估,完整性分数计算如下:
$completeness = 1 - \frac{\text{miss rate} + \text{false alarm rate}}{2}$
这反映了检测的整体彻底性。为了形成一个综合分数,该函数通过加权平均结合了位置精度和检测完整性。在匹配预测框和真实框时,采用贪婪匹配策略,即迭代选择 IoU 最高的框对,直到无法再进行满意的匹配。值得注意的是,如果预测标签与真实标签不匹配,即使 IoU 本身很高,IoU 也将设置为 0,这会影响最终分数。这种多维奖励方法,我们将其命名为 weighted_sum,提供了一个综合指标来反映目标检测模型的性能。我们将此奖励指标应用于训练,并将其与 AP 奖励进行比较。结果表明,weighted_sum 奖励可以将 mAP 分数进一步提高到 27.5。
- 余弦奖励与重复奖励
受论文《揭秘 LLM 中长链式思维推理》(https://arxiv.org/abs/2502.03373)的启发,我们在实验中实现了余弦奖励和重复奖励。余弦奖励通过在已获得正确答案时促进更短的响应来鼓励更高效的推理过程。相反,对于不正确的答案,余弦奖励激励进一步探索直到找到正确答案。这种方法有助于将响应长度收敛到合理的大小,同时避免不必要的推理。
此外,我们还实现了重复奖励以惩罚 N-gram 模式,因为我们观察到在生成响应时存在重复实例。鉴于我们专注于对象视觉检测(OVD)任务,单个图像中很可能存在多个对象。因此,我们解析 OVD 输出 JSON 并根据其中包含的元素计算 N-gram。
我们发现,余弦奖励和重复奖励的实施可以在单次训练会话中收敛到相同的推理过程。然而,不同的训练尝试可能导致不同推理模式的收敛。下面,我们介绍在实验中观察到的几个有趣的推理模式。
problem:
Please carefully observe the image and detect the following targets: plastic chair.Output each detected targets' bbox coordinates in JSON format. The format of the bbox coordinates is: ```json
[{"bbox_2d": [x1, y1, x2, y2], "label": "target name"}, {"bbox_2d": [x1, y1, x2, y2], "label": "target name"}]
```. If there are no such targets in the image, simply respond with None.
Content: <think>
4
</think>
<answer>
```json
[
{"bbox_2d": [38, 95, 113, 164], "label": "plastic chair"},
{"bbox_2d": [130, 90, 177, 150], "label": "plastic chair"},
{"bbox_2d": [174, 89, 222, 140], "label": "plastic chair"},
{"bbox_2d": [222, 86, 258, 135], "label": "plastic chair"}
]
problem:
Please carefully observe the image and detect the following targets: iron door.Output each detected targets' bbox coordinates in JSON format. The format of the bbox coordinates is: ```json
[{"bbox_2d": [x1, y1, x2, y2], "label": "target name"}, {"bbox_2d": [x1, y1, x2, y2], "label": "target name"}]
```. If there are no such targets in the image, simply respond with None.
Content: <think>
image.
</think>
<answer>
```json
[
{"bbox_2d": [97, 91, 406, 718], "label": "iron door"}
]
当我们引入余弦奖励时,我们注意到性能显著提高,mAP 提高到 29.3。伴随而来的是精度的大幅提升,达到 76.95,召回率也略有改善,达到 59.11。此外,当我们将重复奖励添加到加权和与余弦奖励的组合中时,mAP 略微下降到 28.8。虽然精度保持在 77.08 的高位,但召回率下降到 57.98。这表明,虽然重复奖励可能有助于减少预测中的冗余,但也可能导致模型过于保守,从而可能遗漏一些相关实例。总体结果表明,余弦奖励的加入显著提升了模型的性能,尤其是在精度方面。
5. 提示词工程发现
我们对 3B 模型在 OVDEval 数据集上进行了一系列实验,并获得了以下发现。
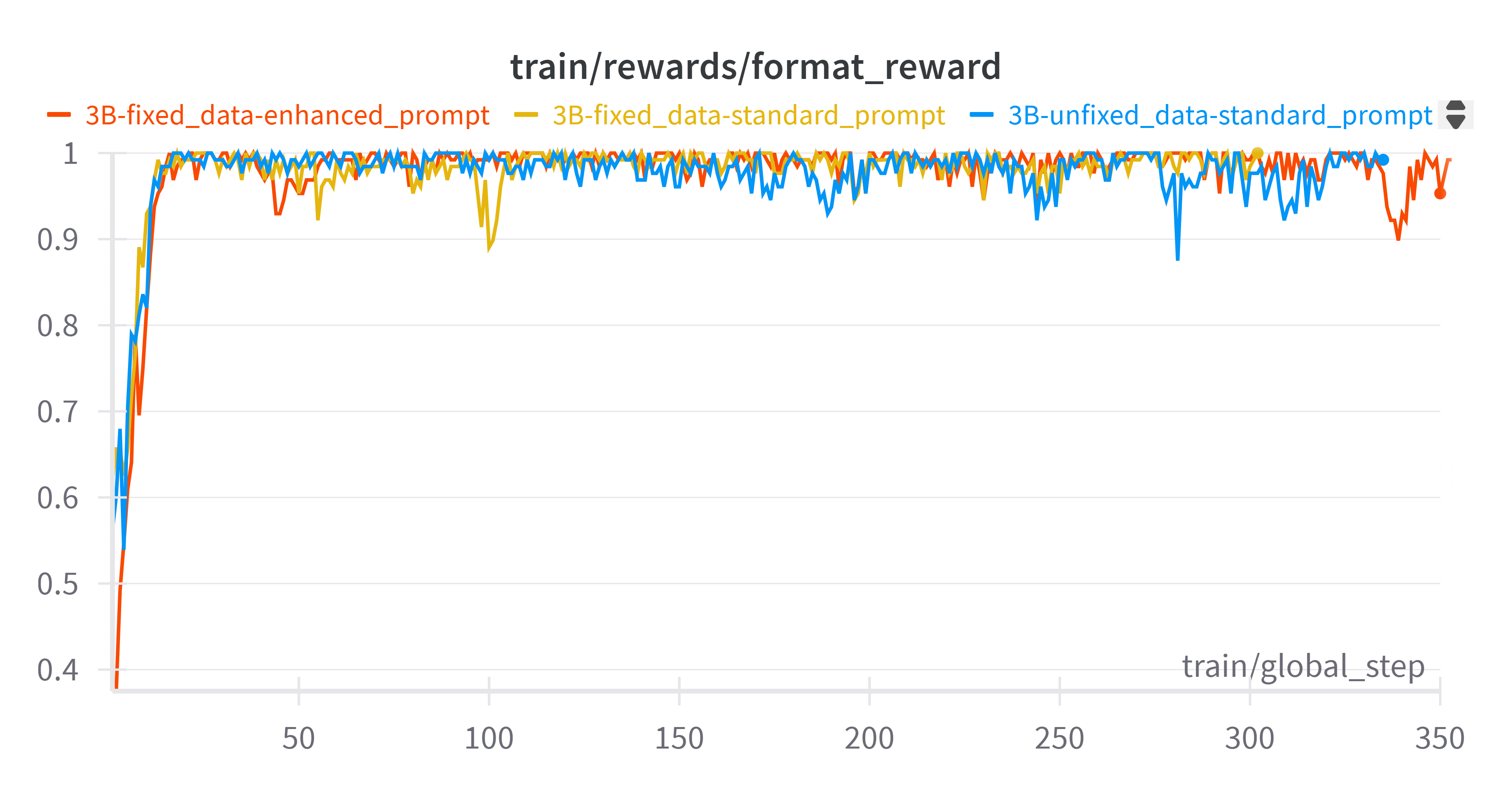
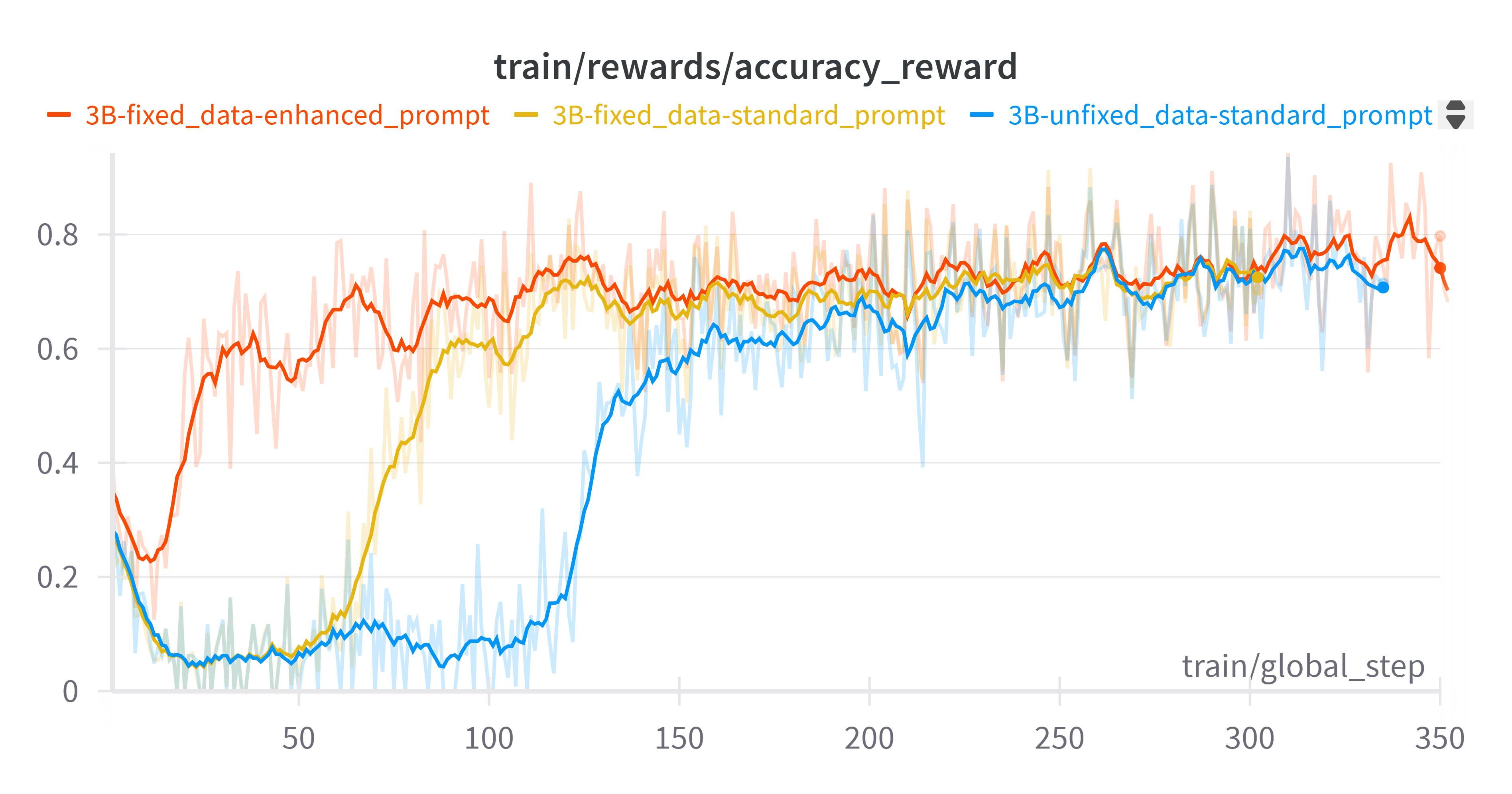
5.1 轻微语法问题的影响
- 即使是小的语法问题(例如缺少空格)也会显著影响 3B 模型的训练收敛。
在 3B 模型上使用 OVDEval 数据(使用有语法问题的数据和标准提示词)开始训练时。我们观察到精度奖励在格式奖励完成收敛(约 15 步)后没有上升,直到约 125 步才开始上升。检查训练参数配置后,我们发现数据集存在缺少空格的问题,我们修复了这个问题并再次尝试训练。结果发现模型确实加快了收敛速度,在大约 65 步时开始上升。然而,在使训练的精度奖励开始更快上升的同时,最终收敛到相同的值(约 0.7)。
问题数据示例
::: 缺少空格的数据
\n 请仔细观察图像并检测以下目标:person sit on motorcycle; motorcycle is sat on by person.Output each detected targets' bbox coordinates in JSON format. The format of the bbox coordinates is: ```json\n[{"bbox_2d": [x1, y1, x2, y2], "label": "target name"}, {"bbox_2d": [x1, y1, x2, y2], "label": "target name"}]\n```. 如果图像中没有此类目标,则简单回复 None。 ::: ::: 已修复的数据
\n 请仔细观察图像并检测以下目标:person sit on motorcycle; motorcycle is sat on by person. Output each detected targets' bbox coordinates in JSON format. The format of the bbox coordinates is: ```json\n[{"bbox_2d": [x1, y1, x2, y2], "label": "target name"}, {"bbox_2d": [x1, y1, x2, y2], "label": "target name"}]\n```. 如果图像中没有此类目标,则简单回复 None。 ::
5.2 提示词结构优化
- 提示词修改可以提高 3B 模型的训练收敛效率。
尽管数据修正后,精度奖励可以更快地开始收敛(约 65 步),但仍然与格式奖励的趋势不符(约 15 步)。我们随后尝试修改提示词,而不改变其他训练设置,最终训练的精度奖励可以在格式奖励完成收敛后立即上升(约 15 步)。尽管在训练过程中收敛速度再次加快,但提示词的修改并未提高最终的精度奖励值(约 0.7)。
::: 增强提示词
“首先在脑中思考推理过程,然后向用户提供答案。推理过程和答案分别包含在 <think> </think> 和 <answer> </answer> 标签内,即:<think> 在此处推理 </think><answer> 在此处回答 </answer>” ::
5.3 7B 和 3B 模型对提示词的不同鲁棒性
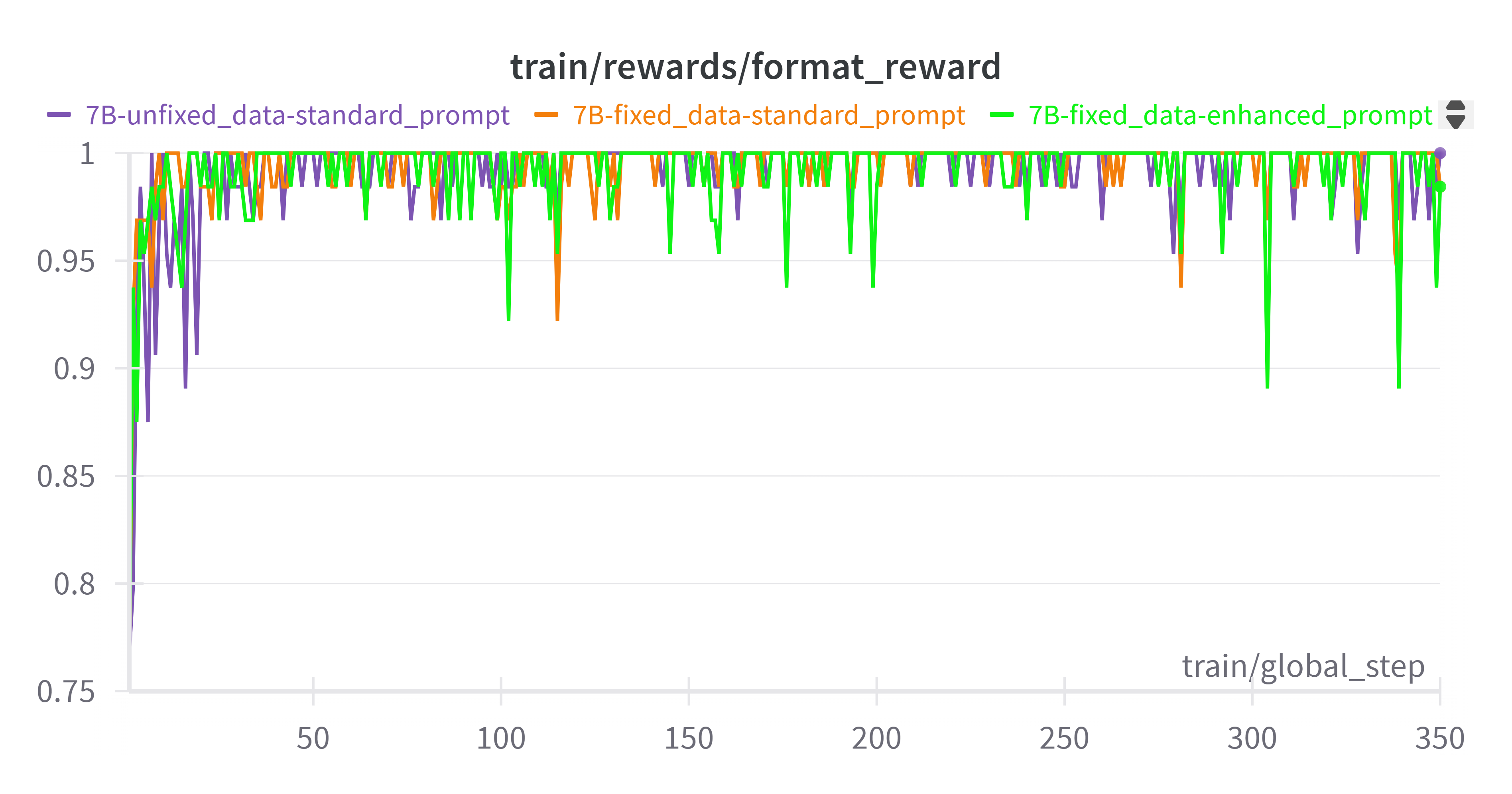
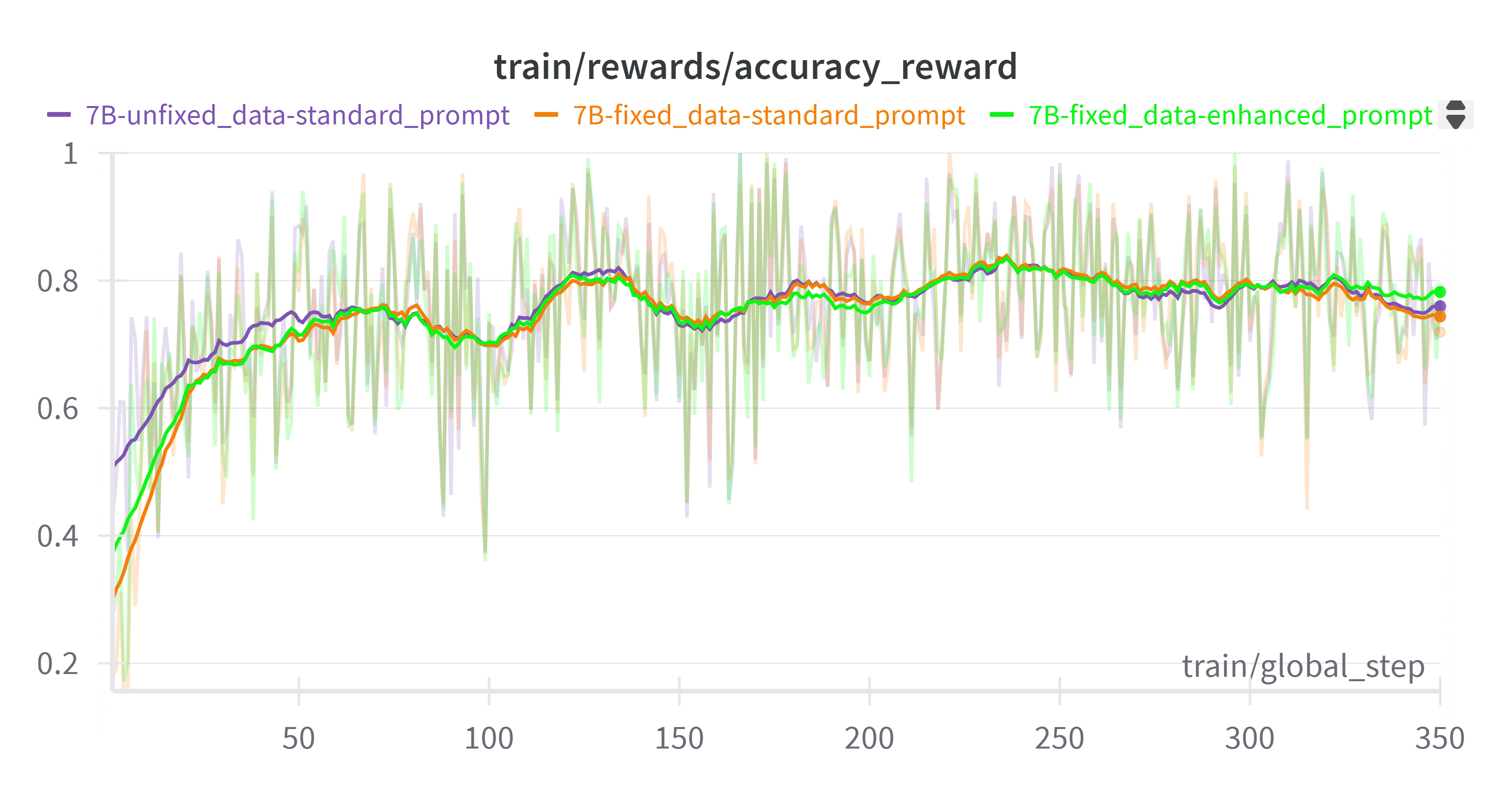
- 7B 模型对提示词更具鲁棒性,带来更强的初始格式依从性
我们对 7B 模型进行了与 3B 模型相同的实验(固定数据和使用增强提示词),结果表明训练奖励几乎相同。精度奖励从一开始就随着格式奖励一起上升。这反映了一个事实:与 3B 模型(其训练性能可能会因提示词的微小调整而显著变化)不同,7B 模型由于其更强的泛化能力和更高的参数容量,对提示词修改的敏感性相对较低。这也体现在 7B 模型具有更强的初始格式依从性(初始格式分数为 0.75)方面,而 3B 模型为 0.4。
5.3 系统提示词变体
- 对于指令模型,系统提示词对格式学习的影响微乎其微
我们额外尝试了使用增强提示词作为内置系统提示词进行训练,发现格式奖励几乎没有增加,这验证了“MM-Eureka: Exploring Visual Aha Moment with Rule-based Large-scale Reinforcement Learning”(https://arxiv.org/abs/2503.07365)中提出的观点:对于指令模型,应该保留模型的内置系统提示词,并在用户提示词中包含格式相关信息。相反,对于基础模型,我们应该在系统提示词中提供格式信息。
| 模型 | COCO_pos_1 (mAP) | 精度 (IoU=0.5) | 召回率 (IoU=0.5) |
|---|---|---|---|
| 3B 基础版 (Qwen2.5-VL-3B-Instruct) | 23.6 | 70.14 | 47.69 |
| 3B (固定数据和增强提示词) | 24.5 | 68.2 | 50.27 |
| 3B 基础版 (Qwen2.5-VL-3B-Instruct) | 23.6 | 70.14 | 47.69 |
| 3B (固定数据和增强提示词) | 24.5 | 68.2 | 50.27 |
| 7B 基础版 (Qwen2.5-VL-7B-Instruct) | 24.6 | 71.53 | 50.56 |
| 7B (固定数据和增强提示词) | 24.6 | 68.1 | 55.15 |
我们最终在 COCO pos1 上评估了我们的模型。7B 模型在 mAP 上没有显示出任何改进,而 3B 模型获得了一些改进,因此也许使用相同的数据 (OCDEval),具有较小训练参数的 3B 模型可能比具有更强基础能力的 7B 模型能够实现更多的改进。
然而,以上所有发现都是通过在 OVDEval 数据集上训练获得的,其数据特性可能产生一些影响。未来,我们将尝试在其他数据集(例如 D³)上继续实验以验证这些发现。
6. 强化学习 vs. SFT 训练比较
6.1 基本性能比较
我们使用相同的训练数据 (COCO) 和基础模型 (Qwen2.5-VL-3B) 对基本的强化学习 (RL) 和监督微调 (SFT) 方法进行了初步比较。在此次比较中,我们使用 MAP 奖励进行强化学习。请注意,这些结果反映了基本的 RL 实现,不包括稍后探索的高级技术,例如 KL 散度调整 (KL=0) 或输出长度控制奖励。
| 训练方法 | REFCOCO | REFGTA | COCO_filtered (mAP) |
|---|---|---|---|
| 基础模型 (Qwen2.5-VL-3B) | 73.73 | 71.8 | 23.7 |
| 基本强化学习训练 | 73.87 | 67.4 | 23.5 |
| SFT 训练 | 83.20 | 70.4 | 25.5 |
注:这些初步结果显示,SFT 在没有高级技术的情况下优于基本 RL。后来使用优化 RL 奖励进行的实验显示,相对于这些基线 RL 结果,性能有了实质性改进。
6.2 Token 生成分析
| 模型 | 最小 Token 数 | 最大 Token 数(不包括 ≥3000) | 平均 Token 数(不包括 ≥3000) | Token 数 ≥3000 的记录 |
|---|---|---|---|---|
| 基础模型 | 34 | 1892 | 139.752 | 281 |
| 强化学习模型 | 79 | 2999 | 240.563 | 534 |
| SFT 模型 | 48 | 2999 | 192.259 | 238 |
关键观察:SFT 训练的模型输出往往更简洁,同时保持更好的性能。使用 MAP 奖励的 RL 倾向于生成更冗长的输出,可能通过生成更多边界框来“破解”奖励。
7. 其他实现发现
7.1 训练器一致性验证
对多种实现进行了一致性测试
| 代码版本 | SuperCLEVR 测试分数 |
|---|---|
| 旧版本 [734e46] | 85 |
| 新版本 [a301eb] | 87 |
| VLLM 版本 [85d9f4] | 87 |
所有实现都表现出一致的性能,验证了代码库的稳定性。
7.2 模型大小影响 (3B vs 7B)
OVDEVAL 上的性能比较
| 模型 | OVDEval 平均 (mAP) | 专有名词平均 | 属性平均 | 立场 | 关系 | 否定 |
|---|---|---|---|---|---|---|
| 7B 最佳 | 45.27 | 53.33 | 25.10 | 65.4 | 26.1 | 56.4 |
| 3B 最佳 | 43.43 | 51.87 | 24.70 | 63.1 | 26.6 | 50.9 |
7B 模型通常表现稍好,尽管差异不显著。7B 模型在否定任务上尤其具有优势。
7.3 完成长度和批处理大小
将最大完成长度增加到 2048 同时减少批处理大小并未带来显著改进
原始配置(最大长度 1024,较大批处理大小)在处理效率和响应质量方面表现更好
8. 关键要点和最佳实践
训练方法
经过良好调整的 RL(特别是带有余弦奖励的)可以胜过 SFT
未经仔细奖励工程的基本 RL 可能会表现不佳于 SFT
数据准备
优先使用单类别、单框目标检测训练数据
在小目标训练时考虑精度-召回率权衡
避免在目标检测任务中进行纯单区域标签训练
奖励选择
使用 AP 而非 AP50 来获得更精细的反馈
加权和与余弦奖励结合可提供最佳性能
谨慎使用重复奖励,因为它们可能会降低召回率
提示词工程
即使是微小的语法问题也可能影响训练收敛
结构良好的提示词可以显著加速训练
在提示词中保留结构化的思考过程
7B 模型对提示词格式的敏感度低于 3B 模型
实现
代码实现在不同版本中均稳定
VLLM 可以安全地用作替代实现
9. 未来研究方向
研究多任务训练的最佳混合比例
开发改进的强化学习训练奖励函数
研究在不损失精度的情况下更好地处理小目标检测的方法
我们将继续探索新方法,并欢迎社区的反馈和贡献。