通过强化学习与 VLM-R1 改进目标检测








概述
这项工作表明,与视觉语言模型中的监督微调(SFT)相比,强化学习(RL)显著提高了目标检测性能。使用基于 Qwen2.5-VL-3B 构建的 VLM-R1 框架,并在描述检测数据集(D³)上进行训练,RL 取得了以下成果:
COCO 上 20.1% 的 mAP(SFT 为 17.8%;7B 模型为 14.2%)
OVDEval 上新的 SOTA 31.01 nms-AP(SFT 为 26.50;7B 模型为 29.08),在复杂任务如位置检测(+9.2%)和关系检测(+8.4%)中表现出色。
“OD 恍然大悟”推理的出现:RL 模型通过内部验证步骤,在检测前自发地学会过滤不相关的对象(例如,网球场景中的“白天鹅”)。
关键创新包括奖励工程,用于抑制冗余边界框和长度控制输出,解决了传统 AP 指标的关键局限性。结果验证了 RL 学习的是可泛化的检测原理,而不是记忆训练数据,从而推动了现实世界场景中的开放词汇目标检测。
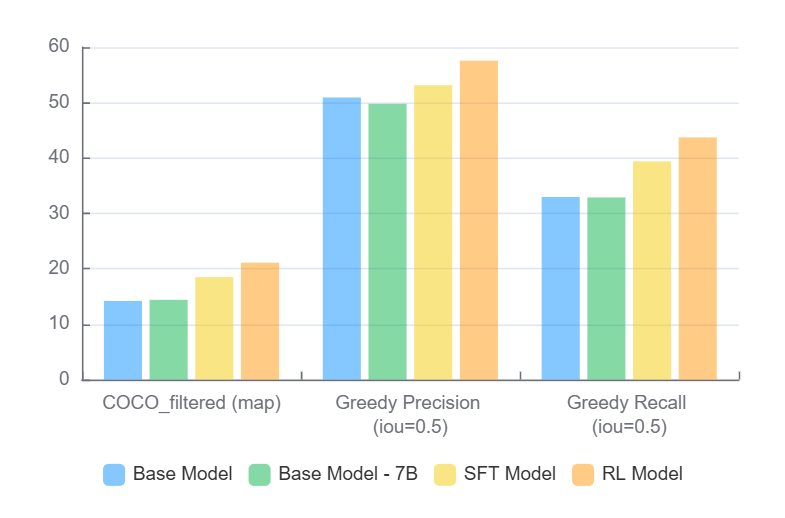
(在过滤后的 COCO val2017 集上的结果)
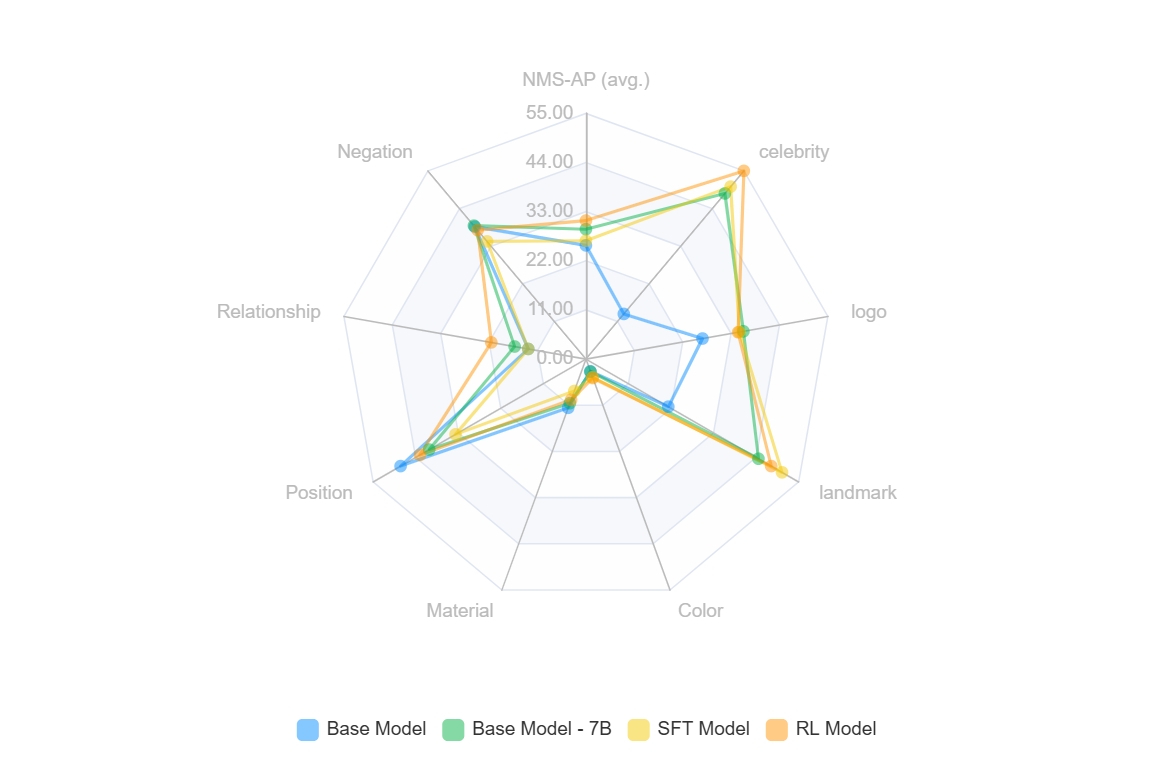
(OVDEval 数据集上的结果)
引言
目标检测仍然是计算机视觉中的一个基本挑战,尤其是在处理灵活的语言描述和复杂场景时。在我们最近的工作中,我们探索了使用强化学习(RL)来增强视觉语言模型的目标检测能力,采用了 VLM-R1 框架。我们的研究结果与最近的研究一致,表明 RL 方法倾向于学习比监督微调(SFT)方法更具泛化性的知识(Chu et al., 2024)。
我们研究中最令人惊讶的发现之一是,在经过 RL 训练的模型中出现了一种意想不到的推理模式(我们称之为“OD 恍然大悟时刻”)。当遇到包含多个潜在对象(包括强负标签)的检测任务时,模型自发地发展出两步方法:首先通过一个“思考”步骤明确过滤和识别图像中实际存在的对象,然后进行精确的边界框检测。这种涌现的行为特别有趣,因为它没有经过明确的训练或提示——模型独立地学会了通过首先推理相关对象,然后再进行检测来处理复杂场景。例如,当给定一张包含相关对象和不相关项目(如“白天鹅”或“未完成的苹果”)的网球场图像时,模型首先声明它关注与网球相关的元素,然后才输出任何边界框,从而实现更准确和高效的检测。
目标检测“恍然大悟”示例

Given task: Please carefully check the image and detect the following objects:
- white swan in the water
- person playing tennis with a racket
- person wearing a hat on a tennis court
- tennis racket
- incomplete apple
- non-human mask
- volleyball on the beach
- person doing yoga
<think>
The task requires object detection. From analyzing the image, I can see this is a tennis-related scene.
Only tennis-related objects are present - specifically a player with a racket wearing a hat.
Other objects like swans, apples, masks, volleyballs and yoga poses are not in this image.
</think>
<answer>
```json
[
{"bbox_2d": [160, 17, 534, 507], "label": "person playing tennis with a racket"},
{"bbox_2d": [160, 17, 534, 507], "label": "person wearing a hat on a tennis court"},
{"bbox_2d": [146, 74, 228, 133], "label": "tennis racket"}
]
方法
我们首先尝试在最流行的 OD 数据集 COCO 上进行训练,但 SFT 和 RL 模型都没有比基础模型有所改进。我们假设基础模型 Qwen2.5-VL-3B 在 COCO 上已经训练得很好,无法从中学习任何新知识。我们最终使用描述检测数据集(D³)进行了实验,该数据集为训练目标检测模型提供了几个独特的优势:
完整的注释覆盖
不受限制的语言描述
实例级注释
支持缺失表达
我们的训练过程利用了 VLM-R1 框架,该框架以 Qwen2.5-VL-3B 模型作为基础架构。与“SFT 记忆,RL 泛化”中描述的方法类似,我们探索了 SFT 和 RL 两种训练范式,以比较它们在学习可泛化检测原理而不是仅仅记忆训练数据方面的有效性。
评估基准:
OVDEval
为了全面评估我们模型的能力,我们使用了 OVDEval,这是一个专门为测试开放词汇检测(OVD)模型而设计的综合基准。OVDEval 通过以下方式解决了现有评估方法中的几个局限性:
系统泛化测试:该基准由 9 个子数据集组成,涵盖 6 个关键语言方面
目标检测
专有名词识别(名人、徽标、地标)
属性检测
位置理解
关系理解
否定处理
硬负例评估:OVDEval 包含精心选择的硬负例标签,使其在评估实际模型性能方面特别有效。这对于理解模型如何处理具有挑战性的情况和模糊场景至关重要。
质量保证:所有数据均由人类专家手动标注,以确保高质量的真实数据,数据来源包括 HICO、VG 和 Laion-400m 等多样化数据集。
改进的指标:该基准引入了一种新的非极大值抑制平均精度(NMS-AP)指标,以解决传统评估方法中常见的“AP 虚高问题”。这通过防止冗余预测导致人为高分来提供更准确的模型性能评估。
这个全面的评估框架使我们不仅能够评估基本的目标检测能力,还能评估模型处理复杂语言描述和现实世界场景的能力。
COCO 过滤:
COCO 数据集是根据 COCO 数据集的 instances_val2017.json 文件创建的。由于 VLM 在 OD 任务中通常难以召回(参见 ChatRex),我们过滤掉了注释框超过 10 个的类别,确保只包含框更少的类别。
结果与分析
COCO 数据集性能
我们在过滤后的 COCO val2017 集上的结果显示,关键指标有了显著改善:
| 模型 | COCO_filtered (mAP) | 贪婪精确度 (IoU=0.5) | 贪婪召回率 (IoU=0.5) |
|---|---|---|---|
| 基础版 | 13.8 | 50.93 | 32.97 |
| 基础 7B | 14.2 | 49.79 | 32.88 |
| SFT 模型 | 17.8 | 53.15 | 39.4 |
| RL 模型 | 20.1 | 57.57 | 43.73 |
RL 训练模型在 SFT 模型上表现出显著改进,mAP 增加了 2.3 个百分点(20.1% 对 17.8%),贪婪精确度提高了 4.42 个百分点(57.57% 对 53.15%),贪婪召回率提高了 4.33 个百分点(43.73% 对 39.4%)。这些在所有指标上的一致改进表明了 RL 卓越的泛化能力。
OVDEval 基准测试结果
在全面的 OVDEval 基准测试中,RL 模型在几个关键领域显示出优于 SFT 的显著优势:
| 模型 | nms-ap (平均) | 名人 | 徽标 | 地标 | 颜色 | 材质 | 立场 | 关系 | 否定 |
|---|---|---|---|---|---|---|---|---|---|
| 基础版 | 25.46 | 13.2 | 26.5 | 21.3 | 2.9 | 11.6 | 47.9 | 13.1 | 38.7 |
| 基础 7B | 29.08 | 48.4 | 35.8 | 44.6 | 3 | 10.5 | 40.5 | 16.2 | 39 |
| SFT | 26.50 | 50.4 | 34.9 | 50.7 | 4.3 | 7.6 | 33.7 | 13.1 | 34.4 |
| RL | 31.01 | 55.0 | 34.6 | 47.9 | 4.5 | 9.7 | 42.9 | 21.5 | 37.7 |
| RL - SFT | +4.51 | +4.6 | -0.3 | -2.8 | +0.2 | +2.1 | +9.2 | +8.4 | +3.3 |
“SFT 记忆,RL 泛化”
我们的研究结果有力支持了 Chu et al. 关于 SFT 和 RL 方法不同学习行为的结论:
泛化能力:RL 模型通过在 9 个检测类别中的 7 个方面优于 SFT,展示了卓越的泛化能力。最值得注意的是,它在需要更深入理解的复杂任务中显示出显著改进:
位置检测(+9.2 分)
关系检测(+8.4 分)
否定处理(+3.3 分)
视觉能力:虽然 SFT 在名人、标志和地标检测等特定类别中表现强劲,但 RL 在不同的视觉任务中表现出更均衡的改进,表明对视觉理解的整体泛化能力更好。
SFT 与 RL 的作用:结果清楚地表明,虽然 SFT 对某些特定任务有效,但 RL 提供了更全面的改进。平均 nms-ap 提高 4.51 分(31.01 对 26.50)表明 RL 学习可泛化特征的能力优于仅仅记忆训练模式。
技术见解
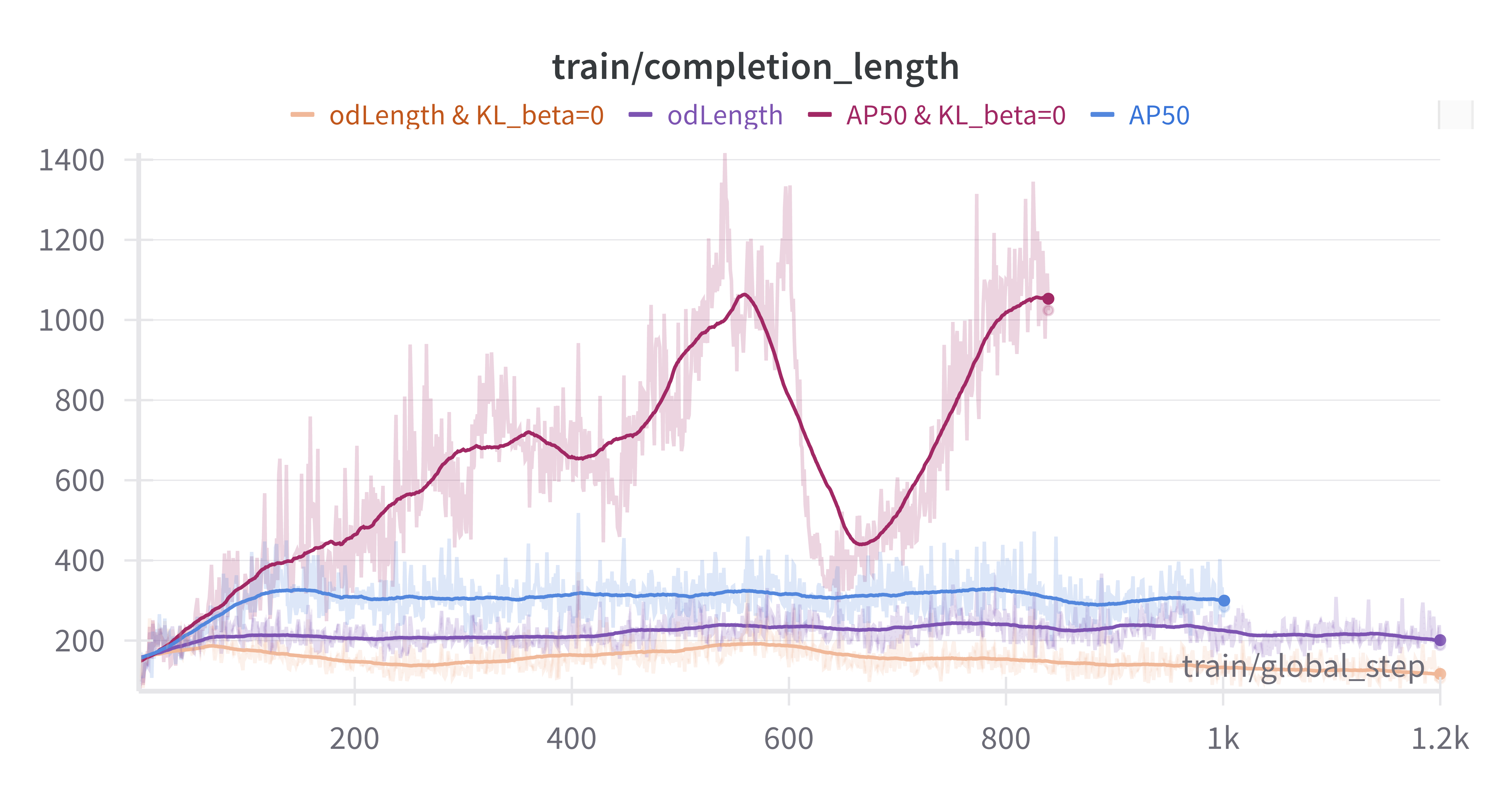
通过我们的实验过程,我们做了一些重要的发现:
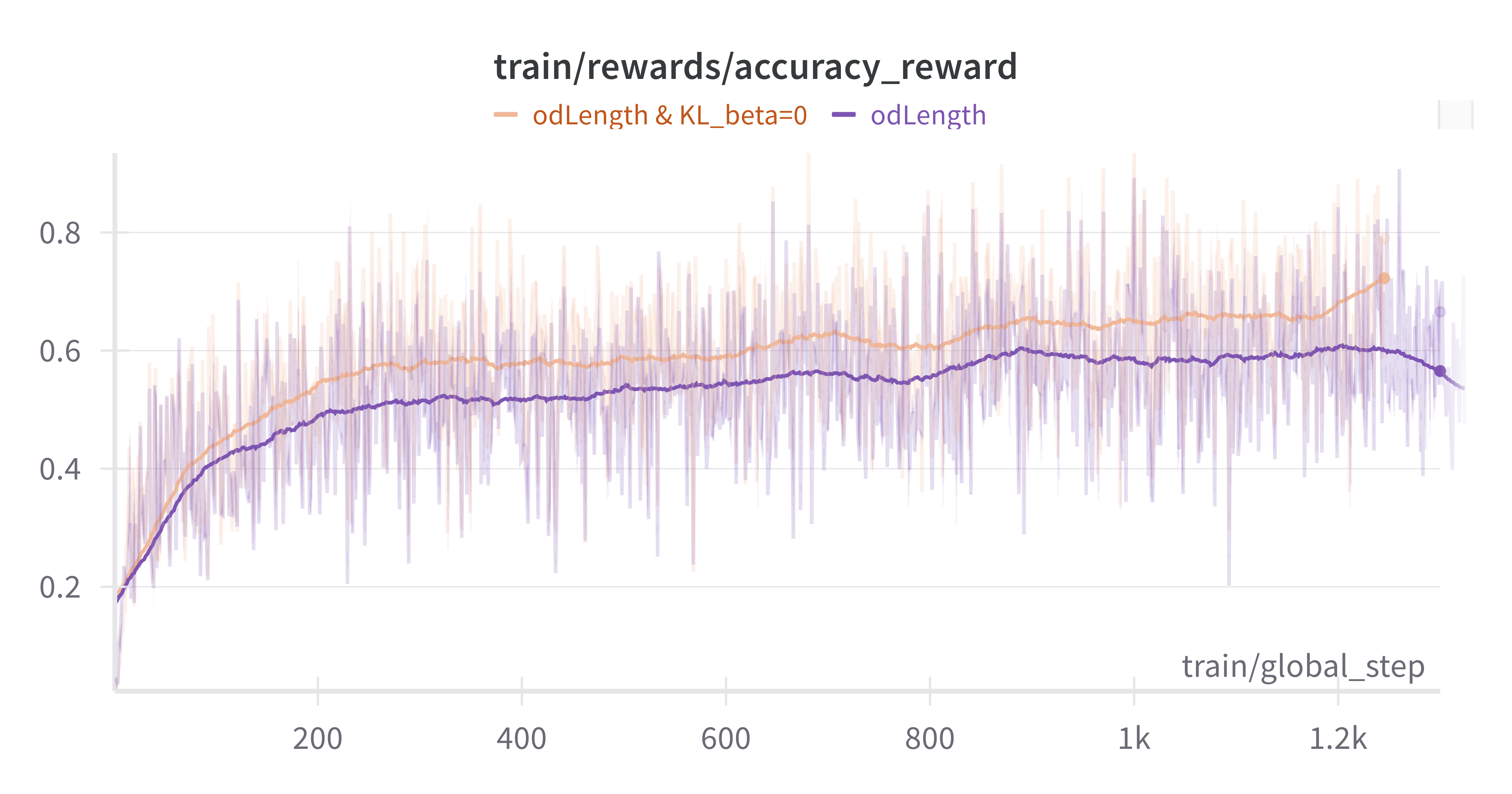
KL 散度影响:将 KL beta 设置为 0 导致完成长度更长,但引入了早期边界框冗余问题。这需要额外的奖励工程来控制。
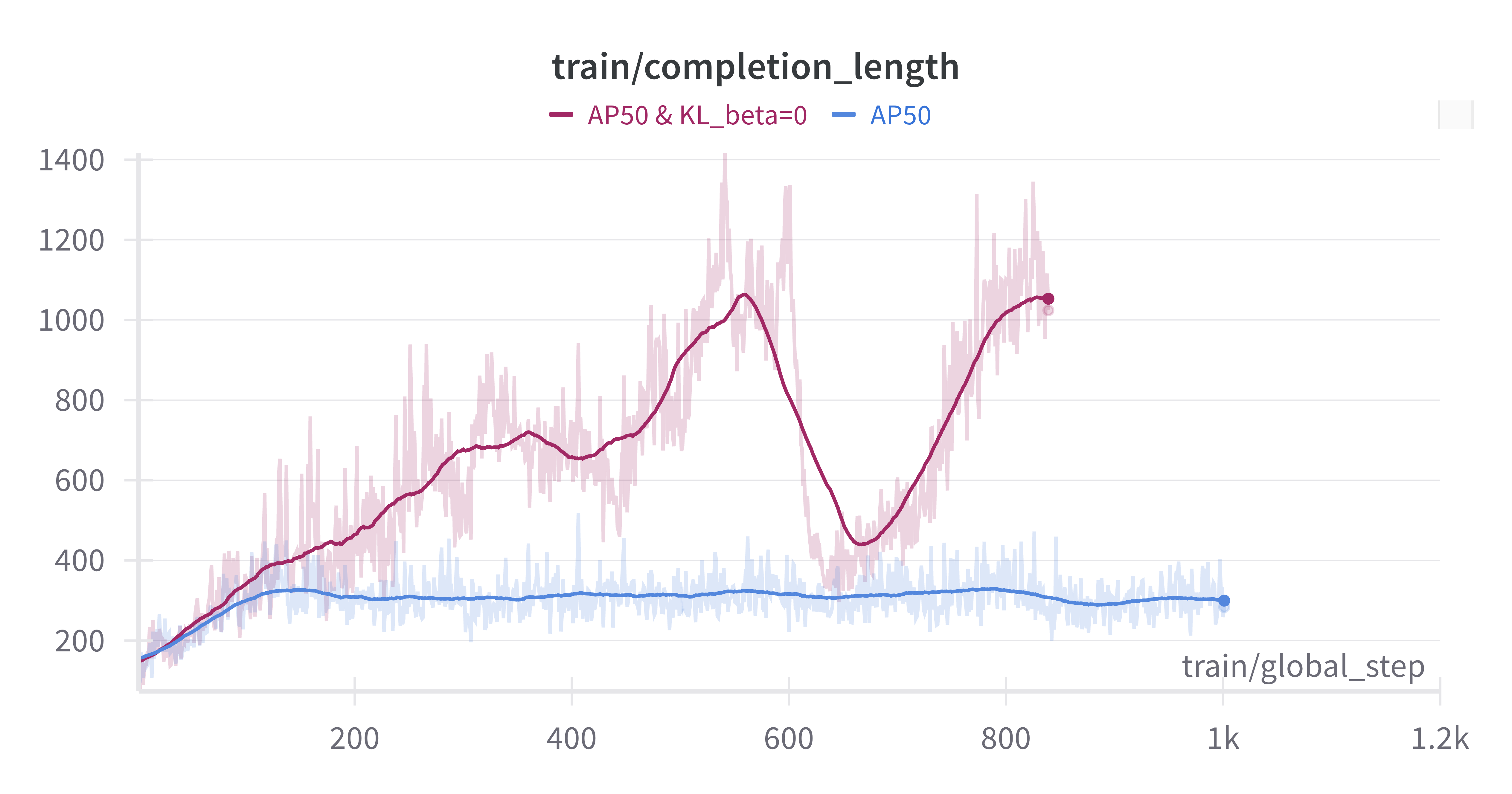
边界框的 AP 或 AP50: 对于 VLM 模型,准确预测边界框坐标可能具有挑战性。最初,AP50 被用作更宽松的奖励函数来训练模型。在评估期间,所有预测框的置信度得分都设置为 1.0,并计算 COCO mAP 来确定奖励。训练结果表明,模型在 AP50 上快速取得了高分,但在评估期间的 mAP 性能不尽理想。比较表明,使用更严格的 AP 指标进行训练会产生更好的结果。
边界框长度控制奖励:mAP 指标对过多的误报框的惩罚很小,这使得模型可以通过生成冗余框来人为地提高 AP 分数。当 KL 散度为零时,这种行为尤为明显,因为模型倾向于通过增加输出标记来产生更多冗余框。为了抵消这种行为,我们实现了一种奖励机制来抑制这种行为。引入结合了 AP 和边界框长度控制的“odLength”奖励,被证明非常有效。
COCO_filtered mAP 从 11.4 提高到 18.8
OVDEval 平均 mAP 从 12.0 增加到 30.2
输出特性:使用 KL=0 和长度控制训练的模型产生更简洁的输出,同时保持检测精度,表明更高的效率。
与最先进的 OD:OmDet 的比较
OmDet 代表了专业开放词汇检测的最新技术水平,引入了高效融合头部 (EFH) 和语言缓存等创新,以在保持高精度的同时实现实时性能。然而,我们的 VLM-R1 模型表明,大型视觉语言模型在几个关键方面可以超越专业架构。
比较 OVDEval 上的整体性能:
OmDet: 25.86 nms-ap
VLM-R1 (RL): 31.01 nms-ap
提升: +5.15 分 (相对提升 19.9%)
这种显著的性能差距揭示了关于不同方法的优势和局限性的有趣见解:
世界知识和实体识别:
在名人检测中,VLM-R1 达到 55.0 nms-ap,而 OmDet 为 1.8
这种巨大的差异(>50 分)证明了 VLM 预训练世界知识的价值
在标志和地标检测中也出现了类似的模式,其中语义理解至关重要
细粒度检测与高层次理解:OVDEval 中的属性类别包含大量小对象。
OmDet 在属性检测中表现出更强的性能(颜色:41.98 对 4.5)
这表明专用架构擅长细粒度、局部特征检测
对于需要精确定位的小对象,差距尤其明显
复杂推理任务:
VLM-R1 在关系检测中显著优于 OmDet (21.5 对 11.4)
更好地处理否定 (37.7 对 35.1)
展示了 VLM 在需要上下文理解的任务中的卓越能力
这些比较表明了一个有希望的未来方向:结合两种方法的互补优势。专业 OD 架构擅长细粒度检测和高召回率场景,而 VLM 则带来丰富的世界知识和卓越的推理能力。未来的研究可以专注于创建混合架构,利用专用 OD 模型的精确本地化能力和 VLM 的语义理解能力。
结论
我们的探索表明,强化学习在提高目标检测性能的同时保持泛化能力方面特别有效。D³ 数据集与我们增强的 VLM-R1 框架的结合,为该领域的未来发展提供了坚实的基础。
结果表明,精心的奖励工程,特别是围绕输出长度控制的奖励,在实现最佳性能方面起着至关重要的作用。这与 RL 方法可以学习更具泛化性的原理而不是简单地记忆训练数据的更广泛理解相符。
[来源:[VLM-R1 GitHub 存储库](https://github.com/om-ai-lab/VLM-R1)\]