通过 Racine.ai Flantier 开源多模态模型推进欧洲人工智能主权







作者:Racine.ai 团队
人工智能技术的迅速发展突显了人工智能主权能力,特别是在**图像-文本到向量检索**等多模态任务中的战略重要性。尽管该领域中高性能模型(**例如基于 Qwen 的模型**)已表现出卓越的准确性,但它们**非欧洲**的起源引发了对长期**技术自主性、数据治理和工业竞争力**的担忧。
为此,我们与 ECE(法国电子技术中央学院)人工智能实验室启动了一项合作倡议,作为 2025 年 3 月 18 日 ECE 人工智能教学研究创新中心落成典礼上与 MBDA 共同展示的用例的一部分。人工智能实验室的目标是通过将尖端技术融入 ECE 学生的教育中,培养未来的 AI 领导者,并通过与法国和国际的行业领导者和学术机构建立战略伙伴关系来促进负责任的创新。我们的目标是评估**由法国公司 Hugging Face 开发的欧洲开源模型 SmolVLM**是否可以通过**系统的数据整理和微调**来接近领先的中国模型的性能水平。
我们的调查始于对 **SmolVLM 基线性能**的评估,该模型在我们今天与 Energy 上线的内部开放 VLM 基准测试中,准确率约为 **19%**,**远低于 Qwen 微调模型的 90%**。这一差异凸显了需要进行有针对性的改进,特别是在模型从多模态输入生成**高质量向量表示(旨在嵌入文档截图)**的能力方面。
Racine.ai 开放 VLM 排行榜 – 所有语言

为解决此问题,我们开发了**“组织、分组、清理”(OGC)数据集**,这是一组精心策划的资源,专门用于在**图像-文本到向量任务**上微调 SmolVLM,我们已将相关代码开源,可在此处获取。通过整合和标准化来自多个来源的数据(包括 ColPali、VisRAG-Ret-Train-Synthetic-data 和 VDR-Multilingual-Train),我们构建了一个统一的**纯正样本数据集 (OGC_2_vdr-visRAG-colpali)**,以优化训练效率。**我们删除了负样本以简化学习过程**,确保每个条目仅包含相关的查询-图像对。
使用 OGC 数据集对 SmolVLM 进行**微调取得了显著的改进**。**5 亿参数模型实现了 0.57 的平均准确率**,而 **20 亿参数模型则达到了 0.767**,这表明即使是中等规模的欧洲模型,通过高质量的数据增强也能达到工业可行的性能。
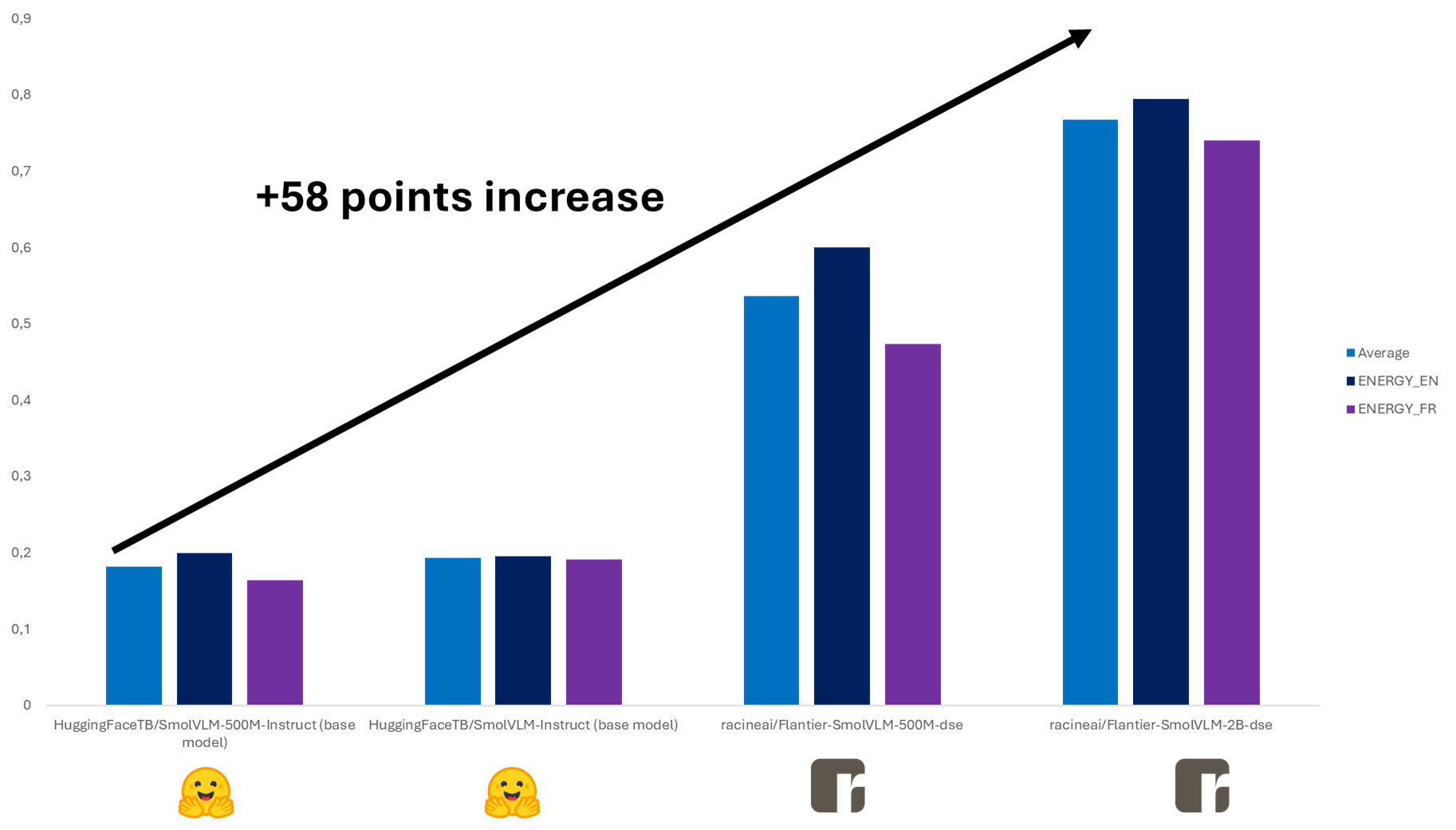
这些结果仅比 Qwen 的 0.86 平均准确率(Qwen 目前用于多数用例的工业化)**低 0.10**,这验证了**开源、符合主权原则的替代方案**的潜力。
Racine.ai 开放 VLM 排行榜 – 仅限英语查询

为了更好地理解这些进展,**我们根据开放 VLM 检索排行榜上的现有解决方案对我们微调的模型进行了基准测试**,该排行榜评估了跨行业和语言的**跨语言检索准确性**。虽然**阿里巴巴-NLP/gme-Qwen2-VL-2B-Instruct 和 vidore/colqwen2-v1.0 等中文模型占据了排行榜的前列**,但我们增强的 SmolVLM (racineai/Flantier-SmolVLM-2B-dse)**表现出色,尤其是在英语任务中(平均准确率为 0.822)**。值得注意的是,**在英语基准测试中,它甚至达到了 0.887 的中等水平分数**。
**法语和其他欧洲语言的性能仍有待进一步优化**,这凸显了在训练数据中实现更广泛语言多样化的必要性。
我们的方法保持**完全透明**:我们的模型、数据集和训练方法均**公开可用,以促进协作和迭代改进**。
**这项工作的影响超越了技术指标**。通过**开源每个组件**——从基础模型(SmolVLM2-2.2B)到特定行业数据集——我们旨在催生一个协作生态系统,让欧洲机构、公司和研究人员能够共同提升本地 AI 能力。这项倡议不仅是**概念验证**,更是**行动号召**:只有通过**对数据、计算和模型改进的共同投入**,欧洲 AI 才能缩小与全球领导者的差距。
展望未来,我们确定了**三个关键的进步途径**:
- **扩展 OGC 数据集的语言和行业覆盖范围**,以解决当前多语言性能中的不对称问题。
- **优化架构效率**,以在不牺牲准确性的前提下降低推理成本。
- **与行业和学术界建立伙伴关系**,以扩展数据收集和验证过程。
这些步骤中的每一步都与**技术自给自足**这一更广泛的当务之急相符,在一个**人工智能主权与经济和战略弹性密不可分**的时代。
我们还通过为关键行业创建专门的多语言子集来扩展数据集的适用性,这些行业在 Hugging Face 上都缺乏数据集,例如国防(**OGC_Military**)(上传时 Hugging Face 上只有大约 20 个“军事”关键词数据集),目前这是**最大的开源军事数据集之一,拥有超过 160,000 行数据**;能源(**OGC_Energy**);岩土工程(**OGC_Geotechnie**),以及氢能(**OGC_Hydrogen**)(上传时 Hugging Face 上只有不到五个),所有这些都根据 Apache-2.0 许可证发布。
我们开发了 OGC 框架来简化数据集合并,这是一项关键的优化,因为训练期间的运行时数据映射会消耗过多的 GPU 资源。通过在 CPU 上预处理此步骤,我们优化了训练管道,达到了与最先进模型相当的准确率。
这项工作总共包括 **500,000 行自定义数据集,以及与 OGC 格式合并的数据集总计超过 100 万行**,所有这些都在 Apache-2.0 许可证下开源。
此外,我们还开源了一个**退化数据集**——25,000 行 OCR 退化文档图像及其真实 OCR 文本——解决了 OCR 模型训练中的一个关键空白。该数据集模拟了生产环境中遇到的真实世界条件,特别是在国防应用中,文档可能扫描质量差、在光线不足的情况下拍摄或因环境因素而退化。

这些**特定领域数据集**使组织能够针对小众用例微调模型,而不会损害其通用性。我们鼓励**行业利益相关者利用这些资源——无论是改进他们自己的模型还是为我们发布的模型做出进一步贡献**。
我们的结果表明,**欧洲模型与严格的数据整理相结合,可以实现与最先进系统的有意义的对等**。实现全面竞争的旅程是迭代的,但**基础——开放、适应性强、社区驱动——现已到位**。**我们邀请所有利益相关者利用这些资源,确保欧洲的 AI 未来由其自身的机构、价值观和抱负塑造**。
关于 Racine.ai:
Racine.ai 是 **TW3 Partners** 的 GenAI 子公司,专门为在**主权领域**(domaine régaliens)运营的企业(包括国防、能源和关键基础设施)提供**人工智能解决方案**。通过利用**开源、符合主权原则的技术**,我们使组织能够利用人工智能,同时确保**数据治理、战略自主和工业竞争力**。
发布的关键资源:
- **模型**:微调后的 **SmolVLM-500M (准确率 57%)** 和 **SmolVLM-2B (准确率 69%)**。
- **数据集**:OGC_2_vdr-visRAG-colpali、OGC_Military、OGC_Energy、OGC_Geotechnie、OGC_Hydrogen、ocr-pdf-degraded。
- **基准测试**:开放 VLM 检索排行榜上的完整结果。
- OGC 代码
- **访问权限**:所有资产和模型均可在 Hugging Face 上获取,遵循 MIT 或 Apache 2.0 许可证。
致谢:
这项工作离不开 Hugging Face 的基础模型及其开源生态系统,它们使我们能够构建、完善和扩展主权人工智能解决方案。
作者:
- **Paul Lemaistre**:TW3 Partners 首席开发人员 & Racine.ai 联合创始人 – 法国电子技术中央学院兼职教授。
- **Léo Appourchaux**:TW3 Partners 人工智能开发人员。
- **André-Louis Rochet**:TW3 Partners 执行董事 & Racine.ai 联合创始人 – 法国电子技术中央学院兼职教授。
关于 Ecole Centrale d'Electronique:
ECE 是一所多项目、多校区、多领域的工程学院,专注于数字工程,为 21 世纪培养能够应对数字和可持续发展双重革命挑战的工程师和技术专家。法国工程学院 ECE





