Perceiver IO:一种可扩展的、全注意力模型,适用于任何模态







TLDR
我们已将 Perceiver IO 添加到 Transformers 中,这是第一个基于 Transformer 的神经网络,可处理各种模态(文本、图像、音频、视频、点云等)及其组合。请查看以下 Spaces 以查看一些示例
我们还提供了 几个 Jupyter Notebook。
下面是模型的详细技术解释。
引言
Vaswani 等人于 2017 年首次引入的 Transformer 在人工智能社区引发了一场革命,最初在机器翻译领域提升了最先进 (SOTA) 的结果。2018 年,BERT 发布,这是一种仅包含 Transformer 编码器的模型,在自然语言处理 (NLP) 的基准测试中表现出色,其中最著名的是 GLUE 基准。
此后不久,人工智能研究人员开始将 BERT 的思想应用于其他领域。举几个例子
- Facebook AI 的 Wav2Vec2 证明该架构可以扩展到音频
- Google AI 的 Vision Transformer (ViT) 表明该架构在视觉方面表现出色
- 最近,Google AI 的 Video Vision Transformer (ViViT) 也将该架构应用于视频。
在所有这些领域中,得益于这种强大架构与大规模预训练的结合,最先进的结果得到了显著改善。
然而,Transformer 架构存在一个重要限制:由于其 自注意力机制,它在计算和内存方面的扩展性 非常差。在每个层中,所有输入都用于生成查询 (queries) 和键 (keys),并计算它们的点积。因此,如果不进行某种形式的预处理,就无法在高维数据上应用自注意力。例如,Wav2Vec2 通过使用特征编码器将原始波形转换为基于时间的特征序列来解决这个问题。Vision Transformer (ViT) 将图像分割成不重叠的图像块序列,这些图像块充当“token”。Video Vision Transformer (ViViT) 从视频中提取不重叠的时空“管”,这些“管”充当“token”。为了使 Transformer 在特定模态上工作,通常需要将其离散化为 token 序列。
Perceiver 模型
Perceiver 旨在通过对一组潜在变量而不是输入数据应用自注意力机制来解决此限制。输入数据(可以是文本、图像、音频、视频)仅用于与潜在变量进行交叉注意力。这样做的好处是,大部分计算发生在潜在空间中,计算成本较低(通常使用 256 或 512 个潜在变量)。由此产生的架构没有输入大小的二次依赖性:Transformer 编码器仅线性依赖于输入大小,而潜在注意力与输入大小无关。在后续论文《Perceiver IO》中,作者扩展了这一思想,使 Perceiver 也能处理任意输出。其思想类似:仅使用输出与潜在变量进行交叉注意力。请注意,在本篇博文中,“Perceiver”和“Perceiver IO”这两个术语将可互换地指代 Perceiver IO 模型。
在接下来的部分中,我们将更详细地了解 Perceiver IO 的实际工作原理,通过其在 HuggingFace Transformers 中的实现进行讲解。HuggingFace Transformers 是一个流行的库,最初用于实现基于 Transformer 的 NLP 模型,但现在也开始在其他领域实现它们。在以下部分中,我们将通过张量的形状,详细解释 Perceiver 实际如何对任何模态进行预处理和后处理。
HuggingFace Transformers 中的所有 Perceiver 变体都基于 `PerceiverModel` 类。要初始化 `PerceiverModel`,可以为模型提供 3 个额外的实例
- 一个预处理器
- 一个解码器
- 一个后处理器。
请注意,这些都是可选的。只有当尚未自行嵌入 `inputs`(例如文本、图像、音频、视频)时才需要 `preprocessor`。只有当需要将 Perceiver 编码器的输出(即潜在变量的最后隐藏状态)解码为更有用的东西,例如分类 logits 或光流时,才需要 `decoder`。只有当需要将解码器的输出转换为特定特征时才需要 `postprocessor`(这仅在进行自编码时需要,我们稍后会看到)。架构概述如下图所示。

Perceiver 架构。
换句话说,`inputs`(可以是任何模态,或它们的组合)首先通过 `preprocessor` 进行可选的预处理。接下来,预处理后的输入与 Perceiver 编码器的潜在变量执行交叉注意力操作。在此操作中,潜在变量生成查询 (Q),而预处理后的输入生成键和值 (KV)。此操作后,Perceiver 编码器采用(可重复的)自注意力层块来更新潜在变量的嵌入。编码器最终将生成一个形状为 (batch_size, num_latents, d_latents) 的张量,其中包含潜在变量的最后隐藏状态。接下来,有一个可选的 `decoder`,可用于将潜在变量的最终隐藏状态解码为更有用的东西,例如分类 logits。这是通过执行交叉注意力操作完成的,其中可训练的嵌入用于生成查询 (Q),而潜在变量用于生成键和值 (KV)。最后,有一个可选的 `postprocessor`,可用于将解码器输出后处理为特定特征。
让我们首先展示 Perceiver 如何实现文本处理。
文本 Perceiver
假设我们想应用 Perceiver 进行文本分类。由于 Perceiver 自注意力机制的内存和时间需求不依赖于输入的大小,我们可以直接向模型提供原始 UTF-8 字节。这是有益的,因为熟悉的基于 Transformer 的模型(如 BERT 和 RoBERTa)都采用某种形式的显式分词,例如 WordPiece、BPE 或 SentencePiece,这 可能有害。为了与 BERT(使用 512 个子词 token 的序列长度)进行公平比较,作者使用了 2048 字节的输入序列。假设我们还添加了一个批处理维度,那么模型的 `inputs` 形状为 (batch_size, 2048)。`inputs` 包含单个文本的字节 ID(类似于 BERT 的 `input_ids`)。我们可以使用 `PerceiverTokenizer` 将文本转换为字节 ID 序列,并填充到 2048 的长度。
from transformers import PerceiverTokenizer
tokenizer = PerceiverTokenizer.from_pretrained("deepmind/language-perceiver")
text = "hello world"
inputs = tokenizer(text, padding="max_length", return_tensors="pt").input_ids
在这种情况下,我们为模型提供了 `PerceiverTextPreprocessor` 作为预处理器,它将负责嵌入 `inputs`(即将每个字节 ID 转换为相应的向量),并添加绝对位置嵌入。作为解码器,我们为模型提供了 `PerceiverClassificationDecoder`(它将潜在变量的最后隐藏状态转换为分类 logits)。不需要后处理器。换句话说,用于文本分类的 Perceiver 模型(在 HuggingFace Transformers 中称为 `PerceiverForSequenceClassification`)的实现如下:
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverTextPreprocessor, PerceiverClassificationDecoder
class PerceiverForSequenceClassification(nn.Module):
def __init__(self, config):
super().__init__(config)
self.perceiver = PerceiverModel(
config,
input_preprocessor=PerceiverTextPreprocessor(config),
decoder=PerceiverClassificationDecoder(
config,
num_channels=config.d_latents,
trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
use_query_residual=True,
),
)
在这里我们可以看到,解码器是用可训练的位置编码参数初始化的。这是为什么呢?好吧,让我们详细看看 Perceiver IO 究竟是如何工作的。在初始化时,`PerceiverModel` 在内部定义了一组潜在变量,如下所示
from torch import nn
self.latents = nn.Parameter(torch.randn(config.num_latents, config.d_latents))
在 Perceiver IO 论文中,使用了 256 个潜在变量,并将潜在变量的维度设置为 1280。如果再添加一个批处理维度,则 Perceiver 的潜在变量形状为 (batch_size, 256, 1280)。首先,预处理器(在初始化时提供)将负责将 UTF-8 字节 ID 嵌入到嵌入向量中。因此,`PerceiverTextPreprocessor` 会将形状为 (batch_size, 2048) 的 `inputs` 转换为形状为 (batch_size, 2048, 768) 的张量——假设每个字节 ID 都转换为大小为 768 的向量(这由 `PerceiverConfig` 的 `d_model` 属性决定)。
在此之后,Perceiver IO 在形状为 (batch_size, 256, 1280) 的潜在变量(生成查询)与形状为 (batch_size, 2048, 768) 的预处理输入(生成键和值)之间应用交叉注意力。这个初始交叉注意力操作的输出是一个与查询(在这种情况下是潜在变量)形状相同的张量。换句话说,交叉注意力操作的输出形状为 (batch_size, 256, 1280)。
接下来,应用一个(可重复的)自注意力层块来更新潜在变量的表示。请注意,这些不依赖于您提供的输入(即字节)的长度,因为这些只在交叉注意力操作期间使用。在 Perceiver IO 论文中,一个包含 26 个自注意力层(每个自注意力层有 8 个注意力头)的单个块被用于更新文本模型的潜在变量表示。请注意,这 26 个自注意力层之后的输出仍然具有与您最初提供给编码器的输入相同的形状:(batch_size, 256, 1280)。这些也被称为潜在变量的“最后隐藏状态”。这与您提供给 BERT 的 token 的“最后隐藏状态”非常相似。
好的,现在我们有了形状为 (batch_size, 256, 1280) 的最终隐藏状态。很棒,但我们实际上想把它们转换成分类 logits,形状为 (batch_size, num_labels)。我们如何让 Perceiver 输出这些呢?
这由 `PerceiverClassificationDecoder` 处理。其思想与将输入映射到潜在空间时的操作非常相似:我们使用交叉注意力。但现在,潜在变量将生成键和值,而我们提供一个任何我们想要的形状的张量——在这种情况下,我们将提供一个形状为 (batch_size, 1, num_labels) 的张量,它将充当查询(作者将其称为“解码器查询”,因为它用于解码器)。这个张量将在训练开始时随机初始化,并进行端到端训练。正如我们所看到的,我们只是提供一个虚拟的序列长度维度为 1。请注意,QKV 注意力层的输出始终与查询的形状相同——因此解码器将输出一个形状为 (batch_size, 1, num_labels) 的张量。然后,解码器简单地压缩此张量,使其形状为 (batch_size, num_labels),然后就得到了分类 logits1。
很棒,不是吗?Perceiver 作者还表明,对 Perceiver 进行掩码语言建模预训练非常简单,类似于 BERT。该模型也已在 HuggingFace Transformers 中提供,并命名为 `PerceiverForMaskedLM`。与 `PerceiverForSequenceClassification` 的唯一区别是,它不使用 `PerceiverClassificationDecoder` 作为解码器,而是使用 `PerceiverBasicDecoder`,将潜在变量解码为形状为 (batch_size, 2048, 1280) 的张量。在此之后,添加一个语言建模头,将其转换为形状为 (batch_size, 2048, vocab_size) 的张量。Perceiver 的词汇量只有 262,即 256 个 UTF-8 字节 ID 以及 6 个特殊标记。通过在英文维基百科和 C4 上预训练 Perceiver,作者表明在微调后,在 GLUE 上可以达到 81.8 的总分。
图像 Perceiver
现在我们已经了解了如何应用 Perceiver 进行文本分类,将 Perceiver 应用于图像分类也变得很简单。唯一的区别是我们将为模型提供一个不同的 `preprocessor`,它将嵌入图像 `inputs`。Perceiver 作者实际上尝试了 3 种不同的预处理方法
- 展平像素值,应用核大小为 1 的卷积层,并添加学习到的绝对 1D 位置嵌入。
- 展平像素值并添加固定的 2D 傅里叶位置嵌入。
- 应用 2D 卷积 + 最大池化层并添加固定的 2D 傅里叶位置嵌入。
这些都在 Transformers 库中实现,分别称为 `PerceiverForImageClassificationLearned`、`PerceiverForImageClassificationFourier` 和 `PerceiverForImageClassificationConvProcessing`。它们仅在 `PerceiverImagePreprocessor` 的配置上有所不同。让我们仔细看看 `PerceiverForImageClassificationLearned`。它初始化 `PerceiverModel` 如下
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverImagePreprocessor, PerceiverClassificationDecoder
class PerceiverForImageClassificationLearned(nn.Module):
def __init__(self, config):
super().__init__(config)
self.perceiver = PerceiverModel(
config,
input_preprocessor=PerceiverImagePreprocessor(
config,
prep_type="conv1x1",
spatial_downsample=1,
out_channels=256,
position_encoding_type="trainable",
concat_or_add_pos="concat",
project_pos_dim=256,
trainable_position_encoding_kwargs=dict(num_channels=256, index_dims=config.image_size ** 2),
),
decoder=PerceiverClassificationDecoder(
config,
num_channels=config.d_latents,
trainable_position_encoding_kwargs=dict(num_channels=config.d_latents, index_dims=1),
use_query_residual=True,
),
)
可以看出,`PerceiverImagePreprocessor` 以 `prep_type = "conv1x1"` 初始化,并且添加了可训练位置编码的参数。那么,这个预处理器究竟是如何工作的呢?假设我们向模型提供了一批图像。假设我们首先将图像中心裁剪到 224 分辨率并对颜色通道进行归一化,这样 `inputs` 的形状为 (batch_size, num_channels, height, width) = (batch_size, 3, 224, 224)。我们可以使用 `PerceiverImageProcessor` 来完成此操作,如下所示
from transformers import PerceiverImageProcessor
import requests
from PIL import Image
processor = PerceiverImageProcessor.from_pretrained("deepmind/vision-perceiver")
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(image, return_tensors="pt").pixel_values
`PerceiverImagePreprocessor`(使用上述设置)将首先应用一个核大小为 (1, 1) 的卷积层,将 `inputs` 转换为形状为 (batch_size, 256, 224, 224) 的张量——从而增加通道维度。然后它会将通道维度放在最后——所以现在我们有一个形状为 (batch_size, 224, 224, 256) 的张量。接下来,它会展平空间(高 + 宽)维度,使我们得到一个形状为 (batch_size, 50176, 256) 的张量。接下来,它将其与可训练的 1D 位置嵌入连接。由于位置嵌入的维度定义为 256(参见上面的 `num_channels` 参数),我们得到一个形状为 (batch_size, 50176, 512) 的张量。这个张量将用于与潜在变量进行交叉注意力操作。
作者对所有图像模型使用 512 个潜在变量,并将潜在变量的维度设置为 1024。因此,潜在变量的形状为 (batch_size, 512, 1024) - 假设我们添加了批处理维度。交叉注意力层接收形状为 (batch_size, 512, 1024) 的查询和形状为 (batch_size, 50176, 512) 的键+值作为输入,并生成一个与查询形状相同的张量,因此输出一个形状为 (batch_size, 512, 1024) 的新张量。接下来,重复应用一个包含 6 个自注意力层(每个自注意力层有 8 个注意力头)的块(8 次),以生成形状为 (batch_size, 512, 1024) 的潜在变量的最终隐藏状态。为了将这些转换为分类 logits,使用 `PerceiverClassificationDecoder`,其工作原理与文本分类的解码器类似:它将潜在变量用作键+值,并使用形状为 (batch_size, 1, num_labels) 的可训练位置嵌入作为查询。交叉注意力操作的输出是一个形状为 (batch_size, 1, num_labels) 的张量,将其压缩后得到形状为 (batch_size, num_labels) 的分类 logits。
Perceiver 作者表明,与主要为图像分类设计的模型(如 ResNet 或 ViT)相比,该模型能够取得出色的结果。在 JFT 上进行大规模预训练后,使用 conv+maxpool 预处理(`PerceiverForImageClassificationConvProcessing`)的模型在 ImageNet 上达到了 84.5 的 top-1 准确率。值得注意的是,`PerceiverForImageClassificationLearned`(仅使用 1D 完全学习的位置编码的模型)达到了 72.7 的 top-1 准确率,尽管它没有关于图像 2D 结构的特权信息。
光流 Perceiver
作者们表明,Perceiver 也很容易应用于光流,这是一个计算机视觉领域存在数十年的问题,具有许多更广泛的应用。有关光流的介绍,请参阅这篇博客文章。给定同一场景的两幅图像(例如,视频的两个连续帧),任务是估计第一幅图像中每个像素的二维位移。现有算法通常是手工设计且复杂,但使用 Perceiver,这变得相对简单。该模型已在 Transformers 库中实现,并作为 `PerceiverForOpticalFlow` 提供。其实现如下
from torch import nn
from transformers import PerceiverModel
from transformers.models.perceiver.modeling_perceiver import PerceiverImagePreprocessor, PerceiverOpticalFlowDecoder
class PerceiverForOpticalFlow(nn.Module):
def __init__(self, config):
super().__init__(config)
fourier_position_encoding_kwargs_preprocessor = dict(
num_bands=64,
max_resolution=config.train_size,
sine_only=False,
concat_pos=True,
)
fourier_position_encoding_kwargs_decoder = dict(
concat_pos=True, max_resolution=config.train_size, num_bands=64, sine_only=False
)
image_preprocessor = PerceiverImagePreprocessor(
config,
prep_type="patches",
spatial_downsample=1,
conv_after_patching=True,
conv_after_patching_in_channels=54,
temporal_downsample=2,
position_encoding_type="fourier",
# position_encoding_kwargs
fourier_position_encoding_kwargs=fourier_position_encoding_kwargs_preprocessor,
)
self.perceiver = PerceiverModel(
config,
input_preprocessor=image_preprocessor,
decoder=PerceiverOpticalFlowDecoder(
config,
num_channels=image_preprocessor.num_channels,
output_image_shape=config.train_size,
rescale_factor=100.0,
use_query_residual=False,
output_num_channels=2,
position_encoding_type="fourier",
fourier_position_encoding_kwargs=fourier_position_encoding_kwargs_decoder,
),
)
如您所见,`PerceiverImagePreprocessor` 用作预处理器(即,准备 2 幅图像以进行与潜在变量的交叉注意力操作),`PerceiverOpticalFlowDecoder` 用作解码器(即,将潜在变量的最终隐藏状态解码为实际预测流)。对于这 2 帧中的每一帧,作者提取每个像素周围的 3 x 3 图像块,从而为每个像素产生 3 x 3 x 3 = 27 个值(因为每个像素也有 3 个颜色通道)。作者使用 (368, 496) 的训练分辨率。如果将每个训练示例的 2 帧大小 (368, 496) 堆叠在一起,则模型的 `inputs` 形状为 (batch_size, 2, 27, 368, 496)。
预处理器(使用上述设置)将首先沿通道维度连接帧,得到形状为 (batch_size, 368, 496, 54) 的张量——假设还将通道维度移动到最后。作者在论文(第 8 页)中解释了为什么沿通道维度连接是有意义的。接下来,空间维度被展平,得到形状为 (batch_size, 368*496, 54) = (batch_size, 182528, 54) 的张量。然后,连接位置嵌入(每个位置嵌入的维度为 258),得到最终预处理后的输入形状为 (batch_size, 182528, 322)。这些将用于与潜在变量进行交叉注意力。
作者对光流模型使用 2048 个潜在变量(是的,2048 个!),每个潜在变量的维度为 512。因此,潜在变量的形状为 (batch_size, 2048, 512)。在交叉注意力之后,我们再次得到一个相同形状的张量(因为潜在变量充当查询)。接下来,应用一个包含 24 个自注意力层(每个自注意力层有 16 个注意力头)的单个块来更新潜在变量的嵌入。
为了将潜在变量的最终隐藏状态解码为实际预测流,`PerceiverOpticalFlowDecoder` 只是将形状为 (batch_size, 182528, 322) 的预处理输入用作交叉注意力操作的查询。接下来,将这些投影到形状为 (batch_size, 182528, 2) 的张量。最后,我们将其重新缩放并重塑回原始图像大小,以获得形状为 (batch_size, 368, 496, 2) 的预测流。作者声称,在 AutoFlow(一个包含 400,000 对带注释图像的大型合成数据集)上进行训练时,该模型在包括 Sintel 和 KITTI 在内的重要基准上取得了最先进的结果。
以下视频展示了两个示例上的预测流。

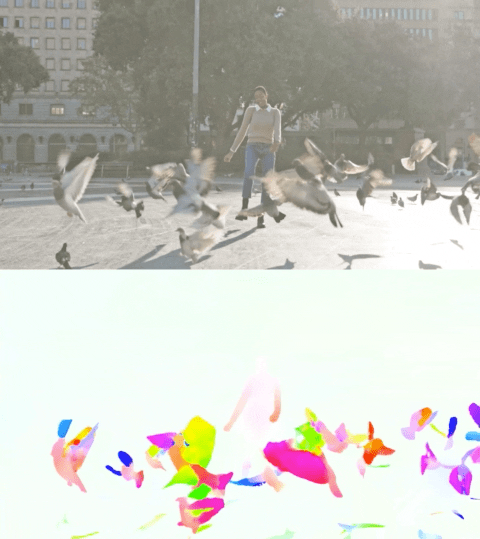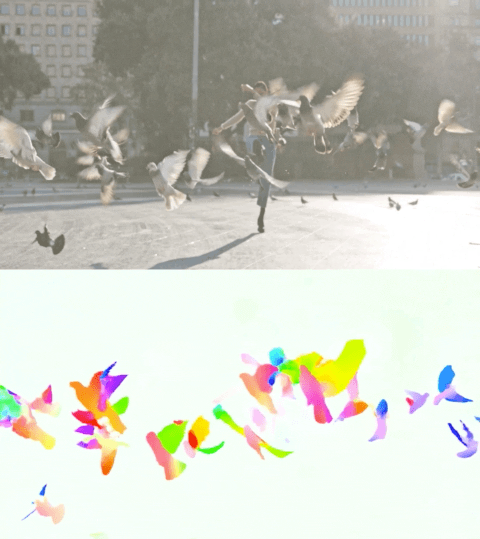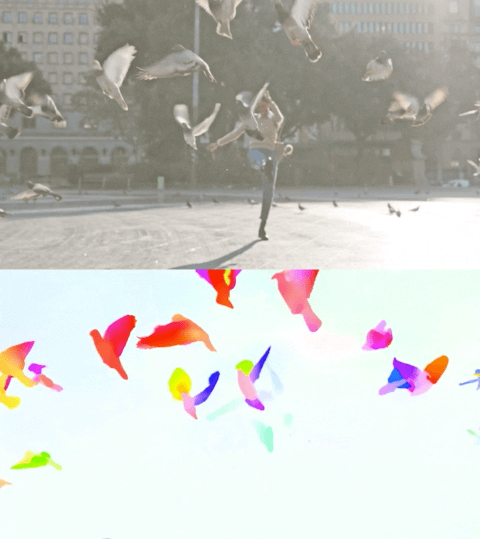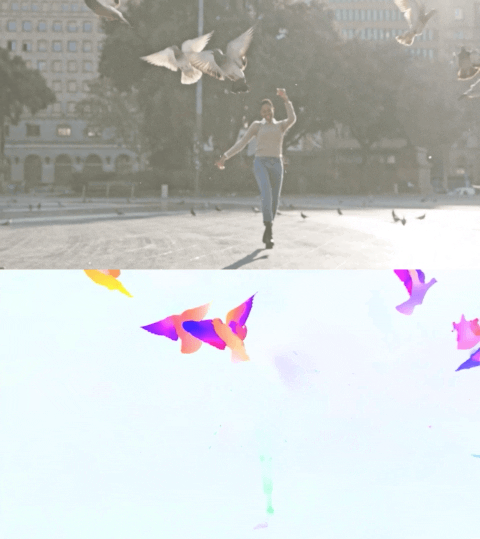
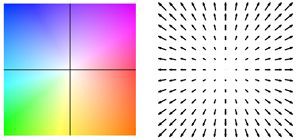
Perceiver IO 的光流估计。每个像素的颜色表示模型估计的运动方向和速度,如右侧图例所示。
多模态自编码 Perceiver
作者还使用 Perceiver 进行多模态自编码。多模态自编码的目标是学习一个模型,该模型能够在架构瓶颈存在的情况下准确地重建多模态输入。作者在 Kinetics-700 数据集上训练模型,其中每个示例都包含一系列图像(即帧)、音频和一个类别标签(700 个可能的标签之一)。该模型也已在 HuggingFace Transformers 中实现,并作为 `PerceiverForMultimodalAutoencoding` 提供。为简洁起见,我将省略定义此模型的代码,但重要的是要注意,它使用 `PerceiverMultimodalPreprocessor` 为模型准备 `inputs`。此预处理器将首先分别使用每种模态(图像、音频、标签)各自的预处理器。假设视频有 16 帧,分辨率为 224x224,以及 30,720 个音频样本,则模态预处理如下
- 使用 `PerceiverImagePreprocessor` 将图像(实际是一系列帧),形状为 (batch_size, 16, 3, 224, 224),转换为形状为 (batch_size, 50176, 243) 的张量。这是一个“空间到深度”的转换,之后连接固定的 2D 傅里叶位置嵌入。
- 音频的形状为 (batch_size, 30720, 1),使用 `PerceiverAudioPreprocessor`(它将固定的傅里叶位置嵌入连接到原始音频)将其转换为形状为 (batch_size, 1920, 401) 的张量。
- 类别标签的形状为 (batch_size, 700),使用 `PerceiverOneHotPreprocessor` 转换为形状为 (batch_size, 1, 700) 的张量。换句话说,此预处理器只是添加了一个虚拟的时间(索引)维度。请注意,在评估期间,将类别标签初始化为零张量,以便模型充当视频分类器。
接下来,`PerceiverMultimodalPreprocessor` 将使用模态特定的可训练嵌入对预处理后的模态进行填充,以实现在时间维度上的连接。在这种情况下,通道维度最高的模态是类别标签(它有 700 个通道)。作者强制最小填充大小为 4,因此每种模态都将填充到 704 个通道。然后可以连接它们,因此最终预处理后的输入是一个形状为 (batch_size, 50176 + 1920 + 1, 704) = (batch_size, 52097, 704) 的张量。
作者使用 784 个潜在变量,每个潜在变量的维度为 512。因此,潜在变量的形状为 (batch_size, 784, 512)。在交叉注意力之后,我们再次得到一个相同形状的张量(因为潜在变量充当查询)。接下来,应用一个包含 8 个自注意力层(每个自注意力层有 8 个注意力头)的单个块来更新潜在变量的嵌入。
接下来是 `PerceiverMultimodalDecoder`,它将首先为每个模态单独创建输出查询。然而,由于无法在单个前向传播中解码整个视频,作者转而分块自编码。每个块将对每个模态的某些索引维度进行子采样。假设我们将视频处理成 128 个块,那么解码器查询将按如下方式生成
- 对于图像模态,解码器查询的总大小为 16x3x224x224 = 802,816。然而,在自编码第一个块时,我们对前 802,816/128 = 6272 个值进行子采样。图像输出查询的形状为 (batch_size, 6272, 195)——195 来自于使用了固定的傅里叶位置嵌入。
- 对于音频模态,总输入有 30,720 个值。但是,我们只对前 30720/128/16 = 15 个值进行子采样。因此,音频查询的形状为 (batch_size, 15, 385)。这里,385 来自于使用了固定的傅里叶位置嵌入。
- 对于类别标签模态,不需要进行子采样。因此,子采样索引设置为 1。标签输出查询的形状为 (batch_size, 1, 1024)。查询使用可训练的位置嵌入(大小为 1024)。
与预处理器类似,`PerceiverMultimodalDecoder` 将不同模态填充到相同的通道数,以使模态特定查询可以在时间维度上进行连接。在这里,类别标签再次拥有最高的通道数 (1024),并且作者强制最小填充大小为 2,因此每个模态都将填充到 1026 个通道。连接后,最终解码器查询的形状为 (batch_size, 6272 + 15 + 1, 1026) = (batch_size, 6288, 1026)。这个张量在交叉注意力操作中生成查询,而潜在变量充当键和值。因此,交叉注意力操作的输出是形状为 (batch_size, 6288, 1026) 的张量。接下来,`PerceiverMultimodalDecoder` 使用一个线性层来减少输出通道,得到形状为 (batch_size, 6288, 512) 的张量。
最后,是 `PerceiverMultimodalPostprocessor`。该类对解码器输出进行后处理,以生成每种模态的实际重建。它首先根据不同的模态拆分解码器输出的时间维度:图像为 (batch_size, 6272, 512),音频为 (batch_size, 15, 512),类别标签为 (batch_size, 1, 512)。接下来,应用每种模态各自的后处理器
- 图像后处理器(在 Transformers 中称为 `PerceiverProjectionPostprocessor`)简单地将 (batch_size, 6272, 512) 张量转换为形状为 (batch_size, 6272, 3) 的张量——即它将最终维度投影到 RGB 值。
- `PerceiverAudioPostprocessor` 将 (batch_size, 15, 512) 张量转换为形状为 (batch_size, 240) 的张量。
- `PerceiverClassificationPostprocessor` 简单地获取第一个(也是唯一的)索引,得到形状为 (batch_size, 700) 的张量。
所以现在我们得到了包含图像、音频和类别标签模态重建的张量。由于我们分块自编码整个视频,因此需要连接每个块的重建,以获得整个视频的最终重建。下图显示了一个示例


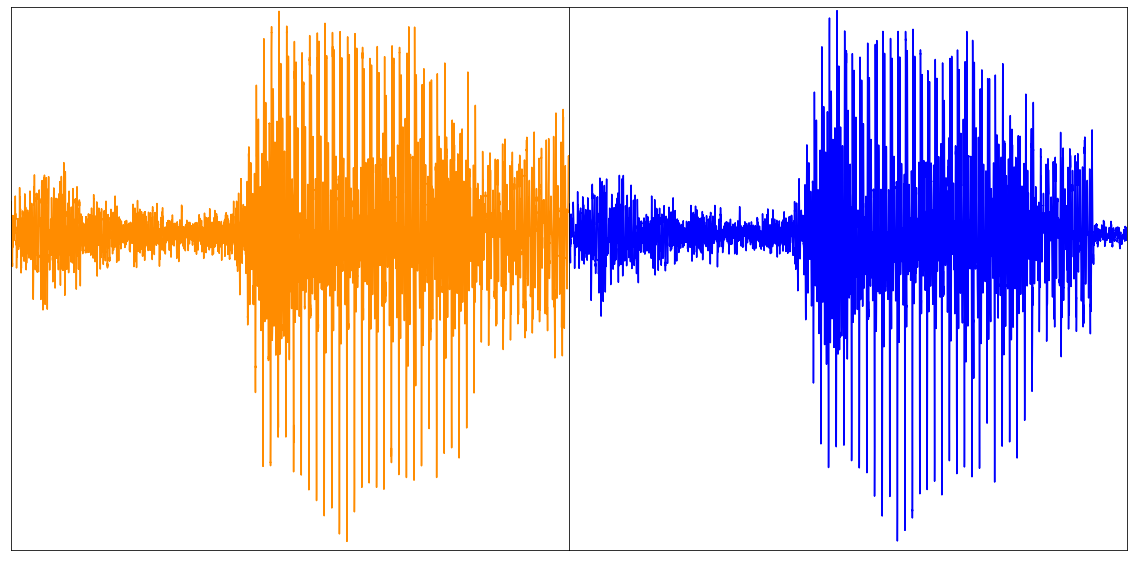
上图:原始视频(左),前 16 帧的重建(右)。视频取自 UCF101 数据集。下图:重建音频(取自论文)。

上述视频的预测标签前 5 名。通过掩码类别标签,Perceiver 变成了一个视频分类器。
通过这种方法,模型学习了 3 种模态的联合分布。作者指出,由于潜在变量在模态之间共享且未明确分配,因此每种模态的重建质量对其损失项的权重和其他训练超参数敏感。通过更强调分类准确性,他们能够在视频中达到 45% 的 top-1 准确性,同时保持 20.7 PSNR(峰值信噪比)。
Perceiver 的其他应用
请注意,Perceiver 的应用没有限制!在最初的 Perceiver 论文中,作者展示了该架构可用于处理 3D 点云——这是配备激光雷达传感器的自动驾驶汽车的常见问题。他们在 ModelNet40(一个包含 40 种物体类别的 3D 三角网格派生点云数据集)上训练了该模型。结果表明,该模型在测试集上达到了 85.7% 的 top-1 准确率,与 PointNet++(一个高度专业化、使用额外几何特征并执行更高级增强的模型)相媲美。
作者还用 Perceiver 替换了 AlphaStar(用于复杂游戏《星际争霸 II》的最先进强化学习系统)中的原始 Transformer。在不调整任何额外参数的情况下,作者观察到由此产生的代理达到了与原始 AlphaStar 代理相同的性能水平,在人类数据上进行行为克隆后,与精英机器人对战的胜率达到 87%。
重要的是,目前实现的模型(如 `PerceiverForImageClassificationLearned`、`PerceiverForOpticalFlow`)只是您可以使用 Perceiver 实现的示例。这些都是 `PerceiverModel` 的不同实例,只是使用了不同的预处理器和/或解码器(以及可选的后处理器,例如多模态自编码)。人们可以提出新的预处理器、解码器和后处理器,使模型解决不同的问题。例如,可以将 Perceiver 扩展到执行命名实体识别 (NER) 或问答(类似于 BERT),音频分类(类似于 Wav2Vec2)或目标检测(类似于 DETR)。
结论
在这篇博客文章中,我们回顾了 Perceiver IO 的架构,它是 Google Deepmind Perceiver 的一个扩展,并展示了其处理各种模态的通用性。Perceiver 的最大优势在于,自注意力机制的计算和内存需求不依赖于输入和输出的大小,因为大部分计算发生在潜在空间中(一组不太大的向量)。尽管其架构与任务无关,但该模型能够有效地处理语言、视觉、多模态数据和点云等模态。未来,同时训练一个单一的(共享的)Perceiver 编码器处理多种模态,并使用模态特定的预处理器和后处理器,可能会很有趣。正如 Karpathy 所说,这种架构很可能能够将所有模态统一到一个共享空间中,并配备一个编码器/解码器库。
说到库,该模型自今天起可在 HuggingFace Transformers 中使用。它将令人兴奋地看到人们用它构建什么,因为它的应用似乎无穷无尽!
附录
HuggingFace Transformers 中的实现基于原始的 JAX/Haiku 实现,可在此处找到。
HuggingFace Transformers 中 Perceiver IO 模型的文档可在此处找到。
关于多种模态 Perceiver 的教程笔记本可在此处找到。
脚注
1 请注意,在官方论文中,作者使用了一个两层 MLP 来生成输出 logits,这里为简洁起见省略了。 ↩






