将 fairseq wmt19 翻译系统移植到 transformers


Stas Bekman 的客座博文
本文旨在记录如何将fairseq wmt19 翻译系统移植到
transformers。
我正在寻找一些有趣的项目来做,Sam Shleifer 建议我尝试移植一个高质量的翻译器。
我阅读了这篇简短的论文:Facebook FAIR 的 WMT19 新闻翻译任务提交,该论文描述了原始系统,并决定尝试一下。
最初,我不知道如何着手这个复杂的项目,Sam 帮助我将其分解成更小的任务,这非常有帮助。
在移植过程中,我选择使用预训练的 `en-ru`/`ru-en` 模型,因为我懂这两种语言。使用 `de-en`/`en-de` 对会困难得多,因为我不懂德语,而在移植过程的高级阶段能够通过阅读和理解输出来评估翻译质量为我节省了大量时间。
此外,由于我最初使用 `en-ru`/`ru-en` 模型进行移植,我完全不知道 `de-en`/`en-de` 模型使用了合并词汇表,而前者使用了两个不同大小的独立词汇表。因此,一旦我完成了支持两个独立词汇表的更复杂的工作,使合并词汇表工作就变得微不足道了。
让我们作弊
第一步当然是作弊。既然可以花小力气,为什么要花大力气呢?所以我写了一个简短的笔记本,它通过几行代码提供了一个 fairseq 的代理,并模拟了 transformers API。
如果只需要基本的翻译功能,这已经足够了。但是,我们当然希望进行完整的移植,所以在取得这个小胜利之后,我着手处理更困难的事情。
准备工作
为了本文的方便,我们假设在 `~/porting` 目录下工作,所以让我们创建这个目录
mkdir ~/porting
cd ~/porting
我们需要为这项工作安装一些东西
# install fairseq
git clone https://github.com/pytorch/fairseq
cd fairseq
pip install -e .
# install mosesdecoder under fairseq
git clone https://github.com/moses-smt/mosesdecoder
# install fastBPE under fairseq
git clone git@github.com:glample/fastBPE.git
cd fastBPE; g++ -std=c++11 -pthread -O3 fastBPE/main.cc -IfastBPE -o fast; cd -
cd -
# install transformers
git clone https://github.com/huggingface/transformers/
pip install -e .[dev]
文件
简单概括一下,需要创建和编写以下文件
src/transformers/configuration_fsmt.py- 一个简短的配置类。src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py- 一个复杂的转换脚本。src/transformers/modeling_fsmt.py- 这是模型架构的实现。src/transformers/tokenization_fsmt.py- 分词器代码。tests/test_modeling_fsmt.py- 模型测试。tests/test_tokenization_fsmt.py- 分词器测试。docs/source/model_doc/fsmt.rst- 一个文档文件。
还有其他文件也需要修改,我们将在文章末尾讨论。
转换
移植过程中最重要的部分之一是创建一个脚本,该脚本将获取模型原始开发人员提供的所有可用源数据,其中包括一个包含预训练权重、模型和训练配置、字典和分词器支持文件的检查点,并将其转换为 transformers 支持的新模型文件集。您将在此处找到最终的转换脚本:src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py
我通过复制现有的转换脚本 `src/transformers/convert_bart_original_pytorch_checkpoint_to_pytorch.py` 来开始这个过程,清除了大部分内容,然后随着移植过程的进展逐渐添加了各个部分。
在开发过程中,我将所有代码都针对转换后的模型文件的本地副本进行测试,直到所有准备就绪,我才将文件上传到 🤗 s3,然后继续针对在线版本进行测试。
fairseq 模型及其支持文件
我们首先来看看 fairseq 预训练模型中包含哪些数据。
我们将使用方便的 `torch.hub` API,这使得部署提交到该 hub 的模型变得非常容易
import torch
torch.hub.load('pytorch/fairseq', 'transformer.wmt19.en-ru', checkpoint_file='model4.pt',
tokenizer='moses', bpe='fastbpe')
此代码下载预训练模型及其支持文件。我在 pytorch hub 上与fairseq 对应的页面上找到了此信息。
要查看下载文件中的内容,我们首先必须在 `~/.cache` 下找到正确的文件夹。
ls -1 ~/.cache/torch/hub/pytorch_fairseq/
显示
15bca559d0277eb5c17149cc7e808459c6e307e5dfbb296d0cf1cfe89bb665d7.ded47c1b3054e7b2d78c0b86297f36a170b7d2e7980d8c29003634eb58d973d9
15bca559d0277eb5c17149cc7e808459c6e307e5dfbb296d0cf1cfe89bb665d7.ded47c1b3054e7b2d78c0b86297f36a170b7d2e7980d8c29003634eb58d973d9.json
如果您曾将 `hub` 用于其他模型,那里可能有一个以上的条目。
让我们创建一个符号链接,以便将来可以轻松引用那个晦涩的缓存文件夹名称
ln -s /code/data/cache/torch/hub/pytorch_fairseq/15bca559d0277eb5c17149cc7e808459c6e307e5dfbb296d0cf1cfe89bb665d7.ded47c1b3054e7b2d78c0b86297f36a170b7d2e7980d8c29003634eb58d973d9 \
~/porting/pytorch_fairseq_model
注意:当您自己尝试时,路径可能会有所不同,因为模型的哈希值可能会改变。您将在 `~/.cache/torch/hub/pytorch_fairseq/` 中找到正确的路径。
如果我们查看该文件夹内部
ls -l ~/porting/pytorch_fairseq_model/
total 13646584
-rw-rw-r-- 1 stas stas 532048 Sep 8 21:29 bpecodes
-rw-rw-r-- 1 stas stas 351706 Sep 8 21:29 dict.en.txt
-rw-rw-r-- 1 stas stas 515506 Sep 8 21:29 dict.ru.txt
-rw-rw-r-- 1 stas stas 3493170533 Sep 8 21:28 model1.pt
-rw-rw-r-- 1 stas stas 3493170532 Sep 8 21:28 model2.pt
-rw-rw-r-- 1 stas stas 3493170374 Sep 8 21:28 model3.pt
-rw-rw-r-- 1 stas stas 3493170386 Sep 8 21:29 model4.pt
我们有
model*.pt- 4 个检查点(包含所有预训练权重和各种其他内容的 PyTorch `state_dict`)dict.*.txt- 源词典和目标词典bpecodes- 分词器使用的特殊映射文件
我们将在以下部分中研究这些文件。
翻译系统的工作原理
这里是对计算机如今如何翻译文本的简要介绍。
计算机无法阅读文本,只能处理数字。因此,在处理文本时,我们必须将一个或多个字母映射成数字,然后将这些数字交给计算机程序。程序完成后,它也会返回数字,我们需要将其转换回文本。
让我们从俄语和英语的两个句子开始,并为每个单词分配一个唯一的数字
я люблю следовательно я существую
10 11 12 10 13
I love therefore I am
20 21 22 20 23
以 10 开头的数字将俄语单词映射到唯一的数字。以 20 开头的数字对英语单词做同样的事情。如果您不懂俄语,您仍然可以看到单词 `я`(意思是“我”)在句子中重复了两次,并且它被分配了相同的数字 10。对于 `I`(20)也是如此,它也重复了两次。
翻译系统的工作阶段如下
1. [я люблю следовательно я существую] # tokenize sentence into words
2. [10 11 12 10 13] # look up words in the input dictionary and convert to ids
3. [black box] # machine learning system magic
4. [20 21 22 20 23] # look up numbers in the output dictionary and convert to text
5. [I love therefore I am] # detokenize the tokens back into a sentence
如果我们将前两个步骤和后两个步骤合并,我们得到 3 个阶段
- 编码输入:将输入文本分解成标记,为这些标记创建一个字典(词汇表),并将每个标记重新映射到该字典中的唯一 ID。
- 生成翻译:获取输入数字,通过预训练的机器学习模型运行它们,该模型预测最佳翻译,并返回输出数字。
- 解码输出:获取输出数字,在目标语言词典中查找它们,将它们转换回文本,最后将转换后的标记合并为翻译后的句子。
第二阶段可能会返回一个或几个可能的翻译。在后一种情况下,调用者可以选择最合适的结果。在本文中,我将提及束搜索算法,这是搜索多个可能结果的方法之一。束的大小指的是返回结果的数量。
如果只请求一个结果,模型将选择概率最高的一个。如果请求多个结果,它将按概率排序返回这些结果。
请注意,同样的想法适用于大多数自然语言处理任务,而不仅仅是翻译。
分词
早期的系统将句子分词成单词和标点符号。但是由于许多语言有数十万个单词,处理巨大的词汇表非常耗费资源,因为它大大增加了计算资源需求和完成任务所需的时间。
截至 2020 年,有相当多不同的分词方法,但大多数最新的方法都基于子词分词——也就是说,这些现代分词器不是将输入文本分解成单词,而是将其分解成单词片段和字母,使用某种训练来获得最优的分词。
让我们看看这种方法如何帮助减少内存和计算需求。如果我们有一个包含 6 个常用词的输入词汇表:go、going、speak、speaking、sleep、sleeping - 使用词级分词,我们最终得到 6 个标记。但是,如果我们将其分解为:go、go-ing、speak、speak-ing 等,那么我们的词汇表中只有 4 个标记:go、speak、sleep、ing。这个简单的改变带来了 33% 的改进!除了,子词分词器不使用语法规则,而是通过大量文本输入进行训练以找到这样的拆分。在这个例子中,我使用了一个简单的语法规则,因为它很容易理解。
这种方法的另一个重要优点是处理输入文本中不在我们词汇表中的单词。例如,假设我们的系统遇到单词 `grokking` (*),在它的词汇表中找不到。如果我们把它分成 `grokk` - `ing`,那么机器学习模型可能不知道如何处理单词的前半部分,但它得到了一个有用的见解,即 `ing` 表示进行时态,因此它能够生成更好的翻译。在这种情况下,分词器会将未知片段分成它知道的片段,在最坏的情况下,将其简化为单个字母。
- 脚注:`grok` 一词由罗伯特·A·海因莱因(Robert A. Heinlein)于 1961 年在其著作《异乡异客》("Stranger in a Strange Land")中创造:凭直觉或通过同理心理解(某事)。
关于为什么现代分词方法比简单的单词分词更优越,还有许多其他细微之处,本文将不予赘述。与刚刚演示的简单的“ing”结尾拆分示例相比,这些系统中的大多数在分词方式上都非常复杂,但原理是相似的。
分词器移植
第一步是移植分词器的编码器部分,将文本转换为 ID。解码器部分直到最后才需要。
fairseq 的分词器工作原理
让我们了解 `fairseq` 的分词器是如何工作的。
fairseq (*) 使用字节对编码(BPE)算法进行分词。
- 脚注:从现在开始,当我提到 `fairseq` 时,我指的是此特定模型实现 - `fairseq` 项目本身有数十种不同模型的不同实现。
让我们看看 BPE 是如何工作的
import torch
sentence = "Machine Learning is great"
checkpoint_file='model4.pt'
model = torch.hub.load('pytorch/fairseq', 'transformer.wmt19.en-ru', checkpoint_file=checkpoint_file, tokenizer='moses', bpe='fastbpe')
# encode step by step
tokens = model.tokenize(sentence)
print("tokenize ", tokens)
bpe = model.apply_bpe(tokens)
print("apply_bpe: ", bpe)
bin = model.binarize(bpe)
print("binarize: ", len(bin), bin)
# compare to model.encode - should give us the same output
expected = model.encode(sentence)
print("encode: ", len(expected), expected)
给我们
('tokenize ', 'Machine Learning is great')
('apply_bpe: ', 'Mach@@ ine Lear@@ ning is great')
('binarize: ', 7, tensor([10217, 1419, 3, 2515, 21, 1054, 2]))
('encode: ', 7, tensor([10217, 1419, 3, 2515, 21, 1054, 2]))
您可以看到 `model.encode` 执行 `tokenize+apply_bpe+binarize` - 因为我们得到相同的输出。
步骤是
tokenize:通常它会转义撇号并进行其他预处理,在这个例子中它只是返回了未经任何更改的输入句子apply_bpe:BPE 根据分词器提供的 `bpecodes` 文件将输入文本分割成单词和子词——我们得到 6 个 BPE 块binarize:这只是将前一步的 BPE 块重新映射到词汇表(也随模型下载)中对应的 ID
您可以参考此笔记本以查看更多详细信息。
现在是查看 `bpecodes` 文件内容的好时机。以下是文件的开头部分
$ head -15 ~/porting/pytorch_fairseq_model/bpecodes
e n</w> 1423551864
e r 1300703664
e r</w> 1142368899
i n 1130674201
c h 933581741
a n 845658658
t h 811639783
e n 780050874
u n 661783167
s t 592856434
e i 579569900
a r 494774817
a l 444331573
o r 439176406
th e</w> 432025210
[...]
此文件的顶部条目包含非常频繁的短单字母序列。正如我们稍后将看到的,底部包含最常见的多字母子词,甚至是完整的长单词。
特殊标记 `</w>` 表示单词的结尾。因此,在上面引用的几行中,我们发现
e n</w> 1423551864
e r</w> 1142368899
th e</w> 432025210
如果第二列不包含 `</w>`,则表示此段落在单词中间而不是结尾处。
最后一列声明了此 BPE 代码在训练期间遇到的次数。`bpecodes` 文件按此列排序——因此最常见的 BPE 代码位于顶部。
通过查看计数,我们现在知道,当此分词器进行训练时,它遇到了 1,423,551,864 个以 `en` 结尾的单词,1,142,368,899 个以 `er` 结尾的单词,以及 432,025,210 个以 `the` 结尾的单词。对于后者,它很可能指的是实际的单词 `the`,但也可能包括 `lathe`、`loathe`、`tithe` 等单词。
这些巨大的数字也向我们表明,这个分词器是在大量的文本上训练出来的!
如果我们查看同一文件的底部
$ tail -10 ~/porting/pytorch_fairseq_model/bpecodes
4 x 109019
F ische</w> 109018
sal aries</w> 109012
e kt 108978
ver gewal 108978
Sten cils</w> 108977
Freiwilli ge</w> 108969
doub les</w> 108965
po ckets</w> 108953
Gö tz</w> 108943
我们看到复杂的子词组合仍然非常常见,例如 `salaries` 出现了 109,012 次!所以它在 `bpecodes` 映射文件中拥有自己的专用条目。
apply_bpe 是如何工作的?它通过在 `bpecodes` 映射文件中查找各种字母组合,并在找到最长的匹配条目时使用它。
回到我们的例子,我们看到它将 `Machine` 分割成:`Mach@@` + `ine` - 让我们检查一下
$ grep -i ^mach ~/porting/pytorch_fairseq_model/bpecodes
mach ine</w> 463985
Mach t 376252
Mach ines</w> 374223
mach ines</w> 214050
Mach th 119438
您可以看到它包含 `mach ine</w>`。我们没有看到 `Mach ine` 在其中 - 所以它必须在正常大小写不匹配时处理小写查找。
现在检查一下:`Lear@@` + `ning`
$ grep -i ^lear ~/porting/pytorch_fairseq_model/bpecodes
lear n</w> 675290
lear ned</w> 505087
lear ning</w> 417623
我们发现 `learning</w>` 在那里(同样,大小写不一致)。
仔细想想,大小写对于分词可能并不重要,只要字典中存在 `Mach` / `Lear` 和 `mach` / `lear` 的唯一条目,其中涵盖每种大小写至关重要。
希望您现在能明白这是如何运作的。
一个令人困惑的地方是,如果您还记得 `apply_bpe` 的输出是
('apply_bpe: ', 6, ['Mach@@', 'ine', 'Lear@@', 'ning', 'is', 'great'])
它不是用 `</w>` 标记单词的结尾,而是保留原样,而是用 `@@` 标记不是结尾的单词。这可能是因为 `fairseq` 使用了 `fastBPE` 实现,所以它就是这样做的。我不得不改变它以适应 `transformers` 的实现,后者不使用 `fastBPE`。
最后要检查的是 BPE 代码到词汇表 ID 的重新映射。重复一下,我们有
('apply_bpe: ', 'Mach@@ ine Lear@@ ning is great')
('binarize: ', 7, tensor([10217, 1419, 3, 2515, 21, 1054, 2]))
2 - 最后一个标记 ID 是一个 `eos`(流结束)标记。它用于向模型指示输入的结束。
然后 `Mach@@` 被重新映射到 `10217`,`ine` 被重新映射到 `1419`。
让我们检查一下字典文件是否一致
$ grep ^Mach@@ ~/porting/pytorch_fairseq_model/dict.en.txt
Mach@@ 6410
$ grep "^ine " ~/porting/pytorch_fairseq_model/dict.en.txt
ine 88376
等等——这些不是我们 `binarize` 之后得到的 ID,它们应该是 `10217` 和 `1419`。
经过一番调查,我发现词汇表文件 ID 并非模型使用的 ID,并且在加载词汇表文件后,它们在内部被重新映射到新的 ID。幸运的是,我不需要弄清楚它是如何精确完成的。相反,我只是使用了 `fairseq.data.dictionary.Dictionary.load` 来加载字典 (*),它执行了所有重新映射,——然后我保存了最终的字典。我是通过使用调试器逐步调试 `fairseq` 代码来发现这个 `Dictionary` 类的。
- 脚注:我越是致力于移植模型和数据集,我就越意识到让原始代码为我所用,而不是尝试复制它,可以节省大量时间,最重要的是,这些代码已经经过测试——太容易遗漏一些东西,并在之后发现大问题!毕竟,最终,所有这些转换代码都不重要,因为只有它生成的数据将被 `transformers` 及其最终用户使用。
这是转换脚本的相关部分
from fairseq.data.dictionary import Dictionary
def rewrite_dict_keys(d):
# (1) remove word breaking symbol
# (2) add word ending symbol where the word is not broken up,
# e.g.: d = {'le@@': 5, 'tt@@': 6, 'er': 7} => {'le': 5, 'tt': 6, 'er</w>': 7}
d2 = dict((re.sub(r"@@$", "", k), v) if k.endswith("@@") else (re.sub(r"$", "</w>", k), v) for k, v in d.items())
keep_keys = "<s> <pad> </s> <unk>".split()
# restore the special tokens
for k in keep_keys:
del d2[f"{k}</w>"]
d2[k] = d[k] # restore
return d2
src_dict_file = os.path.join(fsmt_folder_path, f"dict.{src_lang}.txt")
src_dict = Dictionary.load(src_dict_file)
src_vocab = rewrite_dict_keys(src_dict.indices)
src_vocab_size = len(src_vocab)
src_vocab_file = os.path.join(pytorch_dump_folder_path, "vocab-src.json")
print(f"Generating {src_vocab_file}")
with open(src_vocab_file, "w", encoding="utf-8") as f:
f.write(json.dumps(src_vocab, ensure_ascii=False, indent=json_indent))
# we did the same for the target dict - omitted quoting it here
# and we also had to save `bpecodes`, it's called `merges.txt` in the transformers land
运行转换脚本后,让我们检查转换后的字典
$ grep '"Mach"' /code/huggingface/transformers-fair-wmt/data/wmt19-en-ru/vocab-src.json
"Mach": 10217,
$ grep '"ine</w>":' /code/huggingface/transformers-fair-wmt/data/wmt19-en-ru/vocab-src.json
"ine</w>": 1419,
我们有 `transformers` 版本的词汇表文件中的正确 ID。
如您所见,我还必须重写词汇表以匹配 `transformers` BPE 实现。我们必须更改
['Mach@@', 'ine', 'Lear@@', 'ning', 'is', 'great']
到
['Mach', 'ine</w>', 'Lear', 'ning</w>', 'is</w>', 'great</w>']
我们不是标记作为单词片段的块,除了最后一个片段,而是标记作为最终片段的片段或单词。可以轻松地从一种编码样式转换为另一种,然后转换回来。
这成功完成了模型文件第一部分的移植。您可以在此处查看最终的代码版本。
如果您想深入了解,此笔记本中还有更多细节。
将分词器的编码器移植到 transformers
transformers 无法依赖fastBPE,因为后者需要 C 编译器,但幸运的是,有人已经在tokenization_xlm.py中实现了相同的 Python 版本。
所以我只需将其复制到 `src/transformers/tokenization_fsmt.py` 并重命名类名
cp tokenization_xlm.py tokenization_fsmt.py
perl -pi -e 's|XLM|FSMT|ig; s|xlm|fsmt|g;' tokenization_fsmt.py
只需进行极少的更改,我就拥有了一个可用的分词器编码器部分。有很多代码不适用于我需要支持的语言,因此我删除了那些代码。
由于我需要两个不同的词汇表,而不是一个,因此在分词器和所有其他地方,我不得不修改代码以支持两者。例如,我不得不重写超类的方法
def get_vocab(self) -> Dict[str, int]:
return self.get_src_vocab()
@property
def vocab_size(self) -> int:
return self.src_vocab_size
由于 `fairseq` 未使用 `bos`(流开始)标记,我还必须更改代码以不包含这些标记 (*)
- return bos + token_ids_0 + sep
- return bos + token_ids_0 + sep + token_ids_1 + sep
+ return token_ids_0 + sep
+ return token_ids_0 + sep + token_ids_1 + sep
- 脚注:这是 `diff(1)` 的输出,它显示了两个代码块之间的差异——以 `-` 开头的行表示已删除的内容,以 `+` 开头的行表示已添加的内容。
fairseq 还在转义字符并执行激进的破折号分割,所以我也必须改变
- [...].tokenize(text, return_str=False, escape=False)
+ [...].tokenize(text, return_str=False, escape=True, aggressive_dash_splits=True)
如果您正在跟随,并想查看我对原始 `tokenization_xlm.py` 所做的所有更改,您可以执行以下操作
cp tokenization_xlm.py tokenization_orig.py
perl -pi -e 's|XLM|FSMT|g; s|xlm|fsmt|g;' tokenization_orig.py
diff -u tokenization_orig.py tokenization_fsmt.py | less
只需确保您在 fsmt 发布前后签出存储库,因为这两个文件自那时以来可能已经有所不同。
最后阶段是运行一系列输入并确保移植后的分词器产生与原始分词器相同的 ID。您可以在此笔记本中看到这一点,我反复运行该笔记本,试图弄清楚如何使输出匹配。
大部分移植过程都是这样进行的:我选择一个小功能,用 `fairseq` 方式运行它,获取输出;然后用 `transformers` 代码做同样的事情,尝试让输出匹配——反复调整代码直到匹配,然后尝试不同类型的输入,确保它产生相同的输出,以此类推,直到所有输入都产生匹配的输出。
移植核心翻译功能
在分词器移植取得相对较快的成功之后(显然,这要归功于大部分代码已经存在),下一个阶段要复杂得多。这就是 `generate()` 函数,它接受输入 ID,将其通过模型运行并返回输出 ID。
我必须将其分解为多个子任务。我必须
- 移植模型权重。
- 使 `generate()` 在单个束(即只返回一个结果)下工作。
- 然后是多个束(即返回多个结果)。
我首先研究了哪些现有架构与我的需求最接近。BART 是最接近的,所以我继续做了
cp modeling_bart.py modeling_fsmt.py
perl -pi -e 's|Bart|FSMT|ig; s|bart|fsmt|g;' modeling_fsmt.py
这是我的起点,我需要调整它以与 `fairseq` 提供的模型权重一起工作。
移植权重和配置
我做的第一件事是查看公开共享的检查点中的内容。此笔记本展示了我当时所做的事情。
我发现里面有 4 个检查点。我不知道该如何处理,所以我开始做一份更简单的工作,只使用第一个检查点。后来我发现 `fairseq` 使用所有 4 个检查点组成一个集成模型来获得最佳预测,而 `transformers` 目前不支持该功能。当移植完成并且我能够测量性能分数时,我发现 `model4.pt` 检查点提供了最佳分数。但在移植过程中,性能并不重要。由于我只使用了一个检查点,因此当我比较输出时,`fairseq` 也只使用一个相同的检查点,这一点至关重要。
为此,我使用了略有不同的 `fairseq` API
from fairseq import hub_utils
#checkpoint_file = 'model1.pt:model2.pt:model3.pt:model4.pt'
checkpoint_file = 'model1.pt'
model_name_or_path = 'transformer.wmt19.ru-en'
data_name_or_path = '.'
cls = fairseq.model_parallel.models.transformer.ModelParallelTransformerModel
models = cls.hub_models()
kwargs = {'bpe': 'fastbpe', 'tokenizer': 'moses'}
ru2en = hub_utils.from_pretrained(
model_name_or_path,
checkpoint_file,
data_name_or_path,
archive_map=models,
**kwargs
)
首先我看了模型
print(ru2en["models"][0])
TransformerModel(
(encoder): TransformerEncoder(
(dropout_module): FairseqDropout()
(embed_tokens): Embedding(31232, 1024, padding_idx=1)
(embed_positions): SinusoidalPositionalEmbedding()
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(dropout_module): FairseqDropout()
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
[...]
# the full output is in the notebook
看起来与 BART 的架构非常相似,只有几个层略有不同——有些被添加,有些被移除。所以这是个好消息,因为我不需要重新发明轮子,而只需调整一个运行良好的设计。
请注意,在上面的代码示例中,我没有使用 `torch.load()` 来加载 `state_dict`。这是我最初所做的,结果非常令人困惑——我缺少 `self_attn.(k|q|v)_proj` 权重,而只有一个 `self_attn.in_proj`。当我尝试使用 `fairseq` API 加载模型时,它解决了问题——显然那个模型很旧,并且使用了旧的架构,该架构为 `k/q/v` 使用了一组权重,而较新的架构则将它们分开。当 `fairseq` 加载这个旧模型时,它会重写权重以匹配现代架构。
我还使用此笔记本直观地比较了 `state_dict`。在该笔记本中,您还将看到 `fairseq` 在 `last_optimizer_state` 中获取了 2.2GB 的数据,我们可以安全地忽略它,并将最终模型大小减少 3 倍。
在转换脚本中,我还必须删除一些 `state_dict` 键,这些键我不会使用,例如 `model.encoder.version`、`model.model` 以及其他一些键。
接下来我们看看配置参数
args = dict(vars(ru2en["args"]))
pprint(args)
'activation_dropout': 0.0,
'activation_fn': 'relu',
'adam_betas': '(0.9, 0.98)',
'adam_eps': 1e-08,
'adaptive_input': False,
'adaptive_softmax_cutoff': None,
'adaptive_softmax_dropout': 0,
'arch': 'transformer_wmt_en_de_big',
'attention_dropout': 0.1,
'bpe': 'fastbpe',
[... full output is in the notebook ...]
好的,我们将复制这些来配置模型。我必须重命名一些参数名称,只要 `transformers` 对相应的配置设置使用不同的名称。因此,配置的重新映射如下所示
model_conf = {
"architectures": ["FSMTForConditionalGeneration"],
"model_type": "fsmt",
"activation_dropout": args["activation_dropout"],
"activation_function": "relu",
"attention_dropout": args["attention_dropout"],
"d_model": args["decoder_embed_dim"],
"dropout": args["dropout"],
"init_std": 0.02,
"max_position_embeddings": args["max_source_positions"],
"num_hidden_layers": args["encoder_layers"],
"src_vocab_size": src_vocab_size,
"tgt_vocab_size": tgt_vocab_size,
"langs": [src_lang, tgt_lang],
[...]
"bos_token_id": 0,
"pad_token_id": 1,
"eos_token_id": 2,
"is_encoder_decoder": True,
"scale_embedding": not args["no_scale_embedding"],
"tie_word_embeddings": args["share_all_embeddings"],
}
剩下要做的就是将配置保存到 `config.json` 中,并将新的 `state_dict` 导出到 `pytorch.dump` 中。
print(f"Generating {fsmt_tokenizer_config_file}")
with open(fsmt_tokenizer_config_file, "w", encoding="utf-8") as f:
f.write(json.dumps(tokenizer_conf, ensure_ascii=False, indent=json_indent))
[...]
print(f"Generating {pytorch_weights_dump_path}")
torch.save(model_state_dict, pytorch_weights_dump_path)
我们已经移植了配置和模型的 `state_dict` - 太棒了!
您可以在此处找到最终的转换代码。
移植架构代码
现在我们已经移植了模型权重和模型配置,我们只需调整从 `modeling_bart.py` 复制的代码,使其与 `fairseq` 的功能匹配。
第一步是获取一个句子,对其进行编码,然后将其输入到 `generate` 函数中——对于 `fairseq` 和 `transformers` 都是如此。
经过几次非常失败的尝试(*),我很快意识到,以当前的复杂程度,使用 `print` 作为调试方法是行不通的,基本的 `pdb` 调试器也一样。为了高效,并且能够观察多个变量并拥有代码评估监视器,我需要一个严肃的可视化调试器。我花了一天时间尝试各种 Python 调试器,直到我尝试了 `pycharm`,才意识到它正是我需要的工具。这是我第一次使用 `pycharm`,但我很快就弄清楚了如何使用它,因为它非常直观。
- 脚注:模型用俄语生成了“nononono”——这很公平也很搞笑!
随着时间的推移,我在 `pycharm` 中发现了一个很棒的功能,它允许我按功能对断点进行分组,我可以根据我正在调试的内容打开和关闭整个组。例如,在这里我关闭了与束搜索相关的断点,并打开了解码器断点
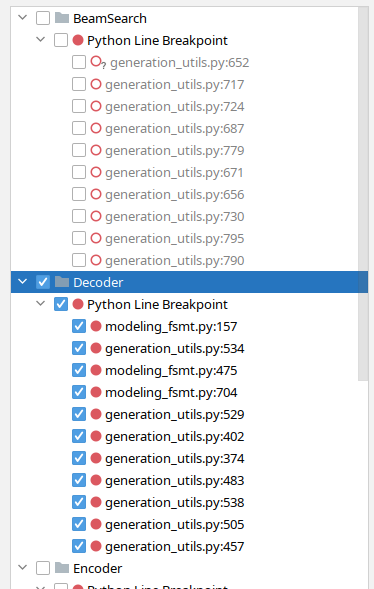
现在我已经使用这个调试器移植 FSMT,我知道如果我用 pdb 做同样的事情,我将花费很多倍的时间——我甚至可能已经放弃了。
我从两个脚本开始
(先不带 `decode` 部分)
同时运行两者,在两侧用调试器逐步执行并比较相关变量的值——直到我发现第一个分歧。然后我研究了代码,在 `modeling_fsmt.py` 中进行了调整,重新启动了调试器,快速跳到分歧点并重新检查了输出。这个循环重复了多次,直到输出匹配。
我首先要做的改变是移除 `fairseq` 未使用的一些层,然后添加它正在使用的一些新层。其余的主要是弄清楚何时切换到 `src_vocab_size`,何时切换到 `tgt_vocab_size`——因为在核心模块中它只是 `vocab_size`,这并没有考虑到可能有两个字典的模型。最后,我发现一些超参数配置不同,因此也更改了这些配置。
我首先对简单的无束搜索执行此过程,一旦输出 100% 匹配,我就会对更复杂的束搜索重复此过程。例如,在这里我发现 `fairseq` 使用了相当于 `early_stopping=True` 的功能,而 `transformers` 默认将其设置为 `False`。当启用提前停止时,一旦候选数量达到束大小,它就会停止寻找新的候选;而当禁用时,算法只有在找不到比现有候选更高概率的候选时才会停止搜索。`fairseq` 论文提到使用了 50 的巨大束大小,这弥补了使用提前停止的不足。
分词器解码器移植
一旦我移植的 `generate` 函数产生的结果与 `fairseq` 的 `generate` 函数非常相似,接下来我需要完成将输出解码为人类可读文本的最后阶段。这使我能够用我的眼睛进行快速比较和翻译质量——这是我无法用输出 ID 做到的。
与编码过程类似,这个过程是反向进行的。
步骤是
- 将输出 ID 转换为文本字符串
- 移除 BPE 编码
- 去分词——处理转义字符等
在这里进行更多调试后,我不得不更改处理 BPE 的方式,使其与 `tokenization_xlm.py` 中的原始方法不同,并且还要将输出通过 `moses` 去分词器运行。
def convert_tokens_to_string(self, tokens):
""" Converts a sequence of tokens (string) in a single string. """
- out_string = "".join(tokens).replace("</w>", " ").strip()
- return out_string
+ # remove BPE
+ tokens = [t.replace(" ", "").replace("</w>", " ") for t in tokens]
+ tokens = "".join(tokens).split()
+ # detokenize
+ text = self.moses_detokenize(tokens, self.tgt_lang)
+ return text
一切顺利。
将模型上传到 s3
一旦转换脚本完成了所有所需文件到 `transformers` 的移植,我将模型上传到我的 🤗 s3 帐户
cd data
transformers-cli upload -y wmt19-ru-en
transformers-cli upload -y wmt19-en-ru
transformers-cli upload -y wmt19-de-en
transformers-cli upload -y wmt19-en-de
cd -
在测试期间,我一直使用我的 🤗 s3 账户,一旦我的 PR 完成所有更改并准备合并,我在 PR 中请求将模型移动到 `facebook` 组织账户,因为这些模型属于那里。
有几次我只需要更新配置文件,不想重新上传大模型,所以我写了这个小脚本,它可以生成正确的上传命令,否则这些命令太长,容易出错
perl -le 'for $f (@ARGV) { print qq[transformers-cli upload -y $_/$f --filename $_/$f] \
for map { "wmt19-$_" } ("en-ru", "ru-en", "de-en", "en-de")}' \
vocab-src.json vocab-tgt.json tokenizer_config.json config.json
# add/remove files as needed
例如,如果我只需要更新所有 `config.json` 文件,上面的脚本就给我提供了一个方便的复制粘贴功能
transformers-cli upload -y wmt19-en-ru/config.json --filename wmt19-en-ru/config.json
transformers-cli upload -y wmt19-ru-en/config.json --filename wmt19-ru-en/config.json
transformers-cli upload -y wmt19-de-en/config.json --filename wmt19-de-en/config.json
transformers-cli upload -y wmt19-en-de/config.json --filename wmt19-en-de/config.json
上传完成后,这些模型即可通过 (*) 访问
tokenizer = FSMTTokenizer.from_pretrained("stas/wmt19-en-ru")
- 脚注:`stas` 是我在https://huggingface.co上的用户名。
在进行此次上传之前,我必须使用模型文件所在的本地路径,例如
tokenizer = FSMTTokenizer.from_pretrained("/code/huggingface/transformers-fair-wmt/data/wmt19-en-ru")
重要提示:如果您更新模型文件并重新上传,您必须注意由于 CDN 缓存,上传的模型可能会在上传后长达 24 小时内无法使用 - 即将交付旧的缓存模型。因此,提前开始使用新模型的唯一方法是:
- 将其下载到本地路径,并将该路径作为参数传递给 `from_pretrained()`。
- 或者在接下来的 24 小时内 everywhere 使用:`from_pretrained(..., use_cdn=False)` - 仅仅一次是不够的。
AutoConfig, AutoTokenizer 等
我需要做的另一项更改是将新移植的模型插入到自动化模型 `transformers` 系统中。这主要用于模型网站,用于加载模型配置、分词器和主类,而无需提供任何特定的类名。例如,在 `FSMT` 的情况下,可以执行以下操作
from transformers import AutoTokenizer, AutoModelWithLMHead
mname = "facebook/wmt19-en-ru"
tokenizer = AutoTokenizer.from_pretrained(mname)
model = AutoModelWithLMHead.from_pretrained(mname)
有 3 个 `*auto*` 文件包含启用此功能的映射
-rw-rw-r-- 1 stas stas 16K Sep 23 13:53 src/transformers/configuration_auto.py
-rw-rw-r-- 1 stas stas 65K Sep 23 13:53 src/transformers/modeling_auto.py
-rw-rw-r-- 1 stas stas 13K Sep 23 13:53 src/transformers/tokenization_auto.py
然后还有管道,它们完全向最终用户隐藏了所有 NLP 的复杂性,并提供了非常简单的 API,只需选择一个模型并将其用于手头的任务。例如,以下是如何使用 `pipeline` 执行摘要任务
summarizer = pipeline("summarization", model="t5-base", tokenizer="t5-base")
summary = summarizer("Some long document here", min_length=5, max_length=20)
print(summary)
撰写本文时,翻译管道仍在开发中,请关注此文档,了解何时支持翻译(目前仅支持少数特定模型/语言)。
最后,还有 `src/transformers/__init__.py` 需要编辑,这样就可以执行
from transformers import FSMTTokenizer, FSMTForConditionalGeneration
而不是
from transformers.tokenization_fsmt import FSMTTokenizer
from transformers.modeling_fsmt import FSMTForConditionalGeneration
但两者都可以。
为了找到我需要插入 FSMT 的所有位置,我模仿了 `BartConfig`、`BartForConditionalGeneration` 和 `BartTokenizer`。我只是 `grep` 搜索了包含它们的那些文件,并为 `FSMTConfig`、`FSMTForConditionalGeneration` 和 `FSMTTokenizer` 插入了相应的条目。
$ egrep -l "(BartConfig|BartForConditionalGeneration|BartTokenizer)" src/transformers/*.py \
| egrep -v "(marian|bart|pegasus|rag|fsmt)"
src/transformers/configuration_auto.py
src/transformers/generation_utils.py
src/transformers/__init__.py
src/transformers/modeling_auto.py
src/transformers/pipelines.py
src/transformers/tokenization_auto.py
在 `grep` 搜索中,我排除了也包含这些类的文件。
手动测试
在此之前,我主要使用自己的脚本进行测试。
一旦翻译器工作正常,我转换了反向的 `ru-en` 模型,然后编写了两个复述脚本
它将源语言中的一个句子翻译成另一种语言,然后将翻译结果再翻译回原始语言。由于不同语言表达相似事物的方式不同,这个过程通常会导致复述结果。
借助这些脚本,我发现了去分词器的一些问题,通过调试器逐步调试并使 fsmt 脚本产生与 fairseq 版本相同的结果。
在这个阶段,无束搜索(no-beam search)基本能产生相同的结果,但束搜索(beam search)仍然存在一些差异。为了识别特殊情况,我编写了一个 fsmt-port-validate.py 脚本,该脚本使用 `sacrebleu` 测试数据作为输入,并通过 `fairseq` 和 `transformers` 翻译运行该数据,只报告不匹配项。它很快识别出一些剩余的问题,通过观察模式,我也能够解决这些问题。
移植其他模型
接下来我着手移植 `en-de` 和 `de-en` 模型。
我惊讶地发现这些模型的构建方式并不相同。每个模型都有一个合并字典,所以有一瞬间我感到沮丧,因为我以为现在又必须进行巨大的更改来支持它。但是,我不需要做任何更改,因为合并字典无需任何更改即可适应。我只是使用了两个相同的字典——一个作为源,另一个作为它的副本作为目标。
我编写了另一个脚本来测试所有移植模型的A基本功能:fsmt-test-all.py。
测试覆盖率
下一步非常重要——我需要为移植后的模型准备广泛的测试。
在 `transformers` 测试套件中,大多数处理大型模型的测试都被标记为 `@slow`,并且它们通常不会在 CI(持续集成)上运行,因为它们确实很慢。因此,我还需要创建一个微型模型,它与正常的预训练模型具有相同的结构,但它必须非常小,并且可以具有随机权重。然后,这个微型模型可以用于测试移植的功能。它不能用于质量测试,因为它只有很少的权重,因此无法真正训练以执行任何实际操作。fsmt-make-tiny-model.py 创建了这样一个微型模型。生成模型及其所有字典和配置文件的大小仅为 3MB。我使用 `transformers-cli upload` 将其上传到 `s3`,现在我可以在测试套件中使用它了。
就像代码一样,我从复制 `tests/test_modeling_bart.py` 开始,并将其转换为使用 `FSMT`,然后调整它以与新模型一起工作。
然后我将我用于手动测试的几个脚本转换成单元测试——这很简单。
transformers 包含大量每个模型都会运行的通用测试——我不得不做一些额外的调整,以使这些测试适用于 `FSMT`(主要是为了适应双字典设置),而且我不得不重写一些测试,由于此模型的独特性,这些测试无法运行,因此跳过了它们。您可以在此处查看结果。
我添加了一个额外的测试,它执行一个轻量级的 BLEU 评估——我只对 4 个模型中的每个模型使用了 8 个文本输入,并测量了它们的 BLEU 分数。这是测试和生成数据的脚本。
SinusoidalPositionalEmbedding
fairseq 使用的 SinusoidalPositionalEmbedding 实现与 transformers 使用的略有不同。最初我复制了 fairseq 的实现。但在尝试使测试套件工作时,我无法通过 torchscript 测试。SinusoidalPositionalEmbedding 的编写方式使其不会成为 state_dict 的一部分,也不会随模型权重保存——该类生成的所有权重都是确定性的,并且未经过训练。fairseq 使用了一个技巧,通过不将其权重作为参数或缓冲区,然后在 forward 期间将权重切换到正确的设备来使其透明地工作。torchscript 对此不太满意,因为它希望在第一次 forward 调用之前所有权重都在正确的设备上。
我不得不重写实现,将其转换为正常的 `nn.Embedding` 子类,然后添加功能,在 `save_pretrained()` 期间不保存这些权重,并且在 `from_pretrained()` 加载 `state_dict` 时,如果找不到这些权重,也不会抱怨。
评估
我知道移植后的模型在大量文本的手动测试中表现相当不错,但我不知道移植后的模型与原始模型相比表现如何。所以是时候进行评估了。
对于翻译任务,BLEU 分数被用作评估指标。`transformers` 有一个脚本 run_eval.py 来执行评估。
以下是 `ru-en` 语对的评估
export PAIR=ru-en
export MODEL=facebook/wmt19-$PAIR
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=64
export NUM_BEAMS=5
export LENGTH_PENALTY=1.1
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py $MODEL \
$DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target \
--score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS \
--length_penalty $LENGTH_PENALTY --info $MODEL --dump-args
运行了几分钟并返回
{'bleu': 39.0498, 'n_obs': 2000, 'runtime': 184, 'seconds_per_sample': 0.092,
'num_beams': 5, 'length_penalty': 1.1, 'info': 'ru-en'}
您可以看到 BLEU 分数是 `39.0498`,并且它使用 `sacrebleu` 提供的 `wmt19` 数据集,评估了 2000 个测试输入。
请记住,我无法使用模型集成,所以我接下来需要找到表现最佳的检查点。为此,我编写了一个脚本 fsmt-bleu-eval-each-chkpt.py,它转换每个检查点,运行评估脚本并报告最佳的一个。结果我得知 `model4.pt` 在四个可用检查点中提供了最佳性能。
我没有得到与原始论文中报告的相同的 BLEU 分数,所以我接下来需要确保我们使用相同的工具比较相同的数据。通过在 `fairseq` 问题中提问,我获得了 `fairseq` 开发人员用来获取 BLEU 分数的代码——你可以在这里找到它。但是,唉,他们的方法使用了未公开的重排序方法。此外,他们评估的是去分词之前的输出,而不是实际的输出,这显然得分更高。总而言之——我们没有以相同的方式得分 (*)。
- 脚注:论文《关于 BLEU 分数报告清晰度的呼吁》邀请开发者开始使用相同的方法计算指标(tl;dr:使用 `sacrebleu`)。
目前,这个移植模型在 BLEU 分数上略低于原始模型,因为没有使用模型集成,但在使用相同的测量方法之前,无法准确判断差异。
移植新模型
上传了 4 个 fairseq 模型这里后,有人建议移植 3 个 wmt16 和 2 个 wmt19 AllenAI 模型(Jungo Kasai 等人)。移植过程非常顺利,我只需要弄清楚如何将所有源文件组合在一起,因为它们分散在几个不相关的存档中。一旦完成,转换就没有任何问题。
我发现的唯一问题是移植后 BLEU 分数低于原始模型。这些模型的创建者 Jungo Kasai 非常乐于助人,他建议使用自定义超参数 `length_penalty=0.6`,一旦我将其插入,我便获得了更好的结果。
这一发现促使我编写了一个新脚本:run_eval_search.py,该脚本可用于搜索各种超参数以获得最佳 BLEU 分数。以下是其用法示例
# search space
export PAIR=ru-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=32
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py stas/wmt19-$PAIR \
$DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target \
--score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation \
--search="num_beams=5:8:11:15 length_penalty=0.6:0.7:0.8:0.9:1.0:1.1 early_stopping=true:false"
在这里,它搜索 `num_beams`、`length_penalty` 和 `early_stopping` 的所有可能组合。
执行完毕后,它报告
bleu | num_beams | length_penalty | early_stopping
----- | --------- | -------------- | --------------
39.20 | 15 | 1.1 | 0
39.13 | 11 | 1.1 | 0
39.05 | 5 | 1.1 | 0
39.05 | 8 | 1.1 | 0
39.03 | 15 | 1.0 | 0
39.00 | 11 | 1.0 | 0
38.93 | 8 | 1.0 | 0
38.92 | 15 | 1.1 | 1
[...]
您可以看到,在 `transformers` 的情况下,`early_stopping=False` 表现更好(`fairseq` 使用的是 `early_stopping=True` 的等效功能)。
所以对于这 5 个新模型,我使用这个脚本来寻找最佳默认参数,并在转换模型时使用了它们。用户仍然可以在调用 `generate()` 时覆盖这些参数,但为什么不提供最佳默认值呢?
您可以在此处找到 5 个已移植的 AllenAI 模型。
更多脚本
由于每一组移植的模型都有其自身的细微差别,我为它们分别编写了专用脚本,以便将来可以轻松地重新构建,或创建新的脚本来转换新模型。您可以在这里找到所有转换、评估和其他脚本。
模型卡
另一件重要的事情是,仅仅移植模型并使其可用是不够的。还需要提供如何使用它、超参数的细微差别、数据集来源、评估指标等信息。所有这些都通过创建模型卡来完成,模型卡只是一个以一些元数据开头的README.md文件,这些元数据由模型网站使用,然后是所有可以共享的有用信息。
例如,我们来看看facebook/wmt19-en-ru模型卡。这是它的顶部
---
language:
- en
- ru
thumbnail:
tags:
- translation
- wmt19
- facebook
license: apache-2.0
datasets:
- wmt19
metrics:
- bleu
---
# FSMT
## Model description
This is a ported version of
[...]
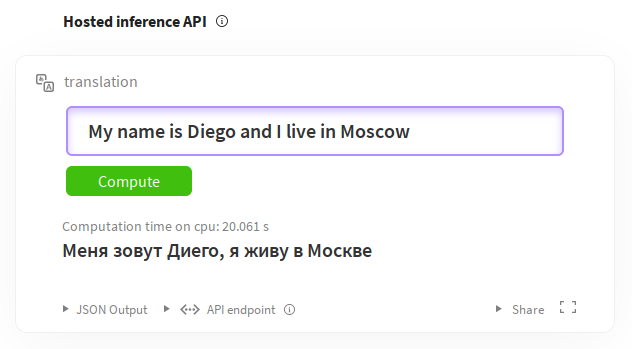
如您所见,我们定义了语言、标签、许可证、数据集和指标。有关编写这些内容的完整指南,请参阅模型共享和上传。其余部分是描述模型及其细微差别的 Markdown 文档。您还可以通过推理小部件直接从模型页面试用模型。例如,对于英语到俄语的翻译:https://huggingface.co/facebook/wmt19-en-ru?text=My+name+is+Diego+and+I+live+in+Moscow。
文档
最后,需要添加文档。
幸运的是,大部分文档都是从模块文件中的文档字符串自动生成的。
和以前一样,我复制了docs/source/model_doc/bart.rst并将其修改为FSMT。准备好后,我通过在docs/source/index.rst中添加fsmt条目来链接它
我使用了
make docs
来测试新添加的文档是否正确构建。运行该目标后我需要检查的文件是docs/_build/html/model_doc/fsmt.html——我只是在浏览器中加载并验证它是否正确渲染。
这是最终的源文档docs/source/model_doc/fsmt.rst及其渲染版本。
提交 PR 的时候了
当我感觉我的工作基本完成时,我准备提交我的 PR。
由于这项工作涉及许多 git 提交,我希望进行一次干净的 PR,因此我使用了以下技术,将所有提交压缩到一个新分支中。这样,如果我以后想访问任何一个提交,所有初始提交都还在。
我正在开发的分支名为fair-wmt,我将从中提交 PR 的新分支名为fair-wmt-clean,所以我做了以下操作:
git checkout master
git checkout -b fair-wmt-clean
git merge --squash fair-wmt
git commit -m "Ready for PR"
git push origin fair-wmt-clean
然后我去了 GitHub,基于fair-wmt-clean分支提交了这个 PR。
它经历了两个星期的多轮反馈、修改和更多类似循环。最终,一切都令人满意,PR 被合并了。
在这个过程中,我发现了一些问题,增加了新的测试,改进了文档等等,所以时间花得很值。
随后,我在改进和重构了一些功能、添加了各种构建脚本、模型卡等之后,又提交了一些 PR。
由于我移植的模型属于facebook和allenai组织,我不得不请 Sam 将这些模型文件从我的s3帐户移动到相应的组织。
结束语
虽然我无法移植模型集成,因为
transformers不支持它,但好的一面是最终的facebook/wmt19-*模型下载大小为 1.1GB,而不是原始的 13GB。出于某种原因,原始模型中包含了优化器状态,因此对于那些只想下载模型并直接用于文本翻译的人来说,这增加了近 9GB(4x2.2GB)的无用负担。虽然移植工作一开始看起来非常有挑战性,因为我既不了解
transformers的内部机制,也不了解fairseq的内部机制,但回顾起来,它最终并没有那么困难。这主要是因为transformers的各个部分已经为我提供了大部分组件——我只需要找到我需要的部件,主要借鉴其他模型,然后对它们进行调整以实现我需要的功能。代码和测试都是如此。换句话说——移植是困难的——但如果我必须从头开始编写所有内容,那将困难得多。而且找到合适的部件也不容易。
致谢
有Sam Shleifer指导我完成这个过程,对我来说帮助极大,这不仅归功于他的技术支持,更重要的是,在我遇到困难时,他给予了我启发和鼓励。
PR 的合并过程耗费了两周时间才被接受。在此阶段,除了 Sam,Lysandre Debut和Sylvain Gugger通过他们的见解和建议做出了巨大贡献,我将这些整合到了代码库中。
我感谢所有为
transformers代码库做出贡献的人,这为我的工作铺平了道路。
备注
在 Jupyter Notebook 中自动打印所有内容
我的 Jupyter Notebook 配置为自动打印所有表达式,因此我无需显式地print()它们。默认行为是只打印每个单元格的最后一个表达式。所以,如果您阅读我的 Notebook 中的输出,它们可能与您自己运行时的输出不同,除非您有相同的设置。
您可以通过在~/.ipython/profile_default/ipython_config.py中添加以下内容(如果没有则创建)来在 Jupyter Notebook 设置中启用“打印所有”功能
c = get_config()
# Run all nodes interactively
c.InteractiveShell.ast_node_interactivity = "all"
# restore to the original behavior
# c.InteractiveShell.ast_node_interactivity = "last_expr"
并重新启动您的 Jupyter Notebook 服务器。
指向 GitHub 文件版本的链接
为了确保所有链接在您阅读本文很久之后仍然有效,这些链接指向代码的特定 SHA 版本,而不一定是最新版本。这样,即使文件被重命名或删除,您仍然可以找到本文所引用的代码。如果您想确保查看最新版本的代码,请将链接中的哈希代码替换为master。例如,一个链接
https://github.com/huggingface/transformers/blob/129fdae04033fe4adfe013b734deaec6ec34ae2e/src/transformers/modeling_fsmt.py
变成
https://github.com/huggingface/transformers/blob/master/src/transformers/convert_fsmt_original_pytorch_checkpoint_to_pytorch.py
感谢您的阅读!

