推出 Agent Leaderboard v2:AI 智能体的企业级基准测试


2025 年 7 月 17 日 • 作者:Pratik Bhavsar, Galileo Labs
TL;DR: v2 的新功能

Klarna 决定用 AI 取代 700 名客服代表,结果适得其反,现在他们不得不重新雇佣人类来弥补不足。他们省了钱,但客户体验却下降了。如果有一种方法能在切换之前就发现这些故障呢?
这正是 Agent Leaderboard v2 旨在解决的问题。我们不仅仅测试智能体是否能调用正确的工具,而是让 AI 经历涵盖五个行业的真实企业场景,其中包括多轮对话和复杂的决策。
截至 2025 年 7 月 17 日的关键结果
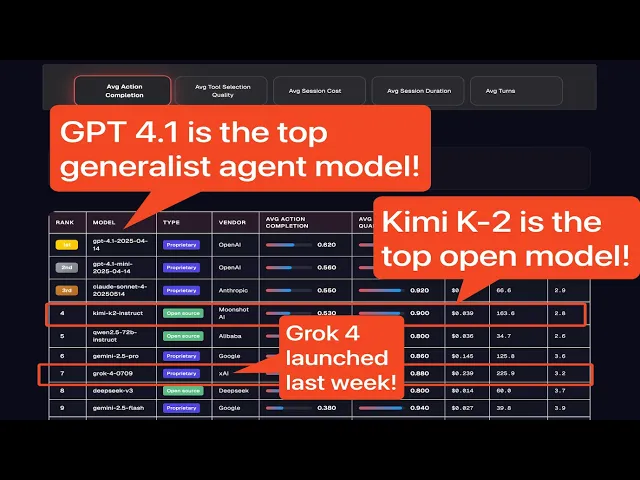
- GPT-4.1 以所有领域平均行动完成度 (AC) 62% 的分数领先。
- Gemini-2.5-flash 在工具选择方面表现出色(94% TSQ),但在任务完成度方面表现不佳(38% AC)。
- GPT-4.1-mini 每次会话成本为 0.014 美元,而 GPT-4.1 为 0.068 美元,性价比极高。
- 性能因行业而异——没有一个模型在所有领域都占据主导地位。
- Grok 4 在任何领域或指标中均未获得榜首。
- 推理模型在整体行动完成度方面普遍落后于非推理模型。
- Kimi 的 K2(新的开源选手)以 0.53 的 AC 分数和 0.90 的 TSQ 领先开源模型,每次会话成本仅为 0.039 美元。
我们衡量什么决定了 AI 的发展方向。通过我们的 Agent Leaderboard 计划,我们将重点重新放回到真实工作发生的地方。“人类最后的考试”基准测试很酷,但我们仍然需要涵盖基础知识。
需要新的基准测试
Agent Leaderboard v1 为我们评估 AI 智能体奠定了基础,测试了 30 多个大型语言模型(LLM),涵盖 14 个数据集。但随着模型质量的提高,在基本工具调用方面的高性能已成为常态,并出现了一些挑战。
- 分数饱和:模型分数普遍高于 90%,使得性能区分变得困难。
- 潜在的基准测试数据泄露:公开基准测试可能已被纳入模型训练,模糊了真正的泛化能力和记忆能力之间的界限。
- 场景复杂性不足:虽然 v1 涵盖了广泛的领域,但大多数场景都是静态的,上下文关联性差,模糊情况少,且未能充分反映真实企业部署的复杂性。
- 静态数据集的局限性:真实世界的任务是动态且多轮的。静态的、一次性评估无法捕捉扩展和演变交互的复杂性。
- 没有领域隔离:缺乏真正的领域特定数据集,使得企业难以理解模型在特定智能体用例中的优势。
这是我与 Latent Space 的采访,我在其中谈到了 v1 的局限性和我的经验教训。
这些局限性意味着 v1 排行榜已不足以指导企业,这些企业需要能够应对其行业中客户交互的真实复杂性和多样性的智能体。当数百个模型在简单的 API 调用测试中得分超过 80% 时,你如何知道哪一个能够处理你真实的客户对话?我们如何才能获得真实、多轮、领域特定的评估?
推出 Agent Leaderboard v2:专为企业打造
Agent Leaderboard v2 是一个飞跃,在发布时模拟了五个关键行业的真实支持代理:银行、医疗保健、投资、电信和保险。
每个领域都有 100 个合成场景,旨在反映真实对话的模糊性、上下文依赖性和不可预测性。每个场景都包含先前的聊天上下文、不断变化的用户需求、缺失或不相关的工具以及条件请求,所有这些都由代表真实用户类型的合成角色驱动。智能体必须在多轮对话中协调行动、提前规划、适应新信息,并使用一套领域特定的工具,就像在真实的企业部署中一样。
每个场景都包含
真实世界的复杂性
- 每次对话包含 5-8 个相互关联的用户目标
- 具有上下文依赖性的多轮对话
- 具有不同沟通风格的动态用户角色
- 反映实际企业 API 的领域特定工具
- 反映生产挑战的边缘案例和模糊性
示例:银行场景
“我需要报告我的白金信用卡丢失,验证我 15 日的抵押贷款还款,设置自动账单支付,在巴黎的酒店附近找一个分行,获取欧元汇率,并在周四去欧洲之前配置旅行警报。”
这不仅仅是调用正确的 API。智能体必须
- 在 6 个以上不同请求之间保持上下文
- 处理时间敏感的协调
- 导航工具依赖关系
- 为每个目标提供明确的确认
v1 是关于检查模型是否使用正确的参数调用 API,而 v2 是关于真实世界的有效性:智能体是否能每次在各种现实情况下为用户完成任务?
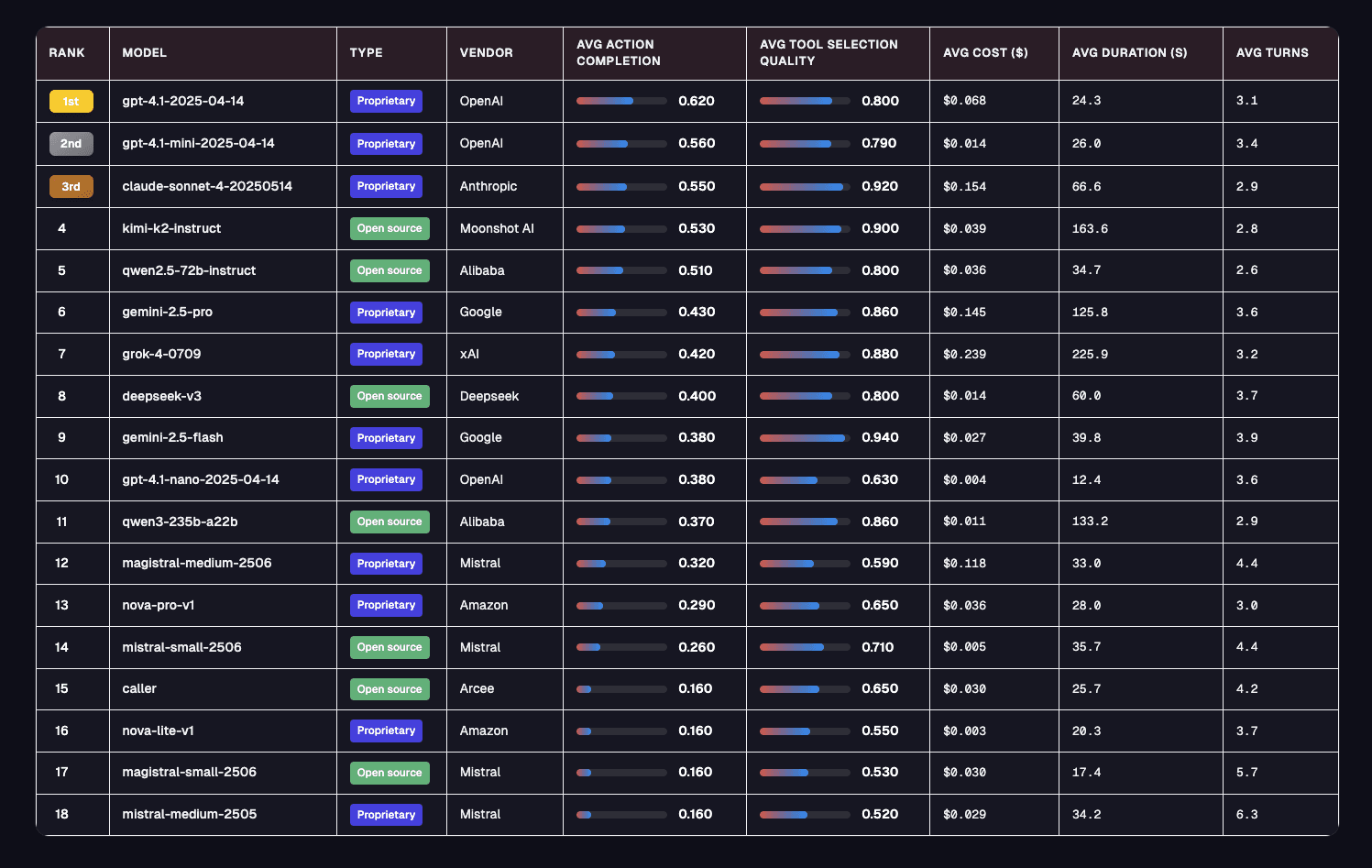
这是我们根据行动完成度进行的排名。GPT-4.1 位居榜首。

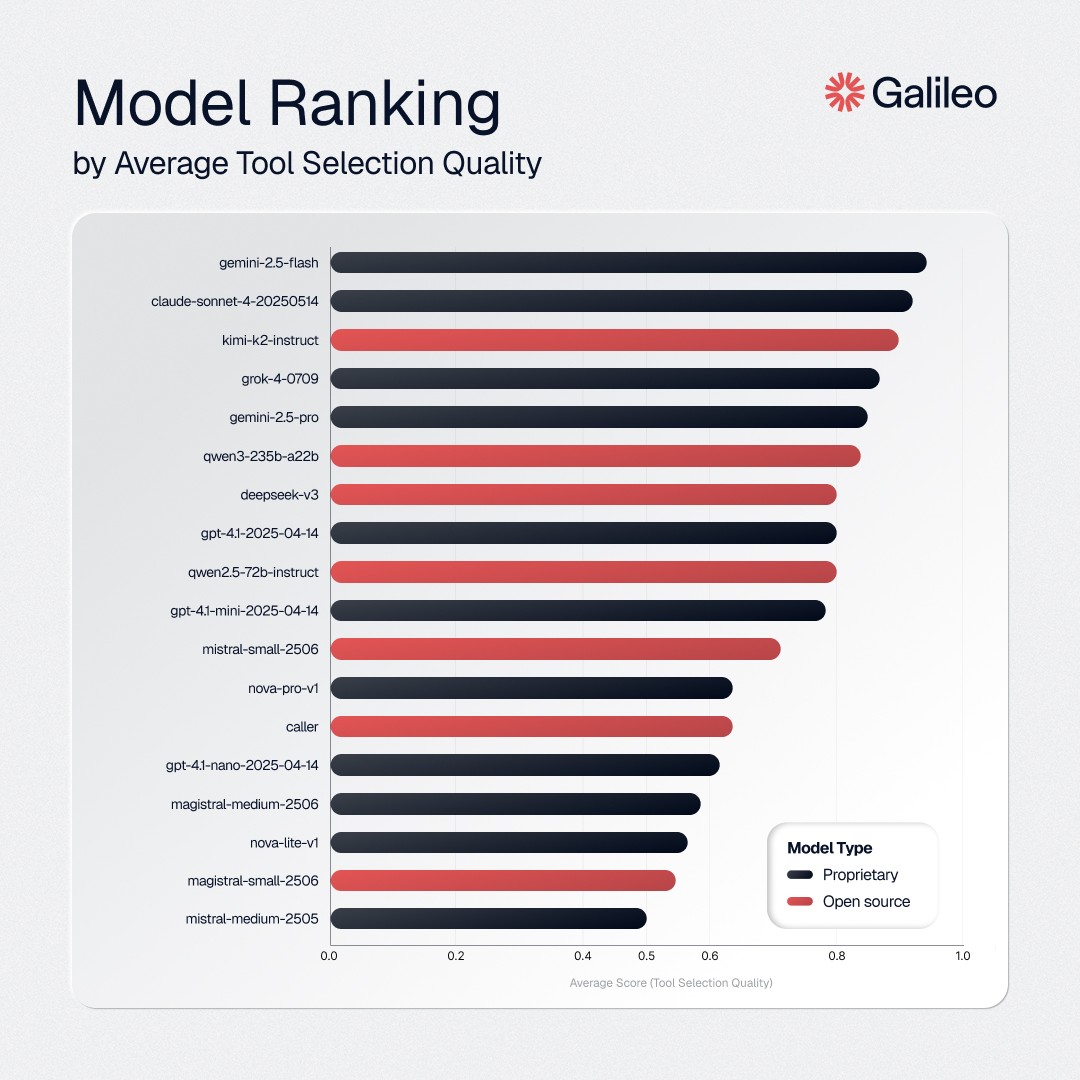
这是我们根据工具选择质量进行的排名。Gemini 2.5 Flash 位居榜首。
关键见解
以下是我们截至 2025 年 7 月 17 日的模型和总体见解
模型见解
- GPT-4.1 以所有领域平均 AC 分数 62% 领先。
- Gemini-2.5-flash 在工具选择方面表现出色(94% TSQ),但在任务完成度方面表现不佳(38% AC)。
- GPT-4.1-mini 每次会话成本为 0.014 美元,而 GPT-4.1 为 0.068 美元,性价比极高。
- 性能因行业而异——没有一个模型在所有领域都占据主导地位。
- Grok 4 在任何领域或指标中均未获得榜首。
- 推理模型在整体行动完成度方面普遍落后于非推理模型。
- Kimi 的 K2(新的开源选手)以 0.53 的 AC 分数和 0.90 的 TSQ 领先开源模型,每次会话成本仅为 0.039 美元。

衡量智能体的性能
我们以行动完成度(Action Completion)和工具选择质量(Tool Selection Quality)这两个互补的支柱为中心,它们共同捕捉智能体实现了什么以及如何实现。
行动完成度
我们的行动完成度指标是 v2 的核心:智能体是否完全实现了每个用户目标,为每个请求提供了明确的答案或确认?这不仅仅是勾选工具调用。智能体必须在多达八个相互依赖的用户请求中跟踪上下文。

行动完成度反映了智能体完成用户请求所有方面的能力,而不仅仅是进行正确的工具调用或提供部分答案。高行动完成度分数意味着助手提供了清晰、完整和准确的结果,无论是回答问题、确认任务成功还是总结工具结果。
简而言之,智能体是否真的解决了用户的问题?
工具选择质量
工具调用的复杂性远远超出了简单的 API 调用。当智能体遇到查询时,它首先必须确定是否需要使用工具。信息可能已经存在于对话历史中,使得工具调用变得多余。另外,可用工具可能不足或与任务无关,这需要智能体承认局限性,而不是强制使用不适当的工具。
各种场景挑战着 AI 智能体在工具使用方面做出适当决策的能力。工具选择质量(TSQ)衡量 AI 智能体选择和使用外部工具以完成用户请求的准确性。完美的 TSQ 分数意味着智能体不仅选择了正确的工具,而且正确提供了所有必需参数,同时避免了不必要或错误的调用。在智能体系统中,调用错误的 API 或传递错误参数等细微错误可能导致不正确或有害的结果,因此 TSQ 精确地揭示了工具使用出错的位置和方式。
我们通过将每个工具调用发送给专门的 LLM 评估器(Anthropic 的 Claude)并带有推理提示来计算 TSQ。

工具选择动态
- 工具选择的精确度和召回率
- 处理可选工具与必需工具
参数处理
- 提供正确的参数名称和值
- 根据规范格式化参数
顺序决策

这些复杂性说明了为什么 TSQ 应该被视为对智能体决策能力的多方面评估。
让我们了解我们是如何构建数据集来运行模拟以评估大型语言模型的。
构建多领域合成数据集
创建一个真正反映企业 AI 需求的基准,不仅需要规模,还需要深度和真实性。对于 Agent Leaderboard v2,我们从头开始构建了一个多领域数据集,重点关注五个关键领域:银行、投资、医疗保健、电信和保险。每个领域都需要一套独特的工具、角色和场景来捕捉该领域特有的复杂性。以下是我们构建此数据集的方法。
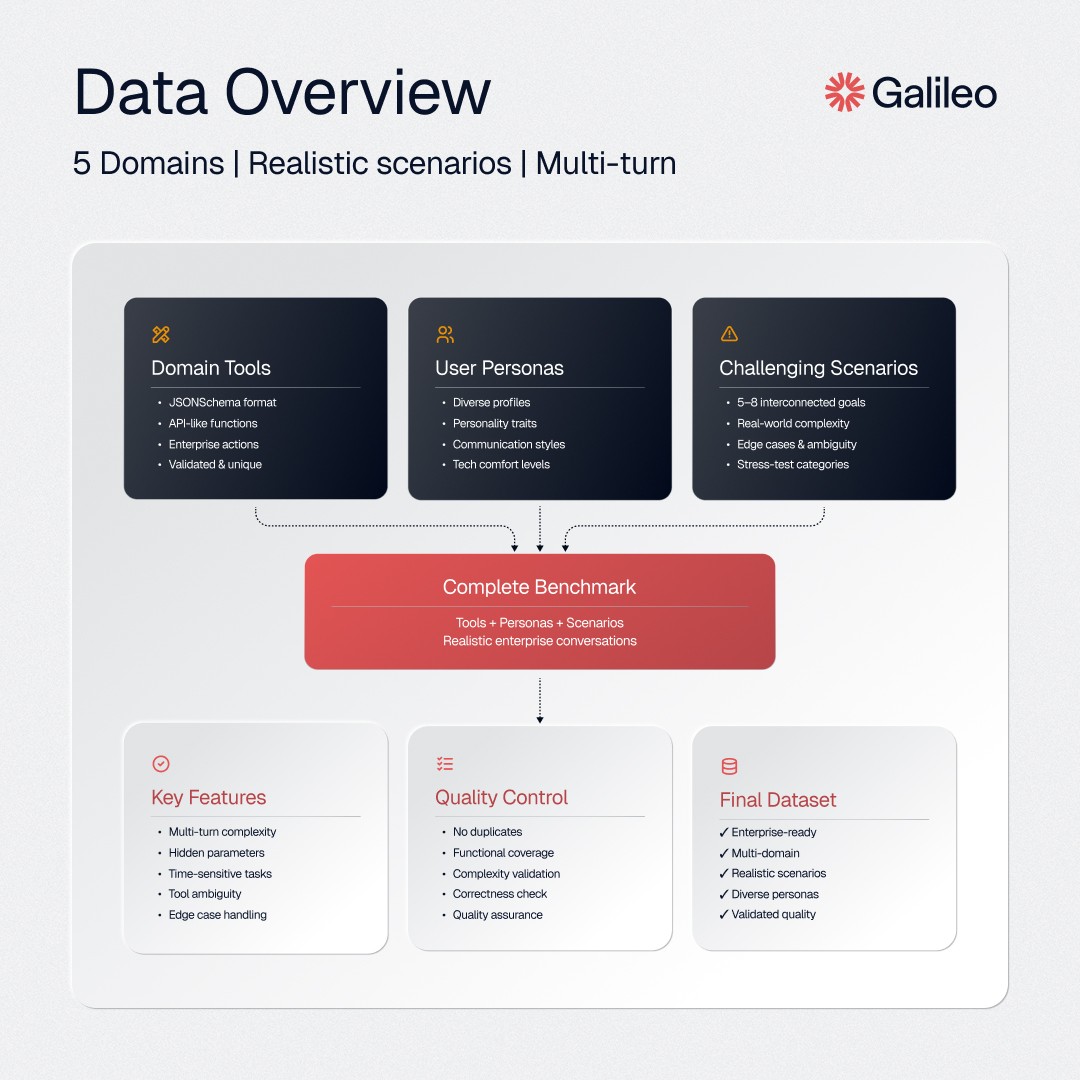
步骤 1:生成领域特定工具
我们数据集的基础是一套为每个领域量身定制的合成工具。这些工具代表了智能体在协助真实用户时可能需要的操作、服务或数据操作。我们使用 Anthropic 的 Claude,通过结构化提示,以严格的 JSON 模式格式生成每个工具。每个工具定义都指定了其参数、必需字段、预期输入类型及其响应结构。
我们仔细验证了每个生成的工具,以确保没有重复项,并保证每个领域的功能覆盖。这一步骤确保模拟环境丰富且真实,为智能体提供了一个反映企业系统中实际 API 和服务的强大工具包。
步骤 2:设计合成角色
在确定可用工具之后,我们专注于用户本身。我们开发了一套多样化的合成角色,以反映企业可能服务的客户或利益相关者的范围。每个角色都由其姓名、年龄、职业、个性特征、语气和偏好的沟通详细程度定义。我们提示 Claude 创建不同年龄组、职业、态度和技术舒适度的角色。验证过程检查每个角色是否独特且合理。
这种多样性是模拟真实交互的关键,并确保智能体不仅在技术技能方面得到评估,而且在适应性和以用户为中心的行为方面也得到评估。
步骤 3:设计具有挑战性的场景
最后一步是数据集的生命所在。我们为每个领域生成了结合可用工具和角色的聊天场景。每个场景都旨在通过在一个对话中完成 5 到 8 个相互关联的用户目标来挑战智能体。场景经过精心设计,以引入真实世界的复杂性:隐藏参数、时间敏感请求、相互依赖的任务、工具歧义和潜在矛盾。我们针对一系列故障模式,例如不完整完成、工具选择错误或边缘案例处理。
每个场景还属于特定的压力测试类别,例如自适应工具使用或范围管理,以确保涵盖不同的智能体能力。每个场景在纳入基准测试之前都经过复杂性和正确性验证。
为什么采用合成方法?
我们选择合成数据方法有几个重要原因。首先,生成式 AI 允许我们创建无限种类的工具、角色和场景,而不会泄露任何真实客户数据或专有信息。这消除了数据泄露或隐私问题的风险。
其次,合成方法使我们能够精确控制每个基准测试的难度、结构和覆盖范围。我们可以系统地探测已知的模型弱点,注入边缘案例,并确信任何模型都没有“见过”这些数据。
最后,通过从头设计每个组件——工具、角色和场景,我们创建了一个完全隔离的、领域特定的测试平台,为所有模型提供公平、可重复和透明的评估。
结果
结果是一个高度真实、多领域的数据集,反映了企业 AI 智能体在现实世界中面临的挑战。它使我们能够超越标准的基本工具使用进行基准测试,并探索智能体在动态和复杂条件下实现真实用户目标的可靠性、适应性和能力。
AI 智能体评估模拟

一旦为每个领域创建了工具、角色和场景,我们就会使用强大的模拟管道来评估不同 AI 模型在真实、多轮对话中的表现。此模拟是更新版 Agent Leaderboard 的核心,旨在模拟生产环境中企业智能体所面临的挑战。
步骤 1:实验编排
该过程始于选择要测试的模型、领域和场景类别。对于每个独特的组合,系统都会启动并行实验。这种并行化使我们能够有效地对数百个领域特定场景中的许多模型进行基准测试。
步骤 2:模拟引擎
每个实验都模拟三个关键组件之间的真实聊天会话
AI 智能体(LLM):这是正在测试的模型。它充当助手,尝试理解用户的请求,选择正确的工具并完成每个目标。
用户模拟器:一个生成式 AI 系统扮演用户的角色,使用先前创建的角色和场景。它发送初始消息并继续对话,根据智能体的响应和工具输出进行调整。
工具模拟器:此模块响应智能体的工具调用,使用预定义的工具模式生成逼真的输出。智能体从不与真实 API 或敏感数据交互——所有内容都模拟以符合领域规范。
模拟循环从用户的第一个消息开始。智能体读取对话历史,决定下一步做什么,并可能调用一个或多个工具。每个工具调用都会被模拟,并且响应会反馈到对话中。用户模拟器继续对话,推动智能体完成用户的所有目标,并根据智能体的表现调整其语言和请求。
步骤 3:多轮、多目标评估
每个聊天会话将持续固定轮数,或者直到用户模拟器确定对话完成。智能体必须处理复杂的、相互依赖的目标——例如资金转移、偏好更新或解决模糊请求——同时协调多个工具并跨轮保持上下文。我们记录每个步骤的工具调用、参数、响应和对话流,以供后续评估。
步骤 4:指标和日志
每次模拟运行后,我们使用两个主要指标分析对话
工具选择质量:智能体是否在每一轮都选择了正确的工具并正确使用了它?
行动完成度:智能体是否完成了场景中的每个用户目标,提供了明确的确认或正确的答案?
这些分数以及完整的对话日志和元数据可以选择性地记录到 Galileo 以进行高级跟踪和可视化。结果也会为每个模型、领域和场景保存,以便进行详细比较和可复现性。
步骤 5:扩展和分析
得益于并行处理,我们可以同时评估多个领域和类别的多个模型。这使得大规模的可靠基准测试成为可能,实验结果自动保存和组织以供进一步分析。
为什么这种方法很重要
我们的模拟管道提供的不仅仅是静态评估。它重现了智能体在现实世界中面临的反复、高压对话,确保模型不仅在准确性方面得到评估,还在其在多轮中适应、推理和协调行动的能力方面得到评估。这种方法揭示了更简单的、一次性基准测试会遗漏的优点和缺点,并为团队提供了关于他们选择的模型在与真实用户部署时效果如何的可操作见解。
你可以在我们的 GitHub 仓库中查看完整的代码。
为什么领域特定评估很重要
企业应用很少是关于“通用”AI 的。公司希望 AI 智能体能够适应其领域特定的需求、法规和工作流程。每个行业都带来独特的挑战:专业术语、领域特定任务、复杂的多分步工作流程、敏感数据以及通用基准中很少出现的边缘案例。
在 v1 中,缺乏独立的领域评估意味着企业无法真正了解模型在其环境中的表现。智能体是否擅长医疗保健调度但难以处理保险索赔?它能否同样可靠地处理金融合规或电信故障排除?如果没有有针对性的基准测试,这些问题将无法回答。
我们的评估直接解决了这一差距。通过构建反映特定领域真实挑战的数据集,并使用领域特定工具、任务和角色,我们现在可以为组织提供关于模型适用于其用例的可操作见解。
从“排行榜幻觉”中学习
最近的研究“排行榜幻觉”强调了宽松的提交规则、隐藏的测试和不均匀的采样如何扭曲 Chatbot Arena 等公开排名。¹ 私人“影子”评估允许一些提供商在一次公开揭示之前调整数十种变体,专有模型比开源同行收集更多的评估数据,而撤回则悄悄抹去了糟糕的结果。该论文的核心警告很简单:当排行榜成为衡量标准时,它就不再衡量真正的进展。
Agent Leaderboard v2 在设计时考虑了这些陷阱。

对 AI 工程师的实际影响
我们的评估揭示了在开发 AI 智能体时创建健壮高效系统的一些关键考虑因素。让我们分解一下这些基本方面。

构建你的智能体评估引擎
在发布这个排行榜后,我对智能体有了很多了解,最近我还与 DAIR.AI 社区讨论了如何为可靠智能体构建评估引擎。

未来工作
随着 Agent Leaderboard 的不断发展,我们专注于三个关键计划
- 每月模型更新
- 多智能体评估
- 按需扩展领域
评论区见
我们希望这能帮到你,并期待在 LinkedIn、Twitter 和 GitHub 上听到你的声音。
通过以下渠道联系我们,获取任何查询。
- 电子邮件:info@galileo.ai
- Twitter:https://x.com/rungalileo
- LinkedIn:https://linkedin.com/company/galileo-ai
- 联系方式:research@galileo.ai
你可以引用排行榜:
@misc{agent-leaderboard,
author = {Pratik Bhavsar},
title = {Agent Leaderboard},
year = {2025},
publisher = {Galileo.ai},
howpublished = "\url{https://huggingface.co/spaces/galileo-ai/agent-leaderboard}"
}
致谢
我们衷心感谢那些为这个评估框架提供了可能性的基准数据集的创建者们: