使用 Hugging Face Transformers 和 Habana Gaudi 预训练 BERT







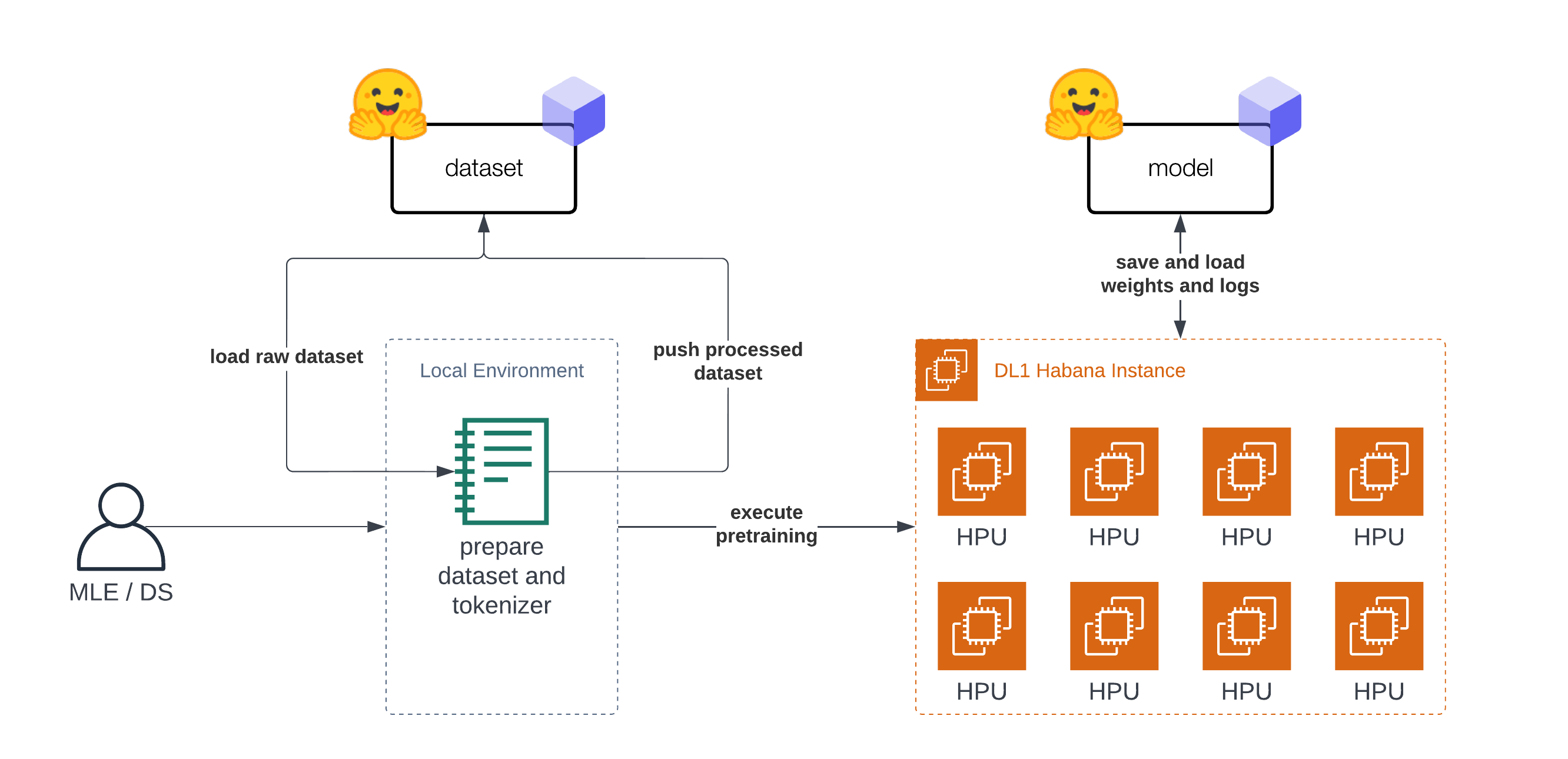
在本教程中,你将学习如何利用 AWS 上基于 Habana Gaudi 的 DL1 实例,从头开始预训练 BERT-base,以发挥 Gaudi 的性价比优势。我们将使用 Hugging Face 的 Transformers、Optimum Habana 和 Datasets 库,通过掩码语言建模(BERT 最初的两个预训练任务之一)来预训练一个 BERT-base 模型。在开始之前,我们需要先设置深度学习环境。 查看代码
您将学习如何
注意:步骤 1 到 3 可以/应该在不同大小的实例上运行,因为这些是 CPU 密集型任务。
要求
在开始之前,请确保你已满足以下要求
- 拥有 DL1 实例类型配额的 AWS 账户
- 已安装 AWS CLI
- 在 CLI 中配置了 AWS IAM 用户,并具有创建和管理 EC2 实例的权限
有用的资源
- 在 AWS 上为 Hugging Face Transformers 和 Habana Gaudi 设置深度学习环境
- 使用 EC2 Remote Runner 和 Habana Gaudi 轻松设置深度学习
- Optimum Habana 文档
- 预训练脚本
- 代码:pre-training-bert.ipynb
什么是 BERT?
BERT,全称为 Bidirectional Encoder Representations from Transformers,是一种用于自然语言处理的机器学习 (ML) 模型。它由 Google AI Language 的研究人员于 2018 年开发,可作为解决 11 种以上最常见语言任务(如情感分析和命名实体识别)的瑞士军刀式解决方案。
在我们的博客 BERT 101 🤗 详解最先进的 NLP 模型中阅读更多关于 BERT 的信息。
什么是掩码语言建模 (MLM)?
MLM 通过在句子中掩盖(隐藏)一个词,并强制 BERT 双向使用被遮盖词两侧的词来预测被掩盖的词,从而实现/强制从文本中进行双向学习。
掩码语言建模示例
“Dang! I’m out fishing and a huge trout just [MASK] my line!”
请在这里阅读更多关于掩码语言建模的信息。
让我们开始吧。🚀
注意:步骤 1 到 3 是在 AWS c6i.12xlarge 实例上运行的。
1. 准备数据集
本教程“分为”两部分。第一部分(步骤 1-3)是关于准备数据集和 Tokenizer。第二部分(步骤 4)是在准备好的数据集上预训练 BERT。在开始准备数据集之前,我们需要设置我们的开发环境。正如引言中所述,你不需要在 DL1 实例上准备数据集,可以使用你的笔记本电脑或台式电脑。
首先,我们将安装 transformers、datasets 和 git-lfs,以便将我们的 Tokenizer 和数据集推送到 Hugging Face Hub 以供后续使用。
!pip install transformers datasets
!sudo apt-get install git-lfs
为了完成我们的设置,让我们登录 Hugging Face Hub,以便在训练期间和之后将我们的数据集、Tokenizer、模型工件、日志和指标推送到 Hub。
为了能够将我们的模型推送到 Hub,你需要在 Hugging Face Hub 上注册。
我们将使用 huggingface_hub 包中的 notebook_login 工具登录我们的账户。你可以在设置中的访问令牌处获取你的令牌。
from huggingface_hub import notebook_login
notebook_login()
既然我们已经登录,让我们获取 user_id,它将用于推送工件。
from huggingface_hub import HfApi
user_id = HfApi().whoami()["name"]
print(f"user id '{user_id}' will be used during the example")
最初的 BERT 是在 维基百科和 BookCorpus 数据集上预训练的。这两个数据集都可以在 Hugging Face Hub 上找到,并且可以使用 datasets 加载。
注意:对于维基百科,我们将使用 20220301 版本,这与原始分割不同。
第一步,我们加载数据集并将它们合并在一起,以创建一个大的数据集。
from datasets import concatenate_datasets, load_dataset
bookcorpus = load_dataset("bookcorpus", split="train")
wiki = load_dataset("wikipedia", "20220301.en", split="train")
wiki = wiki.remove_columns([col for col in wiki.column_names if col != "text"]) # only keep the 'text' column
assert bookcorpus.features.type == wiki.features.type
raw_datasets = concatenate_datasets([bookcorpus, wiki])
我们不打算做一些高级的数据集准备工作,比如去重、过滤或任何其他预处理。如果你计划应用这个笔记本来从头训练你自己的 BERT 模型,我强烈建议将这些数据准备步骤纳入你的工作流程。这将有助于你改进你的语言模型。
2. 训练 Tokenizer
为了能够训练我们的模型,我们需要将文本转换为分词格式。大多数 Transformer 模型都带有预训练的 Tokenizer,但由于我们是从头开始预训练模型,我们也需要在我们的数据上训练一个 Tokenizer。我们可以使用 transformers 和 BertTokenizerFast 类在我们的数据上训练一个 Tokenizer。
关于训练新 Tokenizer 的更多信息可以在我们的 Hugging Face 课程中找到。
from tqdm import tqdm
from transformers import BertTokenizerFast
# repositor id for saving the tokenizer
tokenizer_id="bert-base-uncased-2022-habana"
# create a python generator to dynamically load the data
def batch_iterator(batch_size=10000):
for i in tqdm(range(0, len(raw_datasets), batch_size)):
yield raw_datasets[i : i + batch_size]["text"]
# create a tokenizer from existing one to re-use special tokens
tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
我们可以用 train_new_from_iterator() 开始训练 Tokenizer。
bert_tokenizer = tokenizer.train_new_from_iterator(text_iterator=batch_iterator(), vocab_size=32_000)
bert_tokenizer.save_pretrained("tokenizer")
我们将 Tokenizer 推送到 Hugging Face Hub,以便后续训练我们的模型。
# you need to be logged in to push the tokenizer
bert_tokenizer.push_to_hub(tokenizer_id)
3. 预处理数据集
在我们开始训练模型之前,最后一步是预处理/分词我们的数据集。我们将使用我们训练好的 Tokenizer 对数据集进行分词,然后将其推送到 Hub,以便稍后在我们的训练中轻松加载。分词过程也保持得相当简单,如果文档长于 512 个词元,它们将被截断,而不会被分割成多个文档。
from transformers import AutoTokenizer
import multiprocessing
# load tokenizer
# tokenizer = AutoTokenizer.from_pretrained(f"{user_id}/{tokenizer_id}")
tokenizer = AutoTokenizer.from_pretrained("tokenizer")
num_proc = multiprocessing.cpu_count()
print(f"The max length for the tokenizer is: {tokenizer.model_max_length}")
def group_texts(examples):
tokenized_inputs = tokenizer(
examples["text"], return_special_tokens_mask=True, truncation=True, max_length=tokenizer.model_max_length
)
return tokenized_inputs
# preprocess dataset
tokenized_datasets = raw_datasets.map(group_texts, batched=True, remove_columns=["text"], num_proc=num_proc)
tokenized_datasets.features
作为数据处理函数,我们将连接数据集中的所有文本,并生成长度为 tokenizer.model_max_length (512) 的块。
from itertools import chain
# Main data processing function that will concatenate all texts from our dataset and generate chunks of
# max_seq_length.
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs.
if total_length >= tokenizer.model_max_length:
total_length = (total_length // tokenizer.model_max_length) * tokenizer.model_max_length
# Split by chunks of max_len.
result = {
k: [t[i : i + tokenizer.model_max_length] for i in range(0, total_length, tokenizer.model_max_length)]
for k, t in concatenated_examples.items()
}
return result
tokenized_datasets = tokenized_datasets.map(group_texts, batched=True, num_proc=num_proc)
# shuffle dataset
tokenized_datasets = tokenized_datasets.shuffle(seed=34)
print(f"the dataset contains in total {len(tokenized_datasets)*tokenizer.model_max_length} tokens")
# the dataset contains in total 3417216000 tokens
在我们开始训练之前,最后一步是将我们准备好的数据集推送到 Hub。
# push dataset to hugging face
dataset_id=f"{user_id}/processed_bert_dataset"
tokenized_datasets.push_to_hub(f"{user_id}/processed_bert_dataset")
4. 在 Habana Gaudi 上预训练 BERT
在这个例子中,我们将使用 AWS 上的 Habana Gaudi DL1 实例来运行预训练。我们将使用 Remote Runner 工具包,从我们的本地设置轻松地在远程 DL1 实例上启动预训练。如果你想了解更多关于其工作原理的信息,可以查看使用 EC2 Remote Runner 和 Habana Gaudi 轻松设置深度学习。
!pip install rm-runner
如果使用 GPU,你会使用 Trainer 和 TrainingArguments。由于我们将在 Habana Gaudi 上运行训练,我们利用了 optimum-habana 库,因此我们可以使用 GaudiTrainer 和 GaudiTrainingArguments 来替代。GaudiTrainer 是 Trainer 的一个包装器,它允许你在 Habana Gaudi 实例上预训练或微调 Transformer 模型。
-from transformers import Trainer, TrainingArguments
+from optimum.habana import GaudiTrainer, GaudiTrainingArguments
# define the training arguments
-training_args = TrainingArguments(
+training_args = GaudiTrainingArguments(
+ use_habana=True,
+ use_lazy_mode=True,
+ gaudi_config_name=path_to_gaudi_config,
...
)
# Initialize our Trainer
-trainer = Trainer(
+trainer = GaudiTrainer(
model=model,
args=training_args,
train_dataset=train_dataset
... # other arguments
)
我们使用的 DL1 实例有 8 个可用的 HPU 核心,这意味着我们可以为我们的模型利用分布式数据并行训练。为了以分布式方式运行我们的训练,我们需要创建一个训练脚本,该脚本可以与多进程一起在所有 HPU 上运行。我们创建了一个 run_mlm.py 脚本,使用 GaudiTrainer 实现掩码语言建模。为了执行我们的分布式训练,我们使用 optimum-habana 中的 DistributedRunner 并传入我们的参数。或者,你可以查看 optimum-habana 仓库中的 gaudi_spawn.py。
在开始训练之前,我们需要定义我们想用于训练的 超参数。我们利用 GaudiTrainer 的 Hugging Face Hub 集成功能,在训练期间自动将我们的检查点、日志和指标推送到一个仓库中。
from huggingface_hub import HfFolder
# hyperparameters
hyperparameters = {
"model_config_id": "bert-base-uncased",
"dataset_id": "philschmid/processed_bert_dataset",
"tokenizer_id": "philschmid/bert-base-uncased-2022-habana",
"gaudi_config_id": "philschmid/bert-base-uncased-2022-habana",
"repository_id": "bert-base-uncased-2022",
"hf_hub_token": HfFolder.get_token(), # need to be logged in with `huggingface-cli login`
"max_steps": 100_000,
"per_device_train_batch_size": 32,
"learning_rate": 5e-5,
}
hyperparameters_string = " ".join(f"--{key} {value}" for key, value in hyperparameters.items())
我们可以通过创建一个 EC2RemoteRunner 然后 launch 它来开始我们的训练。这将启动我们的 AWS EC2 DL1 实例,并使用 huggingface/optimum-habana:latest 容器在其上运行我们的 run_mlm.py 脚本。
from rm_runner import EC2RemoteRunner
# create ec2 remote runner
runner = EC2RemoteRunner(
instance_type="dl1.24xlarge",
profile="hf-sm", # adjust to your profile
region="us-east-1",
container="huggingface/optimum-habana:4.21.1-pt1.11.0-synapse1.5.0"
)
# launch my script with gaudi_spawn for distributed training
runner.launch(
command=f"python3 gaudi_spawn.py --use_mpi --world_size=8 run_mlm.py {hyperparameters_string}",
source_dir="scripts",
)
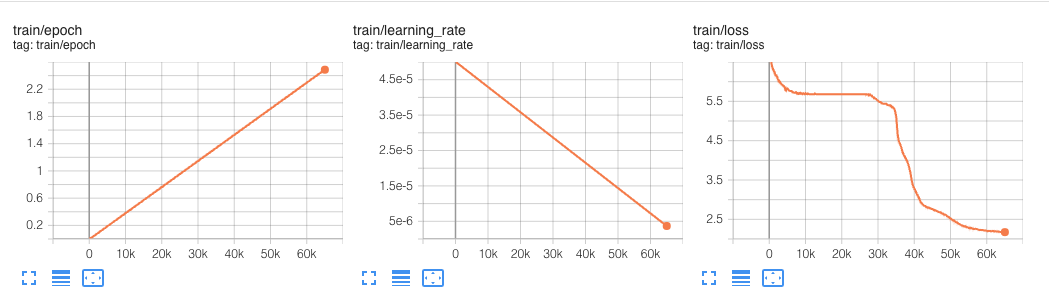
这个实验运行了 6 万步。
在我们的 超参数 中,我们定义了一个 max_steps 属性,将预训练限制在仅 100_000 步。这 100_000 步,全局批处理大小为 256,大约耗时 12.5 小时。
BERT 最初是在100 万步上预训练的,全局批处理大小为 256。
我们以 256 个序列的批次大小进行训练(256 个序列 * 512 个词元 = 128,000 个词元/批次),共进行 1,000,000 步,这大约相当于在 33 亿词的语料库上训练 40 个 epoch。
这意味着如果我们想要进行完整的预训练,大约需要 125 小时(12.5 小时 * 10),使用 AWS 上的 Habana Gaudi 成本约为 1,650 美元,这是非常便宜的。
作为比较,保持最快 BERT 预训练记录的 DeepSpeed 团队报告称,在 1 台 DGX-2(由 16 个 NVIDIA V100 GPU 驱动,每个 GPU 有 32GB 内存)上预训练 BERT 大约需要 33.25 小时。
为了比较成本,我们可以使用 p3dn.24xlarge 作为参考,它配备了 8 个 NVIDIA V100 32GB GPU,每小时成本约为 31.22 美元。我们需要两台这样的实例才能拥有与 DeepSpeed 报告的相同的“设置”,暂时我们忽略多节点设置带来的任何开销(I/O、网络等)。这将使在 AWS 上基于 DeepSpeed GPU 的训练成本约为 2,075 美元,比 Habana Gaudi 目前提供的成本高出 25%。
这里需要注意的是,使用DeepSpeed 通常能将性能提高约 1.5 - 2 倍。这意味着,没有 DeepSpeed 的相同预训练任务可能会花费两倍的时间和两倍的成本,即约 3000-4000 美元。
我们期待在 Gaudi DeepSpeed 集成更广泛可用后再次进行此实验。
结论
本教程到此结束。现在你已经了解了如何使用 Hugging Face Transformers 和 Habana Gaudi 从头开始预训练 BERT 的基础知识。你也看到了从 Trainer 迁移到 GaudiTrainer 是多么容易。
我们将我们的实现与最快的 BERT 预训练结果进行了比较,发现 Habana Gaudi 仍然能降低 25% 的成本,并允许我们以约 1,650 美元的价格预训练 BERT。
这些结果令人难以置信,因为它将允许公司根据自己的语言和领域调整其预训练模型,与通用的 BERT 模型相比,准确率可提高高达 10%。
如果你有兴趣从头开始训练自己的 BERT 或其他 Transformer 模型以降低成本并提高准确性,请联系我们的专家,了解我们的。要了解更多关于 Habana 解决方案的信息,请阅读关于我们的合作伙伴关系以及如何联系他们。
感谢阅读!如果你有任何问题,随时通过 Github 或在论坛上联系我。你也可以在 Twitter 或 LinkedIn 上与我联系。




