10 分钟快速入门 Hugging Face






本文将介绍 Hugging Face——一家提供构建机器学习应用程序工具和平台的公司。我们将探讨 Hugging Face 提供什么,如何使用其资源,以及它如何改变人工智能领域。无论您是经验丰富的数据科学家还是好奇的初学者,本指南都将帮助您理解和利用 Hugging Face 的功能。
什么是 Hugging Face?
让我们从基础开始——什么是 Hugging Face?Hugging Face 最初是一家聊天机器人公司,后来转型专注于开发尖端的开源 NLP 技术。其旗舰库 Transformers 是一款改变游戏规则的产品。它通过提供对预训练模型的轻松访问,简化了与 NLP 相关的复杂任务。这个库建立在 Transformer 架构之上,因其能够以空前的准确性大规模处理自然语言的飞跃性能力而闻名。
Hugging Face 的魅力在于其人工智能技术的民主化。通过提供可访问的工具和模型,Hugging Face 允许不同水平的从业者利用 Transformer 的潜力,而无需大量的计算资源或深度机器学习专业知识。
如何开始使用 Hugging Face
我们将探索多种与 Hugging Face 合作的方式。第一种方式是通过 https://huggingface.co/ 网站。在开始使用它之前,您必须在那里创建一个帐户。
您应该了解三个主要部分
- 模型
- 数据集
- 空间
要使用模型和数据集,您需要使用 Python 语言、Transformer 库和其中一个机器学习框架。但是,如果您没有编程技能,您可以使用 Spaces 来玩不同的 AI 模型。
Hugging Face 模型
Hugging Face 模型中心 是一个存储库,您可以在其中找到用于各种任务的预训练模型,例如自然语言处理 (NLP)、计算机视觉、音频处理等。
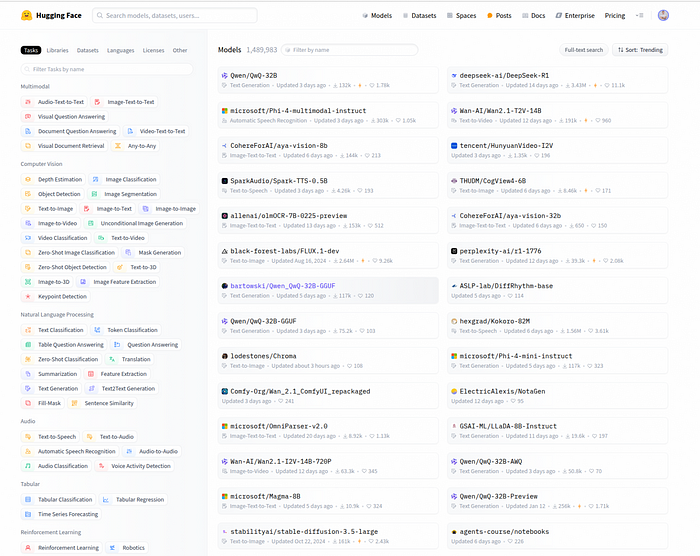
这些模型由社区和 Hugging Face 本身贡献,涵盖 BERT、GPT、T5 等各种架构。
用户可以访问数千个已在大型数据集上预训练的模型,从而可以高效地针对其自定义任务进行微调。
每个模型都附带一个模型卡,提供重要信息,例如其预期用例、限制和性能指标。
请记住
- 高性能模型可能需要大量的计算资源和 GPU 内存才能有效运行。
- 并非所有模型都可以免费用于商业目的。您应该查看每个模型提供的具体许可信息。
Hugging Face 数据集
Hugging Face 的 Datasets 库旨在提供一种简单、高效的方式来访问广泛适用于机器学习和数据驱动项目的数据集。
有用于文本、音频、图像和表格数据的数据集,涵盖多个领域和语言。
所有数据集都与 Hugging Face 的其他工具和库(如 Transformers 和 Tokenizers)无缝集成。
请记住
- 有些数据集非常庞大,如果没有足够的磁盘空间和内存,处理起来会很困难。
- 有些数据集可能对其使用有严格限制,尤其是对于商业应用。在使用前请检查任何许可证。
- 数据可能并非总是完美的,可能需要额外的清理或处理才能适应特定的用例。
Hugging Face Spaces
Spaces 是 Hugging Face 最近新增的功能,它提供了一个易于使用的平台,供用户部署他们的机器学习模型并展示交互式 AI 应用程序。
Hugging Face Spaces 提供免费和付费选项。免费 Spaces 提供 16GB RAM、2 个 CPU 核心和 50GB 非持久性磁盘空间的默认硬件资源。

许多模型都有交互式演示,可以与社区共享,无需您自己的服务器。
您可以创建所有人都可以访问的公共 Spaces,或仅限于选定协作者或团队成员访问的私有 Spaces。
请记住
- 计算资源可能会受到限制,影响托管在 Spaces 中的大型模型或数据集的性能。
- 可能存在基于您的账户级别(例如,免费与付费订阅)的限制,这些限制决定了您可以维护的 Spaces 数量以及它们可以消耗的资源。
如何使用 Hugging Face Spaces
要探索 Hugging Face Spaces 上的现有应用程序,请遵循以下步骤
1. 访问 Hugging Face Spaces 目录: 导航到 Spaces 页面,其中展示了各种机器学习应用程序。
2. 浏览应用程序: 在 Spaces 页面上,应用程序按图像生成、文本生成、语言翻译等类别组织。
3. 探索特色和热门 Spaces: 点击任何应用程序名称以访问其专用页面,您可以在其中与演示进行交互并查看其他详细信息。
4. 与应用程序交互: 许多 Spaces 提供交互式演示。按照屏幕上的说明使用应用程序。
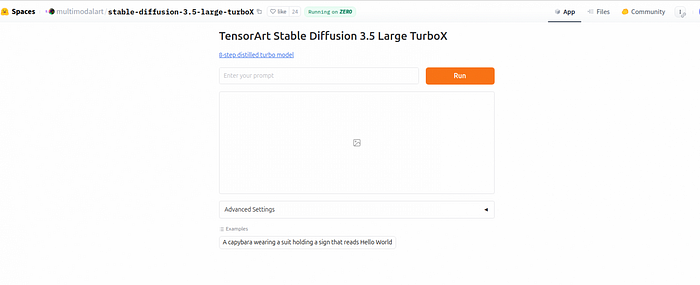
如何使用 Hugging Face 模型
要使用模型,我们需要安装 Transformers 库,该库提供对众多预训练模型的访问。
什么是 Hugging Face Transformers?
Transformers 是一种深度学习模型架构,擅长理解语言的上下文和细微差别。该库提供了大量的预训练模型和微调工具,对于文本分类、分词、翻译、摘要等各种任务都非常有价值。
只需几行代码,您就可以将这些高级模型集成到您的项目中,从而显著减少从头开始训练模型通常所需的时间和精力。这种可访问性降低了入门门槛,营造了一个更具包容性的环境,让更多人可以通过 AI 进行创新。
如何使用 Hugging Face Transformers
在深入了解具体应用之前,请确保您的开发环境已正确设置。您需要将其安装在您的系统上
- IDE(VS Code 或任何其他)
- Python 语言
- Transformers 库
- 机器学习框架(PyTorch 或 TensorFlow)
第一步:安装必要的库
我们将使用终端。
使用以下命令
安装 Python
sudo apt update
sudo apt install python3
使用虚拟环境
创建虚拟环境而不是全局安装包
python3 -m venv venv
source venv/bin/activate
安装 Transformers 和其他一些库
pip install transformers datasets evaluate accelerate
您还需要安装您偏好的机器学习框架。
PyTorch 和 TensorFlow 是最流行的两个深度学习开源框架。
PyTorch 由 Facebook 的 AI 研究实验室 (FAIR) 开发,并于 2016 年发布。它因其易用性和灵活性而获得了极大的普及。
TensorFlow 由 Google Brain 团队开发,并于 2015 年开源。它是构建深度学习模型的最古老、最广泛采用的框架之一。
安装 PyTorch
pip install torch
(可选) 对于 GPU 加速,请安装相应的 CUDA 驱动程序。只需按照 NVIDIA 网站上的说明操作 https://developer.nvidia.com/cuda-downloads
CUDA 是 NVIDIA 专门为其 GPU(图形处理单元)产品线创建的并行计算平台和应用程序编程接口 (API) 模型。它允许开发人员利用 NVIDIA GPU 硬件进行通用处理 (GPGPU),超越了传统的图形用途,并在机器学习、科学计算和数据分析等领域显著加速计算任务。
第二步:探索模型中心
导航到 Hugging Face 模型中心(https://huggingface.co/models)并探索可用的模型。
找到您想尝试的模型后,点击它并将其 transformer 代码复制到您的 IDE 中(请记住,可能不仅有 transformer 代码)。
例如,模型 https://huggingface.co/Salesforce/blip-image-captioning-base 旨在为图像生成描述性标题。
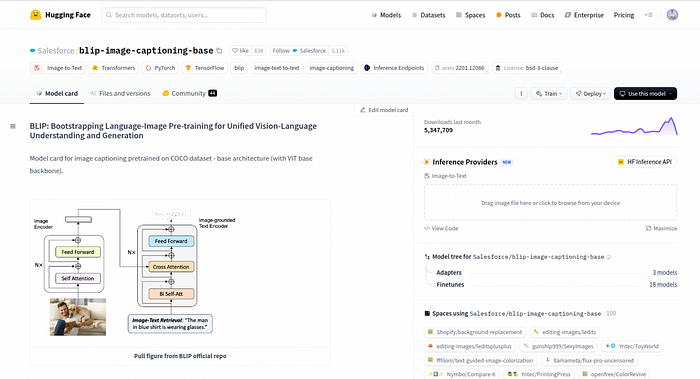
探索模型中心
代码
import requests
from PIL import Image
from transformers import BlipProcessor, BlipForConditionalGeneration
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
model = BlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
# conditional image captioning
text = "a photography of"
inputs = processor(raw_image, text, return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
# >>> a photography of a woman and her dog
# unconditional image captioning
inputs = processor(raw_image, return_tensors="pt")
out = model.generate(**inputs)
print(processor.decode(out[0], skip_special_tokens=True))
结果如下
通过这种方式,您可以尝试 1000 多个不同的模型。但请记住,要有效运行 Hugging Face 的 Transformers 库和 PyTorch,建议您的系统至少有 8 GB RAM 和 4 GB VRAM 的 GPU;但是,为了获得最佳性能,对于大型模型,建议使用 64 GB RAM 和 24 GB VRAM 的 GPU。
视频教程
我还创建了一个详细的视频教程。立即观看或稍后保存。

在 YouTube 上观看: Hugging Face 教程
结论
通过使用 Hugging Face 的资源,您可以增强您的 AI 项目,并为更广泛的 AI 社区的成长和创新做出贡献。请稍等片刻,并在下方与我分享您的想法和学习成果!
干杯!:)





