在 PyTorch / XLA TPU 上运行 Hugging Face:更快更便宜的训练





使用 PyTorch / XLA 在云 TPU 上训练你最喜欢的 Transformers 模型
PyTorch-TPU 项目最初是 Facebook PyTorch 和 Google TPU 团队的合作项目,并于 2019 年 PyTorch 开发者大会上正式启动。从那时起,我们与 Hugging Face 团队合作,为使用 PyTorch / XLA 在云 TPU 上进行训练提供了一流的支持。这项新的集成使得 PyTorch 用户能够在云 TPU 上运行和扩展他们的模型,同时保持与 Hugging Face 训练器完全相同的接口。
这篇博文概述了 Hugging Face 库中所做的更改,PyTorch / XLA 库的功能,一个让你开始在云 TPU 上训练你最喜欢的 transformers 的例子,以及一些性能基准。如果你迫不及待地想开始使用 TPU,请直接跳到“在云 TPU 上训练你的 Transformer”部分——我们在 Trainer 模块中为你处理了所有 PyTorch / XLA 的机制!
XLA:TPU 设备类型
PyTorch / XLA 为 PyTorch 添加了一种新的 xla 设备类型。这种设备类型的工作方式与其他 PyTorch 设备类型一样。例如,以下是如何创建和打印一个 XLA 张量
import torch
import torch_xla
import torch_xla.core.xla_model as xm
t = torch.randn(2, 2, device=xm.xla_device())
print(t.device)
print(t)
这段代码应该看起来很熟悉。PyTorch / XLA 使用与常规 PyTorch 相同的接口,并增加了一些内容。导入 torch_xla 会初始化 PyTorch / XLA,而 xm.xla_device() 会返回当前的 XLA 设备。根据你的环境,这可能是 CPU、GPU 或 TPU,但在本文中,我们将主要关注 TPU。
Trainer 模块利用一个 TrainingArguments 数据类来定义训练的具体细节。它处理多个参数,从批量大小、学习率、梯度累积等,到所使用的设备。基于以上内容,在 TrainingArguments._setup_devices() 中使用 XLA:TPU 设备时,我们只需返回要由 Trainer 使用的 TPU 设备即可。
@dataclass
class TrainingArguments:
...
@cached_property
@torch_required
def _setup_devices(self) -> Tuple["torch.device", int]:
...
elif is_torch_tpu_available():
device = xm.xla_device()
n_gpu = 0
...
return device, n_gpu
XLA 设备上的单步计算
在典型的 XLA:TPU 训练场景中,我们在多个 TPU 核心上并行训练(一个云 TPU 设备包含 8 个 TPU 核心)。因此,我们需要确保通过合并梯度和执行优化器步骤,在数据并行副本之间交换所有梯度。为此,我们提供了 xm.optimizer_step(optimizer),它负责梯度合并和步进。在 Hugging Face 训练器中,我们相应地更新了训练步骤以使用 PyTorch / XLA API
class Trainer:
…
def train(self, *args, **kwargs):
...
if is_torch_tpu_available():
xm.optimizer_step(self.optimizer)
PyTorch / XLA 输入管道
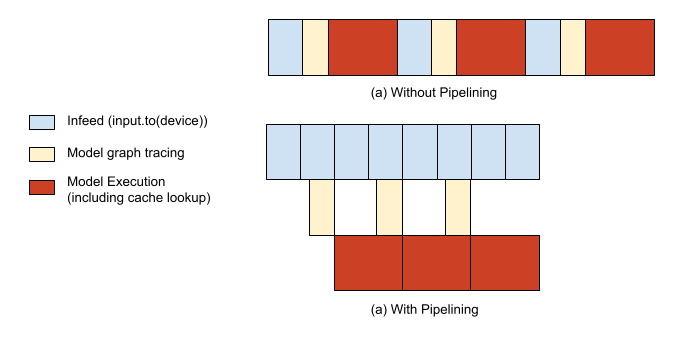
运行 PyTorch / XLA 模型主要有两个部分:(1)惰性地追踪和执行模型的计算图(更深入的解释请参考下面的 “PyTorch / XLA 库” 部分)和(2)为你的模型提供数据。如果没有任何优化,模型的追踪/执行和输入供给将串行执行,导致主机 CPU 和 TPU 加速器分别出现空闲时间段。为了避免这种情况,我们提供了一个 API,将这两者流水线化,从而能够在第 n 步仍在执行时,重叠进行第 n+1 步的追踪。
import torch_xla.distributed.parallel_loader as pl
...
dataloader = pl.MpDeviceLoader(dataloader, device)
检查点的写入和加载
当一个张量从 XLA 设备保存为检查点,然后从检查点加载回来时,它将被加载回原始设备。在为模型中的张量创建检查点之前,你需要确保所有的张量都在 CPU 设备上,而不是在 XLA 设备上。这样,当你加载回张量时,你会通过 CPU 设备加载它们,然后有机会将它们放置到你希望的任何 XLA 设备上。我们为此提供了 xm.save() API,它已经处理了只从每个主机上的一个进程(如果使用跨主机的共享文件系统,则全局只有一个)写入存储位置的问题。
class PreTrainedModel(nn.Module, ModuleUtilsMixin, GenerationMixin):
…
def save_pretrained(self, save_directory):
...
if getattr(self.config, "xla_device", False):
import torch_xla.core.xla_model as xm
if xm.is_master_ordinal():
# Save configuration file
model_to_save.config.save_pretrained(save_directory)
# xm.save takes care of saving only from master
xm.save(state_dict, output_model_file)
class Trainer:
…
def train(self, *args, **kwargs):
...
if is_torch_tpu_available():
xm.rendezvous("saving_optimizer_states")
xm.save(self.optimizer.state_dict(),
os.path.join(output_dir, "optimizer.pt"))
xm.save(self.lr_scheduler.state_dict(),
os.path.join(output_dir, "scheduler.pt"))
PyTorch / XLA 库
PyTorch / XLA 是一个 Python 包,它使用 XLA 线性代数编译器将 PyTorch 深度学习框架与 XLA 设备(包括 CPU、GPU 和云 TPU)连接起来。以下部分内容也见于我们的 API_GUIDE.md。
PyTorch / XLA 张量是惰性的
使用 XLA 张量和设备只需要更改几行代码。然而,尽管 XLA 张量的行为很像 CPU 和 CUDA 张量,但它们的内部机制是不同的。CPU 和 CUDA 张量会立即或“急切地”启动操作。而 XLA 张量则是“惰性”的。它们会将操作记录在一个图中,直到需要结果时才执行。像这样延迟执行可以让 XLA 对其进行优化。一个由多个独立操作组成的图可能会被融合成一个单一的优化操作。
惰性执行对调用者来说通常是不可见的。PyTorch / XLA 会自动构建图,将它们发送到 XLA 设备,并在 XLA 设备和 CPU 之间复制数据时进行同步。在执行优化器步骤时插入一个屏障会显式地同步 CPU 和 XLA 设备。
这意味着当你调用 model(input) 进行前向传播,计算损失 loss.backward(),并执行优化步骤 xm.optimizer_step(optimizer) 时,所有操作的图都在后台构建。只有当你显式地评估张量(例如打印张量或将其移动到 CPU 设备)或标记一个步骤(每次迭代 MpDeviceLoader 时都会这样做)时,完整的步骤才会被执行。
追踪、编译、执行,并重复
从用户的角度来看,在 PyTorch / XLA 上运行模型的典型训练方案包括运行前向传播、后向传播和优化器步骤。从 PyTorch / XLA 库的角度来看,情况略有不同。
当用户运行他们的前向和后向传播时,一个中间表示(IR)图会动态地被追踪。通向每个根/输出张量的 IR 图可以如下检查
>>> import torch
>>> import torch_xla
>>> import torch_xla.core.xla_model as xm
>>> t = torch.tensor(1, device=xm.xla_device())
>>> s = t*t
>>> print(torch_xla._XLAC._get_xla_tensors_text([s]))
IR {
%0 = s64[] prim::Constant(), value=1
%1 = s64[] prim::Constant(), value=0
%2 = s64[] xla::as_strided_view_update(%1, %0), size=(), stride=(), storage_offset=0
%3 = s64[] aten::as_strided(%2), size=(), stride=(), storage_offset=0
%4 = s64[] aten::mul(%3, %3), ROOT=0
}
当用户程序运行前向和后向传播时,这个实时图会不断累积,一旦调用 xm.mark_step()(由 pl.MpDeviceLoader 间接调用),实时张量的图就会被切断。这种截断标志着一个步骤的完成,随后我们将 IR 图降级为 XLA 高级操作(HLO),这是 XLA 的 IR 语言。
然后,这个 HLO 图被编译成 TPU 二进制文件,并随后在 TPU 设备上执行。然而,这个编译步骤可能成本很高,通常比单个步骤耗时更长,所以如果我们每一步都编译用户的程序,开销会很大。为了避免这种情况,我们有缓存来存储已编译的 TPU 二进制文件,这些二进制文件以其 HLO 图的唯一哈希标识符为键。因此,一旦这个 TPU 二进制缓存 populated 在第一步被填充,后续的步骤通常不必重新编译新的 TPU 二进制文件;相反,它们可以简单地从缓存中查找必要的二进制文件。
由于 TPU 编译通常比步骤执行时间慢得多,这意味着如果图的形状不断变化,我们将会出现缓存未命中并过于频繁地编译。为了最小化编译成本,我们建议尽可能保持张量形状的静态。Hugging Face 库的形状大部分已经是静态的,输入标记会进行适当的填充,因此在整个训练过程中,缓存应该会持续命中。这可以使用 PyTorch / XLA 提供的调试工具来检查。在下面的例子中,你可以看到编译只发生了 5 次(CompileTime),而执行则在 1220 个步骤中的每一步都发生了(ExecuteTime)。
>>> import torch_xla.debug.metrics as met
>>> print(met.metrics_report())
Metric: CompileTime
TotalSamples: 5
Accumulator: 28s920ms153.731us
ValueRate: 092ms152.037us / second
Rate: 0.0165028 / second
Percentiles: 1%=428ms053.505us; 5%=428ms053.505us; 10%=428ms053.505us; 20%=03s640ms888.060us; 50%=03s650ms126.150us; 80%=11s110ms545.595us; 90%=11s110ms545.595us; 95%=11s110ms545.595us; 99%=11s110ms545.595us
Metric: DeviceLockWait
TotalSamples: 1281
Accumulator: 38s195ms476.007us
ValueRate: 151ms051.277us / second
Rate: 4.54374 / second
Percentiles: 1%=002.895us; 5%=002.989us; 10%=003.094us; 20%=003.243us; 50%=003.654us; 80%=038ms978.659us; 90%=192ms495.718us; 95%=208ms893.403us; 99%=221ms394.520us
Metric: ExecuteTime
TotalSamples: 1220
Accumulator: 04m22s555ms668.071us
ValueRate: 923ms872.877us / second
Rate: 4.33049 / second
Percentiles: 1%=045ms041.018us; 5%=213ms379.757us; 10%=215ms434.912us; 20%=217ms036.764us; 50%=219ms206.894us; 80%=222ms335.146us; 90%=227ms592.924us; 95%=231ms814.500us; 99%=239ms691.472us
Counter: CachedCompile
Value: 1215
Counter: CreateCompileHandles
Value: 5
...
在云 TPU 上训练你的 Transformer
要配置您的 VM 和云 TPU,请遵循 “设置计算引擎实例” 和 “启动云 TPU 资源”(撰写本文时为 pytorch-1.7 版本)部分。一旦您创建了 VM 和云 TPU,使用它们就像通过 SSH 连接到您的 GCE VM 并运行以下命令来启动 bert-large-uncased 训练一样简单(批量大小适用于 v3-8 设备,在 v2-8 上可能会内存溢出)
conda activate torch-xla-1.7
export TPU_IP_ADDRESS="ENTER_YOUR_TPU_IP_ADDRESS" # ex. 10.0.0.2
export XRT_TPU_CONFIG="tpu_worker;0;$TPU_IP_ADDRESS:8470"
git clone -b v4.2.2 https://github.com/huggingface/transformers.git
cd transformers && pip install .
pip install datasets==1.2.1
python examples/xla_spawn.py \
--num_cores 8 \
examples/language-modeling/run_mlm.py \
--dataset_name wikitext \
--dataset_config_name wikitext-103-raw-v1 \
--max_seq_length 512 \
--pad_to_max_length \
--logging_dir ./tensorboard-metrics \
--cache_dir ./cache_dir \
--do_train \
--do_eval \
--overwrite_output_dir \
--output_dir language-modeling \
--overwrite_cache \
--tpu_metrics_debug \
--model_name_or_path bert-large-uncased \
--num_train_epochs 3 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--save_steps 500000
上述训练应在大约不到 200 分钟内完成,评估困惑度约为 3.25。
性能基准测试
下表显示了在运行 PyTorch / XLA 的 v3-8 云 TPU 系统(包含 4 个 TPU v3 芯片)上训练 bert-large-uncased 的性能。所有基准测试测量使用的数据集是 WikiText103 数据集,我们使用 Hugging Face 示例中提供的 run_mlm.py 脚本。为确保工作负载不受主机 CPU 限制,我们在这些测试中使用了 n1-standard-96 CPU 配置,但您也可以使用较小的配置而不会影响性能。
| 名称 | 数据集 | 硬件 | 全局批次大小 | 精度 | 训练时间(分钟) |
|---|---|---|---|---|---|
| bert-large-uncased | WikiText103 | 4 个 TPUv3 芯片 (即 v3-8) | 64 | FP32 | 178.4 |
| bert-large-uncased | WikiText103 | 4 个 TPUv3 芯片 (即 v3-8) | 128 | BF16 | 106.4 |
开始在 TPU 上使用 PyTorch / XLA
请参阅 Hugging Face 示例下的 “在 TPU 上运行” 部分以开始使用。有关我们 API 的更详细描述,请查看我们的 API 指南,有关性能最佳实践,请参阅我们的 故障排除指南。对于通用的 PyTorch / XLA 示例,请运行我们提供的 Colab 笔记本,它们提供免费的云 TPU 访问。要直接在 GCP 上运行,请参阅我们文档网站上标记为“PyTorch”的教程。
还有其他问题吗?请在 https://github.com/huggingface/transformers/issues 或直接在 https://github.com/pytorch/xla/issues 上提出问题。

