再见Python,你好Rust:用Orca构建RAG CLI应用程序




想象一下,在您的笔记本电脑上运行强大的人工智能大型语言模型,而无需昂贵的云订阅或复杂的设置。在这篇文章中,我们将深入探讨这不仅可能,而且比您想象的更容易实现。虽然LLM通常与昂贵的GPU和基于云的推理相关联,但我将演示如何在本地机器上直接运行推理。我们将开发一个精简的RAG CLI应用程序,它生成Bert句子嵌入并执行Mistral Instruct 7B文本补全,所有这些都不需要互联网连接。这得益于Orca。对于不熟悉Orca的人来说,它是我的最新项目——一个用Rust编写的LLM编排框架。其目标是让开发人员能够轻松创建用于本地使用的快速LLM应用程序,并最终目标是使这些应用程序能够编译成WebAssembly,以实现真正的无服务器推理。为了实现这一点,Orca在底层利用Hugging Face的Candle框架来运行模型。Candle是一个新的极简Rust机器学习框架。在Candle的帮助下,我们离实现这个无服务器愿景又近了一步。
 由DALLE-3生成
由DALLE-3生成
在深入了解之前,让我们先澄清一下RAG的含义。它是检索增强生成(Retrieval-Augmented Generation)的缩写,这是一种强大的技术,它将相关文本的检索与答案生成结合起来,通过将检索到的信息融入生成过程。这种方法本质上允许进行一种特殊形式的微调,可以产生比大型语言模型仅依赖预训练所能产生的更精确的答案。考虑这样一个场景:您正在处理一本厚厚的书,并希望在其中搜索特定信息。这本书的体积远远超出了标准LLM上下文窗口的处理能力。RAG通过将书分解成可管理的部分,为每个部分创建嵌入,然后将您的查询嵌入与相关部分的嵌入进行匹配来直接解决这个问题。然后,向量数据库会提供最接近的匹配,从而实现准确高效的信息检索,这些信息现在可以被输入到LLM的上下文窗口中。
那么我们如何将其制作成一个CLI应用程序呢?为简单起见,我们将把程序设计为接受两个命令行参数:一个文件名和一个提示。最终的响应将直接打印给用户。这种简化的方法向最终用户隐藏了底层复杂性,用户只需提供一个提示即可搜索PDF文件。以下是已完成应用程序的可视化设计。
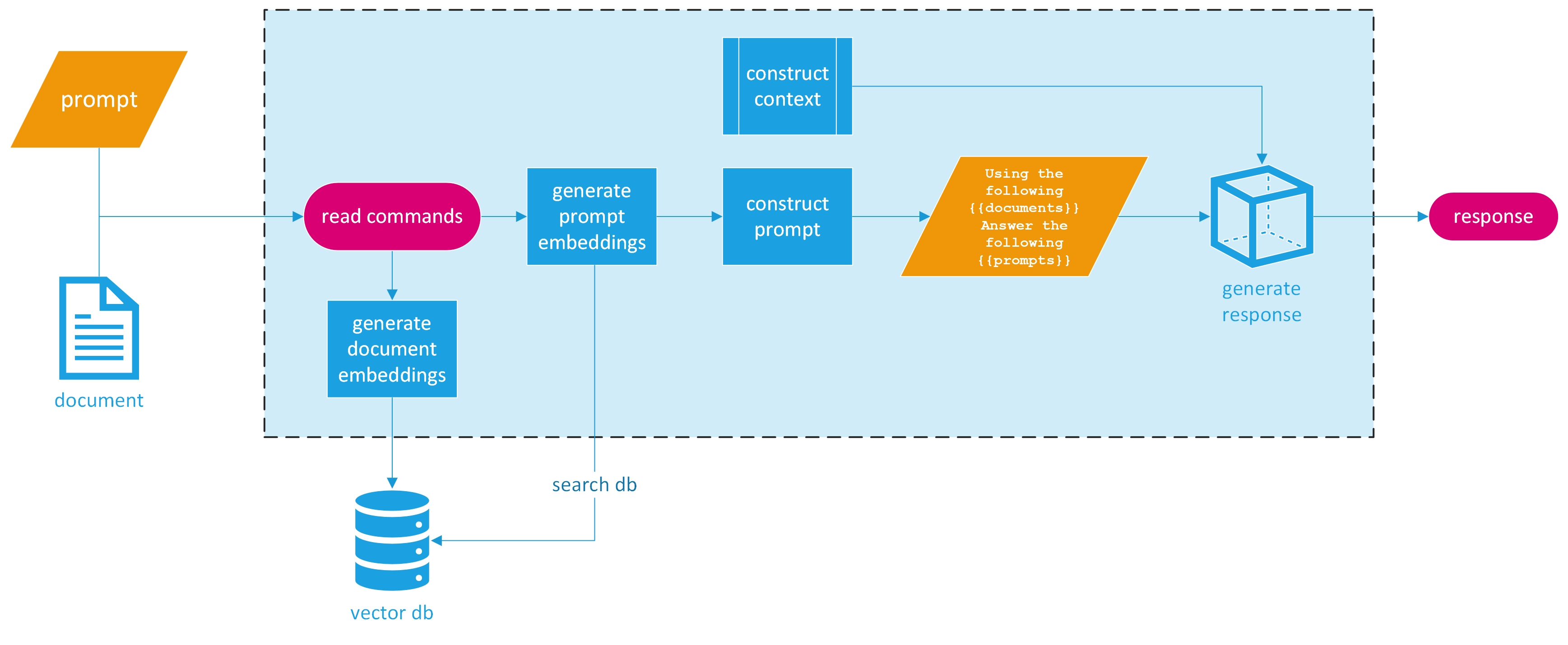 RAG CLI应用程序设计
RAG CLI应用程序设计
提供的图片将我们的RAG CLI应用程序的过程分解为清晰、易于理解的步骤。让我们将其分解为三个主要部分。
设置
为了初始化我们的RAG CLI应用程序,我们首先设置命令行参数解析。对于这项任务,我们将使用`clap`库——Rust生态系统中一个强大的工具,以其简化命令行输入处理并增强用户体验的能力而闻名。
提供的代码片段概述了主要元素
use clap::Parser;
use orca::{
llm::{bert::Bert, quantized::Quantized, Embedding},
pipeline::simple::LLMPipeline,
pipeline::Pipeline,
prompt,
prompt::context::Context,
prompts,
qdrant::Qdrant,
record::{pdf::Pdf, Spin},
};
use serde_json::json;
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
#[clap(long)]
/// The path to the PDF file to index
file: String,
#[clap(long)]
/// The prompt to use to query the index
prompt: String,
}
我们定义了一个结构体`Args`,它派生了Clap的`Parser`特性。在`Args`中,我们指定了两个命令行参数
file:表示用户希望索引的PDF文件的路径。它带有一个长标识符,用于在命令行中作为`--file`使用。prompt:表示用户将传递给LLM的查询或问题。它带有一个长标识符,用于在命令行中作为`--prompt`使用。
通过以这种方式设置命令行参数解析,我们为用户友好的界面奠定了基础。用户可以轻松地提供必要的输入,使PDF文件的索引和查询过程变得轻而易举。接下来的步骤将是将这些输入与我们应用程序的核心功能连接起来,从而实现高效的信息检索和响应生成。
继续设置,我们将解析的参数整合到应用程序的主要功能中
let args = Args::parse();
现在可以通过args.file和args.prompt分别访问文件名和提示。
嵌入
为了生成PDF的嵌入,我们首先需要读取并分割它。幸运的是,Orca的记录处理使其变得非常容易。我们已经导入了`orca::record::pdf::Pdf`,所以现在我们只需使用它来读取文件。一旦读取,我们就可以调用`Spin`特性来生成我们的`Record`(你“旋转”一个记录😃),然后通过指定每个片段的令牌数量来`split`它。我们将使用399个令牌作为默认值。此外,我们可以初始化并构建我们的Bert嵌入模型。
let pdf_records: Vec<Record> = Pdf::from_file(&args.file, false).spin().unwrap().split(399);
let bert = Bert::new().build_model_and_tokenizer().await.unwrap();
build_model_and_tokenizer()函数使用Hugging Face API和Candle框架来检索模型权重和分词器文件,并创建一个BertModel,该模型是由candle-transformers crate提供的Candle Transformer模型。
现在我们可以设置Qdrant,我们的向量数据库。Orca有一个内置的Qdrant包装器。这通过提供一个简单的API,最大程度地减少了用户的设置要求。首先,请确保您已安装Docker并打开Docker Desktop。这将轻松地允许我们在本地机器上启动一个Qdrant实例。Rust Qdrant客户端通过gRPC进行通信,因此您必须运行以下特定命令来拉取镜像并运行它
$ docker pull qdrant/qdrant
$ docker run -d --name qdrant_test_instance -p 6333:6333 -p 6334:6334 -e QDRANT__SERVICE__GRPC_PORT=6334 qdrant/qdrant
在Docker中启动并运行Qdrant实例后,我们现在可以创建一个集合,生成嵌入,并将其插入到数据库中。
let collection = std::path::Path::new(&args.file)
.file_stem()
.and_then(|name| name.to_str())
.unwrap_or("default_collection")
.to_string();
let qdrant = Qdrant::new("https://:6334");
if qdrant.create_collection(&collection, 384).await.is_ok() {
let embeddings = bert.generate_embeddings(prompts!(&pdf_records)).await.unwrap();
qdrant.insert_many(&collection, embeddings.to_vec2().unwrap(), pdf_records).await.unwrap();
}
let query_embedding = bert.generate_embedding(prompt!(args.prompt)).await.unwrap();
let result = qdrant.search(&collection, query_embedding.to_vec().unwrap().clone(), 5, None).await.unwrap();
在此代码片段中,我们从PDF文件路径的词干设置集合名称。然后,我们创建一个指向本地Qdrant实例的新Qdrant客户端。之后,我们使用集合名称在Qdrant中创建一个集合,将维度设置为384(BERT嵌入的典型维度),使用我们的Bert模型为所有记录生成嵌入,并将它们与相关记录一起插入到数据库中。
有趣的事实:Orca并行生成多个嵌入,使其比同步生成嵌入更快。
将我们的嵌入安全地存储在Qdrant中后,我们可以继续为用户的查询生成嵌入并执行搜索。我们要求Qdrant找到与我们的查询嵌入最接近的前5条记录。
仔细观察,我们有两个`prompt`宏,用于将提示传递给模型。`prompt`宏允许我们传递任何实现了`Prompt`特性的类型,而`prompts`宏允许我们传递多个实现了`Prompt`特性的提示类型,无论是向量还是作为参数传入的一系列字符串,例如。
生成我们的响应
这正是大部分神奇发生的地方。Orca有一个非常酷的模板功能。这允许我们使用类似Handlebars的语法来创建提示模板。由于我们希望此应用程序具有聊天式提示,我们可以将模板格式化如下
let prompt_for_model = r#"
{{#chat}}
{{#system}}
You are a highly advanced assistant. You receive a prompt from a user and relevant excerpts extracted from a PDF. You then answer truthfully to the best of your ability. If you do not know the answer, your response is I don't know.
{{/system}}
{{#user}}
{{user_prompt}}
{{/user}}
{{#system}}
Based on the retrieved information from the PDF, here are the relevant excerpts:
{{#each payloads}}
{{this}}
{{/each}}
Please provide a comprehensive answer to the user's question, integrating insights from these excerpts and your general knowledge.
{{/system}}
{{/chat}}
"#;
在这个Orca模板中,我们有效地指示模型扮演一个复杂的助手的角色。它旨在将用户的提问({{user_prompt}})与从PDF中提取的信息(表示为{{#each payloads}}以迭代相关摘录)相结合。{{#chat}}结构帮助我们定义对话流程,引导模型根据我们指定的角色(无论是系统还是用户)进行响应。
一旦模板设置完毕,我们就可以准备将要输入的数据。这些数据包括用户的提示和Qdrant搜索得到的PDF相关摘录。
let context = serde_json::json!({
"user_prompt": args.prompt,
"payloads": result
.iter()
.filter_map(|found_point| {
found_point.payload.as_ref().map(|payload| {
// Assuming you want to convert the whole payload to a JSON string
serde_json::to_string(payload).unwrap_or_else(|_| "{}".to_string())
})
})
.collect::<Vec<String>>()
});
我们在这里利用serde_json::json!宏巧妙地创建了上下文对象。这个宏的优点在于它允许使用更自然的类JSON语法,并确保数据结构正确以便于序列化。链中的filter_map具有双重目的:它过滤掉任何不存在的有效载荷(确保我们只处理有效数据),并将每个有效载荷映射到一个JSON字符串。这一步至关重要,因为它将复杂的数据结构转换为适合我们模板系统的格式。如果序列化失败,我们会优雅地默认使用一个空的JSON对象,从而避免因数据不一致而导致潜在的崩溃。
值得注意的是,虽然我们为了方便和可读性而使用serde_json::json!,但Orca允许任何实现了Serialize特性的类型在此上下文中使用。这意味着开发人员可以自由地根据需要序列化更复杂或自定义的数据结构,使系统能够高度适应各种应用程序。
为了在本地设置中初始化并执行Mistral Instruct 7B,Orca 在底层调用了 Hugging Face 的 Candle 框架。这进一步通过使用 `gguf` 文件构建模型来实现,Orca 可以帮助下载或本地加载该文件,为用户提供无缝的设置体验。
let mistral = Quantized::new()
.with_model(orca::llm::quantized::Model::Mistral7bInstruct)
.with_sample_len(7500)
.load_model_from_path("../../models/mistral-7b-instruct-v0.1.Q4_K_S.gguf")
.unwrap()
.build_model()
.unwrap();
这段代码片段展示了我们如何使用 Orca 加载 Mistral Instruct 7B 的量化版本。Mistral 是 OpenAI GPT-3 的精简版本,经过优化,可在性能没有显著损失的情况下以更低的资源运行。量化模型需要更少的内存和计算资源,这使得它们非常适合在本地机器(如笔记本电脑)上运行。
一旦我们构建了Mistral模型,我们就可以运行实际的推理。鉴于我们构建的提示以及PDF相关摘录的上下文,我们可以使用Orca简单的`LLMPipeline`将其全部连接起来
let mut pipe = LLMPipeline::new(&mistral).with_template("query", prompt_for_model);
pipe.load_context(&Context::new(context).unwrap()).await;
let response = pipe.execute("query").await.unwrap();
println!("Response: {}", response.content());
在Orca中使用LLMPipeline非常容易。要做到这一点,您只需使用您的模型(在本例中是mistral)创建一个LLMPipeline的新实例。然后,您可以将您的模板和上下文加载到管道中。
`with_template` 方法用于将一个句柄(此处为“query”)与我们定义的模板关联起来。然后,这个句柄用于使用给定的上下文执行模板。上下文通过 `load_context` 方法加载到管道中,该方法接受一个由我们之前定义的 JSON 上下文构建的 `Context` 实例。
调用execute时,您将传入要运行的模板的句柄。管道处理提供的信息,生成响应,并将其打印出来。
整个过程是异步的,如`await`关键字所示,这意味着它在不阻塞主线程的情况下运行,允许其他任务并行运行或系统保持响应。
运行CLI LLM应用程序
我们来试试吧!我将查询我笔记本电脑上(M1 Max Macbook Pro)下载的一本书——《纳瓦尔宝典》。
$ cargo run --release -- --file './naval-book.pdf' --prompt 'investing the rest of your life in what has meaning to you'
[2023-11-03T04:18:15Z INFO orca::llm::bert] Computing embeddings
[2023-11-03T04:18:25Z INFO orca::llm::bert] Done computing embeddings
[2023-11-03T04:18:25Z INFO orca::llm::bert] Embeddings took 10.411869958s to generate
[2023-11-03T04:18:26Z INFO orca::llm::bert] token_ids shape: [1, 14]
[2023-11-03T04:18:26Z INFO orca::llm::bert] running inference [1, 14]
[2023-11-03T04:18:26Z INFO orca::llm::bert] embedding shape: [1, 14, 384]
[2023-11-03T04:18:26Z INFO orca::llm::bert] Embedding took 15.420958ms to generate
[2023-11-03T04:18:26Z INFO orca::llm::quantized] loaded 291 tensors (4.14GB) in 0.07s
[2023-11-03T04:18:28Z INFO orca::llm::quantized] model built
"The question is about investing the rest of one's life in what has meaning to them.
According to the relevant excerpts, there are a few things to consider when it comes
to investing one's life in something that has meaning. One is to focus on building wealth
that comes from activities that align with one's interests and passions. For example, if
you are passionate about venture investing, then it may be worth pursuing a career in that
area. However, it's important to potentially diversify your investments and explore
different opportunities to maximize your returns.
Another consideration is to focus on activities that are timeless and have the potential
for long-term growth. Warren Buffett's famous quote about earning with your mind, not your
time, highlights the importance of compound interest and building wealth through investments
that will continue to grow over time. Additionally, it may be beneficial to focus on
relationships that will also provide long-term benefits, whether it's in wealth or personal
fulfillment.
It's also worth noting that pursuing your passions can lead to not just financial reward, but
also personal fulfillment and satisfaction in life. Therefore, it's important to invest in
activities that bring meaning and purpose to your life.
Overall, it seems that the best way to invest the rest of your life in something that has meaning
is to pursue activities that align with your passions and interests, focus on building wealth
through compound interest and long-term growth, and nurture relationships and activities that
will bring personal fulfillment in life.</s>"
瞧,这是一个CLI应用程序,它在您的本地机器上发挥了检索增强生成模型的力量。我们已经完成了Rust应用程序的设置,该应用程序接受一个PDF文件和用户的查询,并通过结合使用Orca、BERT嵌入和Mistral Instruct 7B来生成知情的响应。从将文档分割成可消化的记录,到使用Qdrant将其嵌入可搜索的向量空间,再到通过对话式AI模板精心制作细致入微的答案,这个CLI工具体现了当今AI领域的创新精神。
结论
我们所构建的不仅仅是技术可能性的一次展示;它更是AI技术日益普及的证明。AI的潜力不再局限于云服务和高性能服务器领域,它正在被民主化。开发者和爱好者现在都可以在自己的环境中,按照自己的意愿,将利用语言模型强大功能的应用程序变为现实。
这个RAG CLI应用程序是迈向未来的垫脚石,在这个未来,AI将融入我们的日常计算任务,而无需担心基于云的系统带来的延迟或隐私问题。
此外,对本地LLM部署的这一探索也预示着未来WebAssembly可能允许这些模型在更受限制的环境中运行——例如浏览器和移动设备——为应用程序开发开辟了新的领域。
当我们结束这次探索时,请记住Orca、Candle以及使此应用程序成为可能的所有技术栈,都是一个更大、由社区驱动的开源人工智能力量的努力的一部分。没有无数对我们所使用的开源库做出贡献的人,这次旅程是不可能实现的。他们致力于推动该领域的发展,同时保持其开放和可访问性,这值得我们集体感谢。
现在轮到你了。拿起这个应用程序,调整它,扩展它,并将它整合到你的项目中。人工智能的海洋广阔无垠,大部分尚未探索;像Orca这样的工具是你的航船。扬帆起航,看看这些潮流将把你带向何方。可能性是无限的,也同样令人兴奋。
感谢您与我一起深入AI的海洋。直到我们的下一次技术冒险,祝您编程愉快!
要查看完整的代码,请访问Orca。我很乐意听取您对它的想法和建议。此外,欢迎贡献者加入!
Orca链接: https://github.com/scrippt-tech/orca
Candle链接: https://github.com/huggingface/candle