越大并非越好:如何为特定任务选择最高效的模型 🌱🧑🏼💻







| TL;DR - 鉴于Hub上存在各种各样的开源AI模型,有时很难为特定领域任务选择最合适的模型。但值得考虑的是模型在实践中的实际部署环境,并进行测试和评估,以便根据准确性和效率来选择模型。在我们的实证实验中,我们发现许多小型模型在过程中使用的能量要少几个数量级,但性能却优于大型模型。 |
|---|
对于我们大多数人每天都在接触的技术,“人工智能”(AI)是一个总括性术语,实际上可以指代多种不同类型的方法——从可以在手机上运行的简单文本分类模型,到需要多个专用GPU的拥有数百亿参数的基于Transformer的模型。
虽然我们确实读到了很多关于大型模型最先进成果的新闻标题,但用于比较AI模型的通用基准和评估方法并不能代表AI从业者在不同实践领域中进行的各种特定任务。当我们默认使用大型、计算密集型文本生成模型时,我们认为它们最适合任何任务,但这会给环境带来成本,因为运行它们需要大量的能源和自然资源。这就是为什么在选择正确的模型来执行正确的任务时,同时考虑性能和效率非常重要。
评估模型性能和效率 🚀
像AI能源分数这样的项目可以帮助初步了解模型的能源效率,但最终的能源消耗将取决于部署期间使用的硬件和优化设置。因此,在**现场**测试候选模型非常有用,评估它们在代表模型部署时将接收的数据类型或类似现有数据集的样本数据上的性能。
作为比较不同AI模型性能和效率的特定任务示例,我们使用了来自不同领域和知识的3份报告:
- IPCC 2023年综合报告,共80页,描述了当前关于人为气候变化的科学知识状况。
- 2024年世界银行年度报告,对世界经济、社会流动性和政治状况进行了分析。
- 世界卫生组织发布的2024年世界卫生统计报告,是全球健康和健康相关指标的年度汇编。
我们使用YourBench动态基准生成框架,为每份报告生成60个问题,并评估9个不同大小和架构的模型在这些问题上的表现。在底层,YourBench框架使用了Lighteval评估工具包,它采用了“LLM作为评判者”的方法——在这种情况下,利用QwQ-32B模型——以实现黄金标准答案与不同模型提供的答案之间的比较。
我们评估了9个不同架构和大小的模型在为每份报告生成的问题上的表现。为了估算每个查询所使用的能量,我们计算了每个模型运行硬件的TDP(热设计功耗),并将其乘以响应问题所需的时间——这为我们提供了总能量使用量的近似值。评估结果如下表所示:
2023年IPCC报告 🌎
IPCC(政府间气候变化专门委员会)是联合国负责评估与气候变化相关科学的机构。每隔5-7年,他们都会发布报告,旨在呈现该主题的最新研究成果,从气候模式的实证观测到其社会经济影响。这些报告的不同版本可供不同受众使用,从针对政策制定者的几十页执行摘要到针对专家的数百页深入报告。
在我们的研究中,我们选取了2023年报告的中间版本(80页),并生成了诸如“全球变暖如何影响火灾季节的长度?”和“气候变化导致的一些缓慢发生事件有哪些例子,它们如何影响生态系统和人类社会?”等问题。评估结果(包括准确性和估计能量)如下所示:
| 模型 | 参数 | 持续时间(秒) | 准确率 | 估计能量(瓦时) |
|---|---|---|---|---|
| Qwen3-235B-A22B | 235亿 | 429.44 | 0.867 | 286 |
| phi-4 | 14.7亿 | 130.53 | 0.8 | 12.69 |
| Qwen2.5-72B-Instruct | 720亿 | 147.89 | 0.767 | 65.77 |
| Qwen3-32B | 320亿 | 167.97 | 0.733 | 65.32 |
| DeepSeek-R1-Distill-Qwen-32B | 320亿 | 441.23 | 0.733 | 35.30 |
| Llama-3.3-70B-Instruct | 700亿 | 336.71 | 0.567 | 149.64 |
| Phi-3-mini-4k-instruct | 38.2亿 | 103.79 | 0.533 | 2 |
| c4ai-command-r-plus-08-2024 | 1040亿 | 482.24 | 0.533 | 428.44 |
| Llama-3.1-8B-Instruct | 80亿 | 279.95 | 0.52 | 5.6 |
我们可以看到,最大的模型Qwen3-235B是表现最好的模型,但排名第二的Phi 4模型,只有15B,排名第二,分数低7%,但对于同一组问题,使用的**能量却少了24倍**。这表明,如果事先对模型进行性能和效率评估,就可以节省大量的能源和计算。此外,虽然表现最好的模型处于规模较大的一端,但中等规模(32B)的模型竞争力很强,表现优于Llama-3.3-70B和Command-R-plus等模型。
通过气泡图(气泡大小代表模型大小)绘制准确性和能量,我们可以清楚地看到准确性和能量之间的权衡——尽管Qwen3-235B模型在性能方面表现出色,但它比图左侧的小型模型耗能得多。

2024年世界银行报告 🏦
世界银行是一个国际金融机构,旨在提供贷款和资金,以支持经济发展和减少贫困。在他们的年度报告中,他们提供了关于其运营和倡议的最新信息,以及其资助方法在不同国家和地区产生的影响的见解。这些报告旨在作为其投资的公开记录,并帮助研究人员和政策制定者跟踪全球宏观经济事件的演变。
从报告中生成的问题涉及世界银行活动的战略方面(“世界银行在西非和中非投资的主要目标是什么?”)以及具体项目和指标(“自2015财年以来,有多少妇女和女孩受益于国际开发协会的资源,以及支持了哪些类型的行动?”)。结果如下所示:
| 模型 | 参数 | 持续时间(秒) | 准确率 | 估计能量(瓦时) |
|---|---|---|---|---|
| Qwen3-235B-A22B | 235亿 | 571.82 | 0.54 | 381 |
| Llama-3.3-70B-Instruct | 700亿 | 176.39 | 0.53 | 78.2 |
| phi-4 | 14.7亿 | 114.48 | 0.53 | 11.0 |
| Qwen3-32B | 320亿 | 164.54 | 0.467 | 16 |
| Qwen2.5-72B-Instruct | 720亿 | 142.48 | 0.467 | 15.77 |
| DeepSeek-R1-Distill-Qwen-32B | 320亿 | 278.44 | 0.4 | 22.24 |
| Phi-3-mini-4k-instruct | 38.2亿 | 95.5 | 0.4 | 1.9 |
| Llama-3.1-8B-Instruct | 80亿 | 222.88 | 0.367 | 4.46 |
| c4ai-command-r-plus-08-2024 | 1040亿 | 331.9 | 0.233 | 295.1 |
这项任务的第一名和第二名之间的差异不那么显著,Llama-3.3(70B)在相同准确度下比Qwen 3-235B使用的能量少5倍——如果这些模型每天被部署以响应数百万个查询,这仍然会累积起来。同样有趣的是,Qwen较新的小型(32B)版本表现与较旧、较大的(72B)版本一样好——这表明随着数据质量和模型性能方面的进步,选择最新一代的模型可以带来巨大的性能提升。
在这种情况下,我们可以看到Qwen-235B模型在所有测试模型中耗能最多,以实现其高精度,比Phi 4多35倍以上,而Phi 4实现了非常相似的性能。

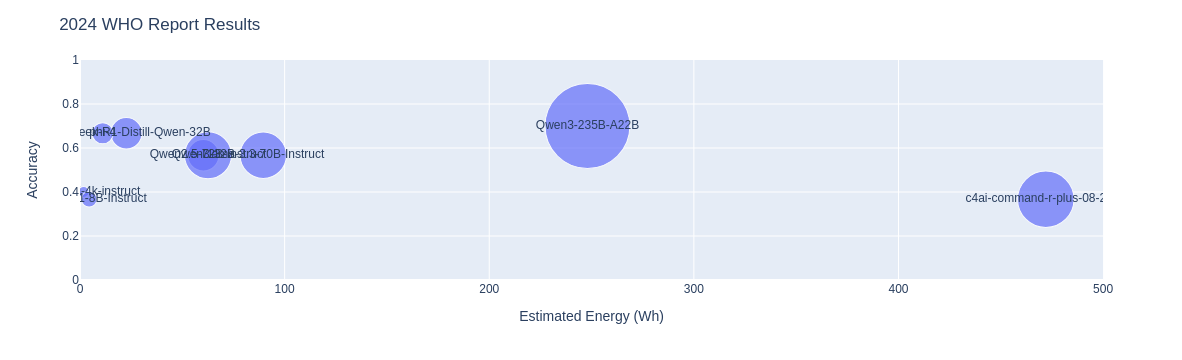
2024年世界卫生统计报告 ⚕️
世界卫生组织 (WHO) 是联合国的一个机构,致力于全球健康和安全,跟踪全球健康趋势,并协调国际行动应对流行病等全球健康紧急情况。他们每年都会发布一份报告,其中包含大量关于健康模式如何随时间变化的统计数据和分析,并允许政府机构和政策制定者制定自己的地方应对措施和战略。
从报告中生成的问题包括“2000年至2019年,男性和女性的预期寿命和健康预期寿命的增长有何不同?”和“2000年至2019年,全球主要死因模式发生了怎样的变化?”模型评估结果如下所示:
| 模型 | 参数 | 持续时间(秒) | 准确率 | 估计能量(瓦时) |
|---|---|---|---|---|
| Qwen3-235B-A22B | 235亿 | 372.05 | 0.7 | 248 |
| DeepSeek-R1-Distill-Qwen-32B | 320亿 | 283.11 | 0.667 | 22.64 |
| phi-4 | 14.7亿 | 114.13 | 0.667 | 11.08 |
| Qwen3-32B | 320亿 | 154.69 | 0.567 | 60.28 |
| Qwen2.5-72B-Instruct | 720亿 | 140.75 | 0.567 | 62.56 |
| Llama-3.3-70B-Instruct | 700亿 | 201.51 | 0.567 | 89.55 |
| Phi-3-mini-4k-instruct | 38.3亿 | 89.8 | 0.4 | 1.8 |
| Llama-3.1-8B-Instruct | 80亿 | 222.88 | 0.367 | 4.46 |
| c4ai-command-r-plus-08-2024 | 1040亿 | 531.09 | 0.367 | 472 |
在顶级模型(也是Qwen3-235B!)和亚军模型(DeepSeek-R1-Distill-Qwen-32B)之间的能量使用方面,差异高达11倍,而性能差异仅为3%。再一次,较新一代的小型模型(Qwen3-32B)表现与其更大更旧的对应模型以及像LLaMa 3.3和Command-R Plus这样的大型模型一样好。
要点 📚
总而言之,值得注意的是:
- 相对较小的(15B)**Phi-4 在所有任务中都排名前三**,这表明即使是适合单个 GPU 的模型也可能优于需要节点(例如 100B 和 200B 模型)的模型。
- 对于某些任务,效率最高和效率最低的模型之间的差异超过**200倍的能量消耗**!
- 新一代模型通常**优于同系列旧版、更大的模型**——例如,Qwen3-32B 在 3 个任务中有 2 个任务优于 Quen2.5-72B。
- DeepSeek-R1 的精简版(Distill-Qwen-32B)也始终表现出色,**显示了知识蒸馏**在减少所需计算量方面的优势(原始 DeepSeek-R1 模型有 685B 参数)。
虽然此分析仅限于我们能够测试和比较的一小部分模型,但它说明了在选择部署到生产的模型之前测试不同架构和大小模型的重要性,因为即使是查询能量的微小差异,在模型被使用数千次甚至数百万次时也会累积起来。





