Colpali、Milvus 和 VLM 实现多模态 RAG







在这篇文章中,我们将探讨如何使用 colpali、milvus 和视觉语言模型(Gemini/gpt-4o)实现多模态 RAG。
我们将构建一个应用程序,允许用户上传 PDF 并对其进行问答查询。问答可以针对 PDF 的文本和视觉元素进行。我们不会从 PDF 中提取文本;相反,我们会将其视为图像,并使用 colpali 获取 PDF 页面的嵌入。这些嵌入将被索引到 Milvus,然后我们将使用 VLM 对 PDF 页面进行问答查询。
如果您只想查看代码运行情况,可以在 https://huggingface.co/spaces/saumitras/colpali-milvus 上找到演示。相关代码请参阅此处。
目录:
- 问题
- 为什么要用 colpali?
- 理解 colpali 的工作原理
- 上传 PDF,使用 colpali 获取嵌入,将其索引到 Milvus,然后使用视觉语言模型(Gemini/OpenAI)进行问答查询的代码
问题
假设一家公司希望为其内部文档(包括 PDF、Word 文件、维基、图像和文本文件)构建问答/搜索界面。传统方法涉及提取文本和媒体、检测布局以获取结构,然后将信息索引到向量存储中进行语义搜索。然而,这种方法对于包含图像、表格和图表的复杂文档往往不足。我们来看一个下面的例子
我们有一个包含新冠疫情统计图表和表格的 PDF 文件。我们想回答以下查询
1. What is the correlation between the samples tested and the positivity rate?
2. When and what was the highest number of cases and TPR?
3. Which country had the highest omicron cases?
这些查询可以通过以下 3 页的数据来回答
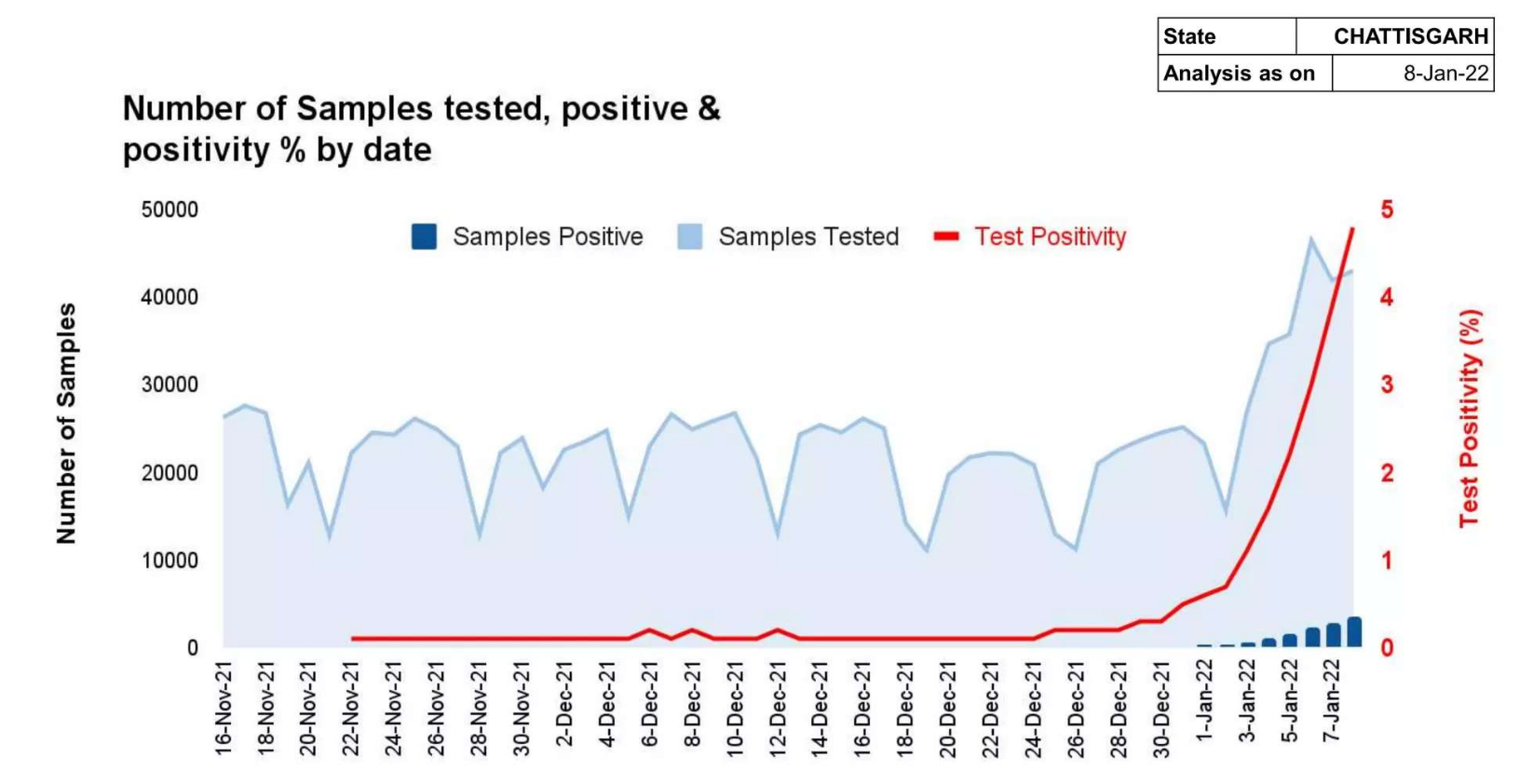
第 4 页:显示样本和阳性率统计数据的图表
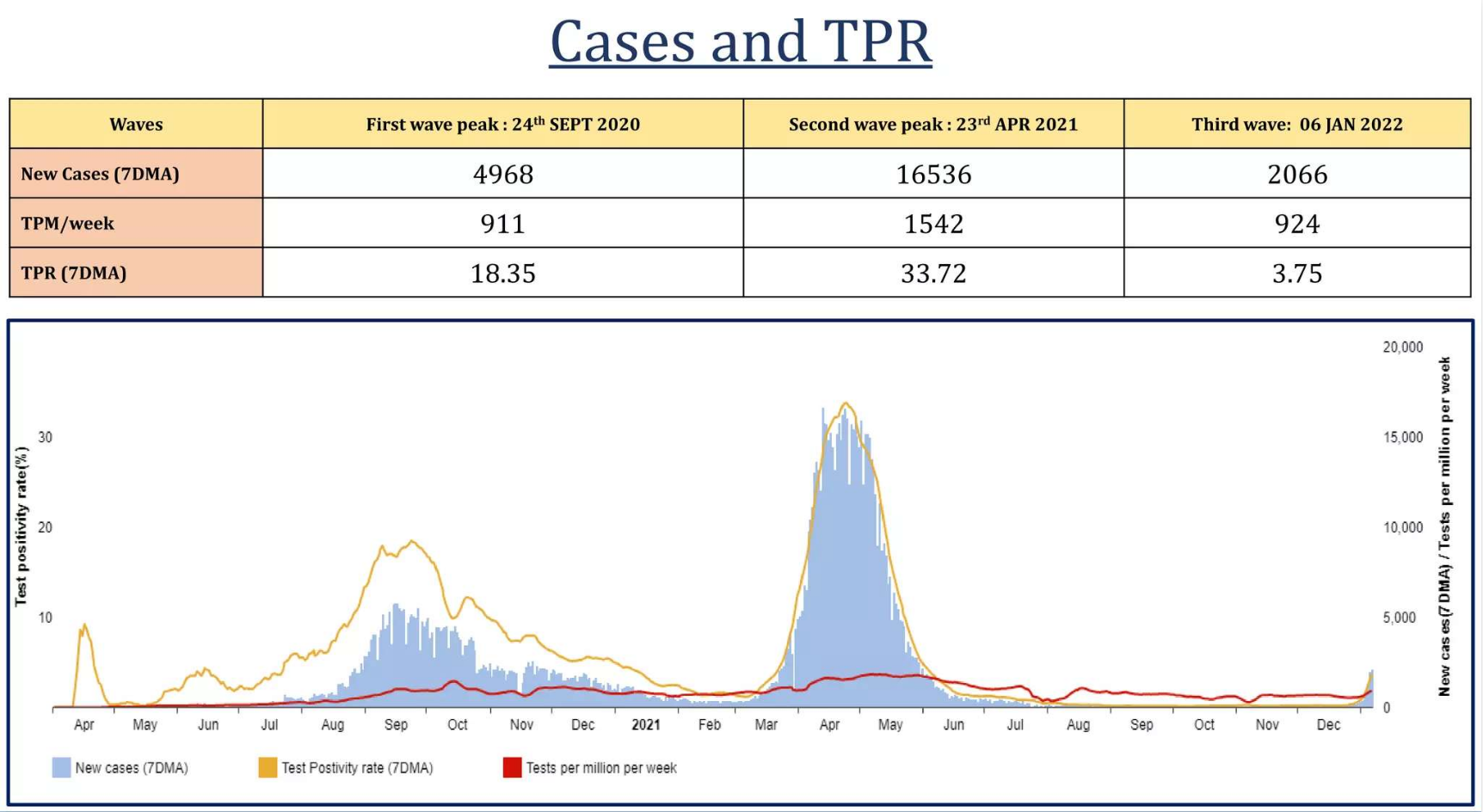
第 8 页:显示病例和 TPR 的表格
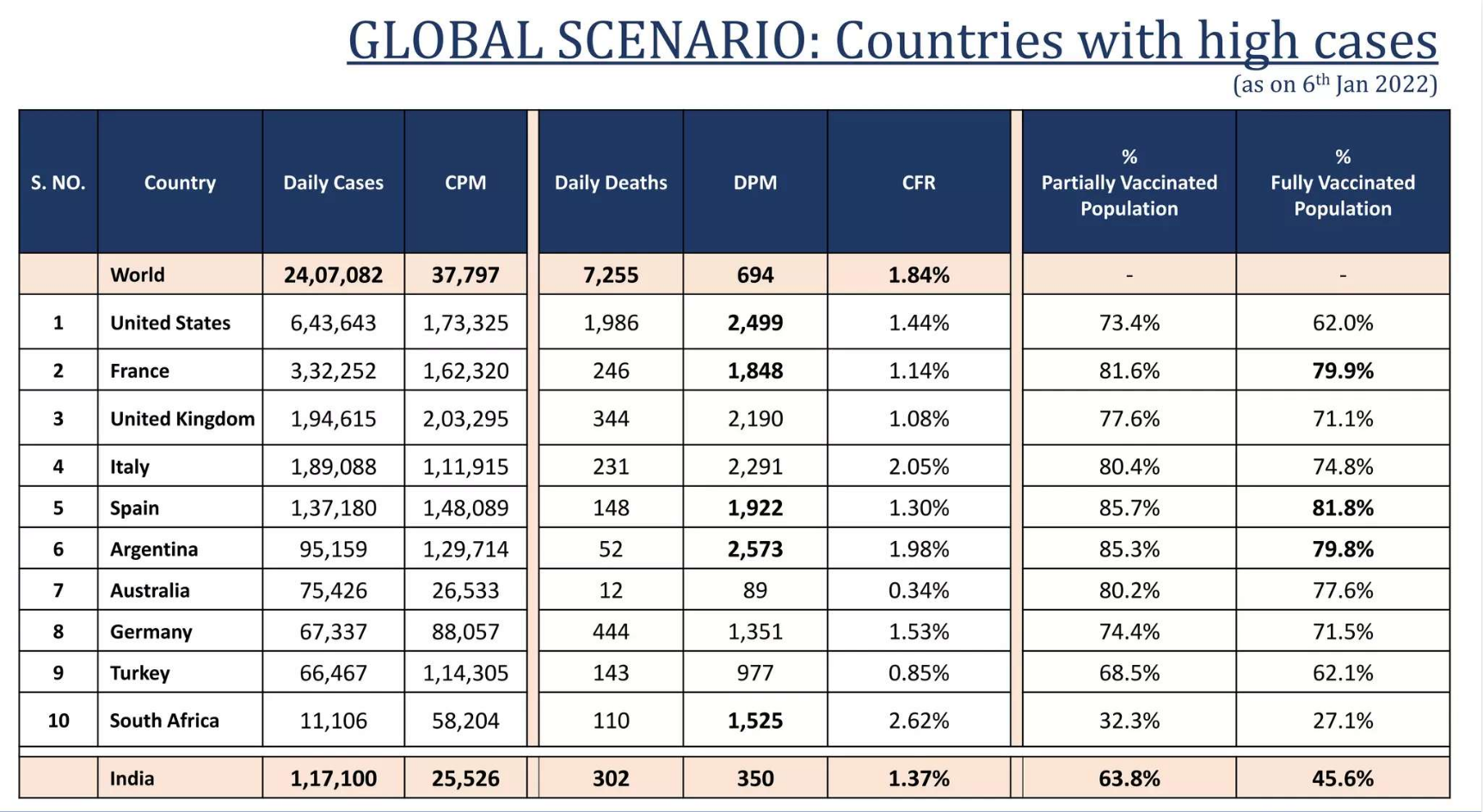
第 9 页:按国家/地区显示病例的表格
以可用于查询的方式从这些页面中提取数据作为文本会很困难。我们希望向用户显示答案以及包含答案的 PDF 源页面,如下图所示
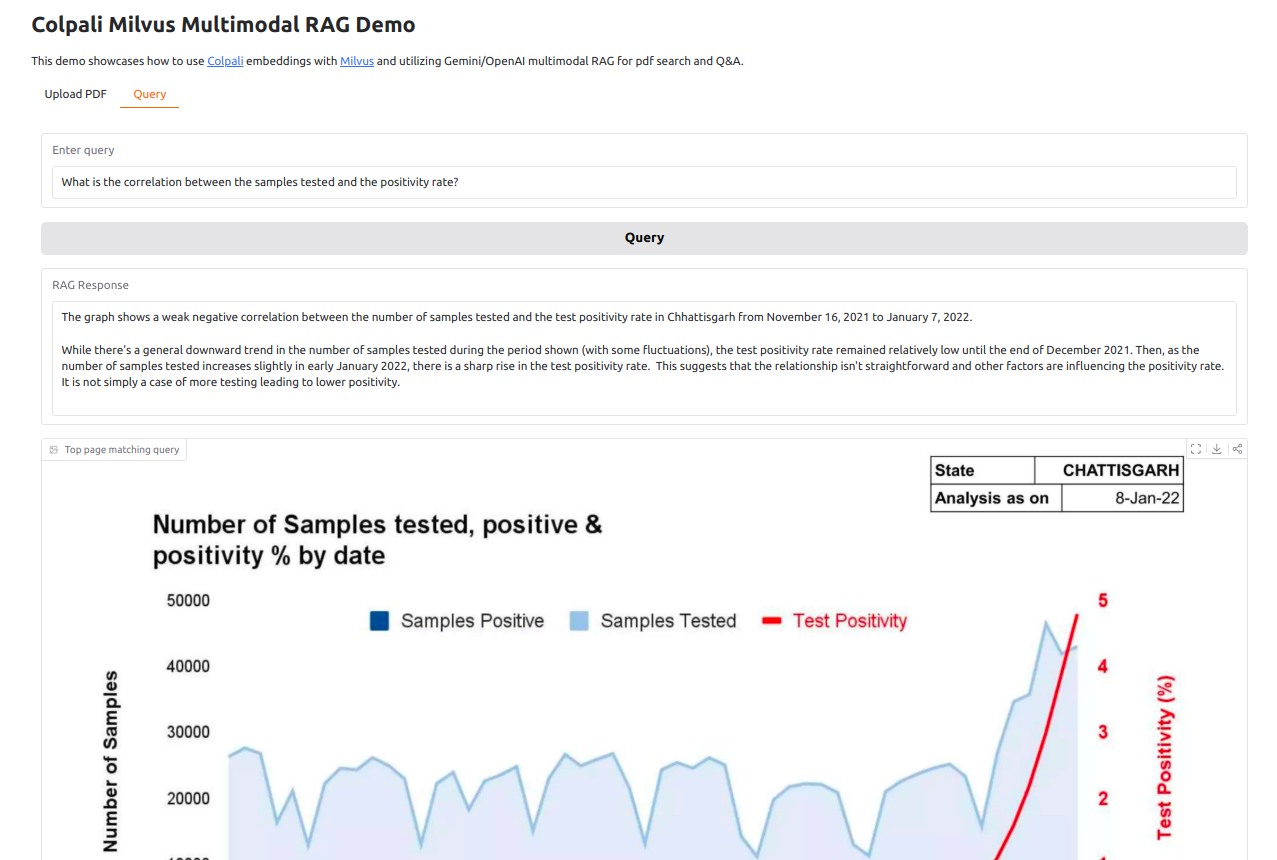
让我们了解 colpali 如何在这里帮助我们。
为什么要用 colpali?
文档检索一直是搜索引擎和信息检索等系统的关键组成部分。传统的文档检索方法严重依赖基于文本的方法(如 OCR 和文本分割),但往往会遗漏重要的视觉线索,如布局、图像和表格。
Colpali 通过使用视觉语言模型 (VLM) 来理解和检索视觉丰富的文档,捕捉文本和视觉信息,从而解决了这个问题。Colpali 的架构允许将文档图像直接编码到公共嵌入空间中,从而无需耗时的文本提取和分割。
理解 colpali 的工作原理
Colpali 的工作步骤如下
第一步:将文档视为图像
想象一下我们有一个 PDF 文档。通常,我们会使用 OCR(光学字符识别)从文档中提取文本,将其分割成不同的部分,然后使用这些部分进行搜索。Colpali 通过将整个文档页面视为图像来简化此过程,从而无需复杂的文本提取、布局检测或 OCR。
第二步:将图像分割成小块
Colpali 得到文档的“图像”后,会将其分割成称为“补丁”的小而均匀的部分。每个补丁都捕捉页面的一小部分。它可能包含几个单词、图表的一部分或图像的一部分。这种划分有助于模型专注于文档的微小细节部分,而不是试图一次性理解整个页面。
乍一看,将图像分割成补丁可能类似于将文本分割成块。然而,这两种方法有几个关键区别,特别是在处理和保留上下文方面。让我们深入探讨这些区别,以了解为什么 colpali 中的基于补丁的处理对于文档检索比传统的文本分块更有效。
了解文本分块中的上下文丢失
在传统的文本分块中,文本根据某些标记被分割成更小的块,因为许多模型限制了它们可以一次处理的标记数量。
上下文丢失问题
- 分块可能会将句子或段落中途分割,导致关键上下文丢失。它还可能导致一个块中的信息不完整,而另一个块中缺少上下文。分块不保留视觉或结构信息,例如标题与其相应内容之间的关系,或文本在表格或图中的位置。
例如,如果您的文档中有一个标题后面跟着一个表格,文本分块可能会将标题和表格分开,从而丢失表格属于该标题的上下文。
Colpali 中基于补丁的图像处理
Colpali 将文档图像分割成补丁,就像将照片分割成小方块一样。每个补丁都是图像的固定大小部分,就像页面该部分的一个小快照。
补丁之所以更有效,原因如下:
- 不丢失结构:这些补丁保留了文档的视觉结构,保留了其空间布局。例如,如果页面有两列文本或一个带有行和列表格,则每个补丁都会保持其相对位置,确保模型理解元素的整体排列。
- 多模态上下文:补丁捕获文本和视觉信息。这包括视觉特征(例如,字体样式、颜色、粗体)和非文本元素(例如,图形和图表)。
- 位置感知:每个补丁都有一个位置嵌入,告诉模型它在页面上的位置,帮助模型理解整体布局。
第三步:创建嵌入并**对齐视觉和文本信息**
每个补丁随后通过一个视觉转换器(ViT),将其转换为独特的嵌入。接下来,colpali 通过将查询转换为其自己的嵌入集,将这些视觉嵌入与查询文本对齐。colpali 使用一个称为“对齐”的过程,将图像路径嵌入和文本嵌入对齐到相同的向量空间中。只有这样,我们才能比较查询和文档嵌入之间的相似性。
第四步:对相关性进行评分——后期交互机制
此时,colpali 已经拥有了查询和文档的嵌入。接下来的挑战是识别文档中的相关部分。colpali 使用一种称为“后期交互机制”的过程,将查询的每个部分与文档的每个部分进行精细匹配,并对其相关性进行评分和排序。
Colpali 突出显示文档中最相关的部分,重点关注与查询最匹配的补丁。这种方法使 Colpali 能够高效地从视觉丰富的文档中检索相关信息,捕获视觉和文本数据而不会丢失上下文。
代码
完整代码见 https://github.com/saumitras/colpali-milvus-rag/
1. 添加 colpali 处理器
model_name = "vidore/colpali-v1.2"
device = get_torch_device("cuda")
model = colpali.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map=device,
).eval()
processor = cast(colpaliProcessor, colpaliProcessor.from_pretrained(model_name))
2. 使用 colpali 获取图像(PDF 页面)的嵌入
def process_images(self, image_paths:list[str], batch_size=5):
print(f"Processing {len(image_paths)} image_paths")
images = self.get_images(image_paths)
dataloader = DataLoader(
dataset=ListDataset[str](images),
batch_size=batch_size,
shuffle=False,
collate_fn=lambda x: processor.process_images(x),
)
ds: List[torch.Tensor] = []
for batch_doc in tqdm(dataloader):
with torch.no_grad():
batch_doc = {k: v.to(model.device) for k, v in batch_doc.items()}
embeddings_doc = model(**batch_doc)
ds.extend(list(torch.unbind(embeddings_doc.to(device))))
ds_np = [d.float().cpu().numpy() for d in ds]
return ds_np
3. 使用 colpali 获取文本(用户查询)的嵌入
def process_text(self, texts: list[str]):
print(f"Processing {len(texts)} texts")
dataloader = DataLoader(
dataset=ListDataset[str](texts),
batch_size=1,
shuffle=False,
collate_fn=lambda x: processor.process_queries(x),
)
qs: List[torch.Tensor] = []
for batch_query in dataloader:
with torch.no_grad():
batch_query = {k: v.to(model.device) for k, v in batch_query.items()}
embeddings_query = model(**batch_query)
qs.extend(list(torch.unbind(embeddings_query.to(device))))
qs_np = [q.float().cpu().numpy() for q in qs]
return qs_np
4. 在 Milvus 中创建集合、索引和查询的代码
class MilvusManager:
def __init__(self, milvus_uri, collection_name, create_collection, dim=128):
self.client = MilvusClient(uri=milvus_uri)
self.collection_name = collection_name
if self.client.has_collection(collection_name=self.collection_name):
self.client.load_collection(collection_name)
self.dim = dim
if create_collection:
self.create_collection()
self.create_index()
def create_collection(self):
if self.client.has_collection(collection_name=self.collection_name):
self.client.drop_collection(collection_name=self.collection_name)
schema = self.client.create_schema(
auto_id=True,
enable_dynamic_fields=True,
)
schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True)
schema.add_field(
field_name="vector", datatype=DataType.FLOAT_VECTOR, dim=self.dim
)
schema.add_field(field_name="seq_id", datatype=DataType.INT16)
schema.add_field(field_name="doc_id", datatype=DataType.INT64)
schema.add_field(field_name="doc", datatype=DataType.VARCHAR, max_length=65535)
self.client.create_collection(
collection_name=self.collection_name, schema=schema
)
def create_index(self):
self.client.release_collection(collection_name=self.collection_name)
self.client.drop_index(
collection_name=self.collection_name, index_name="vector"
)
index_params = self.client.prepare_index_params()
index_params.add_index(
field_name="vector",
index_name="vector_index",
index_type="HNSW",
metric_type="IP",
params={
"M": 16,
"efConstruction": 500,
},
)
self.client.create_index(
collection_name=self.collection_name, index_params=index_params, sync=True
)
def create_scalar_index(self):
self.client.release_collection(collection_name=self.collection_name)
index_params = self.client.prepare_index_params()
index_params.add_index(
field_name="doc_id",
index_name="int32_index",
index_type="INVERTED",
)
self.client.create_index(
collection_name=self.collection_name, index_params=index_params, sync=True
)
def search(self, data, topk):
search_params = {"metric_type": "IP", "params": {}}
results = self.client.search(
self.collection_name,
data,
limit=int(50),
output_fields=["vector", "seq_id", "doc_id"],
search_params=search_params,
)
doc_ids = set()
for r_id in range(len(results)):
for r in range(len(results[r_id])):
doc_ids.add(results[r_id][r]["entity"]["doc_id"])
scores = []
def rerank_single_doc(doc_id, data, client, collection_name):
doc_colbert_vecs = client.query(
collection_name=collection_name,
filter=f"doc_id in [{doc_id}, {doc_id + 1}]",
output_fields=["seq_id", "vector", "doc"],
limit=1000,
)
doc_vecs = np.vstack(
[doc_colbert_vecs[i]["vector"] for i in range(len(doc_colbert_vecs))]
)
score = np.dot(data, doc_vecs.T).max(1).sum()
return (score, doc_id)
with concurrent.futures.ThreadPoolExecutor(max_workers=300) as executor:
futures = {
executor.submit(
rerank_single_doc, doc_id, data, self.client, self.collection_name
): doc_id
for doc_id in doc_ids
}
for future in concurrent.futures.as_completed(futures):
score, doc_id = future.result()
scores.append((score, doc_id))
scores.sort(key=lambda x: x[0], reverse=True)
if len(scores) >= topk:
return scores[:topk]
else:
return scores
def insert(self, data):
colbert_vecs = [vec for vec in data["colbert_vecs"]]
seq_length = len(colbert_vecs)
doc_ids = [data["doc_id"] for i in range(seq_length)]
seq_ids = list(range(seq_length))
docs = [""] * seq_length
docs[0] = data["filepath"]
self.client.insert(
self.collection_name,
[
{
"vector": colbert_vecs[i],
"seq_id": seq_ids[i],
"doc_id": doc_ids[i],
"doc": docs[i],
}
for i in range(seq_length)
],
)
def get_images_as_doc(self, images_with_vectors:list):
images_data = []
for i in range(len(images_with_vectors)):
data = {
"colbert_vecs": images_with_vectors[i]["colbert_vecs"],
"doc_id": i,
"filepath": images_with_vectors[i]["filepath"],
}
images_data.append(data)
return images_data
def insert_images_data(self, image_data):
data = self.get_images_as_doc(image_data)
for i in range(len(data)):
self.insert(data[i])
5. 将 PDF 保存为单独的图像
class PdfManager:
def __init__(self):
pass
def clear_and_recreate_dir(self, output_folder):
print(f"Clearing output folder {output_folder}")
if os.path.exists(output_folder):
shutil.rmtree(output_folder)
os.makedirs(output_folder)
def save_images(self, id, pdf_path, max_pages, pages: list[int] = None) -> list[str]:
output_folder = f"pages/{id}/"
images = convert_from_path(pdf_path)
print(f"Saving images from {pdf_path} to {output_folder}. Max pages: {max_pages}")
self.clear_and_recreate_dir(output_folder)
num_page_processed = 0
for i, image in enumerate(images):
if max_pages and num_page_processed >= max_pages:
break
if pages and i not in pages:
continue
full_save_path = f"{output_folder}/page_{i + 1}.png"
image.save(full_save_path, "PNG")
num_page_processed += 1
return [f"{output_folder}/page_{i + 1}.png" for i in range(num_page_processed)]
6. 中间件,用于索引和搜索 Milvus 中由 colpali 生成的嵌入
class Middleware:
def __init__(self, id:str, create_collection=True):
hashed_id = hashlib.md5(id.encode()).hexdigest()[:8]
milvus_db_name = f"milvus_{hashed_id}.db"
self.milvus_manager = MilvusManager(milvus_db_name, "colpali", create_collection)
def index(self, pdf_path: str, id:str, max_pages: int, pages: list[int] = None):
print(f"Indexing {pdf_path}, id: {id}, max_pages: {max_pages}")
image_paths = pdf_manager.save_images(id, pdf_path, max_pages)
print(f"Saved {len(image_paths)} images")
colbert_vecs = colpali_manager.process_images(image_paths)
images_data = [{
"colbert_vecs": colbert_vecs[i],
"filepath": image_paths[i]
} for i in range(len(image_paths))]
print(f"Inserting {len(images_data)} images data to Milvus")
self.milvus_manager.insert_images_data(images_data)
print("Indexing completed")
return image_paths
def search(self, search_queries: list[str]):
print(f"Searching for {len(search_queries)} queries")
final_res = []
for query in search_queries:
print(f"Searching for query: {query}")
query_vec = colpali_manager.process_text([query])[0]
search_res = self.milvus_manager.search(query_vec, topk=1)
print(f"Search result: {search_res} for query: {query}")
final_res.append(search_res)
return final_res
7. 使用 Gemini 或 gpt-4o 对与用户查询匹配的 PDF 页面进行问答
class Rag:
def get_answer_from_gemini(self, query, imagePaths):
print(f"Querying Gemini for query={query}, imagePaths={imagePaths}")
try:
genai.configure(api_key=os.environ['GEMINI_API_KEY'])
model = genai.GenerativeModel('gemini-1.5-flash')
images = [Image.open(path) for path in imagePaths]
chat = model.start_chat()
response = chat.send_message([*images, query])
answer = response.text
print(answer)
return answer
except Exception as e:
print(f"An error occurred while querying Gemini: {e}")
return f"Error: {str(e)}"
def get_answer_from_openai(self, query, imagesPaths):
print(f"Querying OpenAI for query={query}, imagesPaths={imagesPaths}")
try:
payload = self.__get_openai_api_payload(query, imagesPaths)
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {os.environ['OPENAI_API_KEY']}"
}
response = requests.post(
url="https://api.openai.com/v1/chat/completions",
headers=headers,
json=payload
)
response.raise_for_status() # Raise an HTTPError for bad responses
answer = response.json()["choices"][0]["message"]["content"]
print(answer)
return answer
except Exception as e:
print(f"An error occurred while querying OpenAI: {e}")
return None
def __get_openai_api_payload(self, query:str, imagesPaths:List[str]):
image_payload = []
for imagePath in imagesPaths:
base64_image = encode_image(imagePath)
image_payload.append({
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{base64_image}"
}
})
payload = {
"model": "gpt-4o",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": query
},
*image_payload
]
}
],
"max_tokens": 1024
}
return payload
在下一篇文章中,我们将了解 colpali 的局限性及其解决方法。

