使用 Mistral-7B 在单 GPU 上进行多标签分类,并结合量化和 LoRA








大型语言模型(LLM)在解决各种任务方面展现出令人印象深刻的能力,不仅限于自然语言,还包括多模态环境。由于它们的庞大体量(“较小”的 LLM 仍有超过 10 亿个参数)和硬件要求,对于没有大量计算预算的人来说,直接对它们进行微调并不容易。然而,有一些技术可以减少参数数量并提高这些模型的效率,例如 LoRA 和量化。本文将演示如何使用 Huggingface (HF) 库 transformers、bitsandbytes 和 peft 来实现这些方法。我还会向您展示如何将最先进的 LLM Mistral 7b 应用于多类别分类任务。本指南绝非同类首创,还有其他出色的资源涵盖此主题,例如这篇。尽管如此,我没有找到任何关于多类别分类的特定资源,这就是为什么我希望这篇文章对某些人有帮助的原因。下面代码示例所用的 Python 脚本可以在这里找到:仓库链接
导入
以下代码片段所需的所有导入
import os
import random
import functools
import csv
import numpy as np
import torch
import torch.nn.functional as F
from sklearn.metrics import f1_score
from skmultilearn.model_selection import iterative_train_test_split
from datasets import Dataset, DatasetDict
from peft import (
LoraConfig,
prepare_model_for_kbit_training,
get_peft_model
)
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
Trainer
)
数据集
我们将使用这个Kaggle 数据集,该数据集基于标题和摘要进行研究文章的主题建模。
数据示例
ID: 5
标题:离散小波变换和小波张量分解在药用植物 FTIR 数据特征提取中的比较研究
摘要:使用 7 种植物样本的傅里叶变换红外(FTIR)光谱来探索预处理和特征提取对机器学习算法效率的影响。……
计算机科学: 1
物理: 0
数学: 0
统计: 1
定量生物学: 0
定量金融: 0
我们从 train.csv 创建一个 HF 数据集,因为在使用 HF 库的其他函数/类时需要这样做。
# set random seed
random.seed(0)
# load data
with open('train.csv', newline='') as csvfile:
data = list(csv.reader(csvfile, delimiter=','))
header_row = data.pop(0)
# shuffle data
random.shuffle(data)
# reshape
idx, text, labels = list(zip(*[(int(row[0]), f'Title: {row[1].strip()}\n\nAbstract: {row[2].strip()}', row[3:]) for row in data]))
labels = np.array(labels, dtype=int)
# create label weights
label_weights = 1 - labels.sum(axis=0) / labels.sum()
# stratified train test split for multilabel ds
row_ids = np.arange(len(labels))
train_idx, y_train, val_idx, y_val = iterative_train_test_split(row_ids[:,np.newaxis], labels, test_size = 0.1)
x_train = [text[i] for i in train_idx.flatten()]
x_val = [text[i] for i in val_idx.flatten()]
# create hf dataset
ds = DatasetDict({
'train': Dataset.from_dict({'text': x_train, 'labels': y_train}),
'val': Dataset.from_dict({'text': x_val, 'labels': y_val})
})
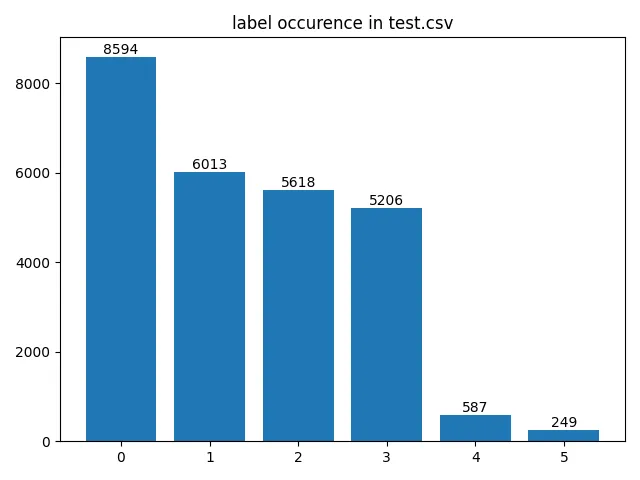
此代码片段中一个稍微不常见的包可能是 skmultilearn,我专门使用其中的 `iterative_train_test_split` 函数。这会为不平衡的多标签数据集创建均匀的划分,本示例就是这种情况,您可以在下面的可视化中看到。因此,我们还为标签生成权重,我们稍后将使用这些权重来计算损失,因为我们希望为代表性不足的类别分配更高的权重。使用加权损失函数当然非常取决于您的用例以及全局准确性与单个类别准确性之间的权衡成本。
初始化模型
接下来,我们将初始化模型和分词器。如引言所述,我们将使用 Mistral 7b,它在各种 NLP 基准测试中都表现出色。然而,下面的代码应该适用于 HF 中心库中的任何仅解码器 LLM。
为了微调,我们使用 LoRA 来学习两个低维差分矩阵,而不是必须微调整个参数矩阵。您可以在这篇论文中找到更多关于 LoRA 的详细信息。由于在使用 LoRA 进行微调期间我们不需要更改预训练参数,因此我们可以使用 HF 的 bitsandbytes 库对它们进行量化。除了我们的模型之外,我们当然还需要初始化一个分词器来预处理我们的数据集。
# model name
model_name = 'mistralai/Mistral-7B-v0.1'
# preprocess dataset with tokenizer
def tokenize_examples(examples, tokenizer):
tokenized_inputs = tokenizer(examples['text'])
tokenized_inputs['labels'] = examples['labels']
return tokenized_inputs
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
tokenized_ds = ds.map(functools.partial(tokenize_examples, tokenizer=tokenizer), batched=True)
tokenized_ds = tokenized_ds.with_format('torch')
# qunatization config
quantization_config = BitsAndBytesConfig(
load_in_4bit = True, # enable 4-bit quantization
bnb_4bit_quant_type = 'nf4', # information theoretically optimal dtype for normally distributed weights
bnb_4bit_use_double_quant = True, # quantize quantized weights //insert xzibit meme
bnb_4bit_compute_dtype = torch.bfloat16 # optimized fp format for ML
)
# lora config
lora_config = LoraConfig(
r = 16, # the dimension of the low-rank matrices
lora_alpha = 8, # scaling factor for LoRA activations vs pre-trained weight activations
target_modules = ['q_proj', 'k_proj', 'v_proj', 'o_proj'],
lora_dropout = 0.05, # dropout probability of the LoRA layers
bias = 'none', # wether to train bias weights, set to 'none' for attention layers
task_type = 'SEQ_CLS'
)
# load model
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
quantization_config=quantization_config,
num_labels=labels.shape[1]
)
model = prepare_model_for_kbit_training(model)
model = get_peft_model(model, lora_config)
model.config.pad_token_id = tokenizer.pad_token_id
正如您从 LoRAConfig 中的 `target_modules` 所看到的,我们仅将微调应用于注意力权重。这效果很好,并且参数效率更高,因为 Transformer 层中最大部分的参数来自我们冻结和量化的前馈网络。`r` 是 LoRA 矩阵的维度,在本例中为 4096x16 和 16x4096,比 Mistral 注意力层中的完整 4096x4096 权重矩阵小得多。
HF 类 `AutoModelForSequenceClassification` 在最后一个标记嵌入之上初始化基础模型,并带有一个额外的(未经训练的)线性分类层。该层自动排除在量化之外,我们将其与其余 LoRA 权重一起进行微调。
训练
在准备好数据集并设置好模型配置后,我们几乎可以开始使用 HF 的 Trainer 类微调模型了。但在此之前,我们必须定义一些 Trainer 将使用的自定义函数。
- 数据整理器
我们需要告诉训练器,它应该如何预处理来自数据集的批次,然后才能将其传递给模型。 - 指标
此外,我们还需要向训练器传递一个函数,该函数定义了我们除了损失之外想要计算的评估指标。
# define custom batch preprocessor
def collate_fn(batch, tokenizer):
dict_keys = ['input_ids', 'attention_mask', 'labels']
d = {k: [dic[k] for dic in batch] for k in dict_keys}
d['input_ids'] = torch.nn.utils.rnn.pad_sequence(
d['input_ids'], batch_first=True, padding_value=tokenizer.pad_token_id
)
d['attention_mask'] = torch.nn.utils.rnn.pad_sequence(
d['attention_mask'], batch_first=True, padding_value=0
)
d['labels'] = torch.stack(d['labels'])
return d
# define which metrics to compute for evaluation
def compute_metrics(p):
predictions, labels = p
f1_micro = f1_score(labels, predictions > 0, average = 'micro')
f1_macro = f1_score(labels, predictions > 0, average = 'macro')
f1_weighted = f1_score(labels, predictions > 0, average = 'weighted')
return {
'f1_micro': f1_micro,
'f1_macro': f1_macro,
'f1_weighted': f1_weighted
}
此外,我们还需要定义一个自定义的训练器类,以便能够计算我们的多标签损失,该损失将每个输出神经元视为一个二元分类实例。为了在损失计算中使用我们的标签权重,我们还需要在 `__init__` 方法中将其定义为类属性,以便 `compute_loss` 方法可以访问它。
# create custom trainer class to be able to pass label weights and calculate mutilabel loss
class CustomTrainer(Trainer):
def __init__(self, label_weights, **kwargs):
super().__init__(**kwargs)
self.label_weights = label_weights
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
# forward pass
outputs = model(**inputs)
logits = outputs.get("logits")
# compute custom loss
loss = F.binary_cross_entropy_with_logits(logits, labels.to(torch.float32), pos_weight=self.label_weights)
return (loss, outputs) if return_outputs else loss
现在一切就绪,我们可以让 HF 施展其魔力了。(根据您的 GPU 内存,您可能需要/想要调整批次大小,这在具有 16GB RAM 的 GPU 上进行了测试)
# define training args
training_args = TrainingArguments(
output_dir = 'multilabel_classification',
learning_rate = 1e-4,
per_device_train_batch_size = 8,
per_device_eval_batch_size = 8,
num_train_epochs = 10,
weight_decay = 0.01,
evaluation_strategy = 'epoch',
save_strategy = 'epoch',
load_best_model_at_end = True
)
# train
trainer = CustomTrainer(
model = model,
args = training_args,
train_dataset = tokenized_ds['train'],
eval_dataset = tokenized_ds['val'],
tokenizer = tokenizer,
data_collator = functools.partial(collate_fn, tokenizer=tokenizer),
compute_metrics = compute_metrics,
label_weights = torch.tensor(label_weights, device=model.device)
)
trainer.train()
# save model
peft_model_id = 'multilabel_mistral'
trainer.model.save_pretrained(peft_model_id)
tokenizer.save_pretrained(peft_model_id)
就是这样!您刚刚微调了一个最先进的 LLM 用于多标签分类。您可以使用从HF 文档中提取的此代码片段加载您保存的模型。
# load model
peft_model_id = 'multilabel_mistral'
model = AutoModelForSequenceClassification.from_pretrained(peft_model_id)
我希望通过这篇文章,我能够阐明如何利用 HF 实现的计算和内存高效技术(如 LoRA 和量化)来完成微调任务。根据我的经验,对于最直接的用例有很多文档,但一旦您的需求稍微偏离,就需要进行一些调整,例如定义自定义的 Trainer 类。





