无需真实数据的高效表格预训练:TAPEX 简介

近年来,语言模型预训练通过利用大规模文本数据取得了巨大成功。通过采用诸如掩码语言建模之类的预训练任务,这些模型在若干下游任务上展现了惊人的性能。然而,预训练任务(例如,语言建模)和下游任务(例如,表格问答)之间的巨大差距使得现有的预训练效率不够高。在实践中,我们通常需要 极其大量 的预训练数据才能获得有希望的改进,即使对于领域自适应预训练也是如此。我们如何设计一个预训练任务来缩小这一差距,从而加速预训练呢?
概览
在《TAPEX: Table Pre-training via Learning a Neural SQL Executor》一文中,我们探索了在预训练期间 使用合成数据作为真实数据的代理,并通过 TAPEX(Table Pre-training via Execution,通过执行进行表格预训练) 作为一个例子来展示其强大之处。在 TAPEX 中,我们表明表格预训练可以通过在合成语料库上学习一个神经 SQL 执行器来实现。
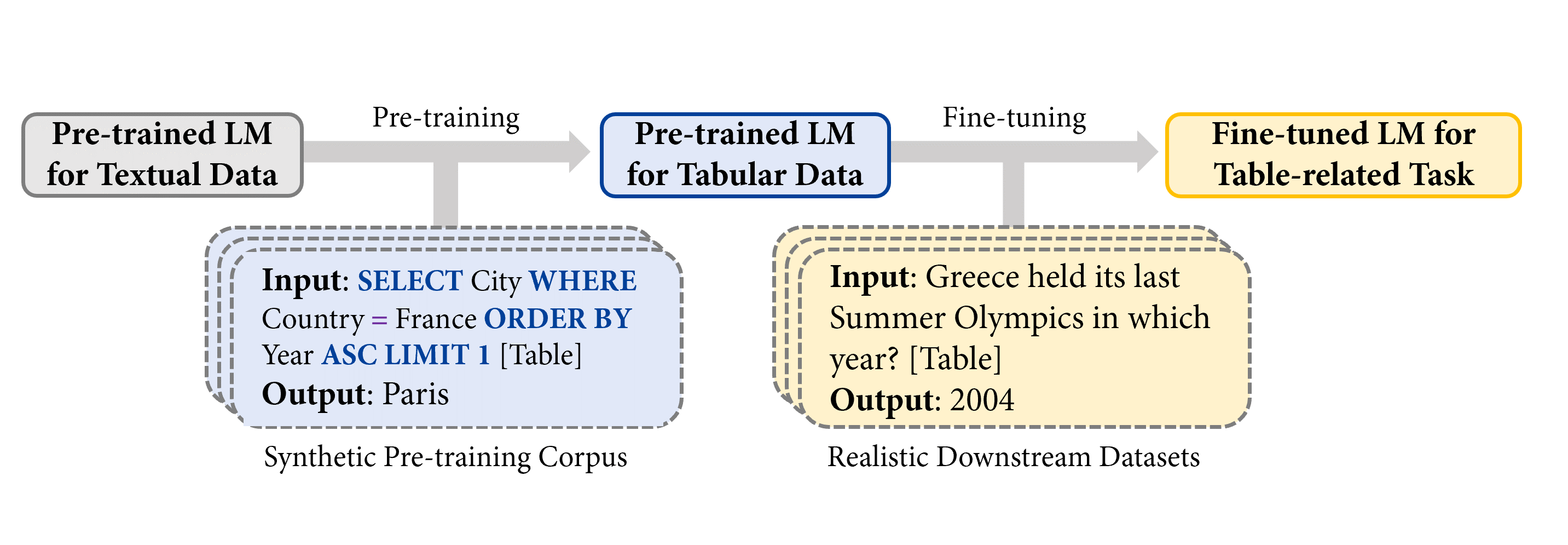
注意:[Table] 是输入中用户提供表格的占位符。
如上图所示,通过系统地采样表格上的 可执行 SQL 查询及其执行输出,TAPEX 首先合成了一个人造的非自然语言预训练语料库。然后,它继续预训练一个语言模型(例如,BART),使其输出 SQL 查询的执行结果,这模仿了一个神经 SQL 执行器的过程。
预训练
下图说明了预训练过程。在每一步,我们首先从网上获取一个表格。示例表格是关于奥运会的。然后我们可以采样一个可执行的 SQL 查询 SELECT City WHERE Country = France ORDER BY Year ASC LIMIT 1。通过一个现成的 SQL 执行器(例如,MySQL),我们可以得到查询的执行结果 Paris。类似地,通过将 SQL 查询和扁平化表格的拼接作为输入提供给模型(例如,BART 编码器),执行结果则作为监督信号提供给模型(例如,BART 解码器)作为输出。

为什么使用诸如 SQL 查询之类的程序而不是自然语言句子作为预训练的来源?最大的优势在于,与不可控的自然语言句子相比,程序的多样性和规模可以得到系统性的保证。因此,我们可以通过采样 SQL 查询轻松地合成一个多样化、大规模且高质量的预训练语料库。
你可以在 🤗 Transformers 中尝试训练好的神经 SQL 执行器,如下所示
from transformers import TapexTokenizer, BartForConditionalGeneration
import pandas as pd
tokenizer = TapexTokenizer.from_pretrained("microsoft/tapex-large-sql-execution")
model = BartForConditionalGeneration.from_pretrained("microsoft/tapex-large-sql-execution")
data = {
"year": [1896, 1900, 1904, 2004, 2008, 2012],
"city": ["athens", "paris", "st. louis", "athens", "beijing", "london"]
}
table = pd.DataFrame.from_dict(data)
# tapex accepts uncased input since it is pre-trained on the uncased corpus
query = "select year where city = beijing"
encoding = tokenizer(table=table, query=query, return_tensors="pt")
outputs = model.generate(**encoding)
print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
# ['2008']
微调
在微调期间,我们将自然语言问题和扁平化表格的拼接作为输入提供给模型,标注者标记的答案则作为监督信号提供给模型作为输出。想自己微调 TAPEX 吗?你可以在这里查看微调脚本,它已经正式集成到 🤗 Transformers 4.19.0 中!
截至目前,所有可用的 TAPEX 模型都已获得 Huggingface 官方支持的交互式小部件!你可以尝试回答一些问题,如下所示。
| 代码库 | 收藏数 (Stars) | 贡献者 | 编程语言 |
|---|---|---|---|
| Transformers | 36542 | 651 | Python |
| 数据集 | 4512 | 77 | Python |
| Tokenizers | 3934 | 34 | Rust、Python 和 NodeJS |
实验
我们在四个基准数据集上评估 TAPEX,包括 WikiSQL (Weak)、WikiTableQuestions、SQA 和 TabFact。前三个数据集是关于表格问答的,而最后一个是关于表格事实核查的,两者都需要对表格和自然语言进行联合推理。以下是一些来自最具挑战性的数据集 WikiTableQuestions 的例子:
| 问题 | 回答 |
|---|---|
| 根据表格,Spicy Horse 制作的最后一个游戏是什么? | Akaneiro: Demon Hunters |
| 科尔雷恩学术学院和皇家邓甘农学校的亚军人数有何差异? | 20 |
| 格林斯特里特参演的第一部和最后一部电影分别是什么? | 马耳他之鹰,马来亚 |
| 在哪届奥运会上,阿萨伊·通迪凯没有进入前 20 名? | 2012 |
| 哪个广播公司主持了 3 个节目,但每个节目只有 1 集? | 第 4 频道 |
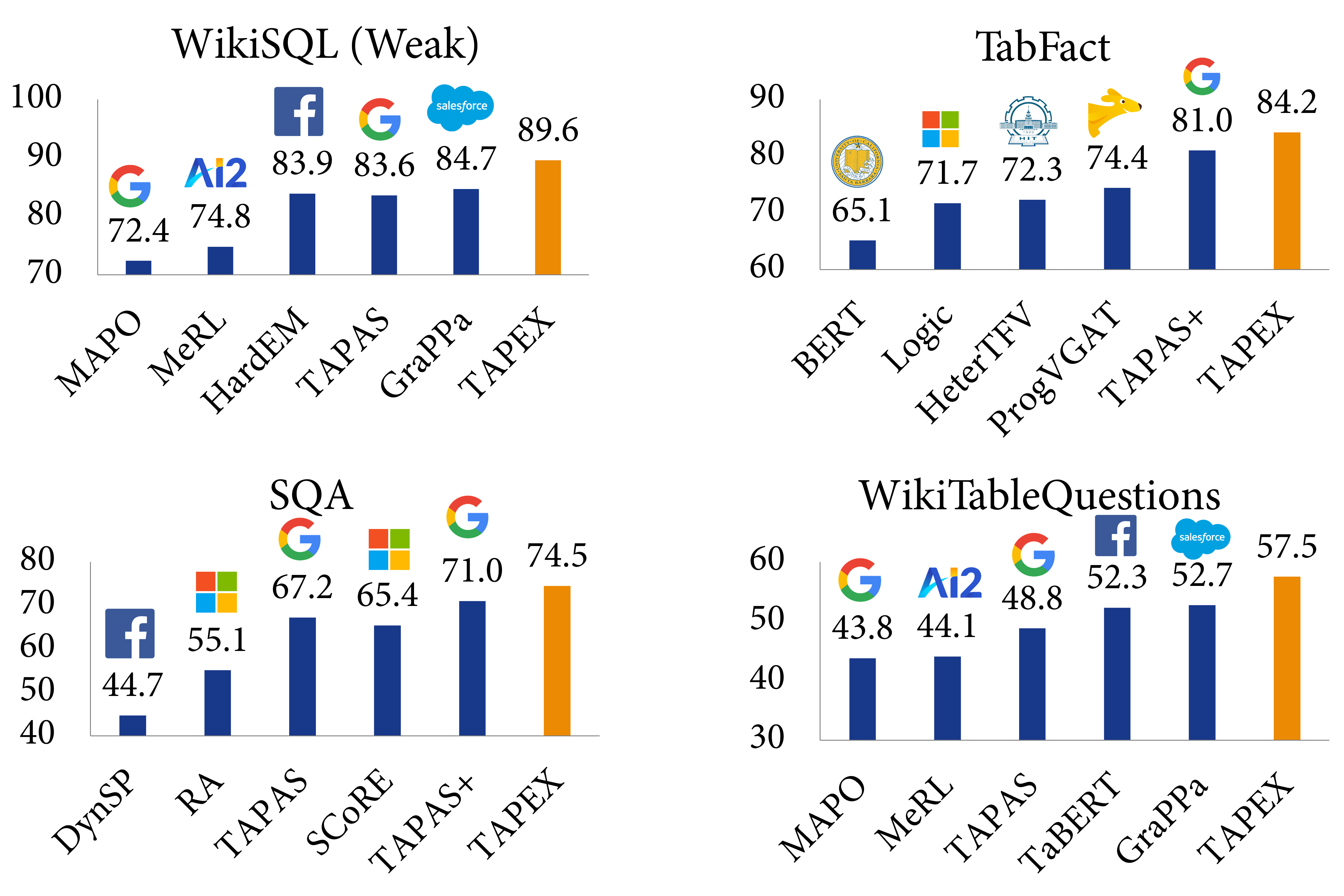
实验结果表明,TAPEX 的性能大幅优于以往的表格预训练方法,并且 ⭐在所有这些数据集上都取得了新的最先进(SOTA)结果⭐。这包括:弱监督的 WikiSQL 指称准确率提升至 89.6%(比 SOTA 高 2.3%,比 BART 高 3.8%),TabFact 准确率提升至 84.2%(比 SOTA 高 3.2%,比 BART 高 3.0%),SQA 指称准确率提升至 74.5%(比 SOTA 高 3.5%,比 BART 高 15.9%),以及 WikiTableQuestion 指称准确率提升至 57.5%(比 SOTA 高 4.8%,比 BART 高 19.5%)。据我们所知,这是首个利用合成可执行程序进行预训练并在各种下游任务上取得新的最先进成果的工作。
与以往表格预训练的比较
最早的表格预训练工作,如来自 Google Research 的 TAPAS(同样在 🤗 Transformers 中可用)和来自 Meta AI 的 TaBERT,已经揭示了收集更多 领域自适应 的数据可以提升下游性能。然而,这些先前的工作主要采用 通用 的预训练任务,例如语言建模或其变体。TAPEX 探索了一条不同的道路,它牺牲了预训练源的自然性,以获得一个 领域自适应 的预训练任务,即 SQL 执行。下面是 BERT、TAPAS/TaBERT 和我们的 TAPEX 的图形化比较。

我们认为 SQL 执行任务更接近于下游的表格问答任务,特别是从结构化推理能力的角度来看。想象一下你面对一个 SQL 查询 SELECT City ORDER BY Year 和一个自然语言问题 按年份对所有城市进行排序。SQL 查询和问题所需的推理路径是相似的,只是 SQL 比自然语言更刻板一些。如果一个语言模型能够被预训练来忠实地“执行” SQL 查询并产生正确的结果,那么它应该对具有相似意图的自然语言有深刻的理解。
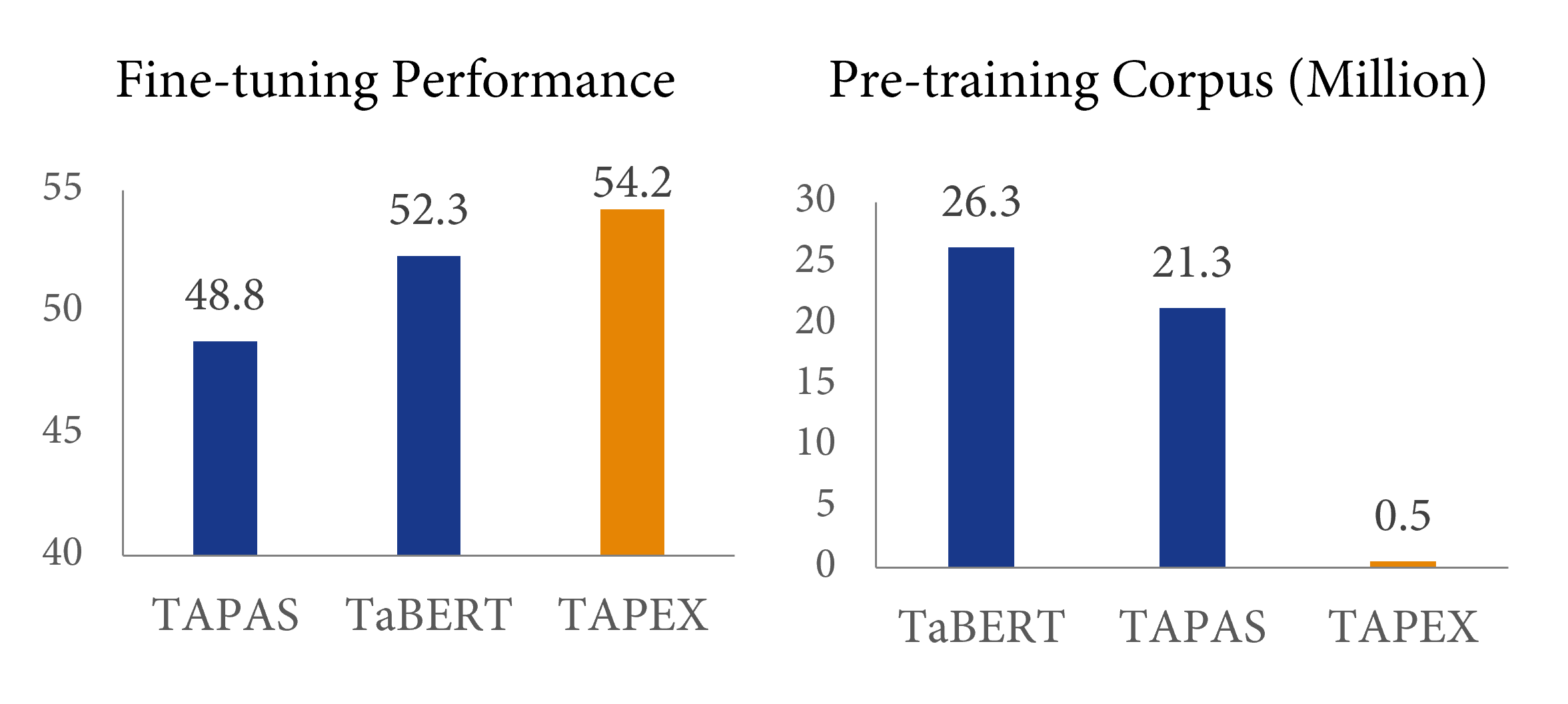
效率如何?与之前的预训练方法相比,这种预训练方法的效率有多高?答案在上图中给出:与之前的表格预训练方法 TaBERT 相比,TAPEX 仅使用 2% 的预训练语料库就能产生 2% 的性能提升,实现了近 50 倍的加速!使用更大的预训练语料库(例如,500 万个
结论
在这篇博客中,我们介绍了 TAPEX,一种表格预训练方法,其语料库通过采样 SQL 查询及其执行结果自动合成。TAPEX 通过在一个多样化、大规模且高质量的合成语料库上学习一个神经 SQL 执行器,解决了表格预训练中的数据稀缺挑战。在四个下游数据集上的实验结果表明,TAPEX 的性能大幅优于以往的表格预训练方法,并且预训练效率更高。
要点
我们能从 TAPEX 的成功中学到什么?我建议,特别是如果你想进行高效的持续预训练,你可以尝试以下选项:
- 合成一个精确且小型的语料库,而不是从互联网上挖掘一个庞大但嘈杂的语料库。
- 通过程序模拟领域自适应的技能,而不是通过自然语言句子进行通用的语言建模。

