宣布 BigCodeBench-Hard 及更多






我们很高兴发布 BigCodeBench-Hard!BigCodeBench-Hard 编译了 BigCodeBench 数据集中的148个任务的子集。您现在可以安装最新的
bigcodebench==v0.1.8,并尝试使用以下命令评估您在 BigCodeBench-Hard 上的模型 👇
# update bigcodebench
pip install -U bigcodebench
# bigcodebench.generate with greedy
bigcodebench.generate \
--model [model_name] \
--split [complete|instruct] \
--subset [full|hard] \
--greedy
# bigcodebench.sanitize
bigcodebench.sanitize --samples samples.jsonl --calibrate
# bigcodebench.evaluate
# note that you need to have a separate environment for evaluation
bigcodebench.evaluate --split [complete|instruct] --subset [full|hard] --samples samples-sanitized-calibrated.jsonl
推出 BigCodeBench-Hard
构建 BigCodeBench-Hard 的工作流程主要受到 MixEval 的启发,MixEval 利用少量基准样本来校准面向用户的评估。MixEval 侧重于通用领域评估,并且只考虑来自 MBPP 和 HumanEval 的最少样本的代码生成任务,我们扩展了这一思想,使代码生成评估更加以用户为中心。具体来说,我们遵循以下步骤创建 BigCodeBench-Hard:

首先,我们选择了一个由 BigCode 社区预处理的 匿名 Stack Overflow 存档。预处理的详细信息可以在 StarCoder2 报告 中找到。该存档包含 1040 万个问题和答案,涵盖了不同的编程语言和主题,使其成为用户查询的良好来源。
为了连接查询源和 BigCodeBench,我们利用了 all-mpnet-base-v2,这是一个由 Sentence Transformers 文档推荐的预训练句子嵌入模型。该模型在文本和代码数据的混合上进行训练,适用于识别编程查询和 BigCodeBench 任务之间的相似性。
我们使用该模型检索 Stack Overflow 存档中每个查询的最相似任务,通过归一化嵌入之间的点积进行排名。根据对检索到的任务的手动检查,我们得出结论,相似性得分高于 0.7 是任务选择的良好阈值。通过应用此阈值,我们在去重后获得了 6,895 个查询和 626 个 BigCodeBench 任务。
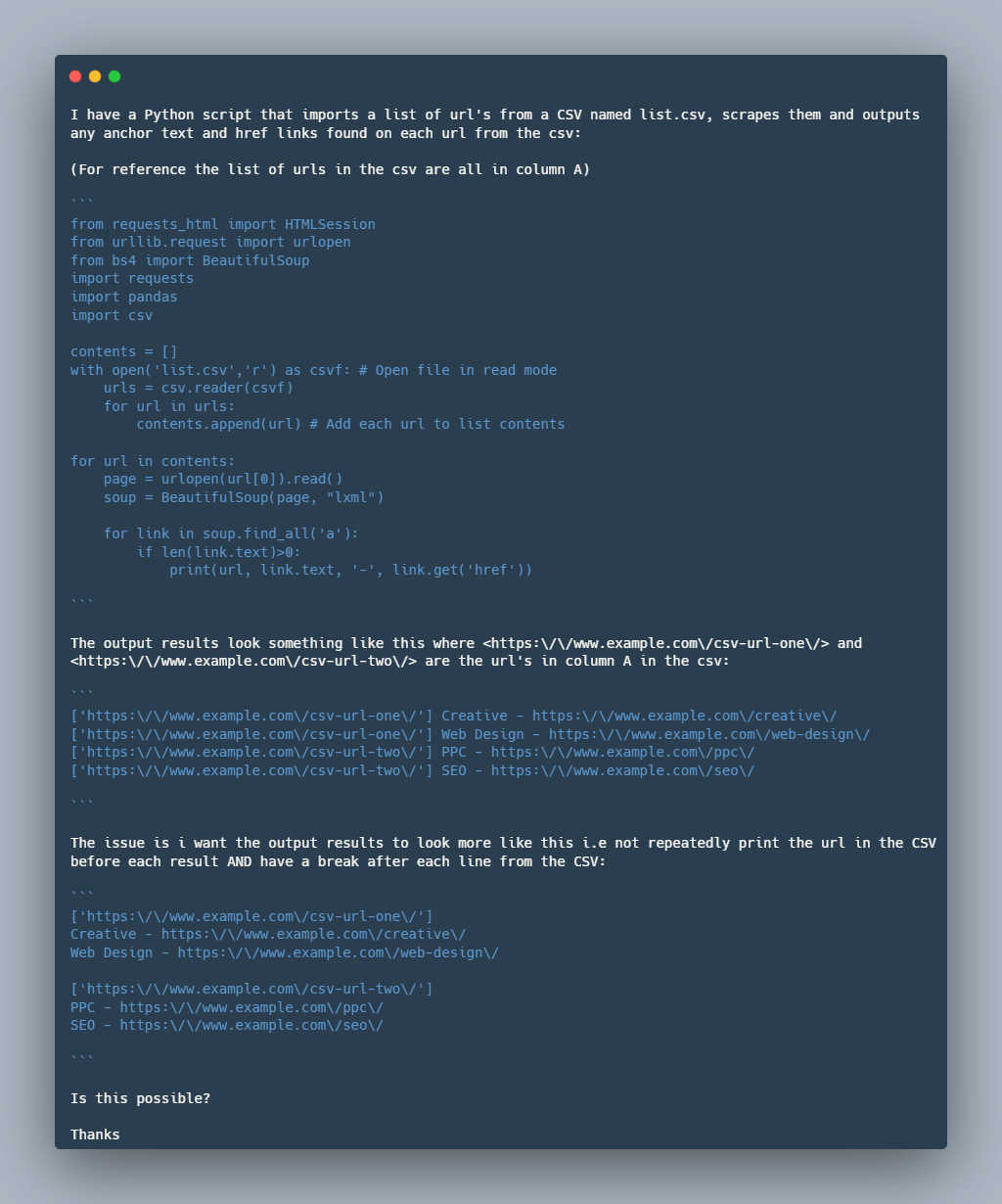
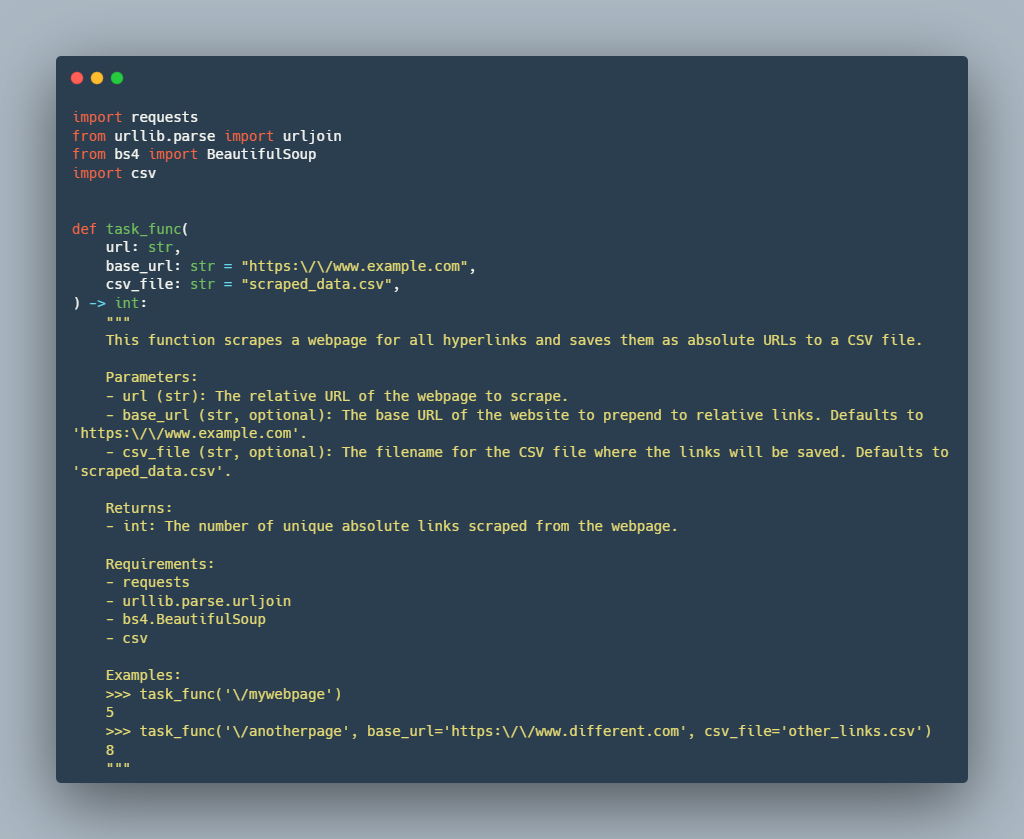
我们通过以下示例说明 Stack Overflow 查询和 BigCodeBench 任务之间的对齐。如给定示例所示,查询和任务提示都围绕着网络抓取,以从网页中提取超链接,使用 Python 库处理 HTTP 请求和解析 HTML。两者都涉及与 CSV 文件交互,以读取输入 URL 或写入输出数据。虽然具体的实现细节不同,但从网页中提取和处理超链接数据的核心目标是共享的方面,使它们的整体范围密切对齐。
Stack Overflow 查询
检索到的 BigCodeBench 任务提示
然而,检索到的 626 个任务对于评估来说仍然不可行。为了提高评估效率,我们通过难度进一步筛选任务。与 MixEval-Hard 的构建不同,我们定义了以下更具可解释性的标准:
库使用:BigCodeBench 中的每个任务都强调编码的组合推理能力,并且需要使用至少两个库。对于 BigCodeBench-Hard,我们只保留需要两个以上库的任务,挑战模型选择更多样化的函数调用作为解决任务的工具。
解决方案长度:我们将阈值设置为 426 个 token,这是 BigCodeBench 中任务的平均解决方案长度。地面真实解决方案为任务复杂性提供了参考,解决方案较长的任务更难解决。
解决率:我们根据排行榜上所有已评估的模型计算每个任务的解决率。解决率定义为可以解决任务的模型数量除以模型总数。具体来说,我们将解决率低于 50% 的任务视为困难任务。

通过比较,我们注意到 BigCodeBench-Hard 上的模型性能与 BigCodeBench 完整集上的性能存在显著差异。我们认为这些差异源于目标领域分布不平衡和 BigCodeBench 中存在大量简单任务,导致评估与面向用户的任务之间存在轻微偏差。例如,GPT-4o-2024-05-13 和 GPT-4-0613 可能过度拟合了 BigCodeBench 中的简单任务,导致在 BigCodeBench-Hard 上表现不佳。
为了验证 BigCodeBench-Hard 的有效性,我们使用 Scale AI 策划的私有排行榜 SEAL-Coding 作为参考。SEAL-Coding 排行榜旨在评估模型在各种应用领域和编程语言中的面向用户任务。具体来说,SEAL-Coding 比较了 四个最佳闭源 LLM 在 Python 方面的表现,排名如下:(1) GPT-4-Turbo Preview,(2) Claude 3.5 Sonnet,(3) GPT-4o,和 (4) Gemini 1.5 Pro (2024年5月)。这些排名与我们基于 BigCodeBench-Hard 的 Complete 和 Instruct 分割的平均得分所获得的结果一致,表明 BigCodeBench-Hard 更以用户为中心,并且对模型评估更具挑战性。
我们鼓励社区在预算有限且评估需要更以用户为中心时使用 BigCodeBench-Hard。此外,我们注意到 BigCodeBench-Hard 可以通过设计实现动态,具体取决于用户查询和评估模型。我们可以定期更新 BigCodeBench-Hard,以保持评估的挑战性和以用户为中心。
排行榜上有96个模型!
我们更新了 BigCodeBench 排行榜,总共有 96 个模型。为了更深入地研究排行榜,我们使用 BigCodeBench-Hard 探讨以下问题:
你注意到最近 DeepSeek-V2-Chat 升级了吗?

DeepSeek-V2-Chat 于2024年6月28日进行的最近升级显著提升了其性能。结果显示,完整任务(Complete)性能惊人地增长了109%,得分从15.5上升到32.4。虽然 BigCodeBench-Instruct 也表现出提升,但其提升更为温和,从21.6增长到25.0,增长了15.7%。这些升级表明 DeepSeek 致力于增强其聊天模型。
Gemma-2-27B-Instruct 在编码方面比 Llama-3-70B-Instruct 更好吗?

在完整任务(Complete)和指令任务(Instruct)两个部分,Llama-3-70B-Instruct 仍然略微优于 Gemma-2-27B-Instruct。这种差异在完整任务中(3.7% 的差异)比指令任务中(1.8% 的差异)更显著。值得注意的是,尽管参数更少(27B vs 70B),Gemma-2-Instruct 的性能接近 Llama-3-70B-Instruct。考虑到模型尺寸的显著差异,这令人印象深刻。
Phi-3-Mini 的秘密更新有多好?

我们使用 Phi-3-Mini-128k-Instruct 进行比较。图中显示的显著改进表明秘密更新非常有效。指令分割(Instruct split)的相对收益更大(24.3% 对完整分割(Complete split)的 13.8%),这表明更新可能侧重于优化模型理解和执行不那么冗长的指令的能力。
还有一件事 🤗
我们很高兴地宣布与 EvalPlus 团队合作,创建一个新的 BigCodeBench 变体:BigCodeBench+,这是一个增强测试严格性的基准!
此外,我们还将与 CRUXEval 团队合作,创建另一个变体 CRUX-BigCodeBench,一个专注于更实际的代码推理和理解的基准。
请继续关注 BigCodeBench 的更多更新!
资源
我们开源了 BigCodeBench-Hard 的所有制品,包括数据、代码和排行榜。您可以在以下位置找到它们:
- GitHub 仓库
- BigCodeBench-Hard 数据集
- BigCodeBench 排行榜
- Stack Overflow 嵌入
- BigCodeBench 嵌入
- 检索到的 BigCodeBench 任务
引用
如果我们的评估对您有用,请考虑引用我们的工作:
@article{zhuo2024bigcodebench,
title={BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions},
author={Zhuo, Terry Yue and Vu, Minh Chien and Chim, Jenny and Hu, Han and Yu, Wenhao and Widyasari, Ratnadira and Yusuf, Imam Nur Bani and Zhan, Haolan and He, Junda and Paul, Indraneil and others},
journal={arXiv preprint arXiv:2406.15877},
year={2024}
}





