NeurIPS 2025 E2LM 竞赛:语言模型早期训练评估













加入我们,共同构建能够捕捉 LLM 早期推理和科学知识的基准!
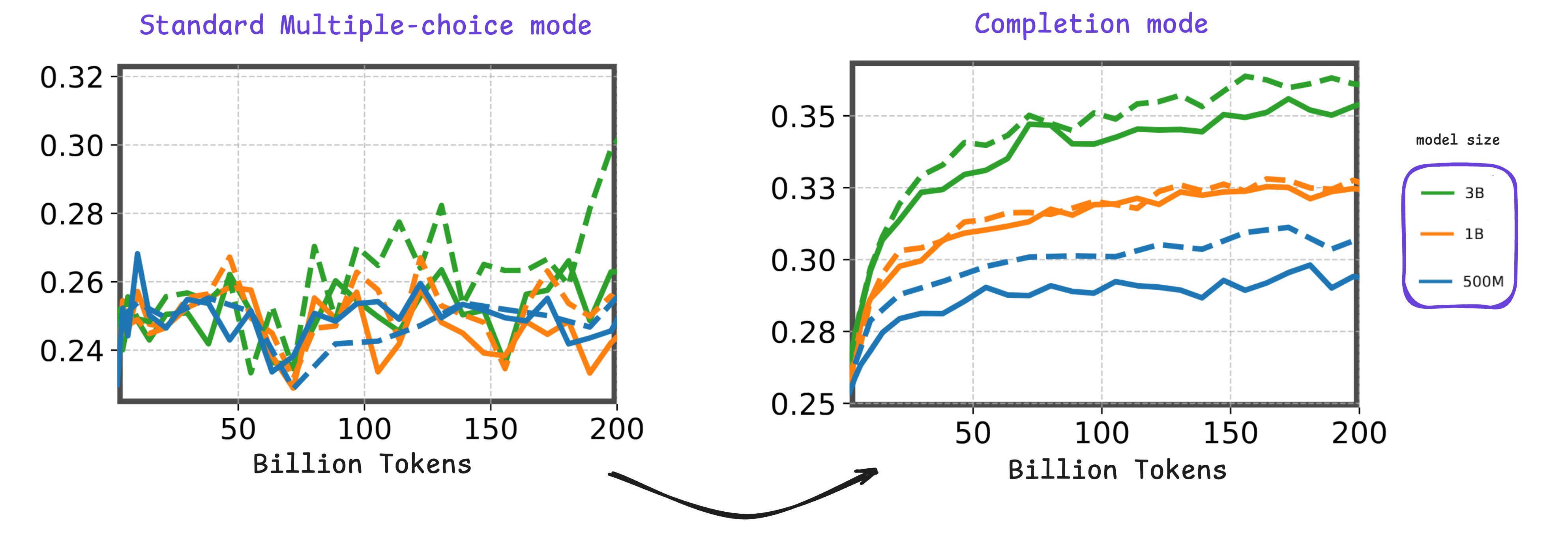
大型语言模型 (LLM) 的开发通常始于一系列消融实验,其中系统地评估各种模型架构、数据混合和训练超参数。这个阶段通常被称为训练的早期阶段。在此期间,研究人员主要监测两个关键指标:训练损失曲线和评估分数。然而,现有的评估基准在 LLM 训练的初始阶段(约 200B 令牌)往往无法提供有意义或有区分度的信号,这使得从正在进行的实验中得出确切结论变得具有挑战性。
在本次竞赛中,我们希望共同构建新的基准,以有效捕捉 LLM 早期训练阶段的相关信号,特别是针对科学知识领域。
如何参与
本次竞赛将在专门的 Hugging Face 组织中举行——如需注册竞赛,请点击此注册链接 👉 https://e2lmc.github.io/registration。参赛者必须通过 HuggingFace Space 提交其解决方案,该解决方案将基于 lm-evaluation-harness 库。竞赛期间将维护一个活跃的排行榜,以跟踪有希望的提交。模型大小使其易于所有人运行,甚至可以在免费的 Google Colab GPU 上运行。我们还提供一个全面的入门工具包,包括多个笔记本,助您开始竞赛。
评估指标
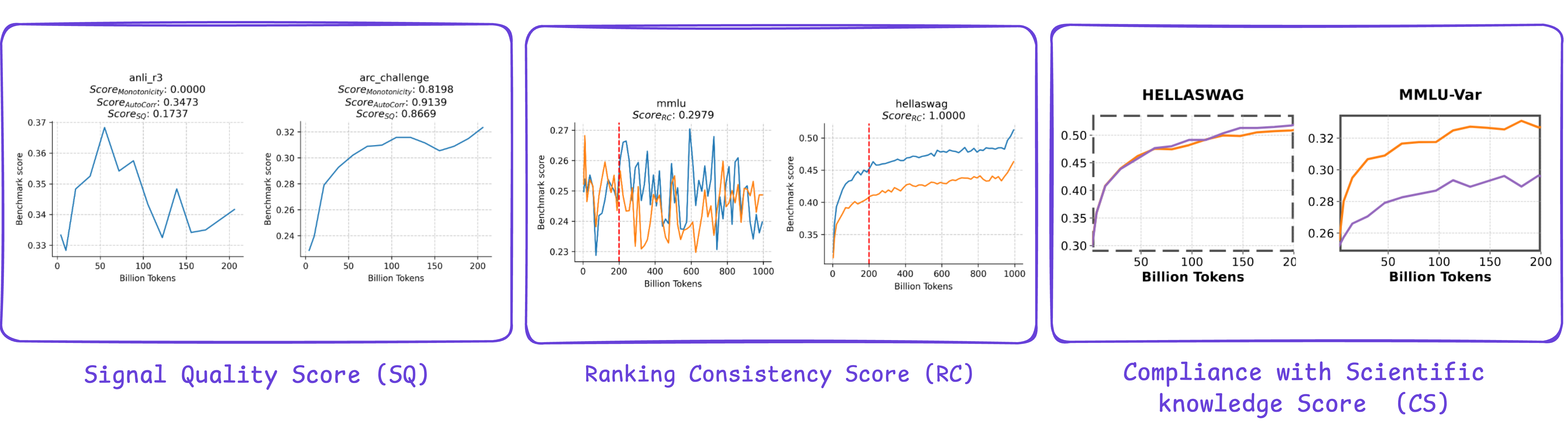
每次提交将使用三个不同的分数进行评估:信号质量分数 (ScoreSQ)、排名一致性分数 (ScoreRC) 和符合科学知识分数 (ScoreCS)。这些标准将组合成一个用于最终排名的总分。此外,将系统地对所有提交应用两个验证程序:(i) 验证与既定科学知识领域的一致性,以及 (ii) 检测潜在的信息泄露,特别是问题提示中是否存在答案。总分通过加权和计算:
其中,αSQ、αRC 和 αCS 是加权系数,反映了每个标准的相对重要性。我们将权重设置为 α1 = 0.5、α2 = 0.1 和 α3 = 0.4,从而更加强调信号质量和对科学知识的符合度,我们认为这是评估提交最重要的指标。
参赛者将能够使用提供的三款小型语言模型(0.5B、1B 和 3B,范围从 0 到 200 BT)的模型检查点以及附带的评分算法(在入门工具包中的笔记本中提供)在本地计算信号质量子分数。相比之下,其他两个子分数无法独立计算,因为相应的检查点——从 200 GT 到 1 T 令牌,以及专门在网络数据上训练的 0.5 亿参数模型——将在整个竞赛期间保持隐藏状态。尽管如此,总分将在通过 Hugging Face 竞赛空间提交后自动计算,允许参赛者跟踪其整体表现。此设置旨在防止过度定制的解决方案专门针对发布的检查点。
有关每个评估指标的更多详细信息,以及在最先进基准上的完整评分结果,请参阅竞赛提案
竞赛时间表
| 竞赛启动 | 2025 年 7 月 14 日 |
| 热身阶段 | 2025 年 7 月 14 日 - 2025 年 8 月 17 日(5 周) |
| 开发阶段 | 2025 年 8 月 18 日 - 2025 年 10 月 26 日(10 周) |
| 最终阶段 | 2025 年 10 月 27 日 - 2025 年 11 月 3 日(3 周) |
| 结果公布 | 2025 年 11 月 4 日 |
| 获奖者情况说明和代码发布截止日期 | 2025 年 11 月 22 日 |
| NeurIPS 竞赛研讨会演示 | 2025 年 12 月 6 日或 7 日 |
奖品
- 🥇 第一名:6,000 美元
- 🥈 第二名:4,000 美元
- 🥉 第三名:2,000 美元
- 🎓 学生奖:2x 2,000 美元,奖励由证明学生身份的参与者提交的前 2 个解决方案
支持和联系方式
如有疑问和支持需求,请联系任务协调员:e2lmc@tii.ae。您也可以在此处加入我们的 Discord 频道,直接与我们互动。
附属机构
|
|
|
|
|
|


