并发请求的预填充与解码——优化LLM性能








并行处理来自多个用户的负载对于LLM应用的性能至关重要。在我们LLM性能系列的上一部分中,我们讨论了针对不同用户请求的排队策略。在本系列的第二部分中,我们将重点关注请求的并发处理,以及它如何影响相关指标,如延迟、吞吐量以及GPU资源利用率。

在TNG,我们使用由24个H100 GPU组成的集群自托管了许多大型语言模型。它支持50种不同的应用程序,每小时处理超过5,000次推理,每天生成超过一千万个令牌。
令牌生成的两个阶段:预填充和解码
大多数LLM逐个令牌生成文本,这保证了每个新令牌都基于所有先行令牌计算(这种模型属性称为*自回归*)。第一个输出令牌依赖于所有提示令牌,但第二个输出令牌已经依赖于所有提示令牌*加上*第一个输出令牌,依此类推。因此,令牌生成不能在单个请求级别上并行化。
在带有注意力机制的LLM中,计算新令牌需要为每个先行令牌计算*键*(key)、*值*(value)和*查询*(query)向量。幸运的是,一些特定计算的结果可以重复用于后续令牌。这个概念被称为键值(KV)缓存。对于每个额外的输出令牌,只需要计算一组*键*和*值*向量并将其添加到KV缓存中。然而,对于第一个输出令牌,我们从一个最初为空的KV缓存开始,需要计算与输入提示中令牌数量一样多的*键*和*值*向量。幸运的是,与后来的任何令牌生成不同,所有输入令牌从一开始就已知,我们可以并行化计算它们各自的*键*和*值*向量。这种差异促成了**预填充(计算第一个输出令牌)**和**解码阶段(计算任何后续输出令牌)**的区别。
在预填充阶段,所有输入令牌的计算可以并行执行,而在解码阶段,在单个请求级别上不可能进行并行化。

指标
预填充和解码阶段的差异也体现在文本生成的两个关键指标上:*首令牌时间*和*每输出令牌时间*。*首令牌时间*由预填充阶段的延迟决定,而*每输出令牌时间*是单个解码步骤的延迟。尽管预填充阶段也只生成一个令牌,但它比单个解码步骤耗时更长,因为需要处理所有输入令牌。另一方面,在输入令牌数量相同的情况下,预填充阶段的速度比解码阶段快得多(这种差异是商业LLM API对输入令牌收费远低于输出令牌的原因)。

这两种延迟都是交互式应用(如聊天机器人)的重要指标。如果用户需要等待超过5秒才能看到响应,他们可能会认为应用程序出问题并离开。同样,如果文本生成速度慢到每秒1个令牌,他们将没有足够的耐心等待其完成。交互式应用的典型延迟目标是每输出令牌100-300毫秒(即每秒3-10个令牌的生成速度,至少与阅读速度一样快,理想情况下允许在文本生成时快速浏览),以及*首令牌时间*3秒或更短。根据模型大小、硬件、提示长度和并发负载,实现这两个延迟目标可能相当具有挑战性。
其他非交互式用例可能不关心单个请求的延迟,而只关心总*令牌吞吐量*(每秒令牌数,所有并发请求的总和)。这在您想要为书籍生成翻译,或总结大型代码库中的代码文件时可能相关。
正如我们将在后面一节中看到的,在最大化总吞吐量和最小化每个单个请求的延迟之间通常存在权衡。
资源利用
由于所有输入令牌都进行并行计算,预填充阶段对GPU计算资源的需求非常高。相反,单个输出令牌的解码步骤使用的计算能力非常少;此时,速度通常受限于GPU内存带宽,即模型权重和激活(包括*键*和*值*向量)从GPU内存加载和访问的速度。
通常,令牌吞吐量可以增加,直到GPU利用率(相对于计算能力)饱和。在预填充阶段,一个带有长提示的单个请求就可以达到最大GPU利用率。在解码阶段,**通过批处理**多个请求可以提高**GPU利用率**。因此,当您绘制令牌吞吐量与并发请求数量的函数图时,在低并发度下会看到吞吐量几乎呈线性增长,因为这种内存密集型模式受益于更大的批次大小。一旦GPU利用率饱和并进入计算密集型模式,吞吐量将随着并发度的增加而保持不变。

并发处理
现在我们将探讨推理引擎如何精确处理在短时间内到达的多个请求。
预填充和解码阶段都可以利用批处理策略来对不同的请求应用相同的操作集。但是,同时运行不同请求的预填充和解码会有什么后果呢?
静态批处理与连续批处理
最简单的批处理形式称为**静态批处理**。(1) 您从一个空批次开始,(2) 您将批次填满尽可能多的等待项并使其符合批次大小,(3) 您处理批次直到所有批处理项完成,(4) 您使用新的空批次重复该过程。
所有请求同时开始其预填充阶段。由于预填充只是一个单一的、但高度并行的GPU操作(可以将其视为一个非常大的矩阵乘法),因此所有并发请求的预填充阶段同时完成。然后,所有解码阶段同时开始。输出令牌较少的请求会提前完成,但由于静态批处理,下一个等待请求只能在最长的批处理请求完成后才能开始。

**静态批处理优化了*每输出令牌时间***,因为解码阶段是不间断的。缺点是资源利用效率非常低。由于单个长提示在预填充期间就可以使计算能力饱和,因此并行处理多个预填充不会提高速度,并且肯定会使GPU利用率达到最大。相反,在解码阶段,GPU可能会被低效利用,因为即使大量的并发解码也不如长提示的预填充那样计算密集。
然而,最大的缺点是潜在的漫长*首令牌时间*。即使一些短请求提前完成,下一个排队请求也必须等待批处理中最长的解码完成,其预填充才能开始。由于静态批处理的这个缺陷,推理引擎通常实现**连续批处理**策略。在这种策略中,任何已完成的请求都会立即从批处理中移除,并且批处理空间会填充队列中的下一个请求。因此,每种连续批处理策略都必须处理预填充和解码阶段之间的并发问题。
预填充优先
为了减少请求的等待时间,推理引擎如vLLM和TGI会在新请求到达并符合当前批次时立即调度其预填充阶段。虽然可以并行运行新请求的预填充与每个先前请求的单个解码步骤,但由于所有操作都在同一个GPU操作中执行,其持续时间主要由预填充决定,并且对于处于解码阶段的每个请求,在此期间只能生成一个输出令牌。因此,这种**预填充优先策略可以最小化*首令牌时间***,但会中断已运行请求的解码阶段。在聊天应用程序中,当其他用户提交长提示时,用户可能会体验到流式令牌生成暂停的情况。
在下面的测量中,您可以看到采用预填充优先策略的连续批处理的效果。

分块预填充
一种减轻中断性预填充对正在运行的解码影响的方法是*分块预填充*。它不是在单个预填充步骤中处理整个提示,而是将其分散到多个块中。这样,在预填充期间可以有与预填充块数一样多的并发解码步骤(而不是在整个预填充期间每个并发请求只有一个解码步骤)。分块预填充步骤仍然会比独立的解码步骤花费更长的时间,但对于小块大小,用户现在只体验到令牌生成速度的减慢,而不是完全暂停;这减少了平均*每输出令牌时间*。从中断请求的角度来看,分块预填充会带来一些开销,并且比独立的连续预填充花费更长的时间,因此*首令牌时间*会略微增加。通过块大小,我们现在有了一个**用于优先考虑*首令牌时间*或*每输出令牌时间*的调整旋钮**。典型的块大小在512到8192个令牌之间(vLLM默认在首次实现分块预填充时为512,后来更新为更高值)。
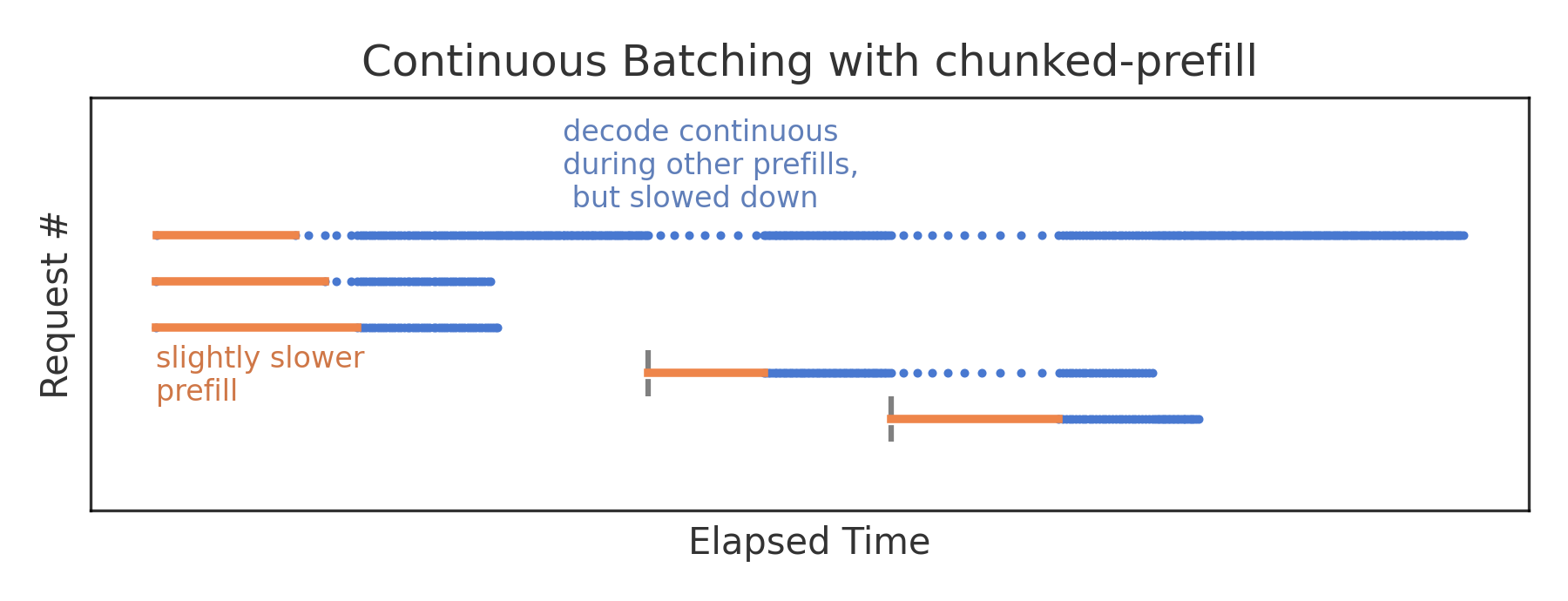
然而,这种策略最大的优势在于**分块预填充能最大化资源效率**。预填充是计算密集型的,而解码是内存受限的。通过并行运行这两种操作,可以在不受GPU资源限制的情况下提高整体吞吐量。当然,最大效率只有在特定块大小下才能实现,而块大小又取决于具体的负载模式。
在标准的vLLM部署中,对于大小均匀的请求,我们观察到**分块预填充使总令牌吞吐量提高了+50%**。它现在已在TNG的所有自托管LLM的vLLM部署中启用。总的来说,分块预填充是大多数用例的良好默认策略。然而,在负载模式不可预测的环境中(例如TNG的许多不同应用程序),优化块大小相当困难;通常,您会坚持使用默认设置。
无论具体的块大小配置如何,分块预填充的并发处理都带来了两个挑战,我们将在下一篇文章中讨论。






