通过 TRL 使用 DDPO 微调 Stable Diffusion 模型










引言
扩散模型 (例如 DALL-E 2, Stable Diffusion) 是一类生成模型,在生成图像方面取得了巨大成功,尤其是在照片级真实感图像方面。然而,这些模型生成的图像可能并不总是符合人类的偏好或意图。因此出现了对齐问题,即如何确保模型的输出与人类偏好(如“质量”)或难以通过提示表达的意图保持一致?这就是强化学习发挥作用的地方。
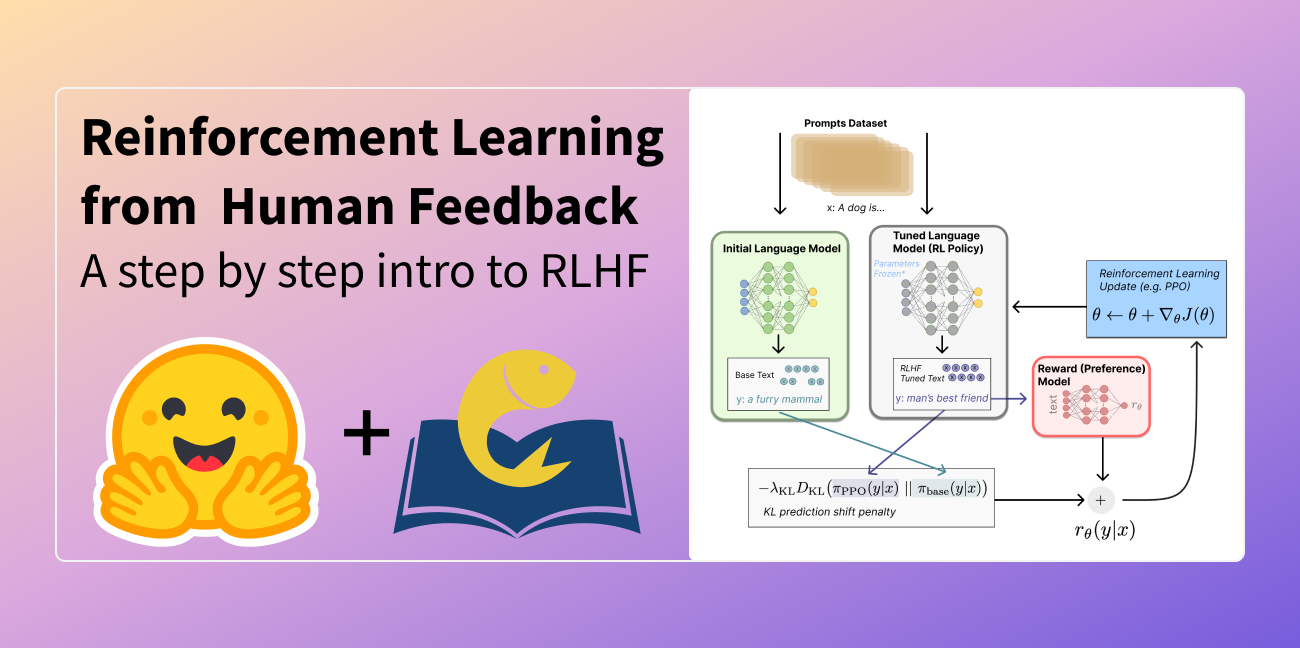
在大型语言模型 (LLMs) 的世界里,强化学习 (RL) 已被证明是一种非常有效的工具,用于将所述模型与人类偏好对齐。它是像 ChatGPT 这样系统表现优异的主要秘诀之一。更准确地说,RL 是从人类反馈中进行强化学习 (RLHF) 的关键组成部分,它让 ChatGPT 能够像人类一样聊天。
在 《使用强化学习训练扩散模型》 一文中,Black 等人展示了如何通过一种名为去噪扩散策略优化 (Denoising Diffusion Policy Optimization, DDPO) 的方法来增强扩散模型,利用 RL 根据目标函数对其进行微调。
在这篇博文中,我们讨论了 DDPO 的由来、其工作原理的简要描述,以及如何将 DDPO 融入 RLHF 工作流程,以实现更符合人类审美的模型输出。然后,我们迅速转向讨论如何使用 `trl` 库中新集成的 `DDPOTrainer` 将 DDPO 应用到你的模型上,并分享我们在 Stable Diffusion 上运行 DDPO 的发现。
DDPO 的优势
对于如何尝试用 RL 微调扩散模型这个问题,DDPO 并非唯一可行的答案。
在深入探讨之前,理解不同 RL 方案优劣时有两个关键点需要记住:
- 计算效率是关键。数据分布越复杂,计算成本就越高。
- 近似是好的,但由于近似并非真实情况,相关误差会累积。
在 DDPO 之前,奖励加权回归 (RWR) 是一种已确立的、使用强化学习微调扩散模型的方法。RWR 复用扩散模型的去噪损失函数,并使用从模型本身采样的训练数据,以及每个样本的损失权重,该权重取决于最终样本的关联奖励。该算法忽略了中间的去噪步骤/样本。虽然这能行得通,但有两点需要注意:
- 通过加权关联损失(这是一个最大似然目标)进行优化是一种近似优化。
- 关联损失并非精确的最大似然目标,而是从一个重新加权的变分界推导出的近似值。
这两层近似对性能和处理复杂目标的能力都有显著影响。
DDPO 以此方法为起点。DDPO 不像 RWR 那样只关注最终样本,将去噪步骤视为单一步骤,而是将整个去噪过程构建为一个多步马尔可夫决策过程 (MDP),其中奖励在最后才收到。这种形式化,加上使用固定的采样器,为智能体策略铺平了道路,使其成为一个各向同性的高斯分布,而不是任意复杂的分布。因此,DDPO 不使用最终样本的近似似然(这是 RWR 的路径),而是使用每个去噪步骤的精确似然,这非常容易计算 ().
如果你有兴趣了解更多关于 DDPO 的细节,我们鼓励你查看原始论文和相关的博客文章。
DDPO 算法简介
鉴于用于模拟去噪过程顺序性的 MDP 框架以及随之而来的其他考虑,解决优化问题的首选工具是策略梯度方法。具体来说,是近端策略优化 (PPO)。整个 DDPO 算法与近端策略优化 (PPO) 基本相同,但其中一个高度定制化的部分是 PPO 的轨迹收集部分。
这里有一个图表来总结流程

DDPO 和 RLHF:融合以增强美学
RLHF 的一般训练流程大致可以分为以下几个步骤:
- 对一个“基础”模型进行有监督的微调,使其学习新数据的分布。
- 收集偏好数据并用其训练一个奖励模型。
- 使用奖励模型作为信号,通过强化学习对模型进行微调。
需要注意的是,在 RLHF 的背景下,偏好数据是捕获人类反馈的主要来源。
当我们将 DDPO 加入进来时,工作流程会变成如下形式:
- 从一个预训练的扩散模型开始。
- 收集偏好数据并用其训练一个奖励模型。
- 使用奖励模型作为信号,通过 DDPO 对模型进行微调。
请注意,一般 RLHF 工作流程中的第 3 步在后者的步骤列表中缺失了,这是因为经验证明(正如你将亲眼看到的那样)这一步并非必要。
为了让扩散模型输出更符合人类审美观念的图像,我们遵循以下步骤:
- 从一个预训练的 Stable Diffusion (SD) 模型开始。
- 在美学视觉分析 (AVA) 数据集上训练一个冻结的 CLIP 模型,该模型带有一个可训练的回归头,用于预测人们对输入图像的平均喜好程度。
- 使用美学预测模型作为奖励信号,通过 DDPO 对 SD 模型进行微调。
我们在接下来的章节中将牢记这些步骤,实际运行它们,具体描述如下。
使用 DDPO 训练 Stable Diffusion
设置
首先,在硬件方面,对于这个 DDPO 实现,至少需要一个 A100 NVIDIA GPU 才能成功训练。任何低于此 GPU 类型的设备很快就会遇到内存不足的问题。
使用 pip 安装 `trl` 库
pip install trl[diffusers]
这应该会安装主库。以下依赖项用于跟踪和图像日志记录。安装 `wandb` 后,请务必登录以将结果保存到个人账户。
pip install wandb torchvision
注意:你也可以选择使用 `tensorboard` 而不是 `wandb`,为此你需要通过 `pip` 安装 `tensorboard` 包。
详细步骤
`trl` 库中负责 DDPO 训练的主要类是 `DDPOTrainer` 和 `DDPOConfig`。有关 `DDPOTrainer` 和 `DDPOConfig` 的更多通用信息,请参阅文档。在 `trl` 仓库中有一个示例训练脚本。它将这两个类与所需输入的默认实现和默认参数结合使用,以微调来自 `RunwayML` 的默认预训练 Stable Diffusion 模型。
此示例脚本使用 `wandb` 进行日志记录,并使用一个美学奖励模型,其权重从一个公开的 HuggingFace 仓库中读取(因此,收集数据和训练美学奖励模型的工作已经为你完成)。默认使用的提示数据集是一个动物名称列表。
用户只需提供一个命令行标志参数即可开始运行。此外,用户需要有一个 Hugging Face 用户访问令牌,该令牌将在微调后用于将模型上传到 Hugging Face Hub。
以下 bash 命令可以启动运行
python ddpo.py --hf_user_access_token <token>
下表包含了与积极结果直接相关的关键超参数。
| 参数 | 描述 | 单 GPU 训练的推荐值(截至目前) |
|---|---|---|
num_epochs |
训练的轮数 | 200 |
train_batch_size |
用于训练的批次大小 | 3 |
sample_batch_size |
用于采样的批次大小 | 6 |
gradient_accumulation_steps |
要使用的基于加速器的梯度累积步数 | 1 |
sample_num_steps |
采样的步数 | 50 |
sample_num_batches_per_epoch |
每轮采样的批次数 | 4 |
per_prompt_stat_tracking |
是否按提示跟踪统计数据。如果为 false,将使用整个批次的均值和标准差计算优势,而不是按提示跟踪 | True |
per_prompt_stat_tracking_buffer_size |
用于按提示跟踪统计数据的缓冲区大小 | 32 |
mixed_precision |
混合精度训练 | True |
train_learning_rate |
学习率 | 3e-4 |
提供的脚本仅仅是一个起点。请随意调整超参数,甚至彻底修改脚本以适应不同的目标函数。例如,可以集成一个衡量 JPEG 可压缩性的函数,或一个使用多模态模型评估视觉-文本对齐的函数,以及其他可能性。
经验教训
- 尽管训练提示词数量极少,但结果似乎在各种提示词上都能很好地泛化。对于奖励美学的目标函数,这一点已得到充分验证。
- 尝试通过增加训练提示词数量和改变提示词来明确泛化,至少对于美学目标函数而言,似乎会减慢收敛速度,而学到的泛化行为几乎察觉不到(如果存在的话)。
- 虽然 LoRA 是推荐的,并且经过多次测试,但非 LoRA 方案也值得考虑,原因之一是根据经验证据,非 LoRA 似乎能生成比 LoRA 更复杂的图像。然而,为稳定的非 LoRA 运行找到合适的超参数要更具挑战性。
- 对于非 LoRA 配置参数的建议是:将学习率设置得相对较低,大约 `1e-5` 应该可以,并将 `mixed_precision` 设置为 `None`。
结果
以下是对于提示词 `bear`(熊)、`heaven`(天堂)和 `dune`(沙丘),微调前(左)和微调后(右)的输出(每行对应一个提示词的输出)。
| 微调前 | 微调后 |
|---|---|
 |
 |
 |
 |
 |
 |
局限性
- 目前 `trl` 的 DDPOTrainer 仅限于微调原版 SD 模型;
- 在我们的实验中,我们主要关注 LoRA,它效果很好。我们也进行了一些全量训练的实验,这可以带来更好的质量,但找到合适的超参数更具挑战性。
结论
像 Stable Diffusion 这样的扩散模型,在使用 DDPO 进行微调后,可以在人类感知或任何其他可被恰当概念化为目标函数的指标上,显著提升生成图像的质量。
DDPO 的计算效率及其在不依赖近似的情况下进行优化的能力,尤其是在与早期实现相同微调扩散模型目标的方法相比时,使其成为微调像 Stable Diffusion 这样的扩散模型的合适选择。
`trl` 库的 `DDPOTrainer` 实现了用于微调 SD 模型的 DDPO。
我们的实验结果强调了 DDPO 在广泛提示词上泛化的能力,尽管通过变化提示词进行显式泛化的尝试结果好坏参半。为非 LoRA 设置找到合适的超参数的困难也成为一个重要的经验教训。
DDPO 是一种很有前途的技术,可以将扩散模型与任何奖励函数对齐,我们希望通过在 TRL 中的发布,能让它更容易地被社区所用!
致谢
感谢 Chunte Lee 为这篇博文制作缩略图。