Hugging Face 上 5 个最被低估的工具







Hugging Face Hub 拥有超过 85 万个公共模型,每月新增约 5 万个,而且这个数字还在不断攀升。我们还提供企业版 Hub 订阅,可解锁合规性、安全性和治理功能,以及推理端点上用于生产级推理的额外计算能力,以及在 Spaces 上进行演示的更多硬件选项。
Hugging Face Hub 允许广泛使用,因为您拥有多样化的硬件,并且几乎可以在Docker Spaces中运行任何您想要的东西。我注意到我们有许多默默无闻的功能(如下所示)。在 Hugging Face Hub 上创建一个语义搜索应用程序的过程中,我利用了所有这些功能来实现解决方案的各个部分。虽然我认为最终的应用程序(在本组织reddit-tools-HF中详细介绍)引人注目,但我希望通过这个例子来展示如何将其应用于您自己的项目。
- ZeroGPU - 如何使用免费 GPU?
- 多进程 Docker - 如何在一个空间中解决 2(n)个问题?
- Gradio API - 如何让多个空间协同工作?
- Webhooks - 如何根据 Hub 的变化触发空间中的事件?
- Nomic Atlas - 功能丰富的语义搜索(视觉和文本)
用例
针对动态数据源的自动更新、可视化、语义搜索,免费
很容易想象出多种有用的场景
- 希望根据描述或报告的问题处理其众多产品的电子商务平台
- 需要梳理法律文件或法规的律师事务所和合规部门
- 需要跟上新进展并找到与其需求相关的论文或文章的研究人员
我将通过使用 Reddit 版块作为我的数据源并使用 Hub 来实现其余部分来演示这一点。有多种方法可以实现这一点。我可以把所有东西都放在一个空间里,但这会非常混乱。另一方面,解决方案中有太多组件也有其自身的挑战。最终,我选择了一种设计,它允许我突出 Hub 上的一些无名英雄,并演示如何有效地使用它们。该架构如图 1所示,并以空间、数据集和 Webhook 的形式完全托管在 Hugging Face 上。我使用的每个功能都是免费的,以实现最大的可访问性。当您需要扩展您的服务时,您可能需要考虑升级到企业版 Hub。
 |
|---|
| 图 1:项目流程 可点击版本在这里 |
您可以看到我使用 r/bestofredditorupdates 作为我的数据源,它每天有 10-15 个新帖子。我每天使用其 API 通过 Reddit 应用程序和 PRAW 从中提取数据,并将结果存储在原始数据集中(reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates)。存储新数据会触发一个 Webhook,进而触发数据处理空间采取行动。数据处理空间将获取原始数据集并向其添加列,即由嵌入模型空间生成并使用 Gradio 客户端检索的特征嵌入。数据处理空间将处理后的数据存储在处理后的数据集中。它还将构建数据浏览器工具。请注意,由于数据源,数据被认为是 not-for-all-audiences。更多信息请参阅道德考量
| 组件 | 详情 | 地点 | 额外信息 |
|---|---|---|---|
| 数据源 | 来自 r/bestofredditorupdates 的数据 | 之所以选择它,是因为它是我最喜欢的 Reddit 版块!使用 PRAW 和 Reddit 的 API 拉取 | |
| 数据集创建器空间 | 将新的 Reddit 数据拉入数据集 | reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates(空间) | - 计划的数据集拉取作业 - 通过日志可视化监控进程 1 |
| 原始数据集 | 来自 r/bestofredditorupdates 的最新原始数据聚合 | reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates(数据集) | |
| 数据处理空间 | 为原始数据集添加一个嵌入列以进行语义比较 | reddit-tools-HF/processing-bestofredditorupdates | 显示处理日志和 Nomic Atlas 地图 |
| 嵌入模型空间 | 托管一个嵌入模型 | reddit-tools-HF/nomic-embeddings | 使用 nomic-ai/nomic-embed-text-v1.5* |
| 处理后的数据集 | 带有嵌入的结果数据集 | reddit-tools-HF/reddit-bestofredditorupdates-processed(数据集) | |
| 数据浏览器 | 基于视觉和文本的语义搜索工具 | Nomic Atlas 地图 | 使用 Nomic Atlas 构建:强大的过滤和缩小范围工具 |
*我使用 nomic-ai/nomic-embed-text-v1.5 来生成嵌入,原因如下:
- 处理长上下文良好(8192 token)
- 1.37 亿参数,效率高
- MTEB 排行榜上排名靠前
- 支持 nomic-atlas 进行语义搜索
ZeroGPU
现代模型面临的挑战之一是它们通常需要 GPU 或其他重型硬件才能运行。这些硬件可能体积庞大,需要长期承诺且非常昂贵。Spaces 让您可以轻松地以低成本使用所需的硬件,但它不会自动启动和停止(尽管您可以以编程方式进行!)。ZeroGPU 是一种用于 Spaces 的新型硬件。免费用户有配额,PRO 用户有更大的配额。
它有两个目标:
- 为 Spaces 提供免费 GPU 访问
- 允许 Spaces 在多个 GPU 上运行
 |
|---|
| 图 2:ZeroGPU 幕后 |
这是通过让 Spaces 根据需要高效地持有和释放 GPU 来实现的(与始终连接 GPU 的经典 GPU 空间不同)。ZeroGPU 在底层使用 Nvidia A100 GPU(每个工作负载有 40GB 的 vRAM 可用)。
应用
我使用 ZeroGPU 在我的嵌入模型空间中托管了出色的 nomic 嵌入模型。这非常方便,因为我不需要专门的 GPU,因为我只需要偶尔进行增量推理。
它使用起来极其简单。唯一的改变是您需要有一个函数,其中包含所有 GPU 代码,并用 @spaces.GPU 进行修饰。
import spaces
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True, device='cuda')
@spaces.GPU
def embed(document: str):
return model.encode(document)
多进程 Docker
 |
|---|
| 图 3:数据处理空间 |
我们从企业那里收到的最常见请求之一是:“我想要集成功能 X 或工具 Y。” Hugging Face Hub 最好的部分之一是我们拥有一个异常强大的 API,可以与几乎任何东西集成。解决这个问题的第二种方法通常在 Spaces 中。在这里,我将使用一个空白的Docker Space,它可以运行任意 Docker 容器,并使用您选择的硬件(在我的情况下是免费 CPU)。
我的主要痛点是我想在同一个空间中运行两个非常不同的东西。大多数空间都有一个单一的身份,例如展示一个扩散器模型,或者生成音乐。考虑一下数据集创建者空间,我需要:
- 运行一些代码从 Reddit 拉取数据并将其存储在原始数据集中
- 这是一个大部分不可见的过程
- 这是由
main.py运行的
- 可视化上述代码的日志,以便我能很好地了解正在发生的事情(如图 3所示)
- 这是由
app.py运行的
- 这是由
请注意,这两个都应该在单独的进程中运行。我遇到过许多可视化日志实际上非常有用且重要的用例。它是一个很好的调试工具,在没有自然 UI 的情况下也更美观。
应用
我通过利用 supervisord 库来实现多进程 Docker 解决方案,该库被称为进程控制系统。这是一种干净地控制多个独立进程的方法。Supervisord 允许我在单个容器中执行多项任务,这在 Docker Space 中非常有用。请注意,Spaces 只允许您公开一个端口,因此这可能会影响您考虑的解决方案。
安装 Supervisor 相当容易,因为它是一个 Python 包。
pip install supervisor
您需要编写一个 supervisord.conf 文件来指定您的配置。您可以在此处查看我的完整示例:supervisord.conf。它非常不言自明。请注意,我不想从 program:app 中获取日志,因为 app.py 只是为了可视化日志,而不是创建日志,所以我将它们路由到 /dev/null。
[supervisord]
nodaemon=true
[program:main]
command=python main.py
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
stderr_logfile=/dev/stderr
stderr_logfile_maxbytes=0
autostart=true
[program:app]
command=python app.py
stdout_logfile=/dev/null
stdout_logfile_maxbytes=0
stderr_logfile=/dev/stderr
stderr_logfile_maxbytes=0
autostart=true
autorestart=true
最后,我们需要启动 supervisord.conf 来实际运行我们的两个进程。在我的 Dockerfile 中,我只需运行:
CMD ["supervisord", "-c", "supervisord.conf"]
Gradio API
在数据处理空间中,我需要帖子的嵌入,如果我在另一个空间中抽象嵌入模型,这将带来挑战。我该如何调用它呢?
当您构建一个 Gradio 应用程序时,默认情况下您可以将任何交互视为 API 调用。这意味着 Hub 上的所有那些酷炫空间都关联了一个 API(如果作者启用,Spaces 也允许您对 Streamlit 或 Docker 空间进行 API 调用)!更酷的是,我们有一个易于使用的客户端来调用这个 API。
应用
我在数据处理空间中使用了客户端,从部署在嵌入模型空间中的 nomic 模型获取嵌入。它被用于此utilities.py文件中,我已将相关部分摘录如下。
from gradio_client import Client
# Define the Client
client = Client("reddit-tools-HF/nomic-embeddings")
# Create an easy to use function (originally applied to a dataframe)
def update_embeddings(content, client):
# Note that the embedding model requires you to add the relevant prefix
embedding = client.predict('search_document: ' + content, api_name="/embed")
return np.array(embedding)
# Consume
final_embedding = update_embeddings(content=row['content'], client=client)
Webhooks
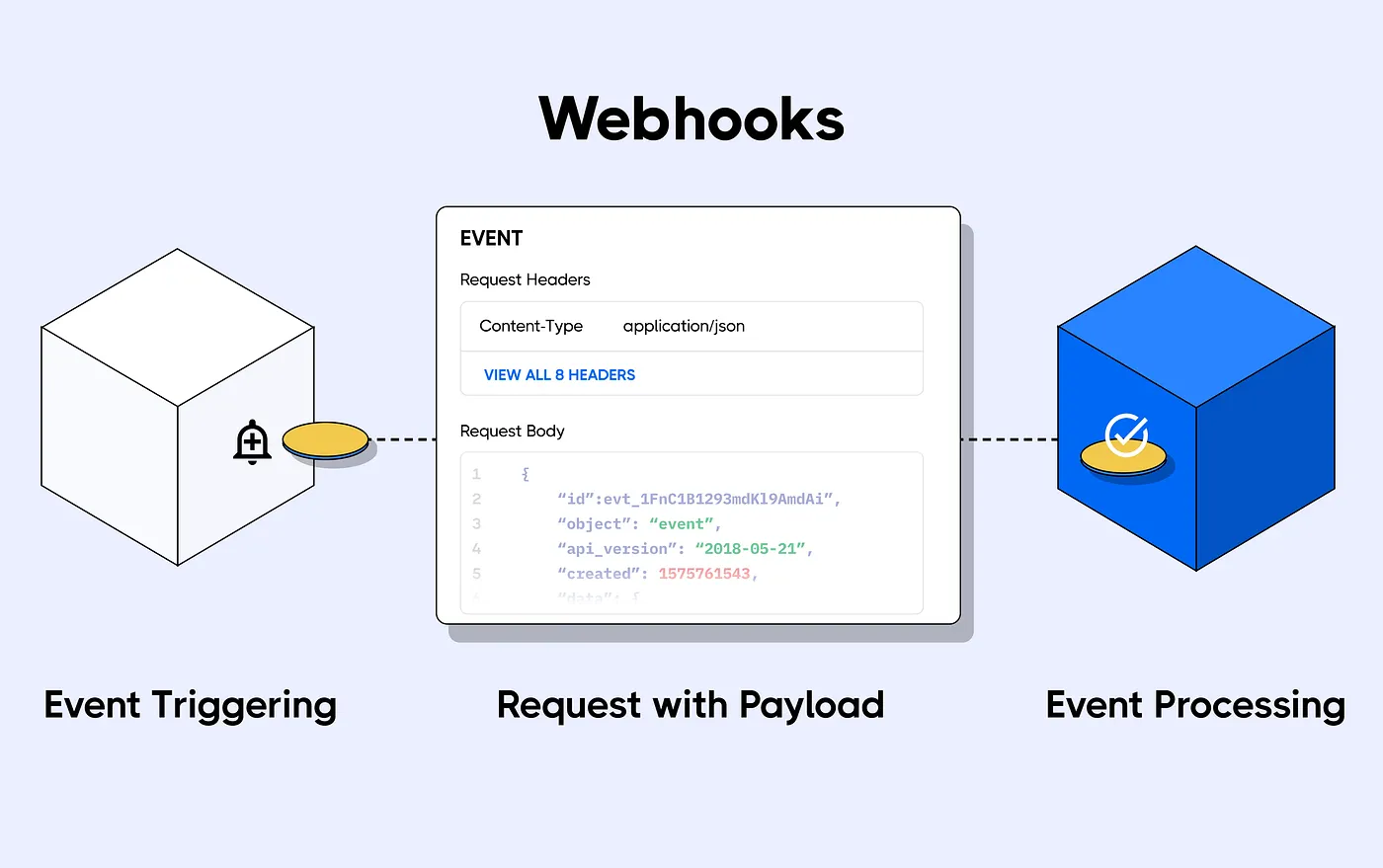 |
|---|
| 图 4:项目 Webhook |
Webhooks 是 MLOps 相关功能的基础。它们允许您监听特定仓库或属于特定用户/组织集的所有仓库的新更改(不仅是您的仓库,还包括任何仓库)。
您可以使用它们自动转换模型、构建社区机器人、为您的模型、数据集和 Spaces 构建 CI/CD,以及更多!
应用
在我的用例中,我希望在更新原始数据集时重建处理过的数据集。您可以在此处查看完整代码。为此,我需要添加一个在原始数据集更新时触发的 webhook,并将其有效负载发送到数据处理空间。可能发生多种类型的更新,有些可能在其他分支或讨论选项卡中。我的标准是在主分支上同时更新 README.md 文件和另一个文件时触发,因为这是新提交推送到数据集时发生的变化(这里有一个示例)。
# Commit cleaned up for readability
T 1807 M README.md
T 52836295 M data/train-00000-of-00001.parquet
首先,您需要在设置中创建 webhook。最好按照此指南创建 webhook,确保使用一致的端点名称(在我的情况下是/dataset_repo)。
另请注意,webhook URL 是直接 URL 附加 /webhooks。直接 URL 可以通过点击空间上方 3 个点并选择 Embed this Space 找到。我还在数据处理空间中设置了webhook 密钥以确保安全。
这是我的 webhook 创建输入的样子。只是不要告诉任何人我的秘密 😉。
目标存储库:datasets/reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates
Webhook URL: https://reddit-tools-hf-processing-bestofredditorupdates.hf.space/webhooks/dataset_repo
秘密(可选):Float-like-a-butterfly
接下来,您需要在您的空间中消费您的 webhook。为此,我将讨论
- 如何设置 webhook 服务器
- 如何有选择地只触发我们关心的更新
- 它必须是
repo更改 - 它必须在主分支上:
refs/heads/main - 它必须是一个不仅仅改变了
README.md的更新
- 它必须是
如何设置 webhook 服务器
首先,我们需要消费负载。我们在 huggingface_hub 库中内置了消费 webhook 负载的便捷方式。您可以看到我使用 @app.add_webhook 定义了一个与我在 webhook 创建时所做的一致的端点。然后我定义我的函数。
请注意,您需要在 30 秒内响应有效负载请求,否则会收到 500 错误。这就是为什么我有一个异步函数来响应,然后启动我的实际进程,而不是在 handle_repository_changes 函数中进行处理。您可以查看后台任务文档以获取更多信息。
from huggingface_hub import WebhookPayload, WebhooksServer
app = WebhooksServer(ui=ui.queue(), webhook_secret=WEBHOOK_SECRET)
# Use /dataset_repo upon webhook creation
@app.add_webhook("/dataset_repo")
async def handle_repository_changes(payload: WebhookPayload, task_queue: BackgroundTasks):
###################################
# Add selective trigger code here #
###################################
logger.info(f"Webhook received from {payload.repo.name} indicating a repo {payload.event.action}")
task_queue.add_task(_process_webhook, payload=payload)
return Response("Task scheduled.", status_code=status.HTTP_202_ACCEPTED)
def _process_webhook(payload: WebhookPayload):
#do processing here
pass
选择性触发
由于我对仓库级别的任何更改都感兴趣,因此我可以使用 payload.event.scope.startswith("repo") 来确定我是否关心此传入负载。
# FILTER 1: Don't trigger on non-repo changes
if not payload.event.scope.startswith("repo"):
return Response("No task scheduled", status_code=status.HTTP_200_OK)
我可以通过 payload.updatedRefs[0] 访问分支信息。
# FILTER 2: Dont trigger if change is not on the main branch
try:
if payload.updatedRefs[0].ref != 'refs/heads/main':
response_content = "No task scheduled: Change not on main branch"
logger.info(response_content)
return Response(response_content, status_code=status.HTTP_200_OK)
except:
response_content = "No task scheduled"
logger.info(response_content)
return Response(response_content, status_code=status.HTTP_200_OK)
检查哪些文件被更改有点复杂。我们可以在 commit_files_url 中看到一些 git 信息,但随后我们需要解析它。它有点像 .tsv。
步骤
- 获取提交信息
- 将其解析为
changed_files - 根据我的条件采取行动
from huggingface_hub.utils import build_hf_headers, get_session
# FILTER 3: Dont trigger if there are only README updates
try:
commit_files_url = f"""{payload.repo.url.api}/compare/{payload.updatedRefs[0].oldSha}..{payload.updatedRefs[0].newSha}?raw=true"""
response_text = get_session.get(commit_files_url, headers=build_hf_headers()).text
logger.info(f"Git Compare URl: {commit_files_url}")
# Splitting the output into lines
file_lines = response_text.split('\n')
# Filtering the lines to find file changes
changed_files = [line.split('\t')[-1] for line in file_lines if line.strip()]
logger.info(f"Changed files: {changed_files}")
# Checking if only README.md has been changed
if all('README.md' in file for file in changed_files):
response_content = "No task scheduled: its a README only update."
logger.info(response_content)
return Response(response_content, status_code=status.HTTP_200_OK)
except Exception as e:
logger.error(f"{str(e)}")
response_content = "Unexpected issue :'("
logger.info(response_content)
return Response(response_content, status_code=status.HTTP_501_NOT_IMPLEMENTED)
Nomic Atlas
我们看到客户/合作伙伴面临的一个常见痛点是数据理解和协作具有挑战性。数据理解通常是解决任何 AI 用例的第一步。我最喜欢的方式是通过可视化来完成,而通常我觉得在语义数据方面没有很好的工具。我非常高兴地发现了 Nomic Atlas。它允许我拥有许多用于数据探索的关键功能:
- 使用 nomic-ai/nomic-embed-text-v1.5 进行语义搜索(目前处于测试阶段)
- 功能丰富的筛选
- 关键词搜索
- 套索搜索(我可以绘制边界!!)
应用
我在数据处理空间中构建了 nomic Atlas。在流程中,我已经构建了处理过的数据集,剩下的唯一事情就是将其可视化。您可以在 build_nomic.py 中查看我如何使用 nomic 进行构建。与之前一样,我将为本博客摘录相关部分。
from nomic import atlas
from nomic.dataset import AtlasClass
from nomic.data_inference import NomicTopicOptions
# Login to nomic with a Space Secret
NOMIC_KEY = os.getenv('NOMIC_KEY')
nomic.login(NOMIC_KEY)
# Set because I do want the super cool topic modeling
topic_options = NomicTopicOptions(build_topic_model=True, community_description_target_field='subreddit')
identifier = 'BORU Subreddit Neural Search'
project = atlas.map_data(embeddings=np.stack(df['embedding'].values),
data=df,
id_field='id',
identifier=identifier,
topic_model=topic_options)
print(f"Succeeded in creating new version of nomic Atlas: {project.slug}")
鉴于 nomic 的工作原理,每次运行 atlas.map_data 时,它都会在您的帐户下创建一个新的 Atlas 数据集。我希望保持相同的数据集更新。目前最好的方法是删除旧数据集。
ac = AtlasClass()
atlas_id = ac._get_dataset_by_slug_identifier("derek2/boru-subreddit-neural-search")['id']
ac._delete_project_by_id(atlas_id)
logger.info(f"Succeeded in deleting old version of nomic Atlas.")
#Naively wait until it's deleted on the server
sleep_time = 300
logger.info(f"Sleeping for {sleep_time}s to wait for old version deletion on the server-side")
time.sleep(sleep_time)
功能
 |
|---|
| 图 5:Nomic 截图 |
使用 Nomic Atlas 应该是不言自明的,您可以在此处找到更多文档。但我将简要介绍一下,以便我可以突出一些鲜为人知的功能。
带点的主要区域显示每个嵌入的文档。每个文档越接近,它们之间的关联性就越大。这会根据一些因素而变化(嵌入器在您的数据上的工作效果、从高维度到二维表示的压缩等),所以请持保留态度。我们可以在左侧搜索和查看文档。
在图 5的红色框中,我们可以看到 5 个框,它们允许我们以不同的方式搜索。每个框都迭代应用,这使得它成为“蚕食大象”的好方法。例如,我们可以按日期或其他字段搜索,然后使用文本搜索。最酷的功能是最左边的那个,它是一个神经搜索,您可以通过 3 种方式使用它:
- 查询搜索 - 您提供一个简短的描述,该描述应与嵌入的(长)文档匹配
- 文档搜索 - 您提供一个长的文档,该文档应与嵌入的文档匹配
- 嵌入搜索 - 直接使用嵌入向量进行搜索
当我探索上传的文档时,我通常使用查询搜索。
在图 5的蓝色框中,我们可以看到我上传的数据集的每一行都得到了很好的可视化。我非常喜欢的一个功能是它能够可视化 HTML。因此,您可以控制它的外观。由于 Reddit 帖子采用 Markdown 格式,因此很容易将其转换为 HTML 进行可视化。
道德考量
所有这些的数据源包含标记为不适合工作(NSFW)的内容,这类似于我们标记的非所有观众可见(NFAA)。我们不禁止 Hub 上的此类内容,但我们确实希望相应地处理它。此外,最近的工作表明,从互联网上随意获取的内容存在包含儿童性虐待材料(CSAM)的风险,特别是那些未经筛选的性材料普遍存在的内容。
为了评估此数据集整理工作中存在的风险,我们可以首先查看源数据整理过程。原始故事(在聚合之前)会经过版主审核,然后更新通常在有版主的 subreddit 中进行。偶尔,更新会上传到原始发帖人的个人资料。最终版本会上传到 r/bestofredditorupdates,该版块有严格的审核。它们之所以严格,是因为它们面临更多“群殴”的风险。总而言之,至少有 2 个审核步骤,通常是 3 个,其中一个以严格著称。
在撰写本文时,有 69 个故事被标记为 NSFW。其中,我手动检查后,没有任何一个包含 CSAM 材料。我还对包含 NFAA 材料的数据集进行了限制。为了使 nomic 可视化更易于访问,我在 atlas 创建时通过删除数据框中包含“NSFW”内容的帖子来创建一个过滤后的数据集。
结论
通过揭示 Hugging Face Hub 中这些鲜为人知的工具和功能,我希望激发您在构建 AI 解决方案时跳出固有思维。无论您是复制我概述的用例,还是提出完全属于您自己的想法,这些工具都可以帮助您构建更高效、更强大、更具创新性的应用程序。立即开始,释放 Hugging Face Hub 的全部潜力!
参考文献
- Fikayo Adepoju, Webhooks 教程:Webhook 工作入门指南, 2021
- philipchircop, CHIP IT AWAY, 2012







