AI 范式转变已来:2025 年第二季度 Hugging Face 论文排名前 50 的 4 大颠覆性趋势


规模竞赛已然结束。智能竞赛刚刚开始。我们将深入剖析强化学习、效率、代理和数据这四大关键趋势,它们正在重新定义人工智能的未来。
如果你一直在关注人工智能,你可能会认为故事很简单:更大的模型、更多的参数、更好的性能。但 2025 年第二季度的最新研究浪潮却讲述了一个不同寻常、更加细致入微的故事。模型规模的疯狂竞赛正在降温,一场新的、更深刻的竞争正在升温——这场竞争的焦点在于效率、深度推理和智能设计。
Hugging Face 上投票最多的论文不再仅仅是打破参数记录。相反,它们提出了根本性的问题:强化学习 (RL) 真的在创造新知识,还是仅仅在完善现有能力?如果计算瓶颈不在模型规模,那又在哪里?我们如何构建代理,使其不仅仅是“涌现”技能,而是系统地与核心推理原则对齐?最重要的是,如果数据不仅仅是燃料,而是算法本身呢?
在这篇文章中,我们将深入探讨本季度最受欢迎的 50 篇论文,以揭示正在重塑 AI 格局的范式转变。首先,我们将列出这些开创性研究的精选清单。然后,我们将把我们的发现综合成四个关键见解,揭示 AI 的下一步发展方向。
🚀 2025 年第二季度排名前 50 的论文(按投票数排名)
以下是引起社区关注的论文,按投票数降序排列。
(1) 基础代理的进展与挑战:从类脑智能到进化、协作和安全系统(293 票)
论文链接: https://huggingface.co/papers/2504.01990
简介
MetaGPT、蒙特利尔大学、Mila、南洋理工大学、微软亚洲研究院和 DeepMind 等机构合作提出的这篇论文,对基础代理进行了全面调查。它将智能代理置于模块化、类脑的架构中,系统地探讨了它们的认知、感知和操作模块,同时深入研究了自我增强、协作和安全等挑战。
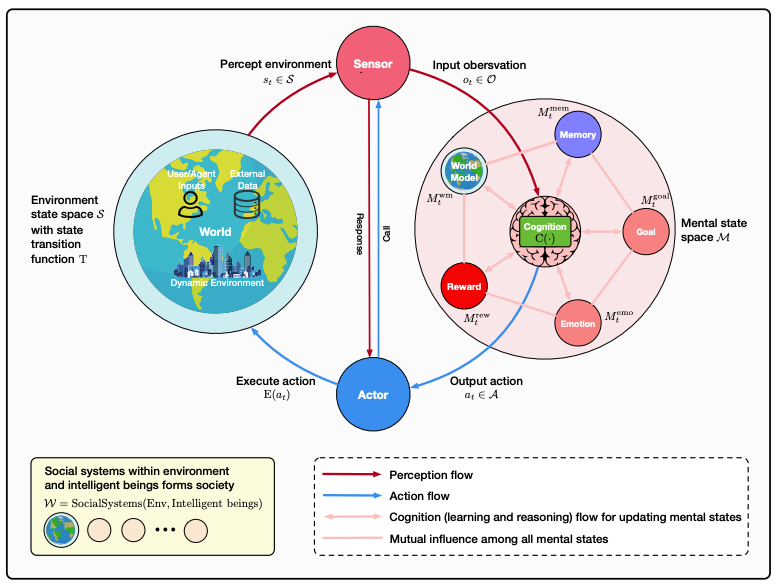
(2) InternVL3:探索开源多模态模型的高级训练和测试时方案(276 票)
论文链接: https://huggingface.co/papers/2504.10479
简介
由上海人工智能实验室、商汤科技、清华大学等机构共同提出的 InternVL3 引入了一种原生多模态预训练范式。它不是对纯文本 LLM 进行改造,而是从一开始就共同获取多模态和语言能力。它在 MMMU 等基准测试中取得了最先进的性能,可与 ChatGPT-4o 等专有模型媲美。
核心图片: 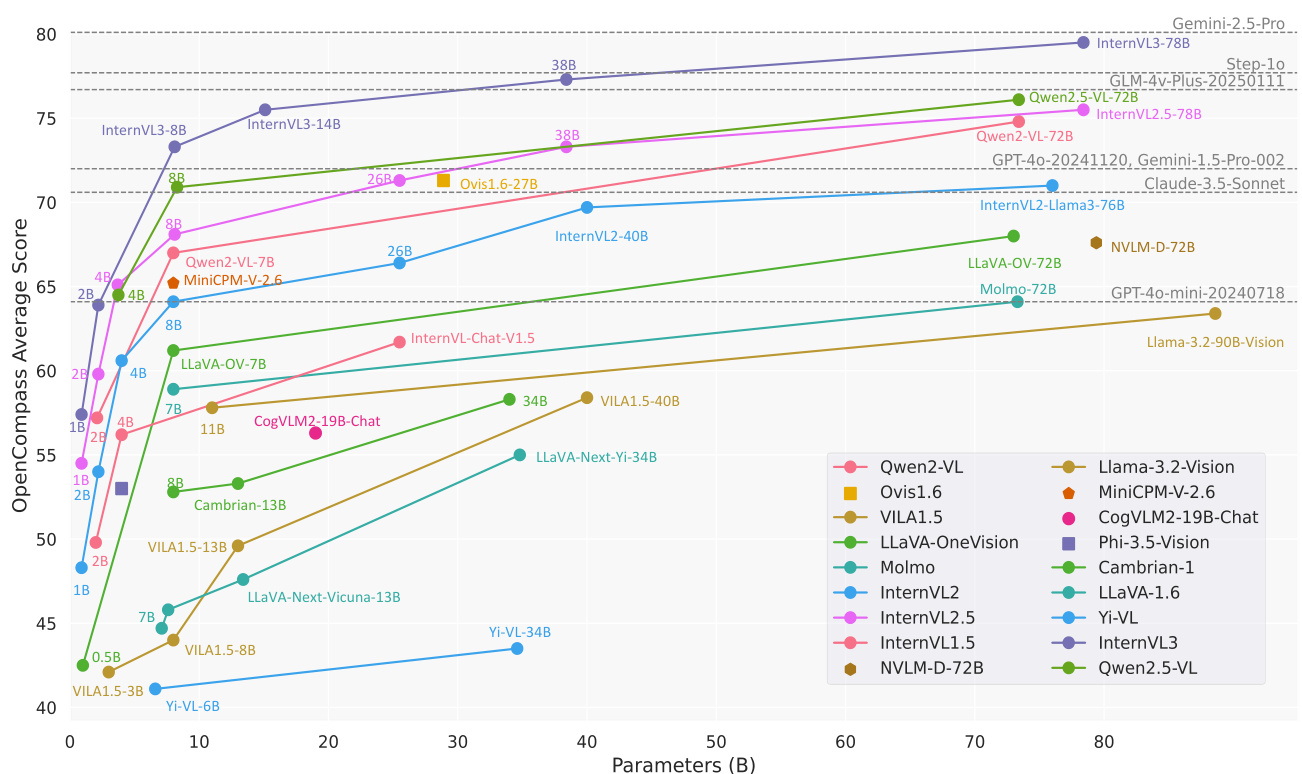
(3) 反思、重试、奖励:通过强化学习自提升 LLM(256 票)
论文链接: https://huggingface.co/papers/2505.24726
简介
Writer, Inc. 提出了“反思、重试、奖励”框架,用于 LLM 自我提升。当模型失败时,它会生成自我反思。如果随后的尝试成功,则通过强化学习奖励反思过程。这种方法仅使用二元反馈即可提高复杂任务的性能,而无需合成数据。
核心图片: 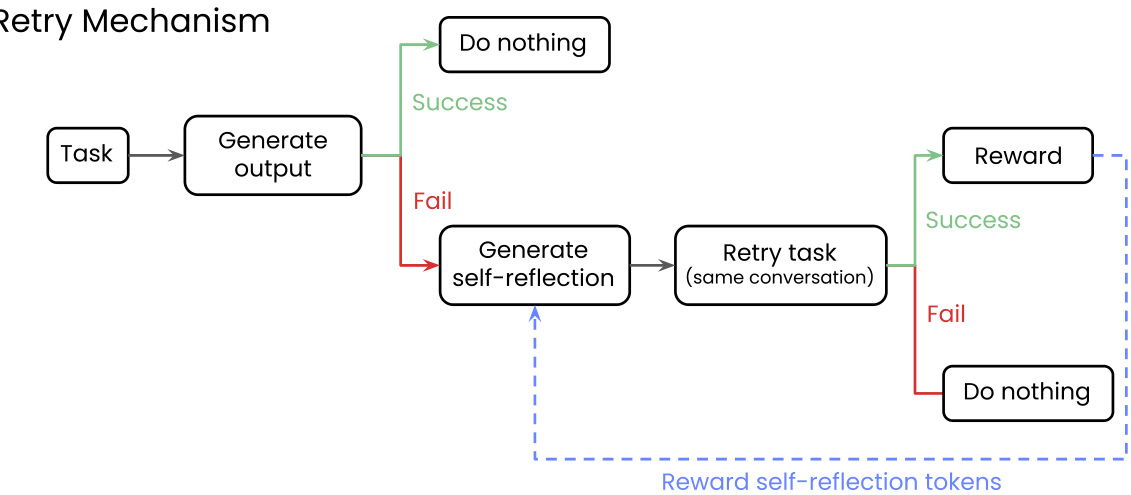
(4) MiniMax-M1:利用闪电注意力高效扩展测试时计算(249 票)
论文链接: https://huggingface.co/papers/2506.13585
简介
MiniMax 引入了 MiniMax-M1,这是第一个开放权重、大规模混合注意力推理模型。它将专家混合 (MoE) 架构与闪电注意力相结合,支持 1M 令牌上下文。凭借其新颖的强化学习算法 CISPO,它在复杂任务上实现了卓越性能,同时显著降低了训练成本。
核心图片: 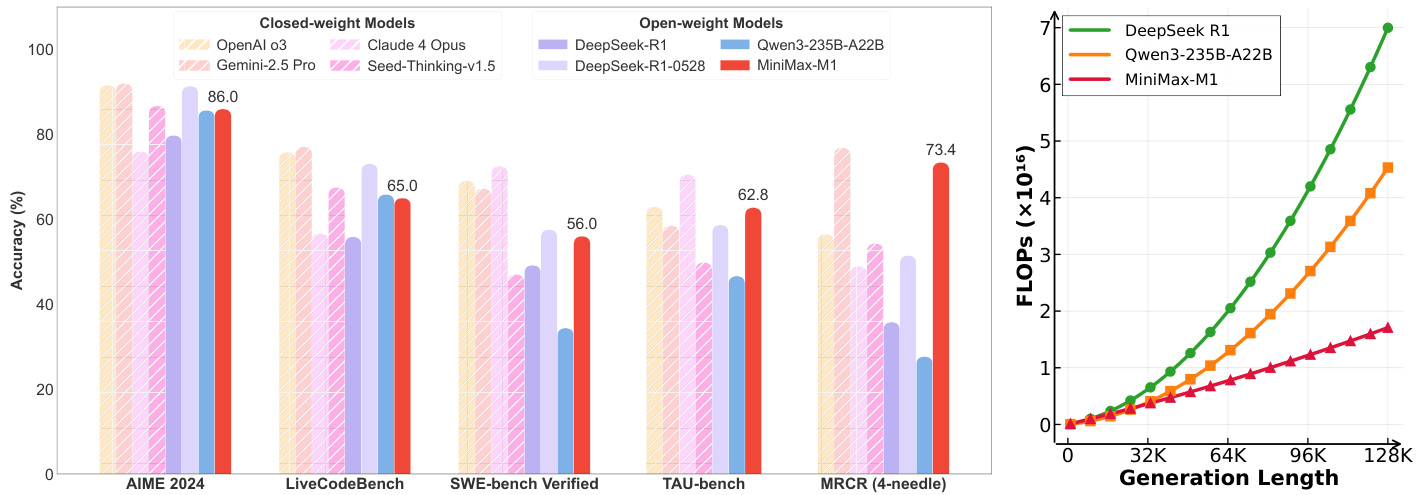
(5) 强化预训练(238 票)
论文链接: https://huggingface.co/papers/2506.08007
简介
微软研究院、北京大学和清华大学引入了强化预训练 (RPT),这是一种扩展 LLM 的新范式。它将下一个令牌预测重新定义为一项通过强化学习训练的推理任务,其中模型因正确预测而获得可验证的奖励。RPT 利用海量文本数据进行通用强化学习,提高了准确性并为微调提供了坚实基础。
核心图片: 
(其余 45 篇论文格式相同) ...
(6) Mutarjim:利用小型语言模型推进双向阿拉伯语-英语翻译(217 票)
论文链接: https://huggingface.co/papers/2505.17894
简介: 由 MISRAJA 提出的 Mutarjim 是一种紧凑但功能强大的双向阿拉伯语-英语翻译模型。它基于 1.5B Kuwain 模型,性能优于其 20 倍大的模型,甚至在某些基准测试上可与 GPT-4o mini 媲美,这得益于优化的两阶段训练方法。 核心图片: 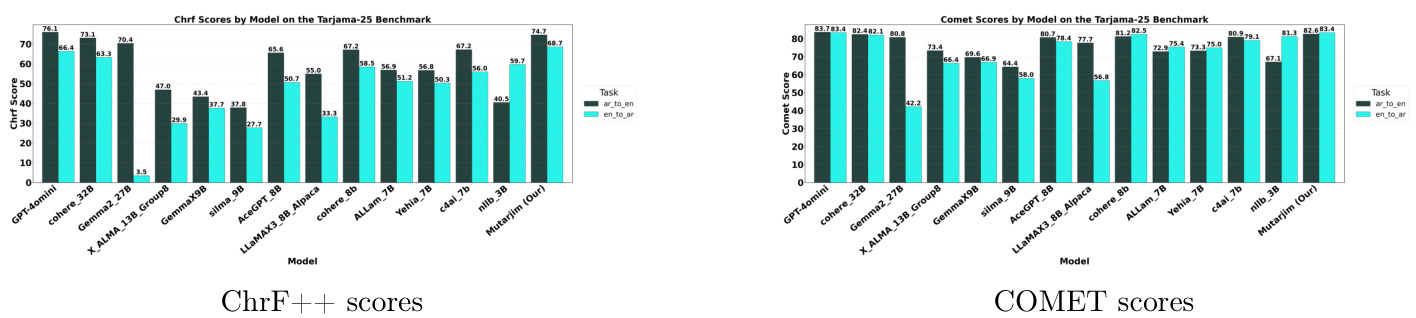
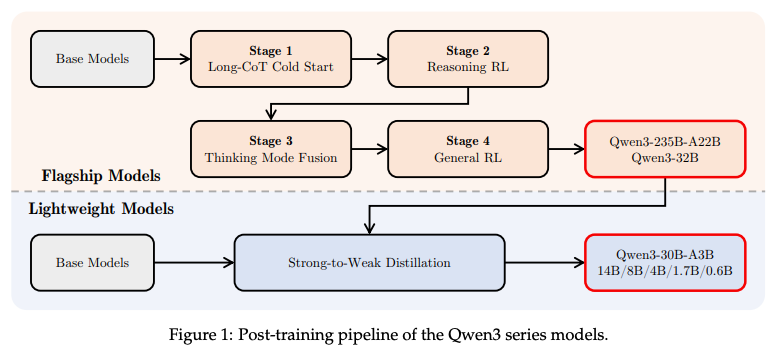
(7) Qwen3 技术报告(209 票)
论文链接: https://huggingface.co/papers/2505.09388
简介: Qwen 团队推出了 Qwen3 模型家族,包含 0.6B 至 235B 参数的密集和 MoE 架构。一个关键的创新是统一框架,它集成了用于复杂推理的“思考模式”和用于快速响应的“非思考模式”。
(8) SmolVLM:重新定义小型高效多模态模型(192 票)
论文链接: https://huggingface.co/papers/2504.05299
简介: Hugging Face 和斯坦福大学推出了 SmolVLM,这是一系列紧凑型多模态模型,专为资源高效的推理而设计。最小的 256M 模型使用不到 1GB 的 GPU 内存,性能优于 300 倍大的 Idefics-80B,可实现设备部署。 核心图片: 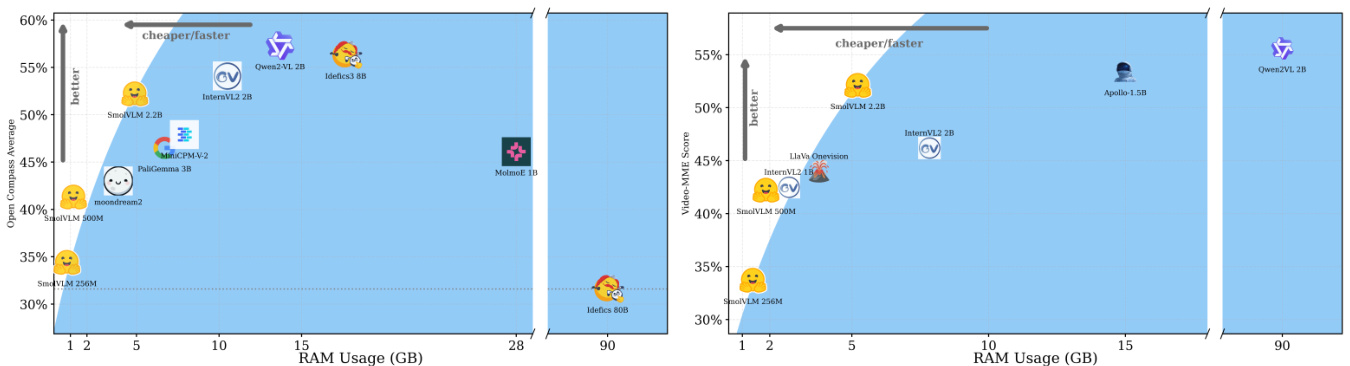
(9) 感知、推理、思考和规划:大型多模态推理模型综述(178 票)
论文链接: https://huggingface.co/papers/2505.04921
简介: 哈尔滨工业大学(深圳)对大型多模态推理模型 (LMRMs) 进行了全面综述。它概述了从模块化管道到统一的、以语言为中心的框架的四阶段发展路线图,并展望了原生、智能的推理模型。 核心图片: 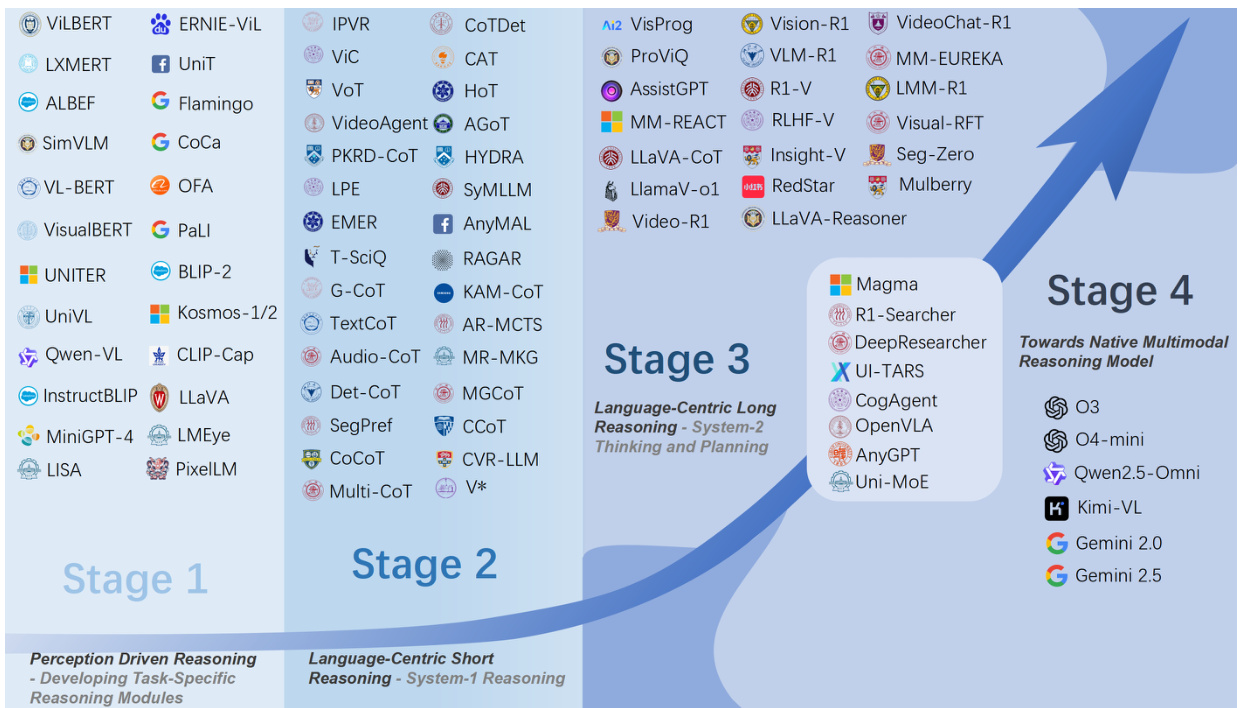
(10) 绝对零:零数据下的强化自博弈推理(177 票)
论文链接: https://huggingface.co/papers/2505.03335
简介: 清华大学等机构提出了 Absolute Zero,这是一种新的强化学习范式,模型通过提出和解决自己的任务来学习,无需任何外部数据。他们的系统 AZR 在编码和数学推理方面取得了 SOTA 性能,证明了通用推理能力可以从自博弈中涌现。 核心图片: 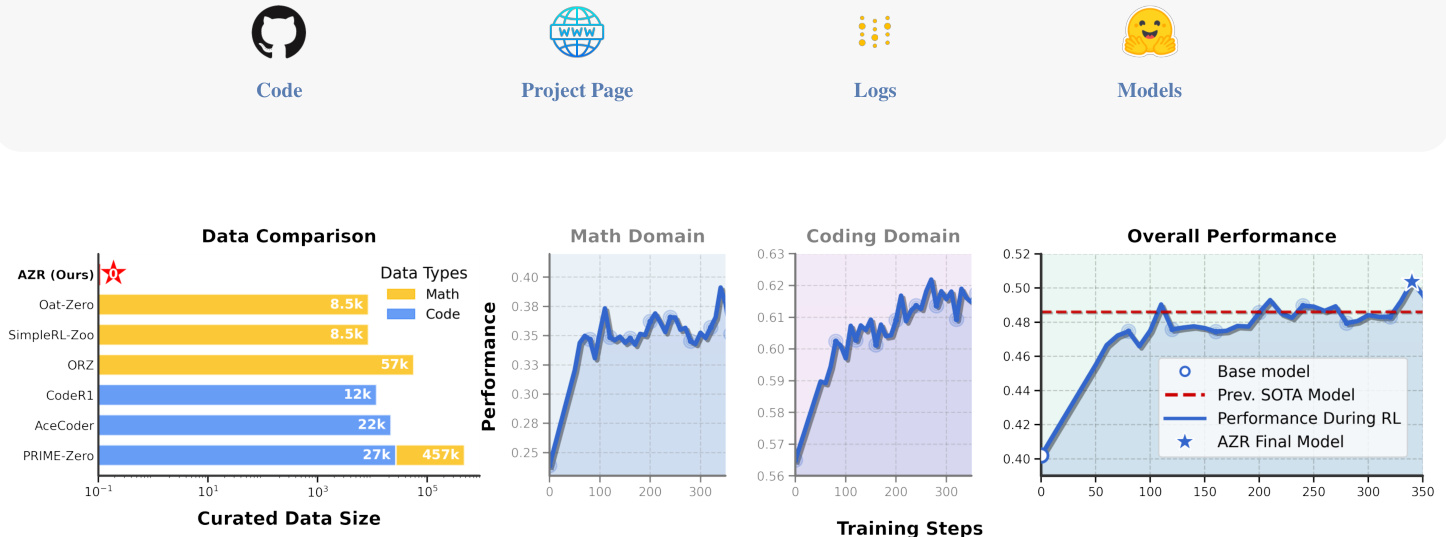
(11) OmniSVG:统一的可伸缩矢量图形生成模型(171 票)
论文链接: https://huggingface.co/papers/2504.06263
简介: 复旦大学和 StepFun 推出了 OmniSVG,一个用于端到端多模态 SVG 生成的统一框架。它使用预训练的 VLM,可以从简单的图标生成高质量、复杂的 SVG,包括精细的动漫角色,并引入了一个新的 2M 资产数据集 MMSVG-2M。 核心图片: 
(12) 超越二八法则:高熵少数令牌驱动 LLM 推理的有效强化学习(165 票)
论文链接: https://huggingface.co/papers/2506.01939
简介: 阿里巴巴 Qwen 团队和清华大学发现,一小部分高熵令牌(“分叉令牌”)是 LLM 推理强化学习性能提升的主要驱动因素。仅在这些关键的 20% 令牌上进行训练,即可达到甚至超过全梯度更新的性能。 核心图片: 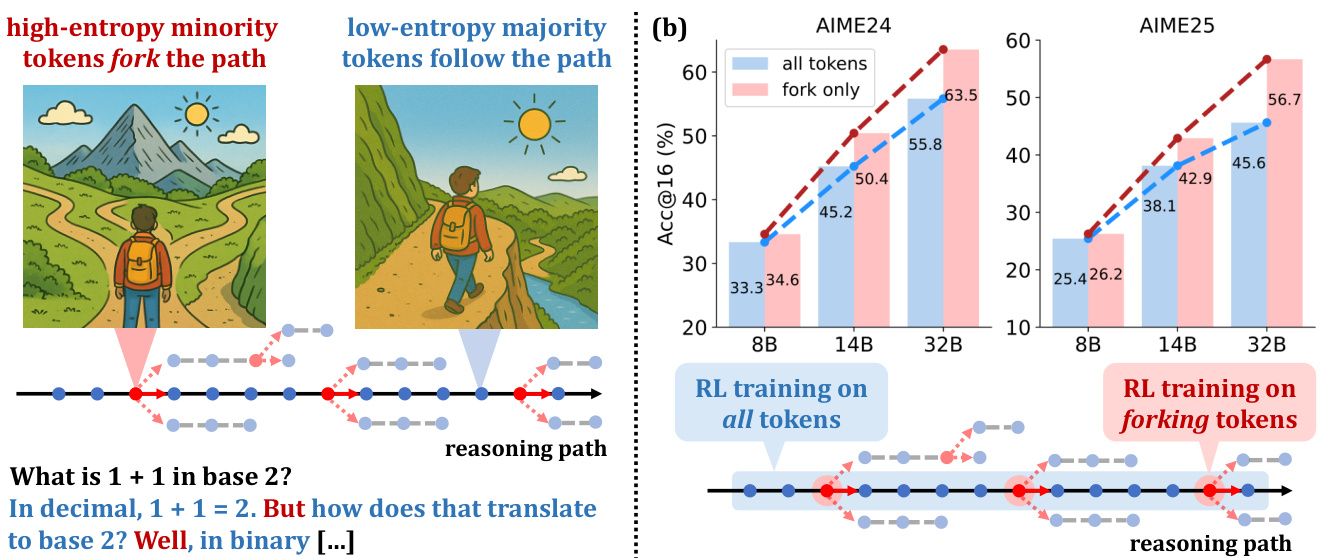
(13) 旨在理解任何视频中的摄像机运动(157 票)
论文链接: https://huggingface.co/papers/2504.15376
简介: CMU、马萨诸塞大学阿默斯特分校等机构推出了 CameraBench,这是一个用于理解摄像机运动的大规模数据集和基准。它与电影摄影师共同设计,具有新的分类法和专家注释,以帮助模型区分几何和语义摄像机运动。 核心图片: 
(14) Seed1.5-VL 技术报告(146 票)
论文链接: https://huggingface.co/papers/2505.07062
简介: 字节跳动 Seed 团队推出了 Seed1.5-VL,一个视觉语言基础模型,拥有 532M 视觉编码器和 20B 活跃参数的 MoE LLM。尽管其尺寸紧凑,它在 60 个公共基准测试中取得了 38 个 SOTA 结果,并在 GUI 控制等以代理为中心的任务中表现出色。 核心图片: 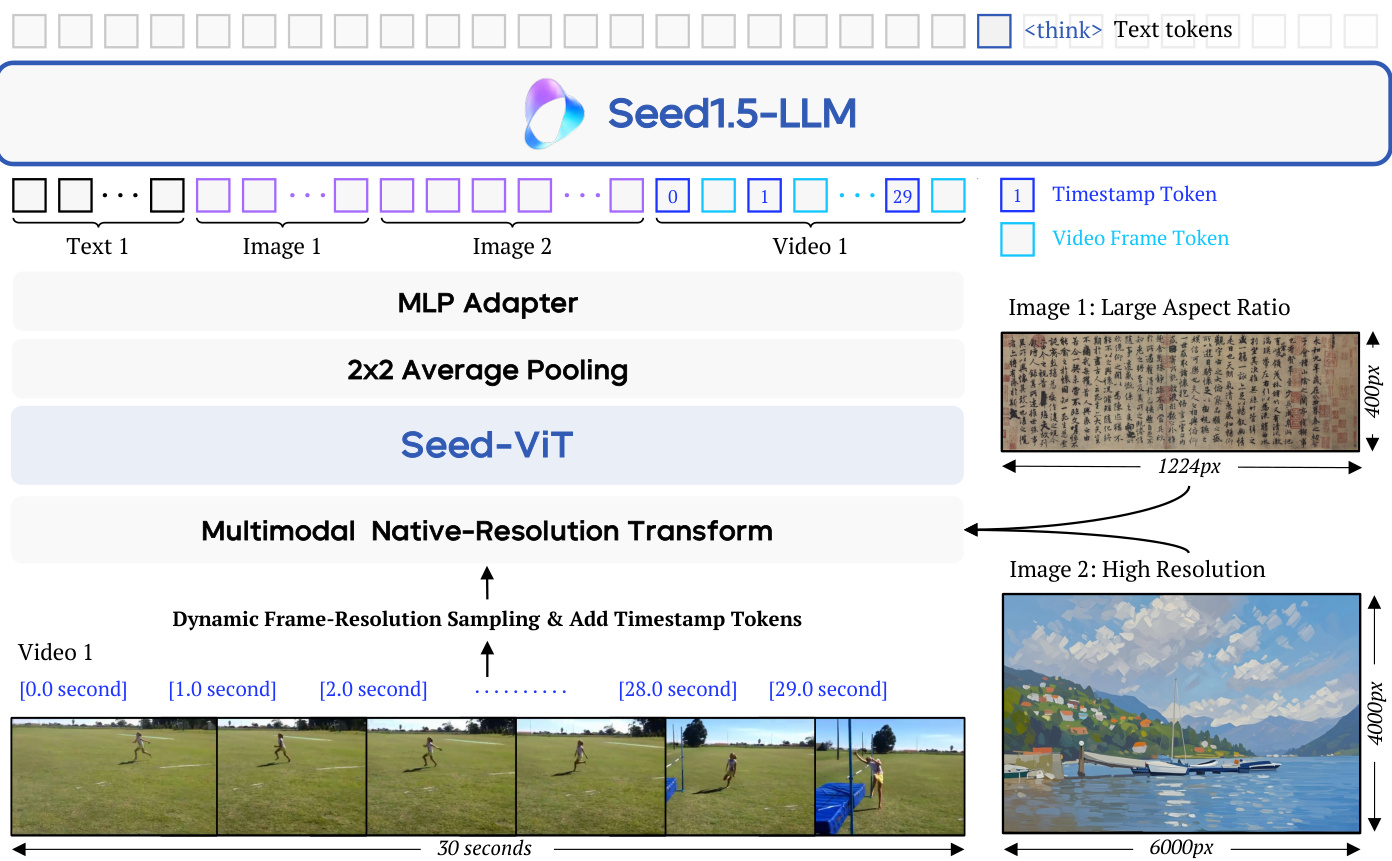
(15) 将 AI 效率从以模型为中心转向以数据为中心的压缩(145 票)
论文链接: https://huggingface.co/papers/2505.19147
简介: 这篇来自上海交通大学等机构的立场论文认为,AI 效率研究的重点正在从以模型为中心转向以数据为中心的压缩。随着模型尺寸的平台化,关键瓶颈现在是长令牌序列注意力机制的二次成本,使得令牌压缩成为新的前沿。 核心图片: 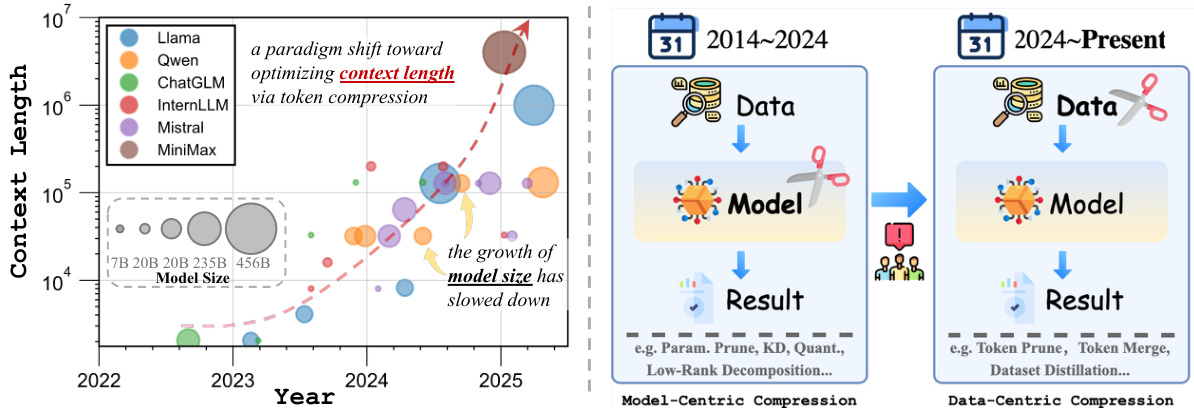
(16) 明天还会是真的吗?多语言常青问题分类以提高可信赖的 QA(134 票)
论文链接: https://huggingface.co/papers/2505.21115
简介: Skoltech 和 AIRI 通过关注问题的时效性来解决 LLM 幻觉问题。他们引入了 EverGreenQA,这是第一个带有“常青”标签的多语言数据集,用于训练分类器,可以区分答案稳定与答案变化的问题,从而提高 QA 的可信赖性。 核心图片: 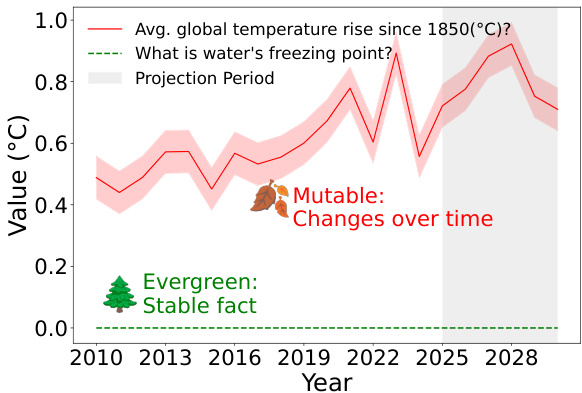
(17) PRIMA.CPP:在低资源日常家庭集群上加速 70B 规模 LLM 推理(133 票)
论文链接: https://huggingface.co/papers/2504.08791
简介: 这项工作引入了 prima.cpp,一个分布式推理系统,可在日常家庭设备(笔记本电脑、手机)上通过 Wi-Fi 运行 70B 规模模型。它使用一种新颖的管道式环并行与预取技术来隐藏磁盘延迟,并采用智能算法来优化将层分配给异构设备。
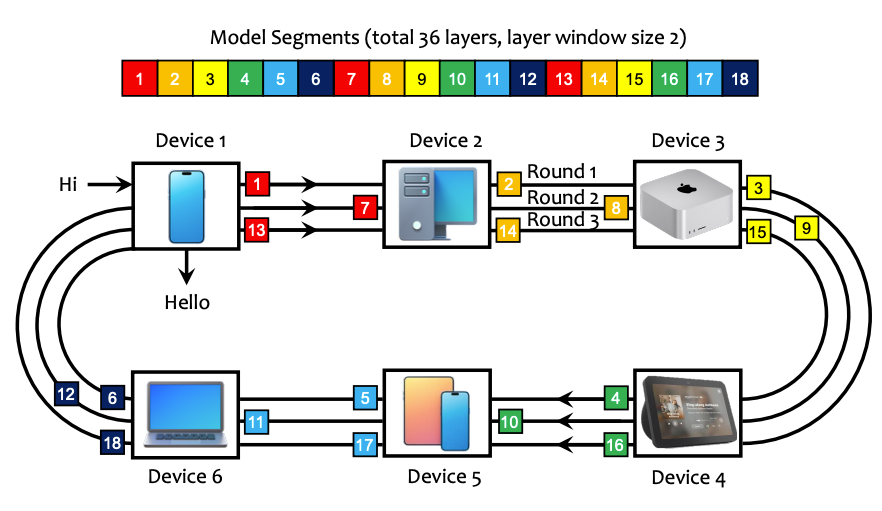
(18) ProRL:长时强化学习扩展大型语言模型的推理边界(132 票)
论文链接: https://huggingface.co/papers/2505.24864
简介: NVIDIA 挑战了强化学习仅增强现有能力的假设。他们引入了 ProRL,一种延长强化学习训练的方法,并表明通过足够的训练时间,模型可以发现基础模型无法获得的全新推理策略,真正扩展了其推理边界。 核心图片: 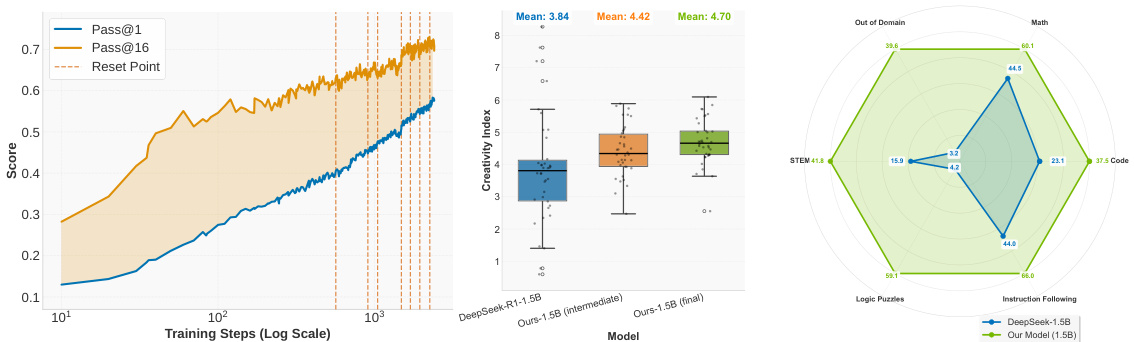
(19) Kimi-VL 技术报告(130 票)
论文链接: https://huggingface.co/papers/2504.07491
简介: Kimi 团队推出了 Kimi-VL,这是一款高效的开源 MoE 视觉语言模型,仅激活 2.8B 参数。它在多模态推理、长上下文理解(128K 窗口)和代理能力方面表现出色,为高效且强大的多模态模型树立了新标准。 核心图片: 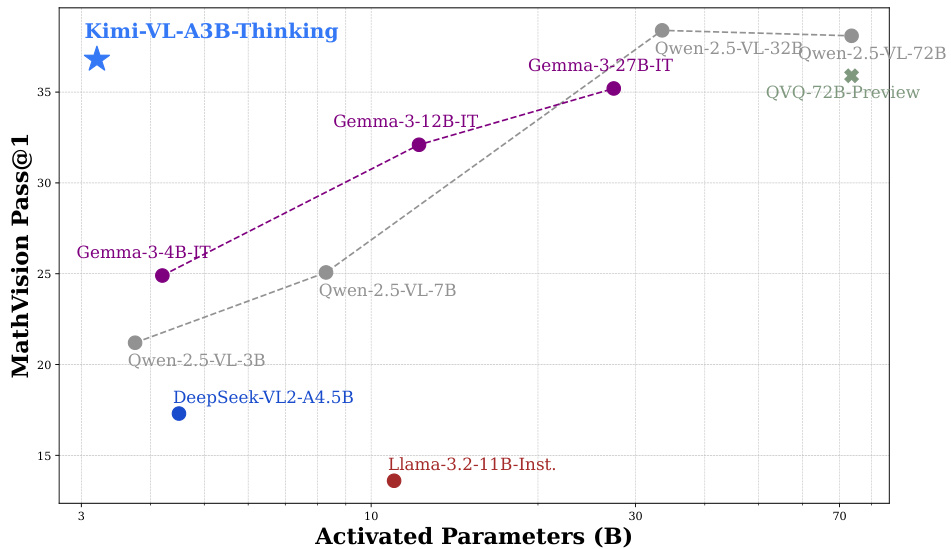
(20) 统一多模态预训练中的涌现特性(130 票)
论文链接: https://huggingface.co/papers/2505.14683
简介: 字节跳动 Seed 等机构引入了 BAGEL,这是一个统一的、仅解码器模型,在数万亿个交错文本、图像、视频和网页令牌上进行预训练。当用如此多样化的数据进行扩展时,BAGEL 在自由形式图像操作和世界导航等复杂推理中展现出涌现能力。 核心图片: 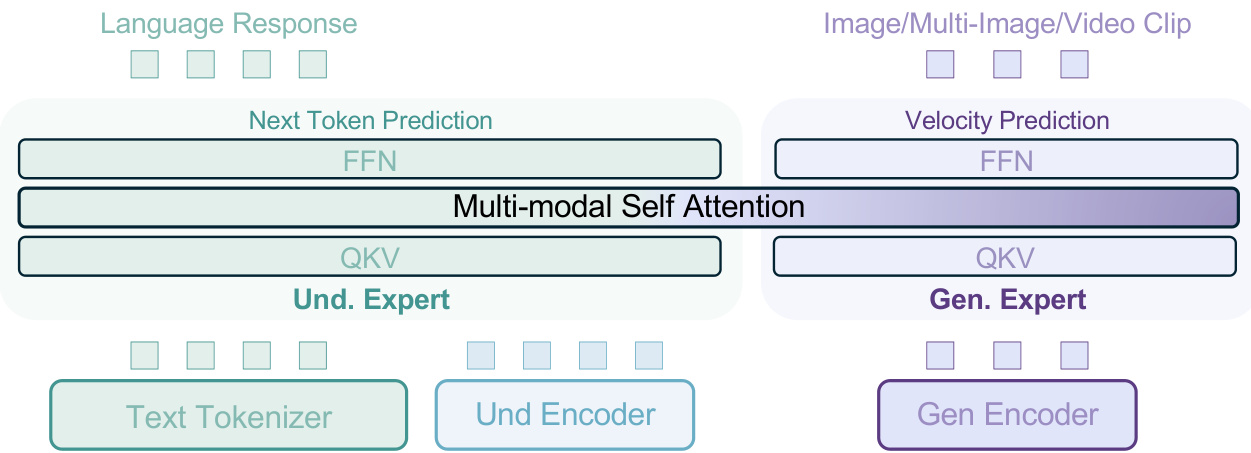
(21) Seaweed-7B:视频生成基础模型的成本效益训练(129 票)
论文链接: https://huggingface.co/papers/2504.08685
简介: 字节跳动 Seed 团队发布了一份关于视频生成模型成本高效训练策略的技术报告。他们的 7B 参数模型 Seaweed-7B 尽管训练资源适中,但表现出与大得多的模型具有竞争力的性能,突出了设计选择的重要性。
(22) 强化学习真的能激励 LLM 超越基础模型的推理能力吗?(129 票)
论文链接: https://huggingface.co/papers/2504.13837
简介: 这项来自清华大学的关键研究重新审视了 RLVR 的影响。通过使用大 k 的 pass@k 指标,他们发现虽然 RL 训练的模型效率更高,但其基础模型通常具有可比甚至更高的推理能力边界。这表明 RLVR 主要使模型偏向于奖励路径,而不是创造新能力。 核心图片: 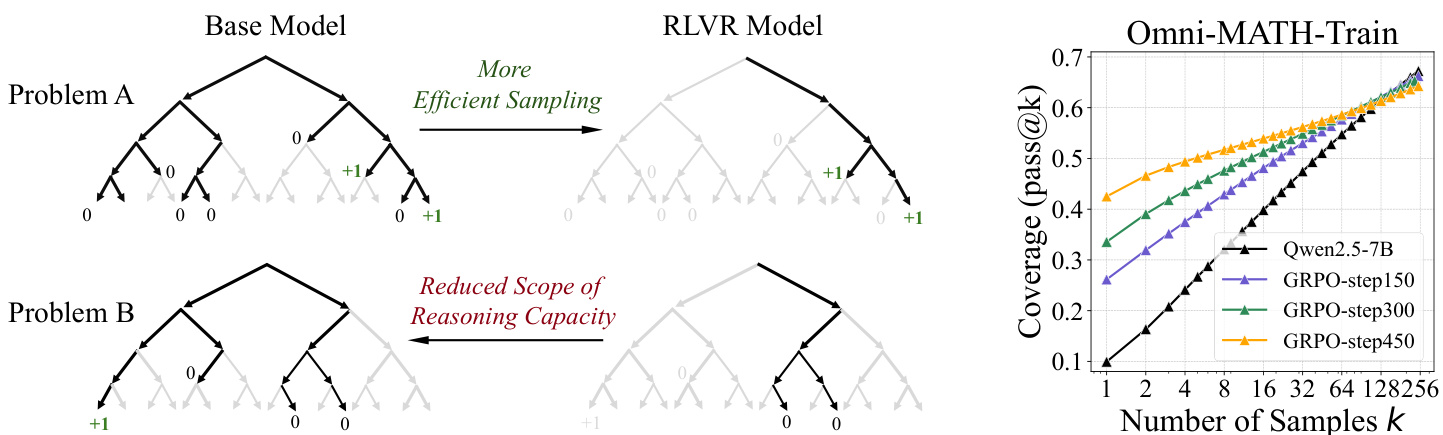
(23) MiniMax-Speech:带有可学习说话人编码器的内在零样本文本到语音(125 票)
论文链接: https://huggingface.co/papers/2505.07916
简介: MiniMax 引入了 MiniMax-Speech,这是一款带有关键创新:可学习说话人编码器的自回归文本到语音 (TTS) 模型。这使其能够在无需转录的情况下从参考音频中提取音色,从而实现高质量、富有表现力的零样本语音合成和 32 种语言的单样本语音克隆。 核心图片: 
(24) 信心就是你需要的一切:语言模型的少样本强化学习微调(124 票)
论文链接: https://huggingface.co/papers/2506.06395
简介: AIRI 和 Skoltech 提出了基于自信心的强化学习 (RLSC),这是一种新颖的方法,它使用模型自身的信心作为奖励信号。这消除了对标签或奖励工程的需求。仅需每个问题 16 个样本和几个训练步骤,RLSC 即可显著提高推理准确性。 核心图片: 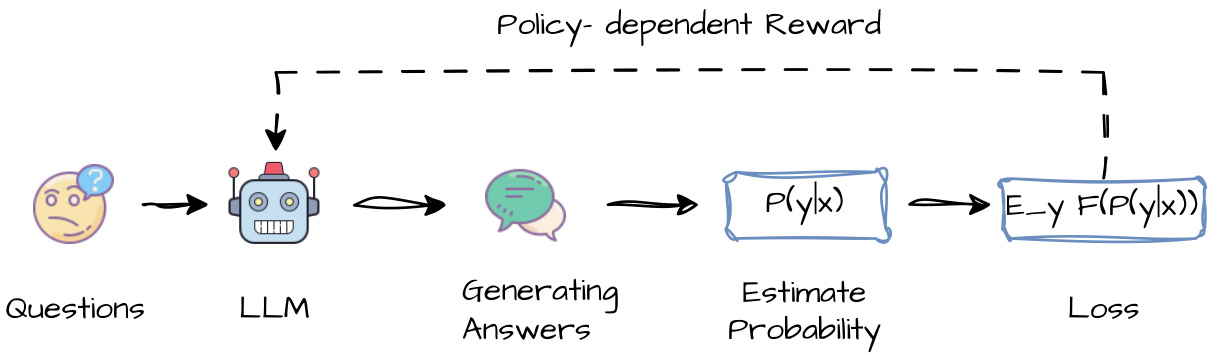
(25) 强化学习在推理语言模型中的熵机制(123 票)
论文链接: https://huggingface.co/papers/2505.22617
简介: 上海人工智能实验室、清华大学等机构研究了推理 LLM 强化学习中的“熵崩溃”现象。他们发现性能受限于策略熵的耗尽,并提出了 Clip-Cov 和 KL-Cov 等新方法来控制熵并摆脱这个陷阱,从而带来更好的性能。 核心图片: 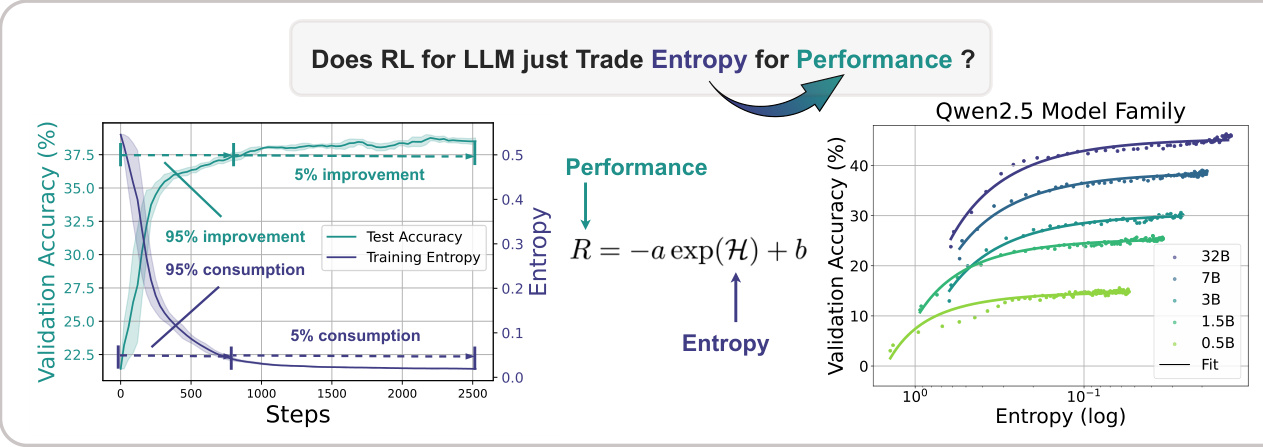
(26) Kuwain 1.5B:通过语言注入实现的阿拉伯语 SLM(121 票)
论文链接: https://huggingface.co/papers/2504.15120
简介: MISRAJA 介绍了 Kuwain 1.5B,它展示了一种新颖的方法,可以在不损害其原始知识的情况下将新语言(阿拉伯语)注入到现有以英语为中心的模型中。这种经济高效的方法为从头开始训练双语模型提供了一个强大的替代方案。 核心图片: 
(27) 超越“啊哈!”:大型推理模型中元能力系统对齐的趋势(119 票)
论文链接: https://huggingface.co/papers/2505.10554
简介: 新加坡国立大学、清华大学和 Salesforce AI Research 认为,推理模型应摆脱对涌现“顿悟时刻”的依赖。他们提出明确将模型与三种元能力——演绎、归纳和溯因——对齐,为推理提供更具可伸缩性和可靠性的基础。 核心图片: 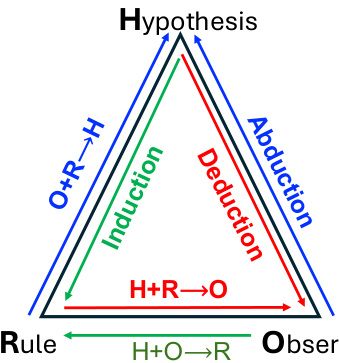
(28) 语言模型的模型链学习(119 票)
论文链接: https://huggingface.co/papers/2505.11820
简介: 微软研究院等机构提出了“模型链”(CoM)这一新颖的学习范式,它在每一层的隐藏状态中引入了因果链式关系。这允许通过激活可变数量的“链”来实现渐进式模型扩展和灵活、弹性的推理。 核心图片: 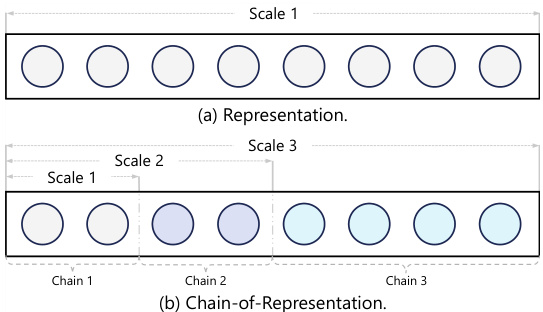
(29) NovelSeek:当代理成为科学家——构建从假设到验证的闭环系统(118 票)
论文链接: https://huggingface.co/papers/2505.16938
简介: 上海人工智能实验室 NovelSeek 团队引入了一个统一的闭环多代理框架,用于进行自主科学研究 (ASR)。NovelSeek 自动化了从假设到验证的整个研究流程,在化学和生物学等领域以人类所需时间的一小部分实现了显著的性能提升。 核心图片: 
(30) TTRL:测试时强化学习(116 票)
论文链接: https://huggingface.co/papers/2504.16084
简介: 清华大学和上海人工智能实验室引入了测试时强化学习 (TTRL),这是一种在无标签数据上训练 LLM 的方法。TTRL 使用多数投票等策略在推理过程中估计奖励,从而实现自我演化和在新的、无标签测试数据上持续改进性能。 核心图片: 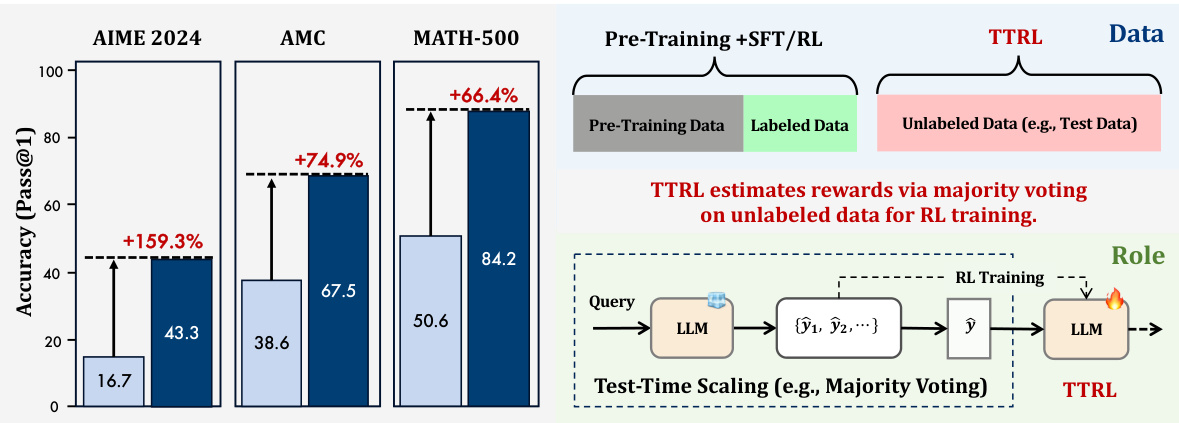
(31) 拖放式 LLM:零样本提示到权重(113 票)
论文链接: https://huggingface.co/papers/2506.16406
简介: 新加坡国立大学、德克萨斯大学奥斯汀分校和牛津大学推出了拖放式 LLM (DnD),这是一种提示条件参数生成器,无需按任务训练。它能在几秒钟内将一些无标签提示直接映射到 LoRA 权重,在未见任务上实现高达 30% 的性能提升,开销降低 12,000 倍。 核心图片: 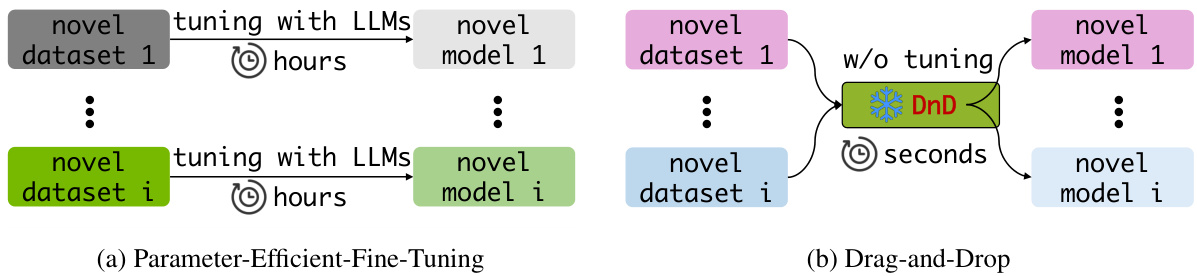
(32) Paper2Code:自动化机器学习科学论文的代码生成(112 票)
论文链接: https://huggingface.co/papers/2504.17192
简介: KAIST 和 DeepAuto.ai 推出了 PaperCoder,这是一个多代理 LLM 框架,可将机器学习论文转换为功能性代码仓库。它以三个阶段(规划、分析和生成)模仿人类开发生命周期,有效解决了机器学习研究中的可复现性危机。 核心图片: 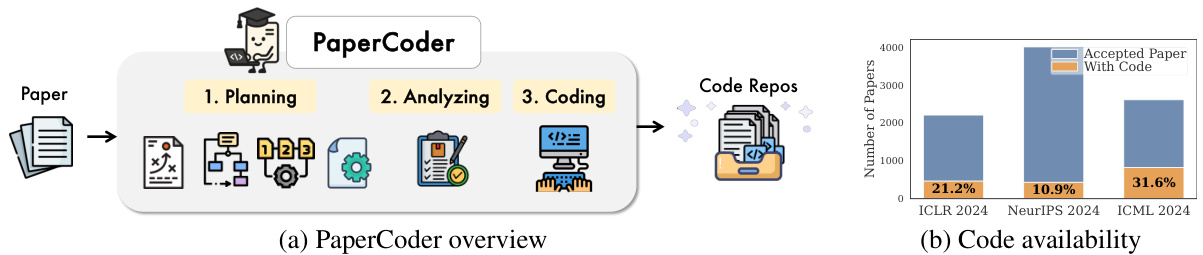
(33) TabSTAR:一个具有语义目标感知表示的基础表格模型(111 票)
论文链接: https://huggingface.co/papers/2505.18125
简介: 以色列理工学院 Technion 介绍了 TabSTAR,一个具有文本特征的表格数据基础模型。它解冻了预训练的文本编码器,并使用目标感知令牌来学习特定于任务的嵌入,在分类基准测试中实现了 SOTA 性能,并优于传统 GBDT。 (论文中没有核心图片)
(34) Hogwild! 推理:通过并发注意力并行 LLM 生成(110 票)
论文链接: https://huggingface.co/papers/2504.06261
简介: Yandex、HSE 大学和奥地利科技学院提出了 Hogwild! 推理,一个并行 LLM 生成引擎。它不采用固定的协作框架,而是并行运行多个 LLM“工作者”,允许它们通过并发更新的注意力缓存同步并开发自己的协作策略。 核心图片: 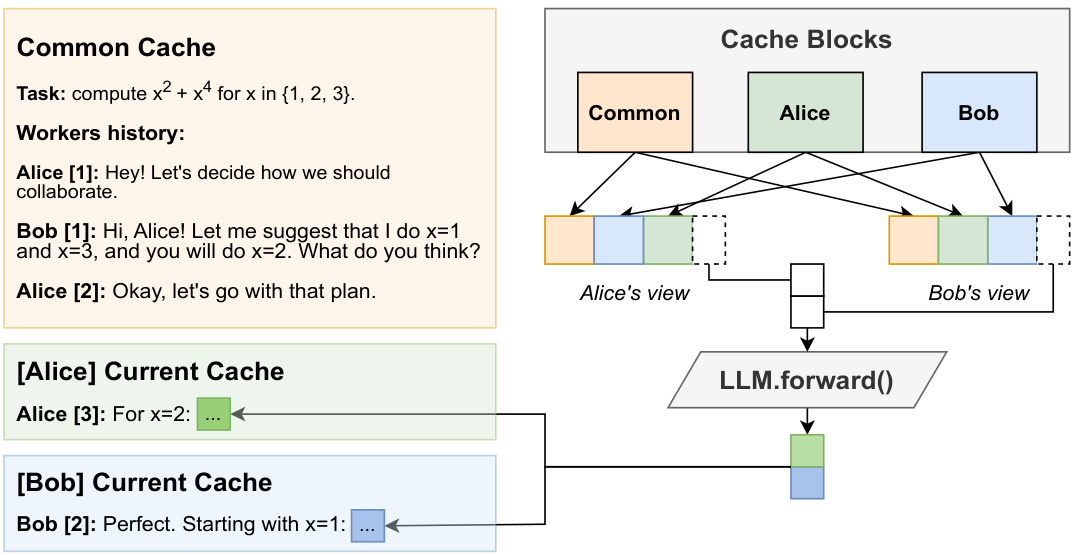
(35) 一分钟视频生成与测试时训练(106 票)
论文链接: https://huggingface.co/papers/2504.05298
简介: NVIDIA、斯坦福大学、加州大学圣地亚哥分校等机构引入了一种利用测试时训练 (TTT) 层生成一分钟视频的方法。这些层使用神经网络作为隐藏状态,使其比标准 RNN 更具表达性,并使预训练的 Transformer 能够生成连贯的长视频。 核心图片: 
(36) SmolVLA:用于经济高效机器人的视觉-语言-动作模型(106 票)
论文链接: https://huggingface.co/papers/2506.01844
简介:Hugging Face、索邦大学等机构推出了SmolVLA,这是一种小巧、高效且由社区驱动的机器人视觉-语言-动作(VLA)模型。它旨在单GPU上进行训练,却能达到比其尺寸大10倍的VLA模型的性能,从而使先进机器人技术更易于普及。核心图片: 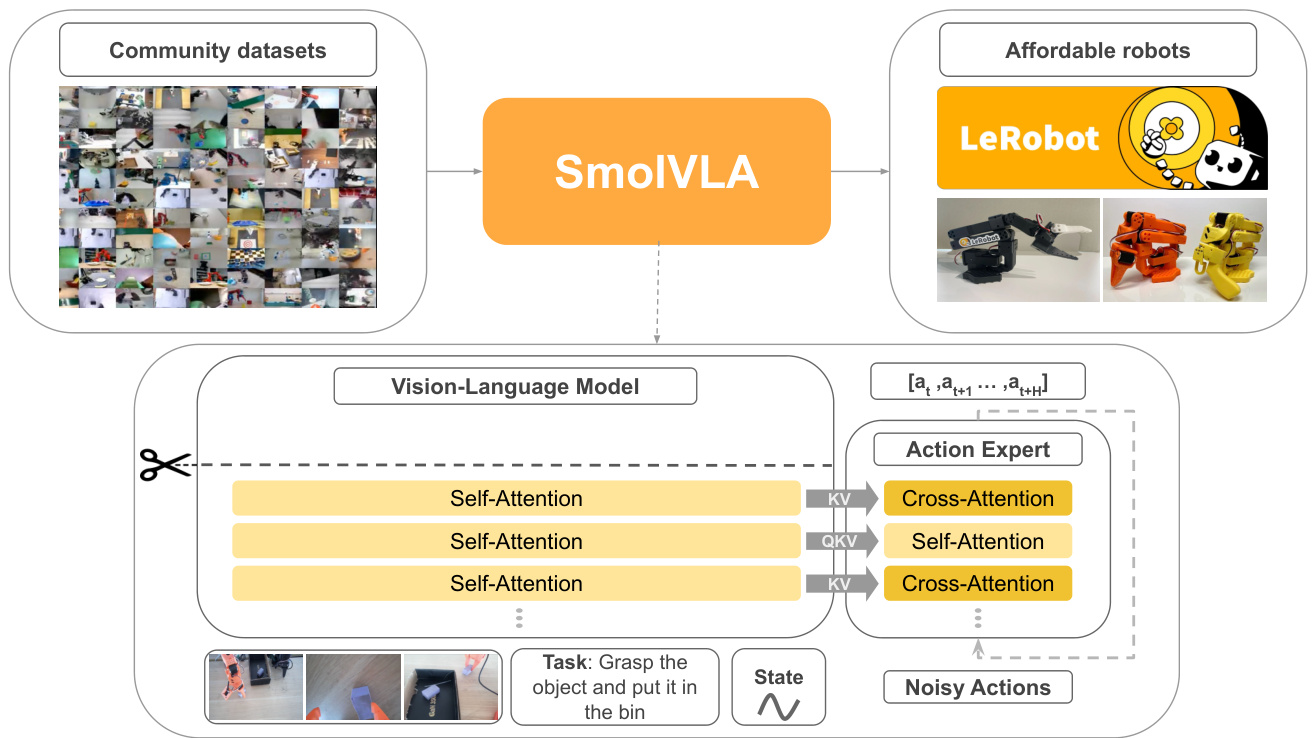
(37) 灵枢:一个用于统一多模态医学理解和推理的通用基础模型(106票)
论文链接: https://huggingface.co/papers/2506.07044
简介:阿里巴巴达摩院LASA团队推出了灵枢,一个用于医学理解和推理的通用基础模型。它在一个精心策划的多模态数据集上进行训练,以解决通用MLLM在医学领域存在的局限性,例如幻觉和缺乏特定知识。核心图片: 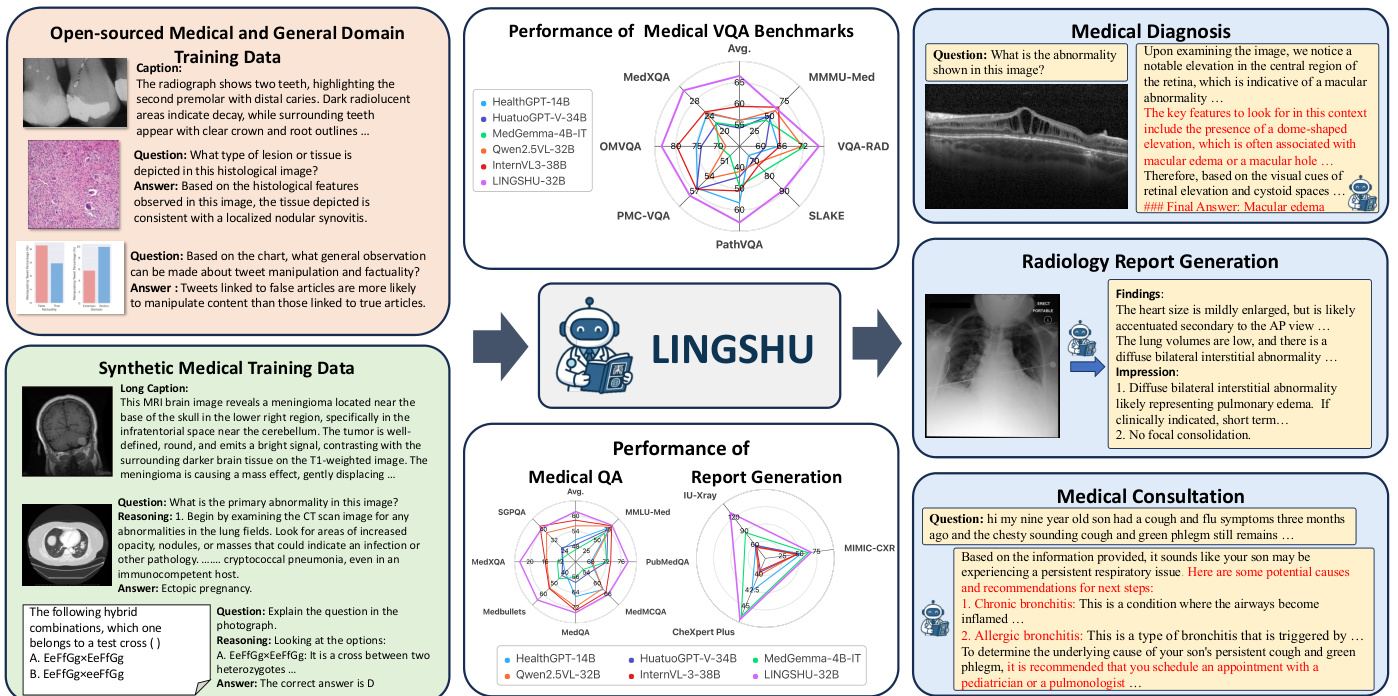
(38) Web-Shepherd:推进PRM以增强网络代理(102票)
论文链接: https://huggingface.co/papers/2505.15277
简介:延世大学和卡内基梅隆大学推出了Web-Shepherd,这是首个专门用于网络导航的进程奖励模型(PRM)。通过在大量步骤级别偏好对数据集上进行训练,Web-Shepherd为网络代理提供比使用MLLM提示更精确、更稳健、更具成本效益的指导。核心图片: 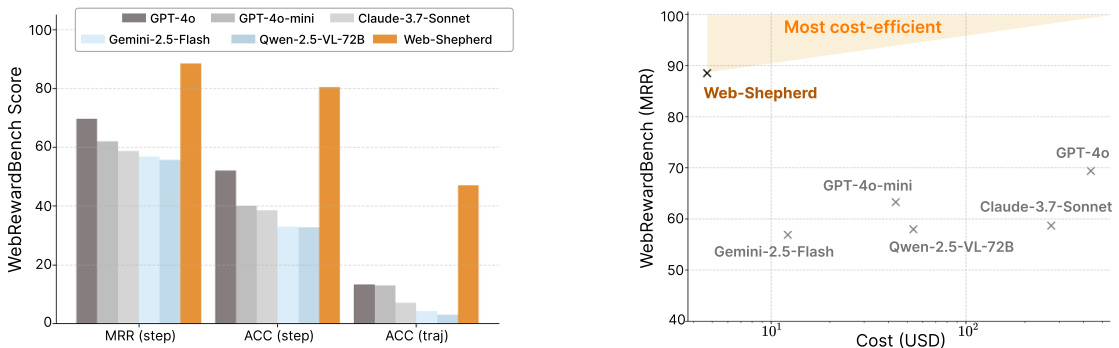
(39) ScienceBoard:在现实科学工作流中评估多模态自主代理(102票)
论文链接: https://huggingface.co/papers/2505.19897
简介:香港大学、上海人工智能实验室等机构推出了ScienceBoard,这是一个用于评估自主代理在科学工作流中表现的基准和环境。它包含一套专业软件和169个真实世界任务,揭示了即使是SOTA(State-of-the-Art,最先进)代理在复杂的科学任务中也面临挑战。核心图片: 
(40) 仅用一个训练示例在大语言模型中进行推理的强化学习(95票)
论文链接: https://huggingface.co/papers/2504.20571
简介:华盛顿大学、南加州大学和微软的这项令人惊讶的研究表明,仅用一个训练示例的RLVR可以非常有效。他们发现一个单独的示例就能将模型在MATH500上的数学推理性能从36.0%提升到73.6%,与使用1.2k示例数据集的结果相匹配。核心图片: 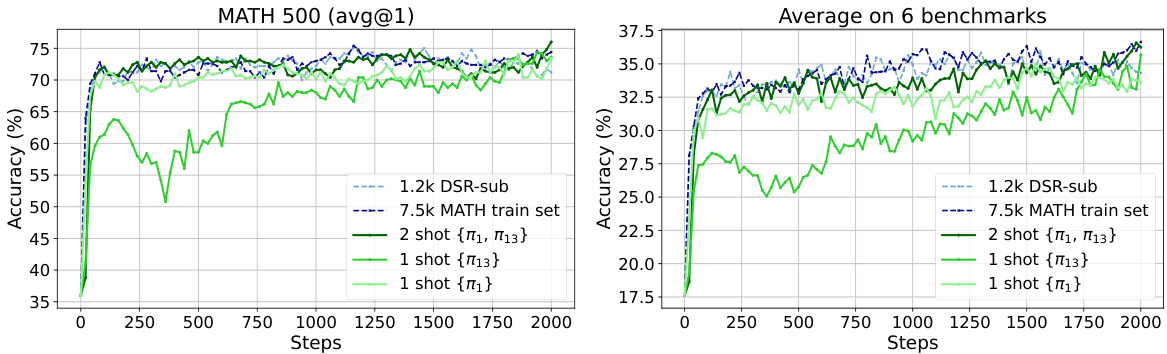
(41) AlphaOne:推理模型在测试时快慢结合(95票)
论文链接: https://huggingface.co/papers/2505.24863
简介:UIUC和加州大学伯克利分校推出了AlphaOne (α1),一个在测试时调节LRM推理速度的通用框架。它引入了“alpha时刻”来扩展思考阶段,动态调度从慢速到快速的思考转换,以提高推理能力和效率。核心图片: 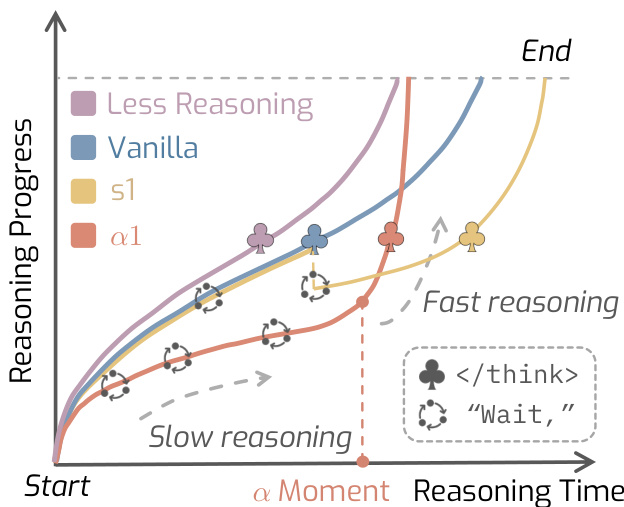
(42) ReasonMed:一个37万多代理生成数据集,用于推进医学推理(95票)
论文链接: https://huggingface.co/papers/2506.09513
简介:阿里巴巴达摩院等机构推出了ReasonMed,这是最大的医学推理数据集,包含37万高质量示例。它通过多代理验证和精炼过程构建而成。他们的模型ReasonMed-7B为10B以下模型树立了新的基准,甚至在PubMedQA上超越了LLaMA3.1-70B。核心图片: 
(43) BLIP3-o:一个完全开放的统一多模态模型家族——架构、训练和数据集(94票)
论文链接: https://huggingface.co/papers/2505.09568
简介:Salesforce Research等机构推出了BLIP3-o,这是一系列最先进的统一多模态模型。他们对图像理解和生成的最优架构进行了全面研究,发现将扩散变换器应用于语义CLIP特征并采用顺序训练策略能获得最佳结果。核心图片: 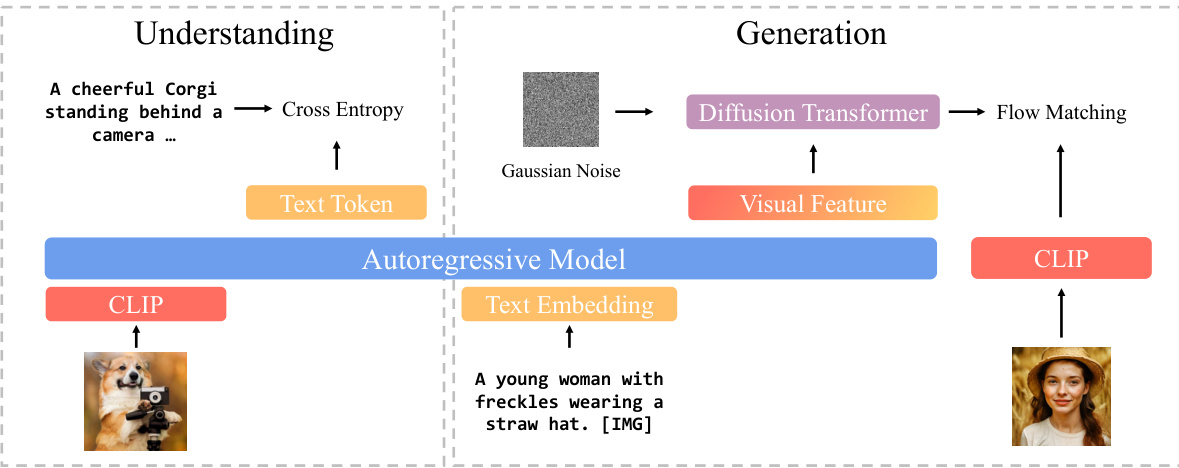
(44) MergeVQ:一个统一的视觉生成和表示框架,具有解耦的token合并和量化功能(93票)
论文链接: https://huggingface.co/papers/2504.00999
简介:浙江大学、清华大学等机构提出了MergeVQ,这是一个将token合并技术融入基于VQ的生成模型的统一框架。它通过在预训练过程中将高级语义与细粒度细节解耦,弥合了生成和表示学习之间的鸿沟。核心图片: 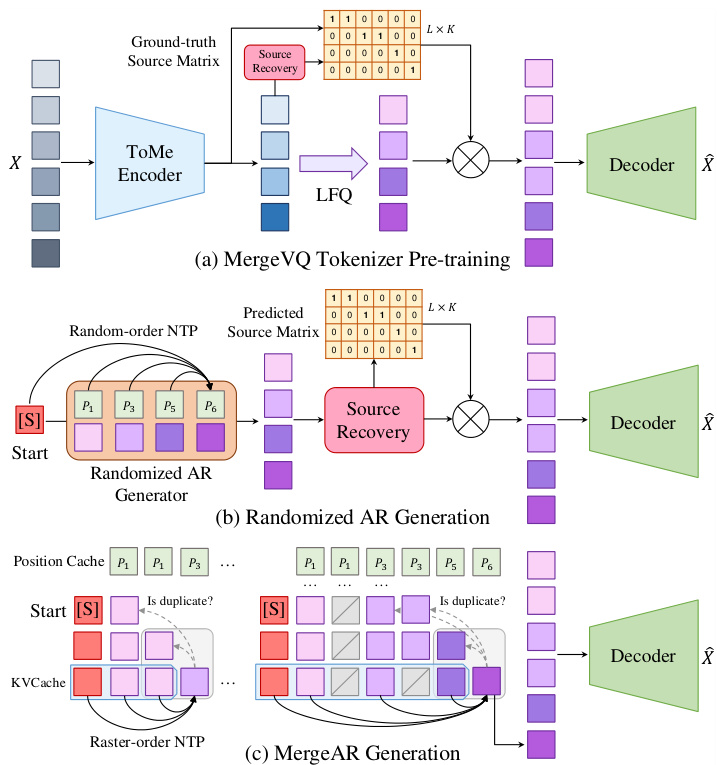
(45) 通过强化微调实现的统一多模态思维链奖励模型(93票)
论文链接: https://huggingface.co/papers/2505.03318
简介:复旦大学、上海人工智能实验室和腾讯混元提出了UnifiedReward-Think,这是首个基于CoT(Chain-of-Thought,思维链)的统一多模态奖励模型。它采用探索驱动的强化学习方法,引导并激励视觉理解和生成奖励任务中的长链推理,从而提高奖励信号的准确性。核心图片: 
(46) CLIMB:基于聚类的迭代数据混合自举用于语言模型预训练(92票)
论文链接: https://huggingface.co/papers/2504.13161
简介:英伟达推出了CLIMB,一个自动化框架,用于发现、评估和精炼预训练数据混合。它嵌入并聚类大规模数据集,然后迭代搜索最优混合。他们训练的1B模型,基于CLIMB优化的混合,超越了SOTA Llama-3.2-1B。核心图片: 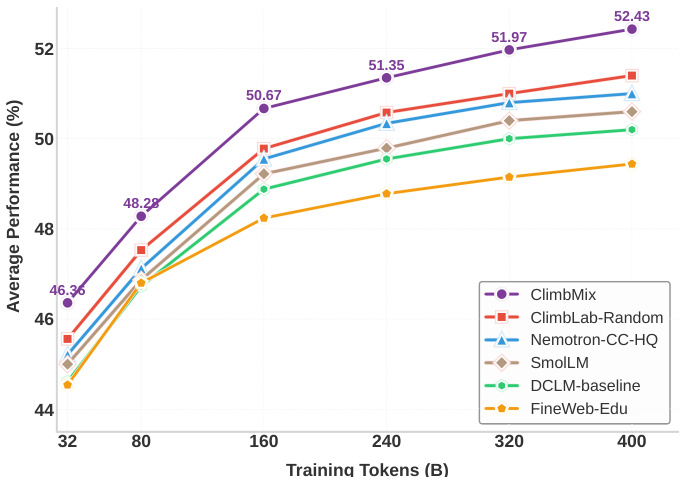
(47) 领域泛化:用于真实世界多跳推理与Transformer的数据增强(91票)
论文链接: https://huggingface.co/papers/2504.20752
简介:这项工作首次将“领域泛化”现象扩展到真实世界的事实数据。通过使用合成数据增强知识图谱,增加推断事实与原子事实的比例,他们使Transformer从记忆过渡到泛化,在多跳问答任务上实现了近乎完美的准确率。核心图片: 
(48) Seedance 1.0:探索视频生成模型的边界(91票)
论文链接: https://huggingface.co/papers/2506.09113
简介:字节跳动Seed团队推出了Seedance 1.0,一个高性能、高效率的视频生成模型。它集成了多源数据整理、支持多镜头生成的有效架构以及视频专用RLHF,以平衡提示遵循、运动合理性和视觉质量。核心图片: 
(49) MultiFinBen:一个多语言、多模态、难度感知的金融LLM评估基准(90票)
论文链接: https://huggingface.co/papers/2506.14028
简介:由众多大学和The FinAI组成的联合体推出了MultiFinBen,这是首个多语言、多模态且难度感知的金融LLM评估基准。它包括多语言金融问答和嵌入OCR的问答等新颖任务,揭示了即使是最强大的模型在复杂的真实世界金融任务中也面临挑战。核心图片: 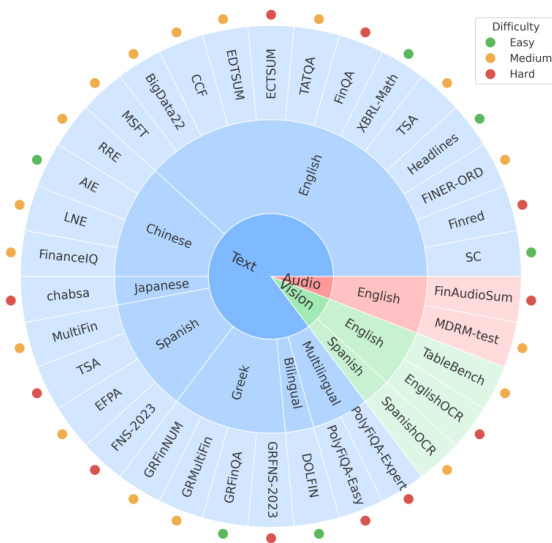
(50) ZClip:LLM预训练中的自适应峰值缓解(89票)
论文链接: https://huggingface.co/papers/2504.02507
简介:BluOrion提出了ZClip,一种自适应梯度裁剪算法,用于缓解LLM预训练期间的损失峰值。与固定阈值不同,ZClip根据梯度范数的z分数异常检测动态调整裁剪阈值,无需人工干预即可主动防止训练发散。核心图片: 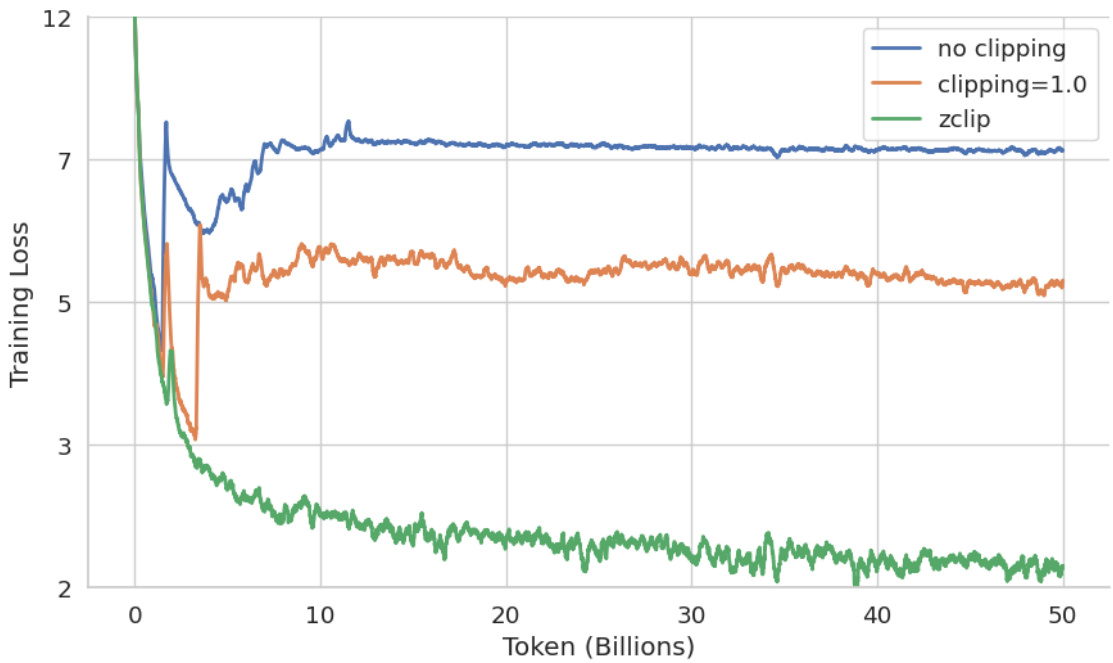
🔥 最终洞察:重塑AI的四大范式转变
在研究了这50项开创性研究之后,人工智能领域正在经历深刻的变革,这一点显而易见。现在的重点不再仅仅是规模,而是智能、效率和设计。以下是定义这个新时代的四个关键洞察:
1. 强化学习大辩论:镀金与炼金 强化学习(RL)曾是本季度的当之无愧的明星,但其作用现在正受到严格的重新审视。一方面,ProRL和One-Shot RLVR等研究展示了其解锁潜在推理能力的巨大力量。另一方面,像“强化学习真的能激励……”这样的论文提出了一个关键问题:强化学习是在创造根本性的新能力(炼金),还是仅仅让模型更有效地采样它们已知的信息(镀金)?答案似乎在于更深入地理解其机制,关注关键决策点(高熵少数Token)和管理策略熵(熵机制)。
- 趋势:研究正从“强化学习是否有效”转向“强化学习如何以及为何有效”。未来在于创建更可解释、可控和高效的强化学习范式。
2. 大迁徙:从以模型为中心到以数据和计算为中心的效率 模型参数“暴力扩展”的时代正在让位于对数据和计算层面效率的新关注。
- 转变:正如“转移AI效率……”中所强调的,主要的瓶颈不再是模型大小,而是处理大量token序列的成本。这使得“token压缩”(MergeVQ)和高效的推理时计算(MiniMax-M1,Hogwild! Inference)成为新的前沿。同时,像SmolVLM这样“小而强大”的模型以及像PRIMA.CPP这样的低资源部署框架证明,无需大量硬件也能实现顶尖性能。
- 趋势:人工智能的“摩尔定律”现在将以效率提升来衡量。未来的突破将来自更智能的数据处理、新颖的注意力机制以及能够在任何地方运行的强大模型。
3. 通用智能体黎明:超越“顿悟”时刻 智能体正从小众概念转向系统级基础能力。
- 统一:统一架构正成为标准,正如基础智能体和BAGEL、Qwen3等模型的调查所示。智能体被设计用于解决真实世界的工作流,从自主科学发现(NovelSeek,ScienceBoard)到日常任务(Web-Shepherd,SmolVLA)。
- 对齐:至关重要的是,该领域正超越依赖突发的“顿悟时刻”。相反,正如“超越‘顿悟!’”所建议的,重点在于系统地将智能体与演绎和归纳等核心“元能力”对齐,为推理建立更可靠和可控的基础。
- 趋势:下一代人工智能将以其“行动”能力来定义。挑战在于将感知、语言和规划整合到一个无缝、目标驱动的系统中,使其既有能力又值得信赖。
4. 数据即新算法:策展智能的崛起 数据不再是被动的燃料;它是塑造模型智能的活跃、可编程组件。
- 策展:高质量、领域特定的数据集现在被认为是成功的先决条件。无论是医学领域的ReasonMed还是网络导航的Web-Shepherd,策展数据是解锁突破性性能的关键。
- 自动化:像CLIMB这样的框架正在将数据混合从一门艺术转变为一门科学,利用人工智能自动发现最佳预训练“配方”。
- 归纳:最深刻的是,“领域泛化”表明数据增强可以作为一种工具,在模型中“诱导”可泛化推理电路,迫使其学习底层逻辑而不是仅仅记忆事实。
- 趋势:数据工程正变得与模型架构同等重要。竞争优势将属于那些能够构建更优越的数据生成、过滤、混合和增强管道的人,从而为人工智能创造强大的自我改进循环。
这不仅仅是一次技术迭代;它更是思维方式的演变。它要求我们作为实践者和研究人员,不仅将自己视为模型的训练者,更要视为其认知过程的设计师和其能力构建的架构师。人工智能的下一个“顿悟时刻”可能不会来自更大的模型,而是来自对这些趋势更智能的洞察。让我们继续探索。