深度探究:Hugging Face Optimum Graphcore 上的 Vision Transformer

这篇博客文章将展示如何在 Graphcore 智能处理单元 (IPU) 上使用 Hugging Face Optimum 库轻松地为您的数据集微调预训练的 Transformer 模型。作为一个示例,我们将提供一个分步指南和一份笔记本,其中包含一个大型、广泛使用的胸部 X 射线数据集,并训练一个 Vision Transformer (ViT) 模型。
介绍 Vision Transformer (ViT) 模型
2017 年,一组 Google AI 研究人员发表了一篇论文,介绍了 Transformer 模型架构。Transformer 以其新颖的自注意力机制为特征,被提出作为一种用于语言应用的新型高效模型组。事实上,在过去的五年中,Transformer 模型的受欢迎程度呈爆炸式增长,现在已被公认为自然语言处理 (NLP) 的事实标准。
用于语言的 Transformer 模型最显著的代表可能是快速发展的 GPT 和 BERT 模型系列。两者都可以在 Graphcore IPU 上轻松高效地运行,作为不断增长的 Hugging Face Optimum Graphcore 库的一部分。
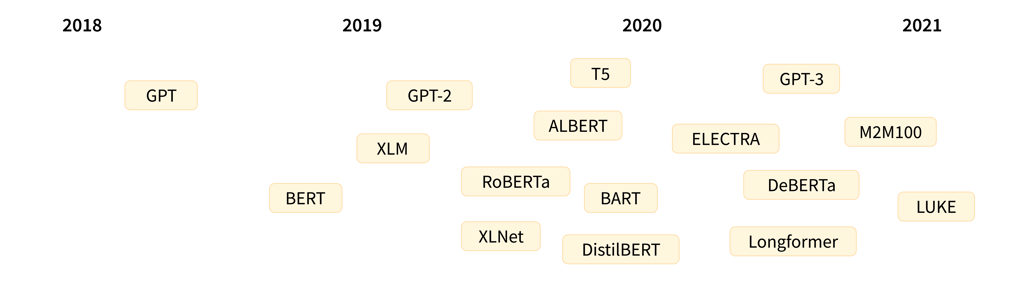
显示突出 Transformer 语言模型发布时间表(图片来源:Hugging Face)
关于 Transformer 模型架构的深入解释(重点关注 NLP)可在 Hugging Face 网站上找到。
虽然 Transformer 模型最初在语言领域取得了成功,但它们用途极其广泛,可用于一系列其他目的,包括计算机视觉 (CV),这正是我们将在本博客文章中介绍的内容。
计算机视觉是一个卷积神经网络 (CNN) 无疑是最流行架构的领域。然而,Vision Transformer (ViT) 架构,最初由 Google Research 在 2021 年的一篇论文中提出,代表了图像识别领域的突破,并使用与 BERT 和 GPT 相同的自注意力机制作为其主要组成部分。
BERT 和其他基于 Transformer 的语言处理模型将句子(即单词列表)作为输入,而 ViT 模型将输入图像分割成几个小块,相当于语言处理中的单个单词。Transformer 模型将每个小块线性编码为可单独处理的向量表示。这种将图像分割成小块或视觉标记的方法与 CNN 使用的像素数组形成对比。
通过预训练,ViT 模型学习图像的内部表示,然后可用于提取对下游任务有用的视觉特征。例如,您可以通过在预训练的视觉编码器顶部放置一个线性层来在新标签图像数据集上训练分类器。通常将线性层放置在 [CLS] 标记的顶部,因为此标记的最后一个隐藏状态可被视为整个图像的表示。
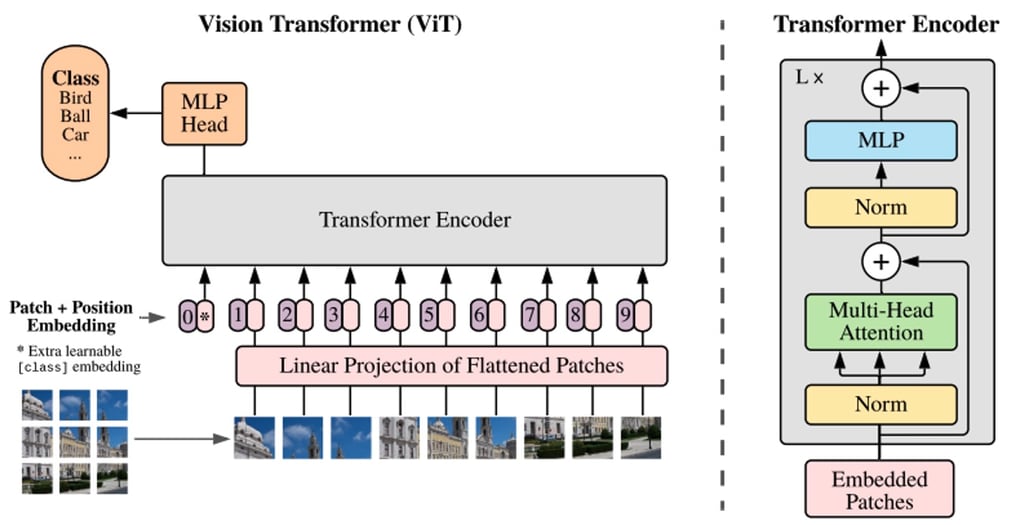
ViT 模型结构的概述,如 Google Research 2021 年原始论文中所述
与 CNN 相比,ViT 模型以更低的计算成本显示出更高的识别精度,并应用于图像分类、目标检测和分割等一系列应用。仅在医疗保健领域,用例就包括 COVID-19、股骨骨折、肺气肿、乳腺癌 和 阿尔茨海默病 的检测和分类等等。
ViT 模型 – IPU 的完美选择
Graphcore IPU 特别适合 ViT 模型,因为它们能够结合数据流水线和模型并行化来并行化训练。通过 IPU 的 MIMD 架构及其以 IPU-Fabric 为中心的横向扩展解决方案,加速这一大规模并行过程成为可能。
通过引入流水线并行化,可以增加每个数据并行实例可处理的批次大小,提高一个 IPU 处理的内存区域的访问效率,并减少数据并行学习的参数聚合通信时间。
由于开源 Hugging Face Optimum Graphcore 库中添加了一系列预优化 Transformer 模型,因此在 IPU 上运行和微调 ViT 等模型时,实现高程度的性能和效率变得异常容易。
通过 Hugging Face Optimum,Graphcore 发布了即用型 IPU 训练的模型检查点和配置文件,以便轻松高效地训练模型。这特别有用,因为 ViT 模型通常需要大量数据进行预训练。这种集成允许您在 Hugging Face 模型中心使用原始作者发布的检查点,因此您无需自己训练它们。通过让用户即插即用任何公共数据集,Optimum 缩短了 AI 模型的整体开发周期,并允许与 Graphcore 最先进的硬件无缝集成,从而加快了价值实现时间。
对于这篇博客文章,我们将使用基于 Dosovitskiy 等人论文 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale 在 ImageNet-21k 上预训练的 ViT 模型。作为一个示例,我们将向您展示在 ChestX-ray14 数据集上使用 Optimum 微调 ViT 的过程。
ViT 模型对 X 射线分类的价值
与所有医学成像任务一样,放射科医生需要多年时间才能可靠、高效地检测问题并根据 X 射线图像做出初步诊断。在很大程度上,这种困难源于图像的微小差异和空间限制,这就是为什么计算机辅助检测和诊断 (CAD) 技术在改善临床医生工作流程和患者预后方面显示出巨大的潜力。
同时,开发任何用于 X 射线分类的模型(无论是 ViT 还是其他)都将面临其应有的挑战:
- 从头开始训练模型需要大量带标签的数据;
- 高分辨率和高容量要求意味着需要强大的计算能力来训练此类模型;以及
- 由于疾病类别的数量,肺部诊断等多类别和多标签问题的复杂性呈指数级增长。
如上所述,为了我们使用 Hugging Face Optimum 的演示目的,我们不需要从头开始训练 ViT。相反,我们将使用托管在 Hugging Face 模型中心的模型权重。
由于一张 X 射线图像可能包含多种疾病,我们将使用一个多标签分类模型。该模型使用 google/vit-base-patch16-224-in21k 检查点。它已从 TIMM 仓库转换而来,并在 ImageNet-21k 的 1400 万张图像上进行了预训练。为了并行化并优化 IPU 的任务,该配置已通过 Graphcore-ViT 模型卡提供。
如果您是第一次使用 IPU,请阅读 IPU 程序员指南以了解基本概念。要在 IPU 上运行您自己的 PyTorch 模型,请参阅 Pytorch 基础教程,并通过我们的 Hugging Face Optimum Notebooks 了解如何使用 Optimum。
在 ChestXRay-14 数据集上训练 ViT
首先,我们需要下载美国国立卫生研究院 (NIH) 临床中心 的 胸部 X 射线数据集。该数据集包含 1992 年至 2015 年期间 30,805 名患者的 112,120 张去识别化的正面 X 射线图像。该数据集涵盖了基于使用 NLP 技术从放射报告文本中挖掘的标签的 14 种常见疾病。
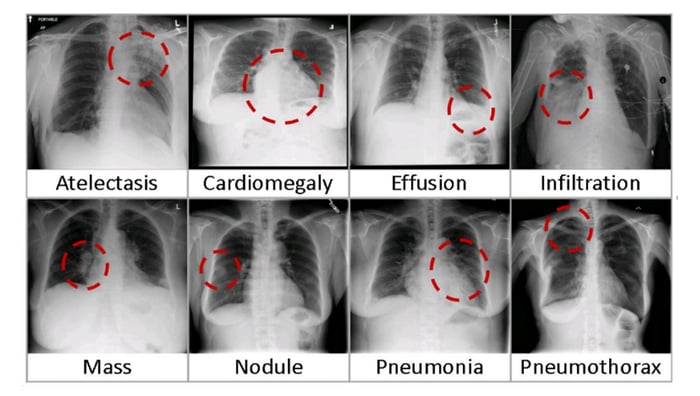
八个常见胸部疾病的视觉示例(图片来源:NIC)
设置环境
以下是运行本演练的要求:
- 一个启用最新 Poplar SDK 和 PopTorch 环境的 Jupyter Notebook 服务器(请参阅我们关于 如何在 Jupyter notebooks 中使用 IPU 的指南)
- 来自 Graphcore Tutorials 仓库的 ViT 训练笔记本
Graphcore Tutorials 仓库包含本指南中讨论的分步教程笔记本和 Python 脚本。克隆仓库并启动在 `tutorials/tutorials/pytorch/vit_model_training/` 中找到的 walkthrough.ipynb 笔记本。
我们甚至通过创建 HF Optimum Gradient 使其变得更容易,这样您就可以在 Free IPU 中启动入门教程。注册并启动运行时![]()
获取数据集
下载数据集的 `/images` 目录。您可以使用 `bash` 提取文件:`for f in images*.tar.gz; do tar xfz "$f"; done`。
接下来,下载 `Data_Entry_2017_v2020.csv` 文件,其中包含标签。默认情况下,教程期望 `/images` 文件夹和 .csv 文件与正在运行的脚本位于同一文件夹中。
一旦您的 Jupyter 环境拥有数据集,您需要安装并导入最新的 Hugging Face Optimum Graphcore 包和 `requirements.txt` 中的其他依赖项。
%pip install -r requirements.txt
胸部 X 射线数据集中包含的检查包括 X 射线图像(灰度,224x224 像素)和相应的元数据:`Finding Labels, Follow-up #, Patient ID, Patient Age, Patient Gender, View Position, OriginalImage[Width Height] 和 OriginalImagePixelSpacing[x y]`。
接下来,我们定义已下载图像的位置以及要在获取数据集中下载的标签文件。
我们将训练 Graphcore Optimum ViT 模型来根据图像预测疾病(由“Finding Label”定义)。“Finding Label”可以是 14 种疾病中的任意一种,也可以是“No Finding”标签,表示未检测到疾病。为了与 Hugging Face 库兼容,文本标签需要转换为 N-hot 编码数组,表示分类每张图像所需的多个标签。N-hot 编码数组将标签表示为布尔值列表,如果标签与图像对应则为 true,否则为 false。
首先,我们确定数据集中的唯一标签。
现在我们将标签转换为 N-hot 编码数组
使用 `datasets.load_dataset` 函数加载数据时,可以通过为每个标签创建文件夹(请参阅“ImageFolder”文档)或使用 `metadata.jsonl` 文件(请参阅“ImageFolder with metadata”文档)来提供标签。由于此数据集中的图像可以有多个标签,我们选择使用 `metadata.jsonl` 文件。我们将图像文件名及其相关标签写入 `metadata.jsonl` 文件。
创建数据集
我们现在准备创建 PyTorch 数据集并将其分割为训练集和验证集。此步骤将数据集转换为 Arrow 文件格式,该格式允许在训练和验证期间快速加载数据(关于 Arrow 和 Hugging Face)。由于整个数据集正在加载和预处理,因此可能需要几分钟。
我们将从检查点 `google/vit-base-patch16-224-in21k` 导入 ViT 模型。该检查点是 Hugging Face 托管的标准模型,不受 Graphcore 管理。
为了微调预训练模型,新数据集必须与用于预训练的原始数据集具有相同的属性。在 Hugging Face 中,原始数据集信息在通过 `AutoImageProcessor` 加载的配置文件中提供。对于此模型,X 射线图像被调整为正确的分辨率 (224x224),从灰度转换为 RGB,并使用平均值 (0.5, 0.5, 0.5) 和标准差 (0.5, 0.5, 0.5) 在 RGB 通道上进行归一化。
为了使模型高效运行,图像需要进行批量处理。为此,我们定义了 `vit_data_collator` 函数,该函数按照 Transformers Data Collator 中的 `default_data_collator` 模式,以字典形式返回图像和标签的批量。
可视化数据集
为了检查数据集,我们显示了前 10 行元数据。
我们还绘制了一些来自验证集的图像及其关联标签。
这些图像是胸部 X 射线,标签是患者被诊断出的肺部疾病。这里,我们展示了转换后的图像。
我们的数据集现在可以使用了。
准备模型
要在 IPU 上训练模型,我们需要从 Hugging Face Hub 导入它,并使用 IPUTrainer 类定义一个训练器。IPUTrainer 类接受与原始 Transformer Trainer 相同的参数,并与 IPUConfig 对象协同工作,该对象指定了在 IPU 上编译和执行的行为。
现在我们从 Hugging Face 导入 ViT 模型。
要在 IPU 上使用此模型,我们需要加载 IPU 配置 `IPUConfig`,它控制 Graphcore IPU 特定的所有参数(现有的 IPU 配置可在此处找到)。我们将使用 `Graphcore/vit-base-ipu`。
让我们使用 `IPUTrainingArguments` 设置我们的训练超参数。这继承了 Hugging Face `TrainingArguments` 类,并添加了 IPU 及其执行特性特有的参数。
实现用于评估的自定义性能指标
多标签分类模型的性能可以使用 ROC(受试者工作特征)曲线下面积(AUC_ROC)进行评估。AUC_ROC 是不同类别在不同阈值下的真阳性率 (TPR) 与假阳性率 (FPR) 的曲线图。这是多标签分类任务中常用的性能指标,因为它对类别不平衡不敏感且易于解释。
对于此数据集,AUC_ROC 代表模型区分不同疾病的能力。0.5 的分数意味着正确诊断疾病的可能性为 50%,而 1 的分数意味着它可以完美区分疾病。此指标在 Datasets 中不可用,因此我们需要自己实现它。HuggingFace Datasets 包允许通过 `load_metric()` 函数进行自定义指标计算。我们定义一个 `compute_metrics` 函数,并将其暴露给 Transformer 的评估函数,就像通过 datasets 包支持的其他指标一样。`compute_metrics` 函数接受 ViT 模型预测的标签,并计算 ROC 曲线下面积。`compute_metrics` 函数接受一个 `EvalPrediction` 对象(一个带有 `predictions` 和 `label_ids` 字段的命名元组),并且必须返回一个字符串到浮点数的字典。
为了训练模型,我们使用 `IPUTrainer` 类定义了一个训练器,该类负责将模型编译到 IPU 上运行,并执行训练和评估。`IPUTrainer` 类的工作方式与 Hugging Face Trainer 类相同,但接受额外的 `ipu_config` 参数。
运行训练
为了加速训练,如果存在,我们将加载最后一个检查点。
现在我们准备开始训练了。
绘制收敛图
现在我们已经完成了训练,我们可以格式化并绘制训练器输出以评估训练行为。
我们绘制训练损失和学习率。
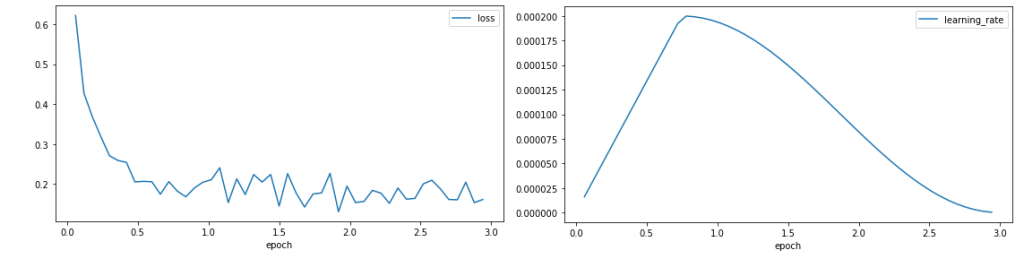 损失曲线显示,训练开始时损失迅速下降,然后稳定在 0.1 左右,表明模型正在学习。学习率在训练期的 25% 预热阶段增加,然后遵循余弦衰减。
损失曲线显示,训练开始时损失迅速下降,然后稳定在 0.1 左右,表明模型正在学习。学习率在训练期的 25% 预热阶段增加,然后遵循余弦衰减。
运行评估
现在我们已经训练了模型,我们可以使用验证数据集评估其预测未见数据标签的能力。
这些指标显示了教程在 3 个 epoch 后达到的验证 AUC_ROC 分数。
有几个方向可以探索以提高模型的准确性,包括更长的训练。验证性能也可以通过更改优化器、学习率、学习率调度、损失缩放或使用自动损失缩放来提高。
免费试用 IPU 上的 Hugging Face Optimum
在这篇文章中,我们介绍了 ViT 模型,并提供了使用本地数据集在 IPU 上训练 Hugging Face Optimum 模型的教程。
得益于 Graphcore 与 Paperspace 的新合作关系,上述整个过程现在可以在几分钟内免费端到端运行。该服务于今日启动,将通过 Paperspace 基于网络的 Jupyter Notebooks——Gradient,提供对由 Graphcore IPU 提供支持的部分 Hugging Face Optimum 模型(包括 ViT、BERT、RoBERTa 等)的访问。
![]()
如果您有兴趣在 Paperspace Gradient 上免费试用包含 ViT、BERT、RoBERTa 等模型的 Hugging Face Optimum with IPU,您可以在此处注册,并在此处找到入门指南。
IPU 上 Hugging Face Optimum 的更多资源
如果没有 Graphcore 的 Eva Woodbridge、James Briggs、Jinchen Ge、Alexandre Payot、Thorin Farnsworth 和所有其他贡献者,以及 Hugging Face 的 Jeff Boudier、Julien Simon 和 Michael Benayoun 的大力支持、指导和见解,本次深度探究将无法实现。

