VideoMamba:用于高效视频理解的状态空间模型


本文提出了VideoMamba,一种基于状态空间模型(SSM)的高效视频理解方法。它旨在解决视频数据中局部冗余和全局依赖的挑战,利用Mamba算子的线性复杂度进行长期建模。
方法概述
VideoMamba将最初为2D图像处理设计的双向Mamba块扩展到处理3D视频序列。它遵循传统Vision Transformer (ViT) 的架构,带有一个3D补丁嵌入层,将输入视频分成不重叠的时空补丁。这些补丁随后被展平并映射为一系列标记,由堆叠的双向Mamba块处理。
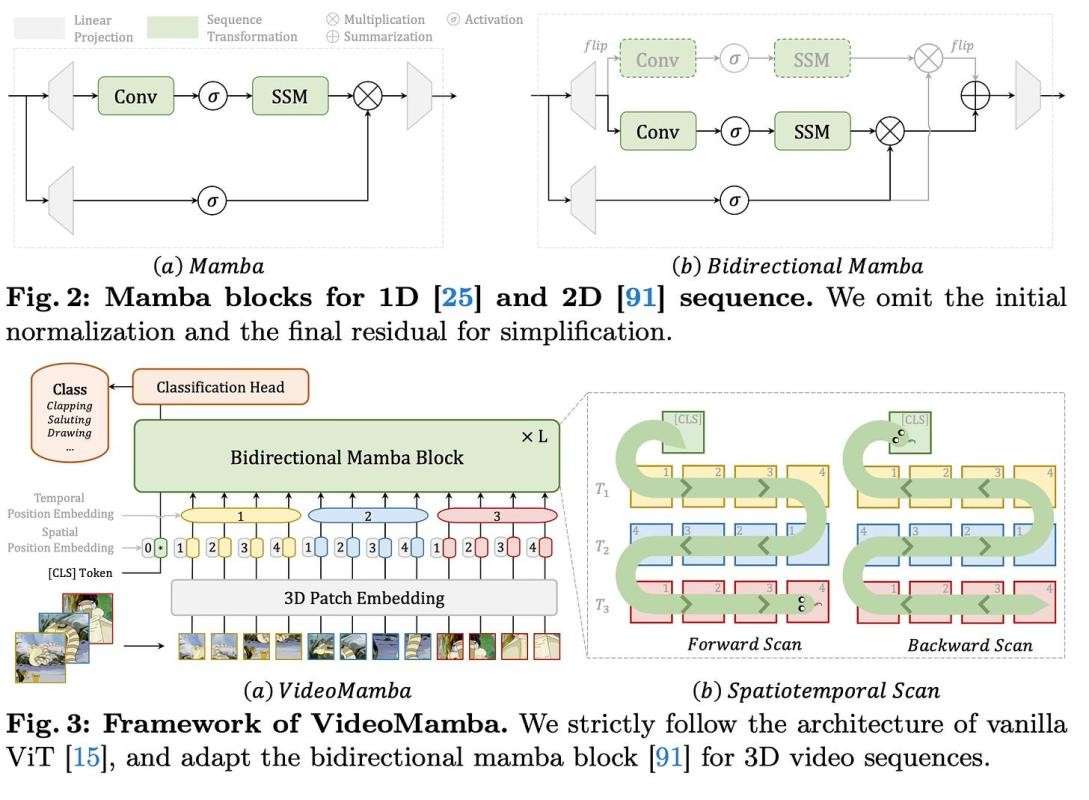
作者探索了双向Mamba块的不同时空扫描顺序,包括空间优先、时间优先和混合扫描。通过实验,他们发现空间优先的双向扫描最为有效,因为它可以通过逐帧扫描无缝利用2D预训练知识。
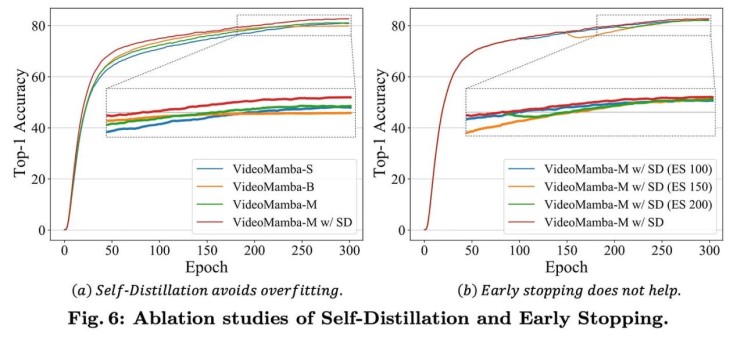
为了增强大型VideoMamba模型的可扩展性,作者引入了一种自蒸馏技术。一个较小、训练有素的模型作为“教师”模型,通过对齐其最终特征图来指导较大“学生”模型的训练,从而缓解在大型Mamba架构中观察到的过拟合问题。
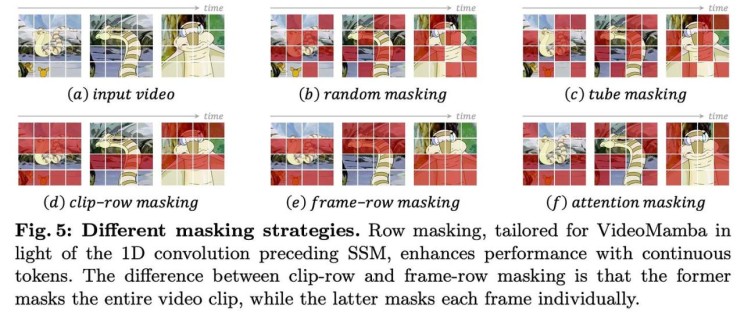
此外,VideoMamba还采用了掩码建模技术来提高其时间敏感性和多模态兼容性。作者提出了针对双向Mamba块中1D卷积的行掩码策略,探索了随机、管状、剪辑行、帧行和基于注意力的掩码。他们还研究了由于架构差异只对齐学生和教师模型最终输出的方法。
结果
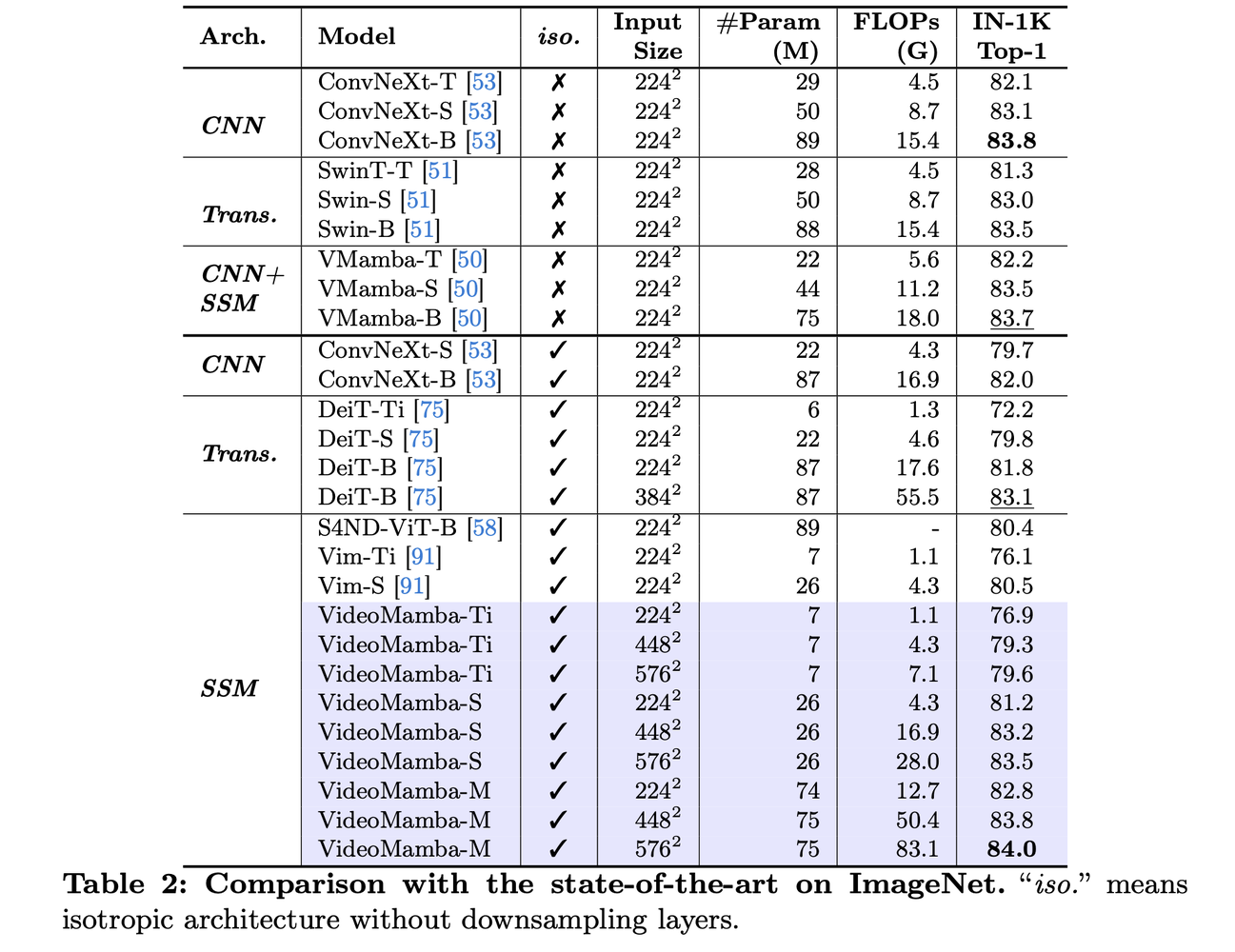
- 可扩展性:VideoMamba在ImageNet-1K上优于其他同构架构,仅用74M参数就实现了84.0%的top-1准确率。
- 短期动作识别:在Kinetics-400和Something-Something V2数据集上,VideoMamba超越了ViViT和TimeSformer等基于注意力的模型,同时降低了计算需求。
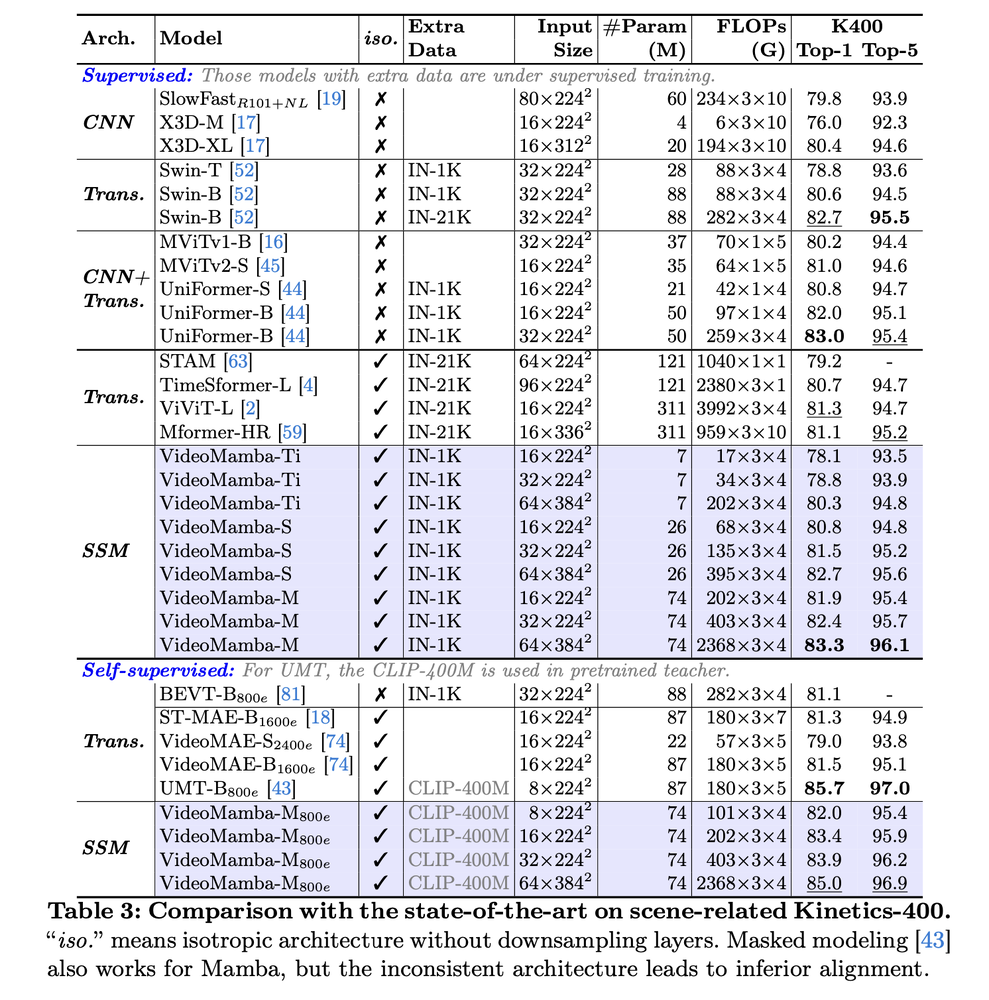
长期视频理解:VideoMamba在Breakfast、COIN和LVU基准测试上,相对于传统基于特征的方法表现出显著优势,并取得了新的最先进结果。
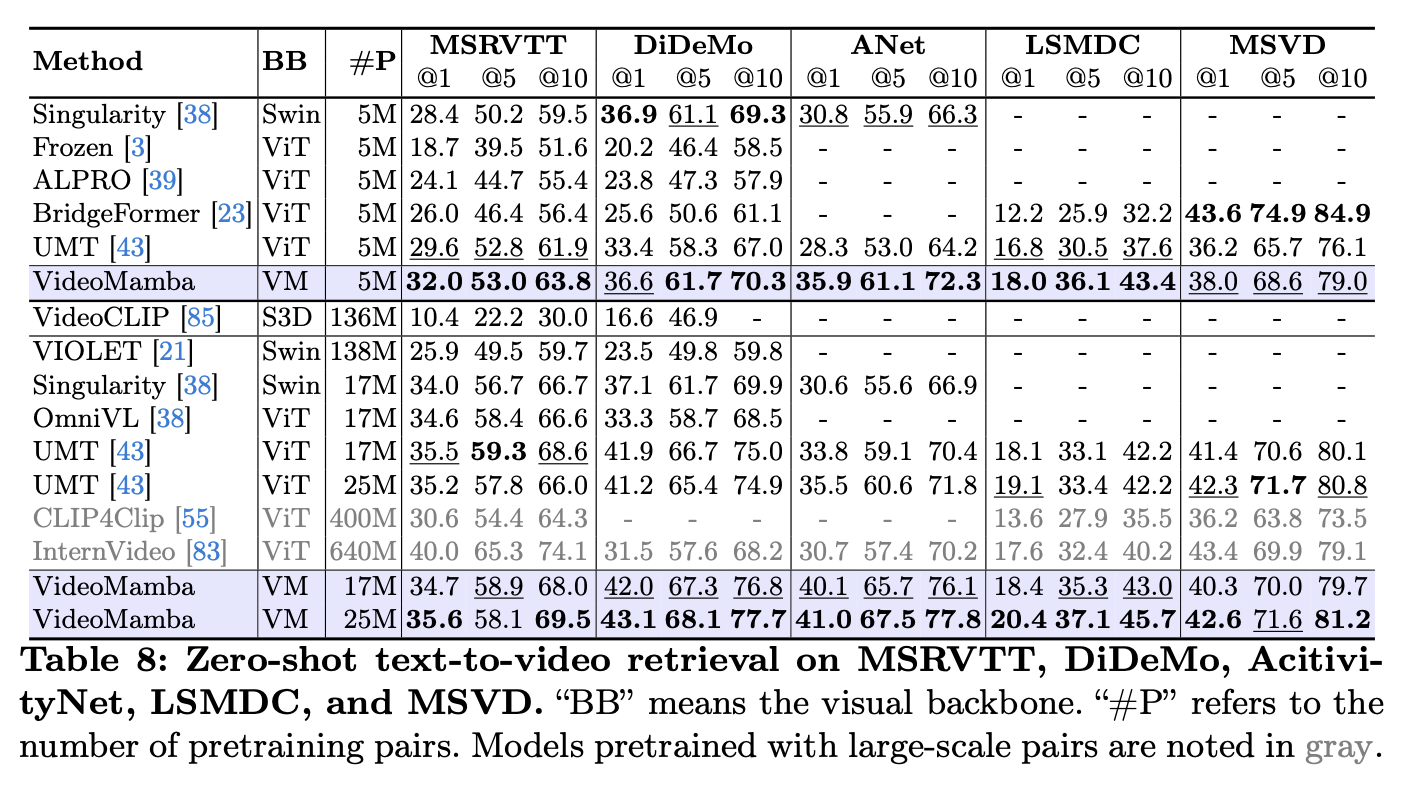
多模态:VideoMamba在零样本视频-文本检索任务中取得了改进的性能,展示了其在多模态上下文中的鲁棒性。
结论
VideoMamba 适应了Mamba架构,实现了高效的长期视频建模,在各种视频理解任务中超越了现有方法。更多详细信息请参阅完整论文或代码。
祝贺作者们的工作!
模型:https://huggingface.co/OpenGVLab/VideoMamba
Li, Kunchang, et al. "VideoMamba: State Space Model for Efficient Video Understanding." arXiv preprint arXiv:2403.06977, 2023.