关于长上下文微调的一切








长文本,大模型
大多数大型语言模型都在长达 8K 的上下文上进行预训练。最近,越来越多的模型开始支持超过 32K 的上下文。这些长文本大模型为文档理解、代码补全及其他场景带来了新的可能性。
- 阅读理解:GPT-4 论文的正文大约有 80,000 个 token 长。总结、提取或分析这样的论文通常需要复杂的检索增强生成(RAG)方法。如果能直接将所有 80,000 个 token 输入模型,就可以避免截断和提取原文。与各种复杂的 RAG 方法相比,这要愉快得多。
- 代码补全也是一个需要交叉引用不同相距很远位置的任务。如果模型能够接受整个代码仓库,它可以更好地利用仓库中的函数定义等内容,从而带来显著优势。
如今,开源社区已经有不少支持上下文长度超过 32K 的模型。然而,其中许多模型只是在长上下文下能够输出合理文本,但并未针对长上下文任务进行特别优化。另一方面,开箱即用的开源模型的输出风格和能力可能无法完全满足我们的需求。
在上述两种情况下,我们自己对开源模型进行一些长文本微调就变得有意义。然而,长文本微调不像常规微调那样直接。随着文本变长,我们首先需要解决由此带来的一系列问题。
本博客的内容大致如下:
长文本建模的挑战:内存使用、批次对齐和注意力空间复杂度;
如何解决长文本微调的问题;
长文本微调的简单示例——Faro 系列模型。
免责声明⚠️:今天,我们主要关注微调的方法,不包括如何尽可能提高长文本性能或更大规模的预训练,尽管这些主题也很重要。而且,作为中国人,我在选择基础模型和数据集时会考虑中文。您可能需要根据自己的使用场景进行修改。
长文本带来了哪些问题?
随着上下文长度的增加,训练效率成为我们面临的最严峻挑战。我将这一挑战总结为在处理长输入时微调机制所带来的问题:
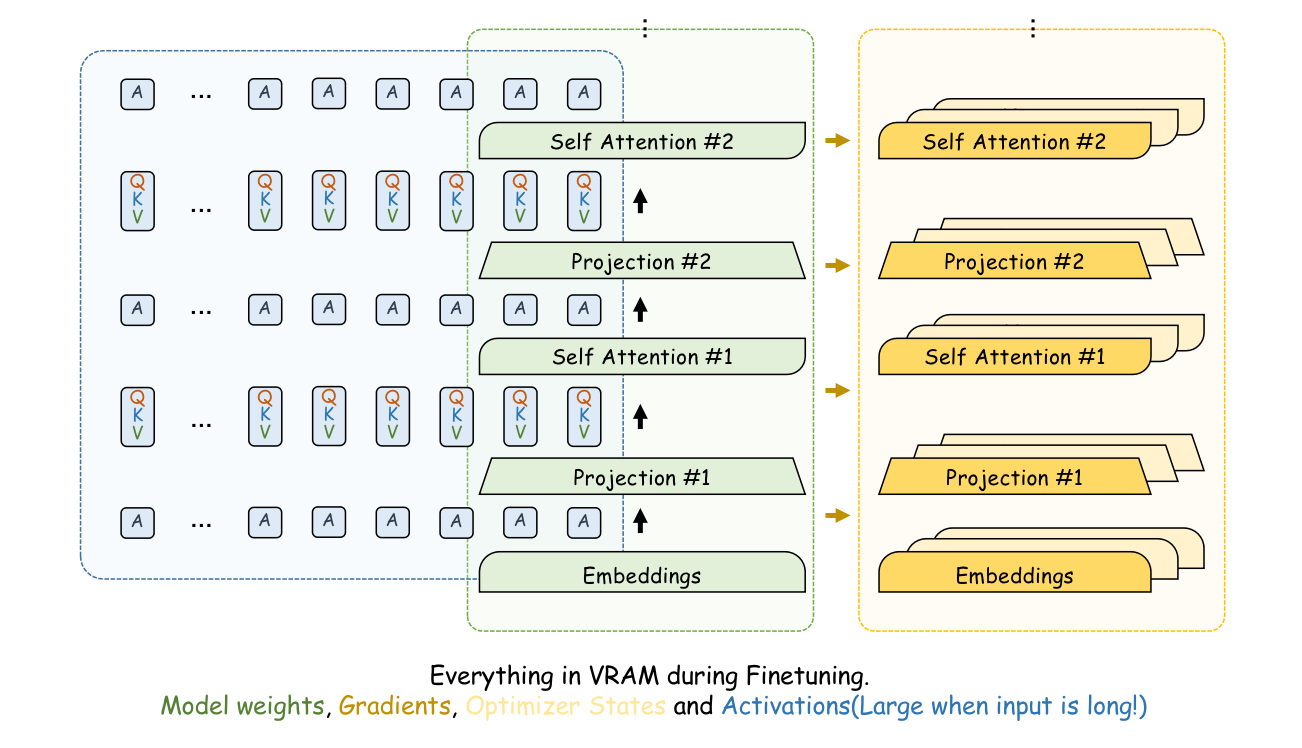
- 内存使用:在正向传播过程中,模型需要计算并保留每一层的中间结果(即激活值)。具体来说,上下文中的每个 token 在每一层都会有自己的多个 Key、Value 和 Query。随着上下文变长,这些激活值会占用大量显存。
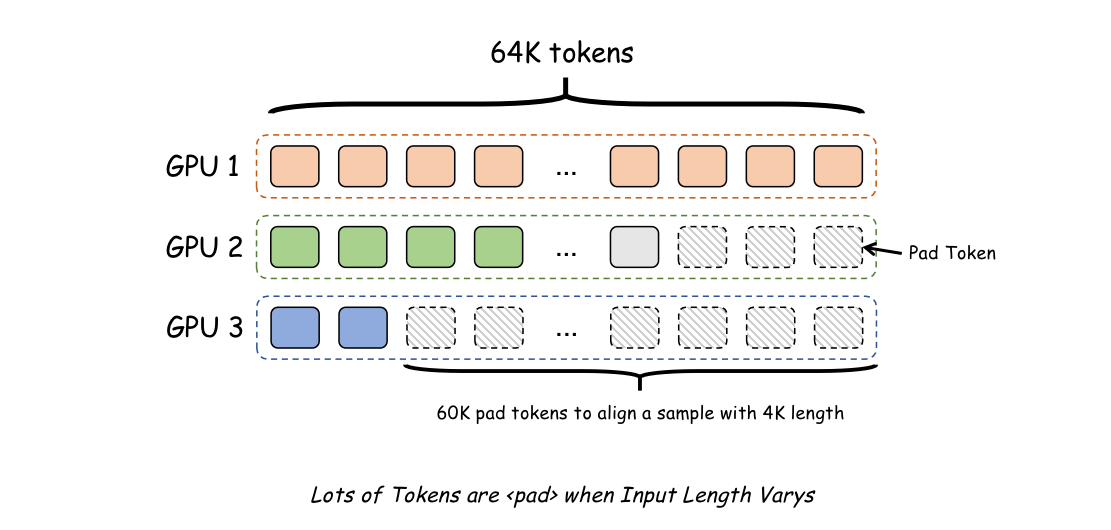
- 批次对齐:当批处理大小大于 1 时,长文本训练可能会因为填充(padding)token 而浪费大量空间,因为长文本的长度分布通常跨越多个数量级。下图显示了一个示例。
- 注意力空间复杂度:自注意力(Self-Attention)需要计算序列中每个 token 对所有其他 token 的注意力值,并且这个注意力计算的结果会形成一个 矩阵。这意味着注意力计算的空间复杂度是 。因此,如果上下文长度增加 30 倍,注意力计算所需的空间将增加 900 倍!
幸运的是,在如今各种训练技术的加持下,这些问题可以得到妥善解决。我们甚至可能根本不会遇到上述问题,因为我们使用的训练框架的默认设置可能已经考虑到了这些问题。但了解这些问题的存在并理解它们是如何优化的仍然非常重要。
内存使用
理想情况下,一个批处理大小为 1、长度为 64K 的样本,在正向传播过程中,其激活值占用的 GPU 内存应该与一个批处理大小为 32、长度为 2K 的样本相同。有人可能会说,批处理大小为 32、长度为 2K 的设置对于微调来说并非不切实际,特别是对于多 GPU 训练。
然而,问题在于这并不意味着批处理大小为 1、长度为 64K 的训练可以使用相同的多 GPU 训练方法,因为目前大多数并行训练框架(Deepspeed 和 FSDP)不支持将单个样本分布到多个 GPU 进行训练。为了在长文本上进行训练,我们需要尽可能多地使用优化方法来节省显存。从节省内存最多到最少,我们可以考虑以下技术。
GQA
在正向传播过程中,每个 token 在每一层都需要保留 num_attention_head 数量的 Query、Key 和 Value 向量。这些 QKV 是内存使用量最大的贡献者。大多数约 10B 的模型都有 num_attention_head = 32,这意味着每个 token 需要分配 32 * 3 = 96 个向量。
这种默认方法是多头注意力(MHA)。像Llama 2 7B、Qwen 系列、Command R 等模型都使用这种方法。
然而,其他模型采用了更高效的多头注意力,即分组查询注意力(GQA)。GQA 模型为每个 token 分配 num_attention_head 数量的 Query,但分配更少的 Key 和 Value。例如,Yi-9B 的 num_key_value_heads = 4,这意味着 Yi-9B 中每个 token 分配 32 + 4 + 4 = 40 个向量。像Llama 2 70B、Llama 3、Mixtral、Mistral、Yi 系列模型都使用 GQA。
GQA 的优势在推理过程中更加明显,因为在推理时,由于不需要反向传播,每个 token 的查询将在计算完成后被丢弃,不会被后续使用。
因此,在这种情况下,如果 MHA 为每个 token 分配 32 * 2 = 64 个向量,GQA 可能只需要 4 * 2 = 8 个向量。这带来的内存优势是巨大的。
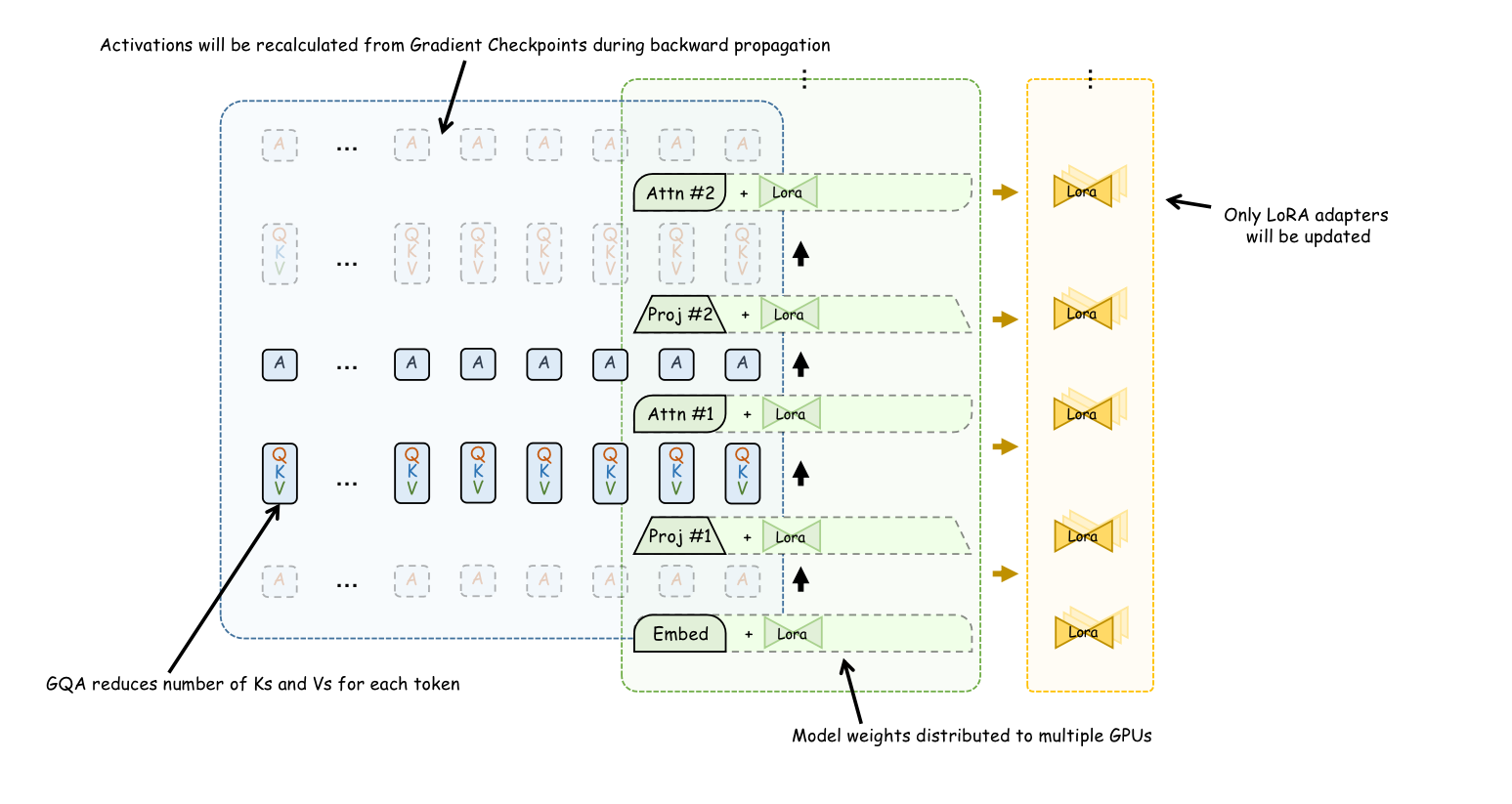
因此,为了实现更快的训练和更高效的推理,我们应该选择使用 GQA 作为微调基础的模型。要确定模型是否使用 GQA,我们只需要检查其配置文件中 num_key_value_heads 是否小于 num_attention_head。
梯度检查点
梯度检查点(Gradient Checkpoint)减少了在训练过程中保存每一层计算的中间结果的需求。它只保留了部分层(例如第 1、5、15 层)的中间结果。在反向传播时,如果需要某一层(例如第 7 层)的计算结果,则从最近的检查点(第 5 层)重新开始正向传播,以计算第 6 和第 7 层的中间结果。
从数学上讲,为了节省最多的内存,梯度检查点会保存 层的结果。对于一个 16 层的模型,它在正向传播时只保存第 1、5、9 和 13 层的结果。因此,对于占据长文本大部分比例的中间结果(即 QKV),使用梯度检查点也会将内存使用量减少 倍。
LoRA
LoRA 在很多情况下已基本成为微调领域的必备方法,尤其是在单 GPU 训练中。通常,在训练模型时,除了将所有模型权重加载到 GPU 中,还会为每个可训练参数分配额外的梯度和用于跟踪梯度动态的优化器状态。根据优化器的类型,优化器状态可能占用模型权重 3 到 6 倍的空间。
LoRA 限制了大多数参数不被训练,并引入了一组额外的少量可训练参数(LoRA Adapters),这些参数通常只占总权重的 1%。只有这 1% 的已训练参数被分配相应的优化器状态。
通过 LoRA,几乎所有由优化器状态带来的内存使用都被消除。但是,需要注意的是,长文本训练的主要内存瓶颈在于 token 的中间计算结果。LoRA 带来的优势与序列长度无关。
分布式训练
分布式训练可以通过使用多个 GPU 来实现超大型模型的训练。然而,它在长文本训练中带来的优势要小得多,因为常用的微调框架,包括 FSDP 和 Deepspeed,都基于数据并行,这意味着每个 GPU 独立训练。它们只将梯度、优化器状态和模型权重卸载到多个 GPU 甚至内存中,并在需要时进行聚合。
但如前所述,优化器和梯度带来的内存负担基本上已被 LoRA 消除。真正的内存负载集中在每个 token 对应的中间计算结果上。然而,基于数据并行的分布式计算要求每个卡至少有一个样本,这意味着它们不会在多张卡之间共享单个样本的内存。
因此,使用这些分布式方法可以通过增加并行度来显著加快训练速度,但同时,它只能减少部分内存使用(通过将模型参数分布到多张卡上)。
总而言之,经过我们不懈的努力,我们已尽可能地将内存使用量降到最低。参照上图。通过测试,这种优化,结合 Flash-attention,使我们能够在浮点 16 精度、80GB A100 环境下,以批处理大小为 1、长度为 64K 的方式对 Yi-9B-200K 进行微调。
批次对齐
与一般微调数据中长度集中在 200-500 个 token 不同,长文本微调的训练样本长度可能跨越几个数量级。
在长文本训练中,一个批次中很容易同时出现 4K 样本和 64K 样本。在这种情况下,大量填充(padding)token 将被添加到 4K 样本之后以对齐样本,造成大量浪费。
在默认设置下,短样本将被填充(padded)到批次中最长样本的长度。这意味着一个 4K 样本可能会被填充到 60K 的长度。幸运的是,目前大多数微调框架可以通过样本打包(Sample Packing)技术解决这个问题,我们只需要启用相应的选项。
样本打包实际上消除了批处理大小的概念。现在,一个包含 3 个样本的批处理被连接成一个更长的序列。这三个样本首尾相连形成一个序列,并且相应的注意力掩码(attention mask)会改变以防止同一序列中不同样本之间相互影响。这样做的好处是,不再有填充(padding)token:一个输入可能包含 2 个长样本或 100 个短样本。
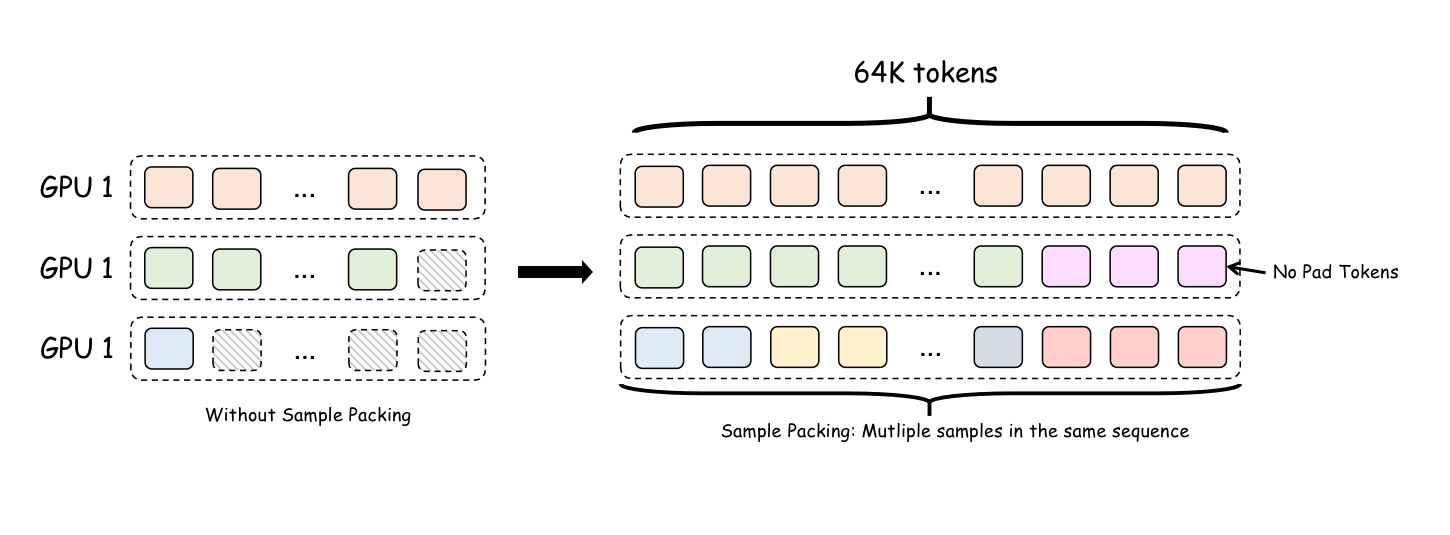
然而,在实践中,LongAlign 论文提到,同一批次中包含长样本和极短样本可能会影响模型收敛。为了解决这个问题,训练中通常会使长度相似的样本出现在同一批次中。常见的训练框架也提供了这个选项,可能被称为 sort_by_length 或类似名称。
注意力空间复杂度
在正常的注意力计算中,Query 与 Key、Value 之间的交互涉及 N * N 矩阵乘法。这使得长文本注意力计算具有 的空间复杂度。
但最后一个问题实际上很容易解决:只需使用 Flash Attention。Flash Attention 为注意力计算设计了特定的 CUDA 运算符。在更新每个 Query 时,不会加载未参与计算的其他 token 对应的 Queries 和 KVs。因此,Flash Attention 的注意力计算更接近 𝑂(𝑁) 复杂度。
鸣谢:https://insujang.github.io/2024-01-21/flash-attention
至此,我们基本上弥合了长文本和短文本微调之间的差距:现在训练一个 32K 长度的样本有效地等同于训练 32 个 1K 样本。然而,有些问题仍然难以解决,例如时间复杂度。执行一次前向传播需要计算每个 token 位置的表示,而每个 token 表示的计算本身就接近 𝑂(𝑁)。一个长上下文样本必然会带来比多个短上下文样本更长的推理时间。
在实际微调中,我们可以使用任何正确实现上述功能的框架进行训练,例如 HF Trainer、Axolotl 和 Llama Factory,它们理论上都应该满足要求。
实践:Faro 系列模型
有了这一系列技术,我们就可以用不算夸张的资源(几块 A100)来训练自己的长文本模型。因此,我首先自己训练了一些模型。我将这个系列的模型命名为 Faro,并训练了多个版本,分别基于 Qwen1.8B、Qwen4B、Yi-9B-200K 和 Yi-34B-200K。您可以在 Huggingface 上下载我的模型,我还提供了所有训练配置文件和 Wandb 跟踪记录,供感兴趣的人参考。
- 模型:Faro-Yi-9B Faro-Yi-34B Faro-Yi-9B-DPO
- Wandb 训练记录:Faro-SFT Faro-DPO
- Axolotl 训练配置文件:SFT.yml DPO.yml
长文本数据
开源的长上下文 SFT 数据集并不多。为了训练长上下文模型,我使用了 LongAlign 和 LongLora 开源的数据集,同时自己也合成了一些。
- THUDM/LongAlign-10k LongAlign 包含 10K 条长文本任务样本,其中 10% 为中文。
- Yukang/LongAlpaca-12k LongAlpaca 包含 12K 条长文本任务,主要关于论文阅读理解,也混合了一些短数据以保持平衡。
- wenbopan/RefGPT-Fact-v2-8x 这是我自行合成的数据。Mutonix/RefGPT-Fact-v2 是一个高质量的对话数据集,涉及文档提取和理解,但其长度稍短,所以我对其进行了扩展。
- wenbopan/anti-haystack 这是使用 GPT-4 生成的长文本任务集合。这些任务大多具有象征性,通常涉及事实的精确召回和段落引用。
以上总计约 4 万条数据。我还添加了一些短样本以保持平衡,同时为了保持模型的中文能力,我将大约 10% 的样本控制为中文。wenbopan/Fusang-v1 是最终获得的数据集,其 long 分支是按照上述方法构建的。这些样本大多数长度在 20K 以内,因此我的实际训练将模型的最大长度限制在 24K。然而,在实践中,这种训练也可以显著增强模型在更长文本上的建模能力。
训练
训练只需根据本博客中提到的方法进行适当配置。我使用 Axolotl 框架进行训练。这个框架最大的优点是其训练高度可配置,所有训练所需的选项都可以通过配置文件定义。Faro 系列模型的训练包括 SFT 和 DPO。只有 SFT 是在长文本上进行的。至于 DPO 的方法,您可以参考我的 Huggingface 仓库和训练脚本。
同时,我也提供了整个训练过程的 Wandb 跟踪记录 Faro-SFT Faro-DPO 以供参考。由于不同的训练运行可能使用不同数量的 GPU,您将在 Wandb 上看到不同长度的损失曲线。
评估
当然,完成训练后,我们需要测试模型在长文本建模方面的表现。这里我选择了 LongBench。我们可以看到,我们的长文本微调效果相当显著:Faro-Yi-9B 在大多数方面都优于 Yi-9B-200K。
| 名称 | 少样本学习_en | 合成任务_en | 单文档问答_en | 多文档问答_en | 摘要_en | 少样本学习_zh | 合成任务_zh | 单文档问答_zh | 多文档问答_zh | 摘要_zh |
|---|---|---|---|---|---|---|---|---|---|---|
| Yi-9B-200K | 60.6 | 22.8 | 30.9 | 38.9 | 25.8 | 46.5 | 28.0 | 49.6 | 17.7 | 9.7 |
| Faro-Yi-9B | 63.8 | 40.2 | 36.2 | 38.0 | 26.3 | 30.0 | 75.1 | 55.6 | 30.7 | 14.1 |
后续工作
目前,我对长文本微调的结果相当满意。但如果想继续改进,仍有很多工作可以做。这种长文本微调方法实际上充满了妥协。为了在单卡上运行长文本,我们不得不使用 LoRA,并且可以微调的模型也仅限于 GQA 模型。对于 13B 模型,最长可微调长度约为 32K,对于 8B 模型则为 64K。更长的长度超出了我们方法的上限。
为了在更长的文本上进行训练,我们需要使用基于张量并行而非数据并行的训练方法,例如 MegatronLM 和 Jax。然而,对于个人研究人员的使用场景,我们的方法已经可以简单快速地生成有用的长文本模型。





